INTR
1.0.0
Este repositorio es la implementación oficial de INTR: un transformador simple e interpretable para análisis y clasificación de imágenes detalladas. Actualmente incluye código y modelos para la interpretación de datos detallados. Proporcionaremos un enlace a las próximas actas de ICLR 2024 para este documento cuando esté disponible en línea.
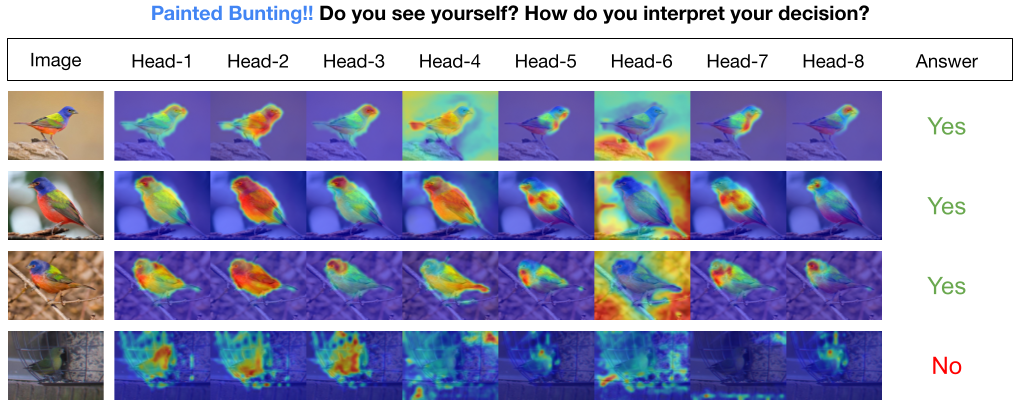
INTR es un uso novedoso de Transformers para hacer que la clasificación de imágenes sea interpretable. En INTR, investigamos un enfoque proactivo para la clasificación, pidiendo a cada clase que se busque a sí misma en una imagen. Aprendemos consultas específicas de clase (una para cada clase) como entrada al decodificador, lo que les permite buscar su presencia en una imagen mediante atención cruzada. Mostramos que INTR anima intrínsecamente a cada clase a asistir de forma distinta; Por tanto, las ponderaciones de atención cruzada proporcionan una interpretación significativa de la predicción del modelo. Curiosamente, a través de la atención cruzada de múltiples cabezales, INTR podría aprender a localizar diferentes atributos de una clase, lo que la hace particularmente adecuada para clasificación y análisis detallados.
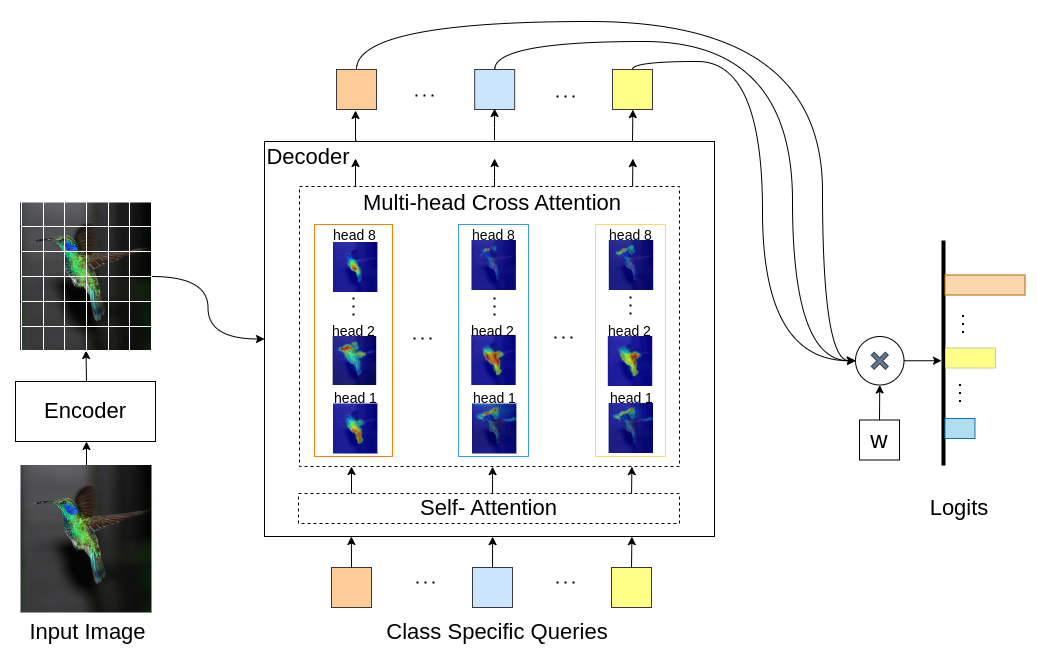
En el modelo INTR, cada consulta en el decodificador es responsable de la predicción de una clase. Entonces, una consulta se mira a sí misma para encontrar características específicas de clase en el mapa de características. Primero, visualizamos el mapa de características, es decir, la matriz de valores de la arquitectura del transformador para ver las partes importantes del objeto en la imagen. Para encontrar las características específicas a las que el modelo presta atención en la matriz de valores, mostramos el mapa de calor de la atención del modelo. Para evitar interferencias externas en la clasificación, utilizamos un vector de peso compartido para la clasificación, por lo que el peso de atención explica la predicción del modelo.
INTR en la red troncal DETR-R50, rendimiento de clasificación y modelos ajustados en diferentes conjuntos de datos.
| Conjunto de datos | acc@1 | acc@5 | Modelo |
|---|---|---|---|
| CACHORRO | 71,8 | 89,3 | descargar punto de control |
| Pájaro | 97,4 | 99,2 | descargar punto de control |
| Mariposa | 95.0 | 98,3 | descargar punto de control |
Crear un entorno Python (opcional)
conda create -n intr python=3.8 -y
conda activate intrClonar el repositorio
git clone https://github.com/dipanjyoti/INTR.git
cd INTRInstalar dependencias de Python
pip install -r requirements.txtSiga el siguiente formato para obtener datos.
datasets
├── dataset_name
│ ├── train
│ │ ├── class1
│ │ │ ├── img1.jpeg
│ │ │ ├── img2.jpeg
│ │ │ └── ...
│ │ ├── class2
│ │ │ ├── img3.jpeg
│ │ │ └── ...
│ │ └── ...
│ └── val
│ ├── class1
│ │ ├── img4.jpeg
│ │ ├── img5.jpeg
│ │ └── ...
│ ├── class2
│ │ ├── img6.jpeg
│ │ └── ...
│ └── ...
Para evaluar el rendimiento de INTR en el conjunto de datos CUB , en una configuración de múltiples GPU (por ejemplo, 4 GPU), ejecute el siguiente comando. Los puntos de control INTR están disponibles en Ajustar el modelo y los resultados.
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 --master_port 12345 --use_env main.py --eval --resume < path/to/intr_checkpoint_cub_detr_r50.pth > --dataset_path < path/to/datasets > --dataset_name < dataset_name > Para generar representaciones visuales de las interpretaciones del INTR, ejecute el comando proporcionado a continuación. Este comando presentará la interpretación de una clase específica con el índice <número_clase>. De forma predeterminada, mostrará las interpretaciones de todos los jefes de atención. Para centrarse también en las interpretaciones asociadas con las consultas principales etiquetadas como top_q, establezca el parámetro sim_query_heads en 1. Utilice un tamaño de lote de 1 para la visualización.
python -m tools.visualization --eval --resume < path/to/intr_checkpoint_cub_detr_r50.pth > --dataset_path < path/to/datasets > --dataset_name < dataset_name > --class_index < class_number >Predicción y visualización de una sola imagen en tiempo de inferencia: también proporcionamos un Jupyter Notebook, demo.ipynb, diseñado para la predicción y visualización de una sola imagen durante el proceso de inferencia. Tenga en cuenta que la demostración se centra en el conjunto de datos CUB.
Para preparar INTR para el entrenamiento, utilice el modelo previamente entrenado DETR-R50. Para entrenar para un conjunto de datos en particular, modifique '--num_queries' configurándolo en el número de clases en el conjunto de datos. Dentro de la arquitectura INTR, a cada consulta en el decodificador se le asigna la tarea de capturar características específicas de la clase, lo que significa que cada consulta se puede adaptar a través del proceso de aprendizaje. En consecuencia, el número total de parámetros del modelo crecerá en proporción al número de clases en el conjunto de datos. Para entrenar INTR en un sistema de múltiples GPU (por ejemplo, 4 GPU), ejecute el siguiente comando.
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 --master_port 12345 --use_env main.py --finetune < path/to/detr-r50-e632da11.pth > --dataset_path < path/to/datasets > --dataset_name < dataset_name > --num_queries < num_of_classes > Nuestro modelo está inspirado en el método DEtection TRansformer (DETR).
Agradecemos a los autores de DETR por realizar tan gran trabajo.
Si encuentra útil nuestro trabajo para su investigación, considere citar la entrada de BibTeX.
@inproceedings{paul2024simple,
title={A Simple Interpretable Transformer for Fine-Grained Image Classification and Analysis},
author={Paul, Dipanjyoti and Chowdhury, Arpita and Xiong, Xinqi and Chang, Feng-Ju and Carlyn, David and Stevens, Samuel and Provost, Kaiya and Karpatne, Anuj and Carstens, Bryan and Rubenstein, Daniel and Stewart, Charles and Berger-Wolf, Tanya and Su, Yu and Chao, Wei-Lun},
booktitle={International Conference on Learning Representations},
year={2024}
}

