horovod
v0.28.1: Build fixes (ROCm, GCC 12)
Horovod es un marco de capacitación distribuido de aprendizaje profundo para TensorFlow, Keras, PyTorch y Apache MXNet. El objetivo de Horovod es hacer que el aprendizaje profundo distribuido sea rápido y fácil de usar.
Horovod está alojado en LF AI & Data Foundation (LF AI & Data). Si es una empresa profundamente comprometida con el uso de tecnologías de código abierto en inteligencia artificial, máquinas y aprendizaje profundo, y desea apoyar a las comunidades de proyectos de código abierto en estos dominios, considere unirse a LF AI & Data Foundation. Para obtener detalles sobre quién está involucrado y cómo Horovod desempeña un papel, lea el anuncio de la Fundación Linux.
Contenido
La motivación principal de este proyecto es facilitar la toma de un script de entrenamiento de una sola GPU y escalarlo exitosamente para entrenarlo en muchas GPU en paralelo. Esto tiene dos aspectos:
Internamente en Uber descubrimos que el modelo MPI es mucho más sencillo y requiere muchos menos cambios de código que soluciones anteriores como Distributed TensorFlow con servidores de parámetros. Una vez que se ha escrito un script de entrenamiento para escalar con Horovod, se puede ejecutar en una sola GPU, en varias GPU o incluso en varios hosts sin realizar más cambios en el código. Consulte la sección Uso para obtener más detalles.
Además de ser fácil de usar, Horovod es rápido. A continuación se muestra un gráfico que representa la prueba comparativa que se realizó en 128 servidores con 4 GPU Pascal, cada una conectada por una red de 25 Gbit/s compatible con RoCE:
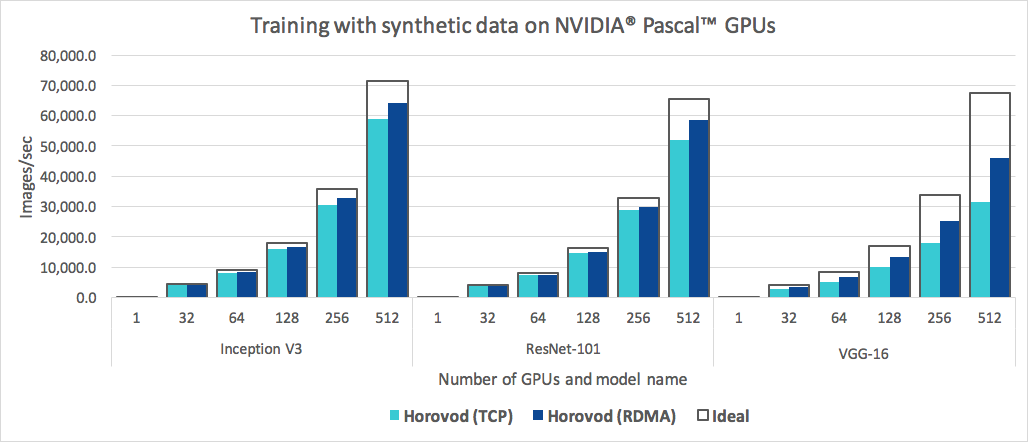
Horovod logra una eficiencia de escalado del 90 % para Inception V3 y ResNet-101, y una eficiencia de escalado del 68 % para VGG-16. Consulte Puntos de referencia para descubrir cómo reproducir estos números.
Si bien la instalación de MPI y NCCL en sí puede parecer una molestia adicional, el equipo que se ocupa de la infraestructura solo debe hacerlo una vez, mientras que todos los demás miembros de la empresa que construyen los modelos pueden disfrutar de la simplicidad de entrenarlos a escala.
Para instalar Horovod en Linux o macOS:
Si instaló TensorFlow desde PyPI, asegúrese de que esté instalado g++-5 o superior. A partir de TensorFlow 2.10, se necesitará un compilador compatible con C++ 17 como g++8 o superior.
Si ha instalado PyTorch desde PyPI, asegúrese de que esté instalado g++-5 o superior.
Si ha instalado cualquiera de los paquetes de Conda, asegúrese de que el paquete gxx_linux-64 Conda esté instalado.
Instale el paquete pip horovod .
Para ejecutar en CPU:
$ pip install horovodPara ejecutar en GPU con NCCL:
$ HOROVOD_GPU_OPERATIONS=NCCL pip install horovodPara obtener más detalles sobre la instalación de Horovod con soporte para GPU, lea Horovod en GPU.
Para obtener la lista completa de opciones de instalación de Horovod, lea la Guía de instalación.
Si desea utilizar MPI, lea Horovod con MPI.
Si desea utilizar Conda, lea Creación de un entorno Conda con soporte de GPU para Horovod.
Si desea utilizar Docker, lea Horovod en Docker.
Para compilar Horovod desde el código fuente, siga las instrucciones de la Guía del colaborador.
Los principios básicos de Horovod se basan en conceptos de MPI como tamaño , rango , rango local , allreduce , allgather , broadcast y alltoall . Consulte esta página para obtener más detalles.
Consulte estas páginas para ver ejemplos y mejores prácticas de Horovod:
Para utilizar Horovod, realice las siguientes adiciones a su programa:
hvd.init() para inicializar Horovod.Fije cada GPU a un único proceso para evitar la contención de recursos.
Con la configuración típica de una GPU por proceso, configúrelo en rango local . Al primer proceso en el servidor se le asignará la primera GPU, al segundo proceso se le asignará la segunda GPU, y así sucesivamente.
Escale la tasa de aprendizaje según el número de trabajadores.
El tamaño de lote efectivo en la capacitación distribuida síncrona se escala según la cantidad de trabajadores. Un aumento en la tasa de aprendizaje compensa el aumento del tamaño del lote.
Envuelva el optimizador en hvd.DistributedOptimizer .
El optimizador distribuido delega el cálculo de gradientes al optimizador original, promedia los gradientes usando allreduce o allgather y luego aplica esos gradientes promediados.
Transmita los estados de las variables iniciales desde el rango 0 a todos los demás procesos.
Esto es necesario para garantizar una inicialización consistente de todos los trabajadores cuando el entrenamiento comienza con pesos aleatorios o se restablece desde un punto de control.
Ejemplo de uso de TensorFlow v1 (consulte el directorio de ejemplos para obtener ejemplos de capacitación completos):
import tensorflow as tf
import horovod . tensorflow as hvd
# Initialize Horovod
hvd . init ()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf . ConfigProto ()
config . gpu_options . visible_device_list = str ( hvd . local_rank ())
# Build model...
loss = ...
opt = tf . train . AdagradOptimizer ( 0.01 * hvd . size ())
# Add Horovod Distributed Optimizer
opt = hvd . DistributedOptimizer ( opt )
# Add hook to broadcast variables from rank 0 to all other processes during
# initialization.
hooks = [ hvd . BroadcastGlobalVariablesHook ( 0 )]
# Make training operation
train_op = opt . minimize ( loss )
# Save checkpoints only on worker 0 to prevent other workers from corrupting them.
checkpoint_dir = '/tmp/train_logs' if hvd . rank () == 0 else None
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf . train . MonitoredTrainingSession ( checkpoint_dir = checkpoint_dir ,
config = config ,
hooks = hooks ) as mon_sess :
while not mon_sess . should_stop ():
# Perform synchronous training.
mon_sess . run ( train_op )Los comandos de ejemplo siguientes muestran cómo ejecutar la capacitación distribuida. Consulte Ejecutar Horovod para obtener más detalles, incluidos ajustes y sugerencias de RoCE/InfiniBand para lidiar con bloqueos.
Para ejecutar en una máquina con 4 GPU:
$ horovodrun -np 4 -H localhost:4 python train.pyPara ejecutar en 4 máquinas con 4 GPU cada una:
$ horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py Para ejecutar usando Open MPI sin el contenedor horovodrun , consulte Ejecución de Horovod con Open MPI.
Para ejecutar en Docker, consulte Horovod en Docker.
Para ejecutar en Kubernetes, consulte Helm Chart, Kubeflow MPI Operador, FfDL y Polyaxon.
Para ejecutar en Spark, consulte Horovod en Spark.
Para ejecutar en Ray, consulte Horovod en Ray.
Para ejecutar en Singularity, consulte Singularity.
Para ejecutar en un clúster LSF HPC (por ejemplo, Summit), consulte LSF.
Para ejecutar Hadoop Yarn, consulte TonY.
Gloo es una biblioteca de comunicaciones colectivas de código abierto desarrollada por Facebook.
Gloo viene incluido con Horovod y permite a los usuarios ejecutar Horovod sin necesidad de instalar MPI.
Para entornos que admiten MPI y Gloo, puede optar por usar Gloo en tiempo de ejecución pasando el argumento --gloo a horovodrun :
$ horovodrun --gloo -np 2 python train.pyHorovod admite mezclar y combinar colectivos de Horovod con otras bibliotecas MPI, como mpi4py, siempre que el MPI se haya creado con soporte de subprocesos múltiples.
Puede comprobar la compatibilidad con subprocesos múltiples de MPI consultando la función hvd.mpi_threads_supported() .
import horovod . tensorflow as hvd
# Initialize Horovod
hvd . init ()
# Verify that MPI multi-threading is supported.
assert hvd . mpi_threads_supported ()
from mpi4py import MPI
assert hvd . size () == MPI . COMM_WORLD . Get_size ()También puede inicializar Horovod con un subcomunicador mpi4py, en cuyo caso cada subcomunicador ejecutará un entrenamiento de Horovod independiente.
from mpi4py import MPI
import horovod . tensorflow as hvd
# Split COMM_WORLD into subcommunicators
subcomm = MPI . COMM_WORLD . Split ( color = MPI . COMM_WORLD . rank % 2 ,
key = MPI . COMM_WORLD . rank )
# Initialize Horovod
hvd . init ( comm = subcomm )
print ( 'COMM_WORLD rank: %d, Horovod rank: %d' % ( MPI . COMM_WORLD . rank , hvd . rank ()))Aprenda cómo optimizar su modelo para la inferencia y eliminar las operaciones de Horovod del gráfico aquí.
Una de las características únicas de Horovod es su capacidad para intercalar comunicación y computación junto con la capacidad de realizar pequeñas operaciones allreduce por lotes, lo que resulta en un mejor rendimiento. A esta función de procesamiento por lotes la llamamos Tensor Fusion.
Consulte aquí para obtener todos los detalles e instrucciones de ajuste.
Horovod tiene la capacidad de registrar la línea de tiempo de su actividad, llamada Horovod Timeline.
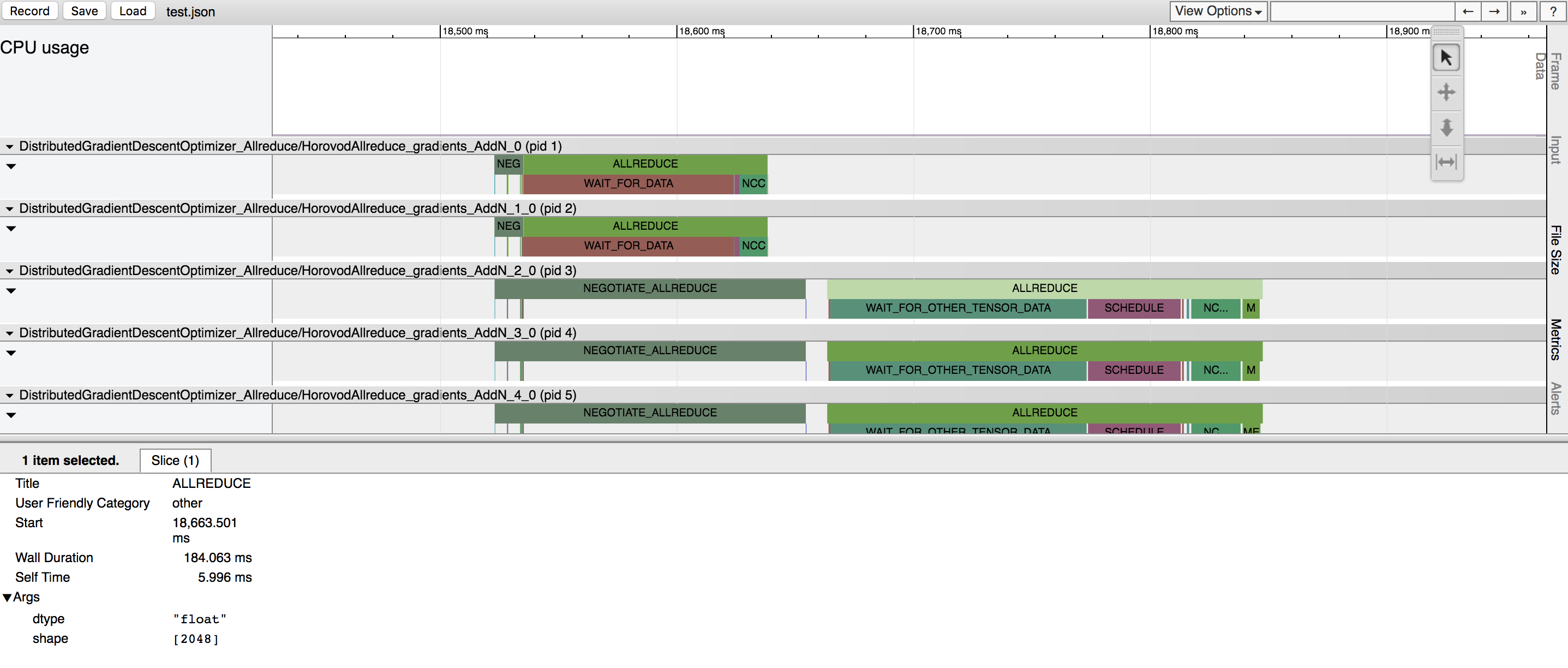
Utilice la línea de tiempo de Horovod para analizar el rendimiento de Horovod. Consulte aquí para obtener todos los detalles e instrucciones de uso.
Seleccionar los valores correctos para hacer uso eficiente de Tensor Fusion y otras funciones avanzadas de Horovod puede implicar una buena cantidad de prueba y error. Proporcionamos un sistema para automatizar este proceso de optimización del rendimiento llamado autoajuste , que puede habilitar con un único argumento de línea de comando para horovodrun .
Consulte aquí para obtener todos los detalles e instrucciones de uso.
Horovod le permite ejecutar simultáneamente distintas operaciones colectivas en diferentes grupos de procesos que participan en una capacitación distribuida. Configure objetos hvd.process_set para hacer uso de esta capacidad.
Consulte Conjuntos de procesos para obtener instrucciones detalladas.
Envíenos enlaces a cualquier guía de usuario que desee publicar en este sitio.
Consulte Solución de problemas y envíe un ticket si no puede encontrar una respuesta.
Cite a Horovod en sus publicaciones si le ayuda en su investigación:
@artículo{sergeev2018horovod,
Autor = {Alexander Sergeev y Mike Del Balso},
Diario = {arXiv preimpresión arXiv:1802.05799},
Título = {Horovod: aprendizaje profundo distribuido rápido y sencillo en {TensorFlow}},
Año = {2018}
}
1. Sergeev, A., Del Balso, M. (2017) Conozca a Horovod: el marco de aprendizaje profundo distribuido de código abierto de Uber para TensorFlow . Obtenido de https://eng.uber.com/horovod/
2. Sergeev, A. (2017) Horovod: TensorFlow distribuido simplificado . Obtenido de https://www.slideshare.net/AlexanderSergeev4/horovod-distributed-tensorflow-made-easy
3. Sergeev, A., Del Balso, M. (2018) Horovod: aprendizaje profundo distribuido rápido y sencillo en TensorFlow . Obtenido de arXiv:1802.05799
El código fuente de Horovod se basó en el repositorio Baidu tensorflow-allreduce escrito por Andrew Gibiansky y Joel Hestness. Su trabajo original se describe en el artículo Bringing HPC Techniques to Deep Learning.


