BeatLearning
1.0.0
¿Alguna vez has querido tocar una canción que no estaba disponible en tu juego de ritmo favorito? ¿Alguna vez has querido tocar infinitas variaciones de esa canción?
Este proyecto de investigación de código abierto tiene como objetivo democratizar el proceso de creación automática de mapas de ritmos, ofreciendo herramientas accesibles y modelos básicos para desarrolladores, jugadores y entusiastas de juegos, allanando el camino para una nueva era de creatividad e innovación en los juegos de ritmo.
Ejemplos (más próximamente):
Primero necesitarás instalar Python 3.12, ir al directorio del repositorio y crear un entorno virtual mediante:
python3 -m venv venv
Luego llame source venv/bin/activate o venvScriptsactivate si está en una máquina con Windows. Una vez activado el entorno virtual, puede instalar las bibliotecas necesarias a través de:
pip3 install -r requirements.txt
Puede utilizar Jupyter para acceder a los notebooks/ :
jupyter notebook
También puedes probar la versión de Google Collab, siempre que tengas instancias de GPU disponibles (las de CPU predeterminadas tardan una eternidad en convertir una canción).
El canal solo admite mapas de ritmos de OSU por el momento.
Este repositorio es todavía un TRABAJO EN CURSO . El objetivo es desarrollar modelos generativos capaces de producir automáticamente mapas de ritmos para una amplia gama de juegos rítmicos, independientemente de la canción. Esta investigación aún está en curso, pero el objetivo es sacar los MVP lo más rápido posible.
Todas las contribuciones son valoradas, especialmente en forma de donaciones informáticas para la formación de modelos básicos. Entonces, si estás interesado, ¡no dudes en colaborar!
¡Únase a nosotros para explorar las infinitas posibilidades de la generación de mapas de ritmos impulsados por IA y dar forma al futuro de los juegos de ritmo!
Los modelos están disponibles en HuggingFace.
Los mapas de ritmo de los juegos de ritmo se convierten inicialmente a un formato de archivo intermedio, que luego se tokeniza en fragmentos de 100 ms. Cada token es capaz de codificar hasta dos eventos diferentes dentro de este período de tiempo (retenciones y/o aciertos) cuantificados con una precisión de 10 ms. El vocabulario del tokenizador se calcula previamente en lugar de aprenderse de los datos para cumplir con este criterio. La longitud del contexto y el tamaño del vocabulario se mantienen intencionalmente pequeños debido a la escasez de ejemplos de capacitación de calidad en el campo.
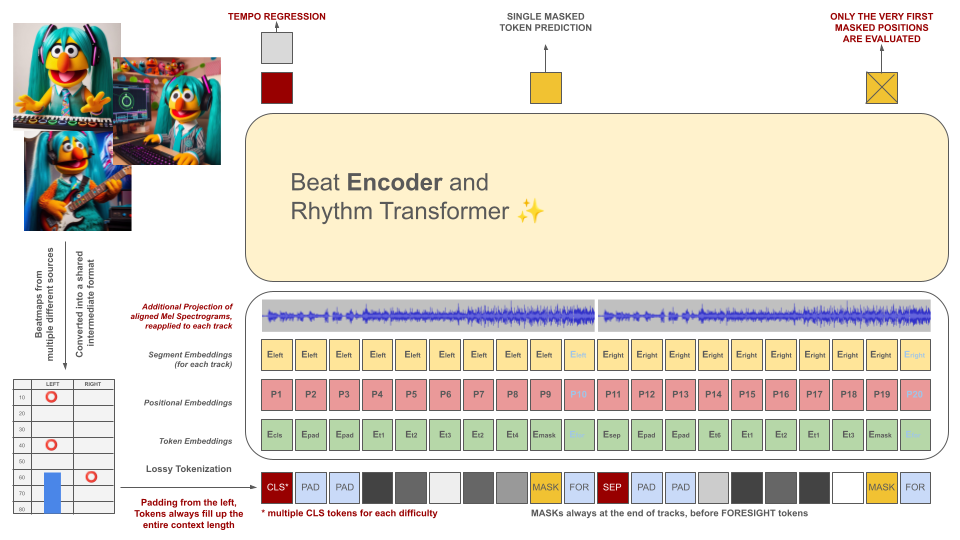 Estos tokens, junto con porciones de los datos de audio (su espectrograma Mel proyectado alineado con los tokens), sirven como entradas para un modelo de codificador enmascarado. Al igual que BeRT, el modelo codificador tiene dos objetivos durante el entrenamiento: estimar el tempo mediante una tarea de regresión y predecir los (siguientes) tokens enmascarados mediante una función de pérdida auditiva . Se admiten beatmaps con 1, 2 y 4 pistas. Cada token se predice de izquierda a derecha, reflejando el proceso de generación de una arquitectura de decodificador. Sin embargo, los tokens enmascarados también tienen acceso a información de audio adicional del futuro, indicados como tokens de previsión desde la derecha.
Estos tokens, junto con porciones de los datos de audio (su espectrograma Mel proyectado alineado con los tokens), sirven como entradas para un modelo de codificador enmascarado. Al igual que BeRT, el modelo codificador tiene dos objetivos durante el entrenamiento: estimar el tempo mediante una tarea de regresión y predecir los (siguientes) tokens enmascarados mediante una función de pérdida auditiva . Se admiten beatmaps con 1, 2 y 4 pistas. Cada token se predice de izquierda a derecha, reflejando el proceso de generación de una arquitectura de decodificador. Sin embargo, los tokens enmascarados también tienen acceso a información de audio adicional del futuro, indicados como tokens de previsión desde la derecha.
El propósito del modelo de IA no es devaluar los mapas de ritmos creados individualmente, sino más bien:
Todo el contenido generado debe cumplir con la normativa de la UE y estar etiquetado adecuadamente, incluidos metadatos que indiquen la participación del modelo de IA.
¡LA GENERACIÓN DE BEATMAPS PARA MATERIAL CON DERECHOS DE AUTOR ESTÁ ESTRICTAMENTE PROHIBIDA! ¡UTILIZA SÓLO CANCIONES PARA LAS CUALES TIENES DERECHOS!
El audio que aparece en los ejemplos de archivos de OSU proviene de artistas enumerados en el sitio web de OSU en la sección artistas destacados y tiene licencia para su uso específicamente en contenido relacionado con osu!.
Para evitar que su mapa de ritmos se utilice como datos de entrenamiento en el futuro, incluya los siguientes metadatos en su archivo de mapa de ritmos:
robots: disallow
El proyecto se inspira en un intento anterior conocido como AIOSU.
Además de depender de la wiki de OSU, osu-parser ha sido fundamental para aclarar las declaraciones de mapas de ritmos (especialmente los controles deslizantes). El modelo de transformador fue influenciado por NanoGPT y por la implementación de BeRT en pytorch.


