alibi
v0.9.6

Alibi es una biblioteca de Python destinada a la inspección e interpretación de modelos de aprendizaje automático. El objetivo de la biblioteca es proporcionar implementaciones de alta calidad de métodos de explicación de caja negra, caja blanca, local y global para modelos de clasificación y regresión.
Si está interesado en la detección de valores atípicos, la deriva de conceptos o la detección de instancias adversas, consulte nuestro proyecto hermano alibi-detect.
Explicaciones de anclaje para imágenes.  | Degradados integrados para texto  |
Ejemplos contrafactuales 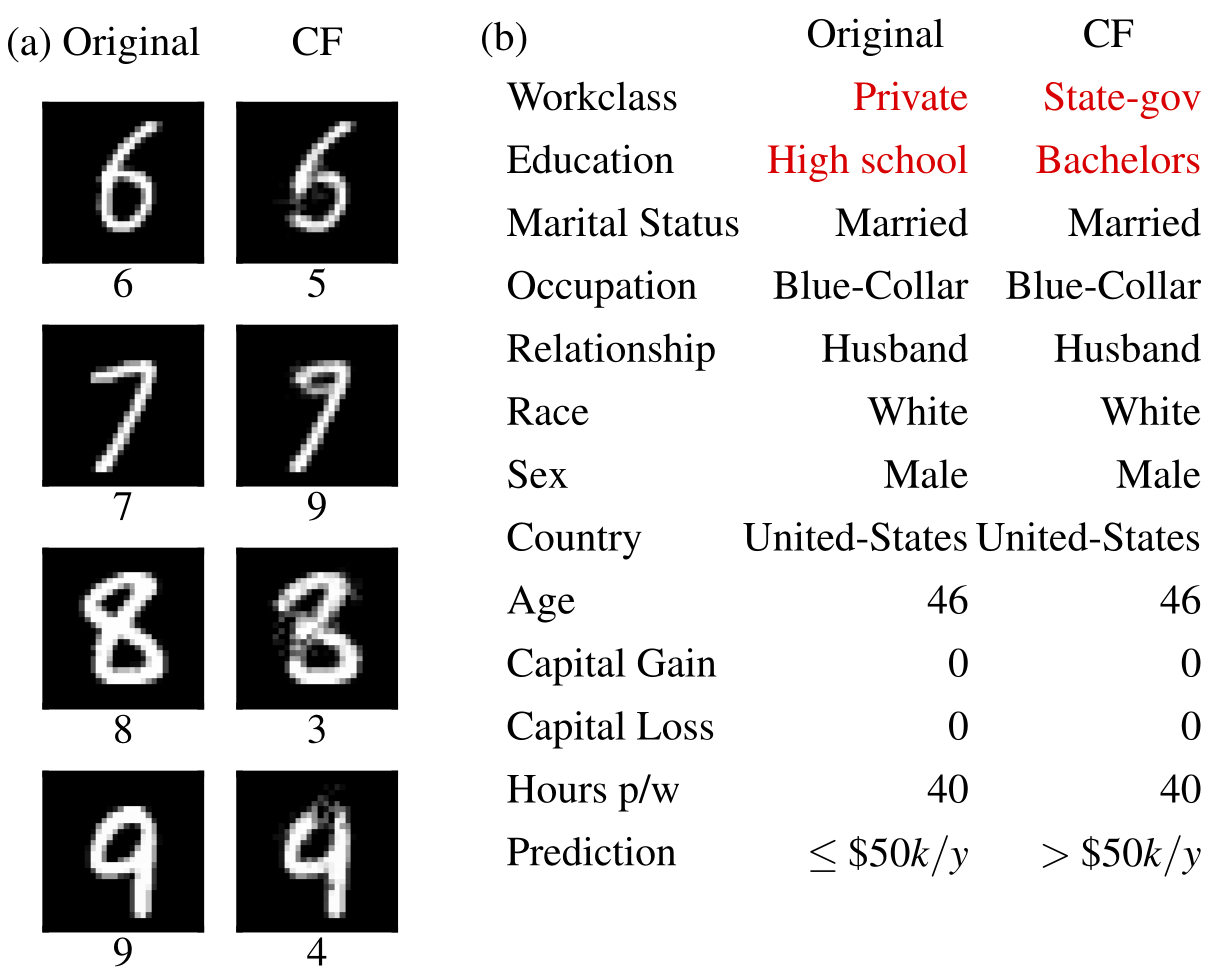 | Efectos locales acumulados 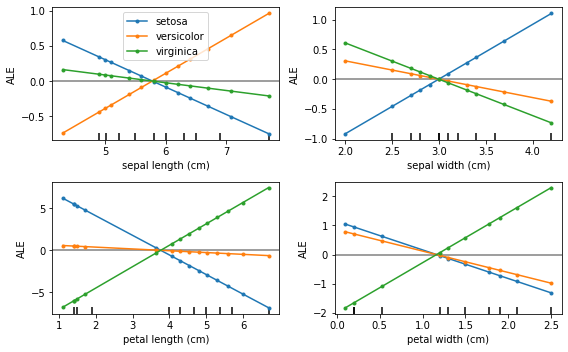 |
Alibi se puede instalar desde:
pip )conda / mamba )Alibi se puede instalar desde PyPI:
pip install alibiAlternativamente, se puede instalar la versión de desarrollo:
pip install git+https://github.com/SeldonIO/alibi.git Para aprovechar el cálculo distribuido de explicaciones, instale alibi con ray :
pip install alibi[ray] Para compatibilidad con SHAP, instale alibi de la siguiente manera:
pip install alibi[shap]Para instalar desde conda-forge, se recomienda utilizar mamba, que se puede instalar en el entorno base de conda con:
conda install mamba -n base -c conda-forgePara la instalación estándar de Alibi:
mamba install -c conda-forge alibiPara soporte informático distribuido:
mamba install -c conda-forge alibi rayPara soporte SHAP:
mamba install -c conda-forge alibi shap La API de explicación de alibi se inspira en scikit-learn y consta de distintos pasos de inicialización, ajuste y explicación. Usaremos el explicador AnchorTabular para ilustrar la API:
from alibi . explainers import AnchorTabular
# initialize and fit explainer by passing a prediction function and any other required arguments
explainer = AnchorTabular ( predict_fn , feature_names = feature_names , category_map = category_map )
explainer . fit ( X_train )
# explain an instance
explanation = explainer . explain ( x ) La explicación devuelta es un objeto Explanation con atributos meta y data . meta es un diccionario que contiene los metadatos del explicador y cualquier hiperparámetro y data es un diccionario que contiene todo lo relacionado con la explicación calculada. Por ejemplo, para el algoritmo Anchor, se puede acceder a la explicación mediante explanation.data['anchor'] (o explanation.anchor ). Los detalles exactos de los campos disponibles varían de un método a otro, por lo que recomendamos al lector que se familiarice con los tipos de métodos admitidos.
Las siguientes tablas resumen los posibles casos de uso para cada método.
| Método | Modelos | Explicaciones | Clasificación | Regresión | Tabular | Texto | Imágenes | Características categóricas | Se requiere juego de trenes | Repartido |
|---|---|---|---|---|---|---|---|---|---|---|
| CERVEZA INGLESA | CAMA Y DESAYUNO | global | ✔ | ✔ | ✔ | |||||
| Dependencia parcial | BB WB | global | ✔ | ✔ | ✔ | ✔ | ||||
| Variación de PD | BB WB | global | ✔ | ✔ | ✔ | ✔ | ||||
| Importancia de la permutación | CAMA Y DESAYUNO | global | ✔ | ✔ | ✔ | ✔ | ||||
| Anclas | CAMA Y DESAYUNO | local | ✔ | ✔ | ✔ | ✔ | ✔ | Para tabulares | ||
| CEM | BB* TF/Keras | local | ✔ | ✔ | ✔ | Opcional | ||||
| Contrafácticos | BB* TF/Keras | local | ✔ | ✔ | ✔ | No | ||||
| Contrafactuales de prototipos | BB* TF/Keras | local | ✔ | ✔ | ✔ | ✔ | Opcional | |||
| Contrafactuales con RL | CAMA Y DESAYUNO | local | ✔ | ✔ | ✔ | ✔ | ✔ | |||
| Degradados integrados | TF/Keras | local | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | Opcional | |
| Núcleo SHAP | CAMA Y DESAYUNO | local global | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ||
| Forma del árbol | BM | local global | ✔ | ✔ | ✔ | ✔ | Opcional | |||
| Explicaciones de similitud | BM | local | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
Estos algoritmos proporcionan puntuaciones específicas de cada instancia que miden la confianza del modelo para realizar una predicción particular.
| Método | Modelos | Clasificación | Regresión | Tabular | Texto | Imágenes | Características categóricas | Se requiere juego de trenes |
|---|---|---|---|---|---|---|---|---|
| Puntuaciones de confianza | CAMA Y DESAYUNO | ✔ | ✔ | ✔(1) | ✔(2) | Sí | ||
| Medida de linealidad | CAMA Y DESAYUNO | ✔ | ✔ | ✔ | ✔ | Opcional |
Llave:
Estos algoritmos proporcionan una vista resumida del conjunto de datos y ayudan a construir un clasificador interpretable 1-KNN.
| Método | Clasificación | Regresión | Tabular | Texto | Imágenes | Características categóricas | Etiquetas del conjunto de trenes |
|---|---|---|---|---|---|---|---|
| ProtoSelect | ✔ | ✔ | ✔ | ✔ | ✔ | Opcional |
Efectos locales acumulados (ALE, Apley y Zhu, 2016)
Dependencia parcial (JH Friedman, 2001)
Varianza de dependencia parcial (Greenwell et al., 2018)
Importancia de la permutación (Breiman, 2001; Fisher et al., 2018)
Explicaciones ancla (Ribeiro et al., 2018)
Método de explicación contrastiva (CEM, Dhurandhar et al., 2018)
Explicaciones contrafactuales (extensión de Wachter et al., 2017)
Explicaciones contrafactuales guiadas por prototipos (Van Looveren y Klaise, 2019)
Explicaciones contrafactuales independientes del modelo mediante RL (Samoilescu et al., 2021)
Gradientes integrados (Sundararajan et al., 2017)
Explicaciones de los aditivos Kernel Shapley (Lundberg et al., 2017)
Explicaciones de los aditivos de Tree Shapley (Lundberg et al., 2020)
Puntuaciones de confianza (Jiang et al., 2018)
Medida de linealidad
ProtoSelect
Explicaciones de similitud
Si utiliza una coartada en su investigación, considere citarla.
Entrada BibTeX:
@article{JMLR:v22:21-0017,
author = {Janis Klaise and Arnaud Van Looveren and Giovanni Vacanti and Alexandru Coca},
title = {Alibi Explain: Algorithms for Explaining Machine Learning Models},
journal = {Journal of Machine Learning Research},
year = {2021},
volume = {22},
number = {181},
pages = {1-7},
url = {http://jmlr.org/papers/v22/21-0017.html}
}


