Index 1.9B
1.0.0
切换到中文 | En línea: Chat y juegos de roles | QQ: Grupo QQ
La serie Index-1.9B es una versión liviana de los modelos de la serie Index, que incluye los siguientes modelos:
| Modelo | Puntuación media | Puntuación media en inglés | MMLU | CEVAL | CMMLU | HellaSwag | Arco-C | Arco-E |
|---|---|---|---|---|---|---|---|---|
| Google Gemma 2B | 41,58 | 46,77 | 41,81 | 31.36 | 31.02 | 66,82 | 36,39 | 42.07 |
| Fi-2 (2.7B) | 58,89 | 72,54 | 57,61 | 31.12 | 32.05 | 70,94 | 74,51 | 87.1 |
| Qwen1.5-1.8B | 58,96 | 59,28 | 47.05 | 59,48 | 57.12 | 58,33 | 56,82 | 74,93 |
| Qwen2-1.5B (informe) | 65.17 | 62,52 | 56,5 | 70,6 | 70.3 | 66,6 | 43,9 | 83.09 |
| MiniCPM-2.4B-SFT | 62,53 | 68,75 | 53,8 | 49.19 | 50,97 | 67,29 | 69,44 | 84,48 |
| Índice-1.9B-Puro | 50,61 | 52,99 | 46.24 | 46,53 | 45.19 | 62,63 | 41,97 | 61.1 |
| Índice-1.9B | 64,92 | 69,93 | 52,53 | 57.01 | 52,79 | 80,69 | 65,15 | 81,35 |
| Llama2-7B | 50,79 | 60.31 | 44,32 | 32,42 | 31.11 | 76 | 46.3 | 74,6 |
| Mistral-7B (informe) | / | 69,23 | 60.1 | / | / | 81.3 | 55,5 | 80 |
| Baichuan2-7B | 54,53 | 53,51 | 54,64 | 56,19 | 56,95 | 25.04 | 57,25 | 77.12 |
| Llama2-13B | 57,51 | 66,61 | 55,78 | 39,93 | 38,7 | 76,22 | 58,88 | 75,56 |
| Baichuan2-13B | 68,90 | 71,69 | 59,63 | 59.21 | 61,27 | 72,61 | 70.04 | 84,48 |
| MPT-30B (informe) | / | 63,48 | 46,9 | / | / | 79,9 | 50,6 | 76,5 |
| Falcon-40B (informe) | / | 68.18 | 55,4 | / | / | 83,6 | 54,5 | 79,2 |
El código de evaluación se basa en OpenCompass con modificaciones de compatibilidad. Consulte la carpeta de evaluación para obtener más detalles.
| AbrazosCara | ModeloScope |
|---|---|
| ? Índice-1.9B-Chat | Índice-1.9B-Chat |
| ? Index-1.9B-Personaje (juego de roles) | Index-1.9B-Personaje (juego de roles) |
| ? Índice-1.9B-Base | Índice-1.9B-Base |
| ? Índice-1.9B-Base-Pura | Índice-1.9B-Base-Pura |
| ? Index-1.9B-32K (contexto largo de 32K) | Index-1.9B-32K (contexto largo de 32K) |
Index-1.9B-32K solo se puede iniciar con esta herramienta: demo/cli_long_text_demo.py .git clone https://github.com/bilibili/Index-1.9B
cd Index-1.9Bpip install -r requirements.txtPuede cargar el modelo Index-1.9B-Chat para dialogar usando el siguiente código:
import argparse
from transformers import AutoTokenizer , pipeline
# Attention! The directory must not contain "." and can be replaced with "_".
parser = argparse . ArgumentParser ()
parser . add_argument ( '--model_path' , default = "./IndexTeam/Index-1.9B-Chat/" , type = str , help = "" )
parser . add_argument ( '--device' , default = "cpu" , type = str , help = "" ) # also could be "cuda" or "mps" for Apple silicon
args = parser . parse_args ()
tokenizer = AutoTokenizer . from_pretrained ( args . model_path , trust_remote_code = True )
generator = pipeline ( "text-generation" ,
model = args . model_path ,
tokenizer = tokenizer , trust_remote_code = True ,
device = args . device )
system_message = "你是由哔哩哔哩自主研发的大语言模型,名为“Index”。你能够根据用户传入的信息,帮助用户完成指定的任务,并生成恰当的、符合要求的回复。"
query = "续写 天不生我金坷垃"
model_input = []
model_input . append ({ "role" : "system" , "content" : system_message })
model_input . append ({ "role" : "user" , "content" : query })
model_output = generator ( model_input , max_new_tokens = 300 , top_k = 5 , top_p = 0.8 , temperature = 0.3 , repetition_penalty = 1.1 , do_sample = True )
print ( 'User:' , query )
print ( 'Model:' , model_output )Depende de Gradio, instalar con:
pip install gradio==4.29.0Inicie un servidor web con el siguiente código. Después de ingresar la dirección de acceso en el navegador, puede usar el modelo Index-1.9B-Chat para dialogar:
python demo/web_demo.py --port= ' port ' --model_path= ' /path/to/model/ ' Nota: Index-1.9B-32K solo se puede iniciar con esta herramienta: demo/cli_long_text_demo.py .
Inicie una demostración de terminal con el siguiente código para utilizar el modelo Index-1.9B-Chat para el diálogo:
python demo/cli_demo.py --model_path= ' /path/to/model/ 'Depende de Flask, instale con:
pip install flask==2.2.5Inicie una API de Flask con el siguiente código:
python demo/openai_demo.py --model_path= ' /path/to/model/ 'Puede realizar diálogos a través de la línea de comando:
curl http://127.0.0.1:8010/v1/chat/completions
-H " Content-Type: application/json "
-d ' {
"messages": [
{"role": "system", "content": "你是由哔哩哔哩自主研发的大语言模型,名为“Index”。你能够根据用户传入的信息,帮助用户完成指定的任务,并生成恰当的、符合要求的回复。"},
{"role": "user", "content": "花儿为什么这么红?"}
]
} 'Index-1.9B-32K es un modelo de lenguaje con solo 1,9 mil millones de parámetros, pero admite una longitud de contexto de 32K (lo que significa que este modelo extremadamente pequeño puede leer documentos de más de 35,000 palabras de una sola vez). El modelo se ha sometido a un entrenamiento previo continuo y a un ajuste fino supervisado (SFT) específicamente para textos de más de 32 000 tokens, basándose en datos de entrenamiento de texto largo cuidadosamente seleccionados y conjuntos de instrucciones de texto largo de construcción propia. El modelo ahora es de código abierto tanto en Hugging Face como en ModelScope.
A pesar de su pequeño tamaño (alrededor del 2% de modelos como GPT-4), Index-1.9B-32K demuestra excelentes capacidades de procesamiento de texto largo. Como se muestra en la siguiente figura, la puntuación de nuestro modelo de tamaño 1.9B incluso supera la del modelo de tamaño 7B. A continuación se muestra una comparación con modelos como GPT-4 y Qwen2:
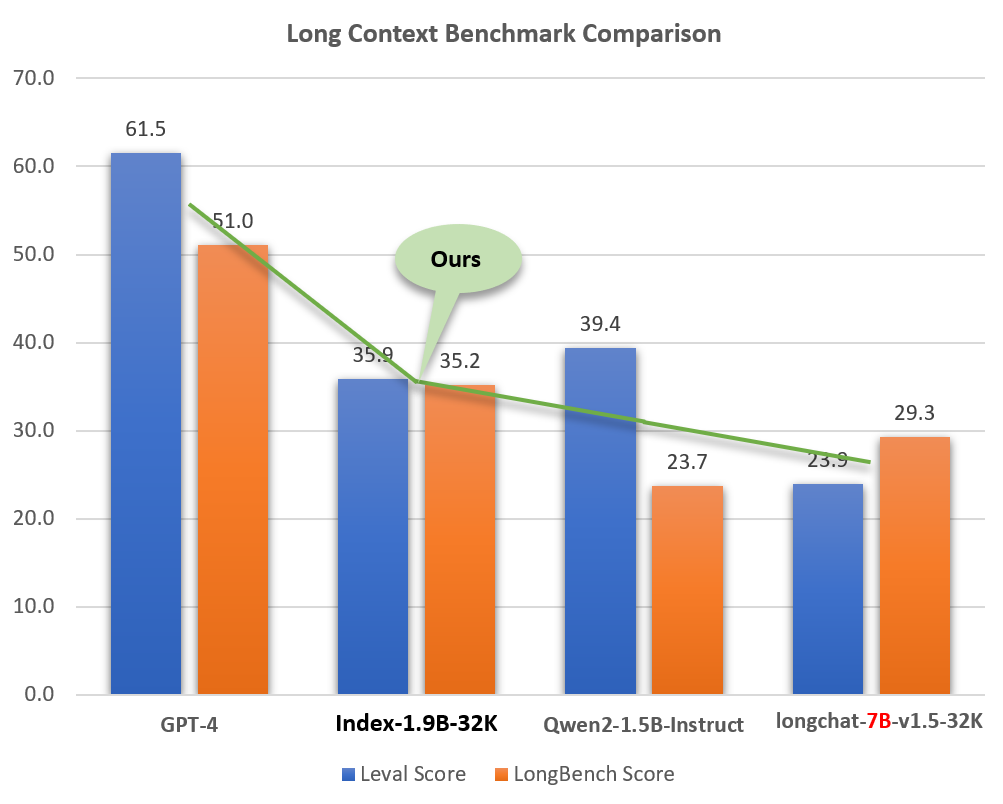
Comparación del Index-1.9B-32K con GPT-4, Qwen2 y otros modelos en capacidad de contexto largo
En una prueba de aguja en un pajar de 32K de longitud, Index-1.9B-32K logró excelentes resultados, como se muestra en la siguiente figura. La única excepción fue una pequeña mancha amarilla (91,08 puntos) en la región de (32K de longitud, 10% de profundidad), y todas las demás áreas tuvieron un desempeño excelente en zonas mayoritariamente verdes.
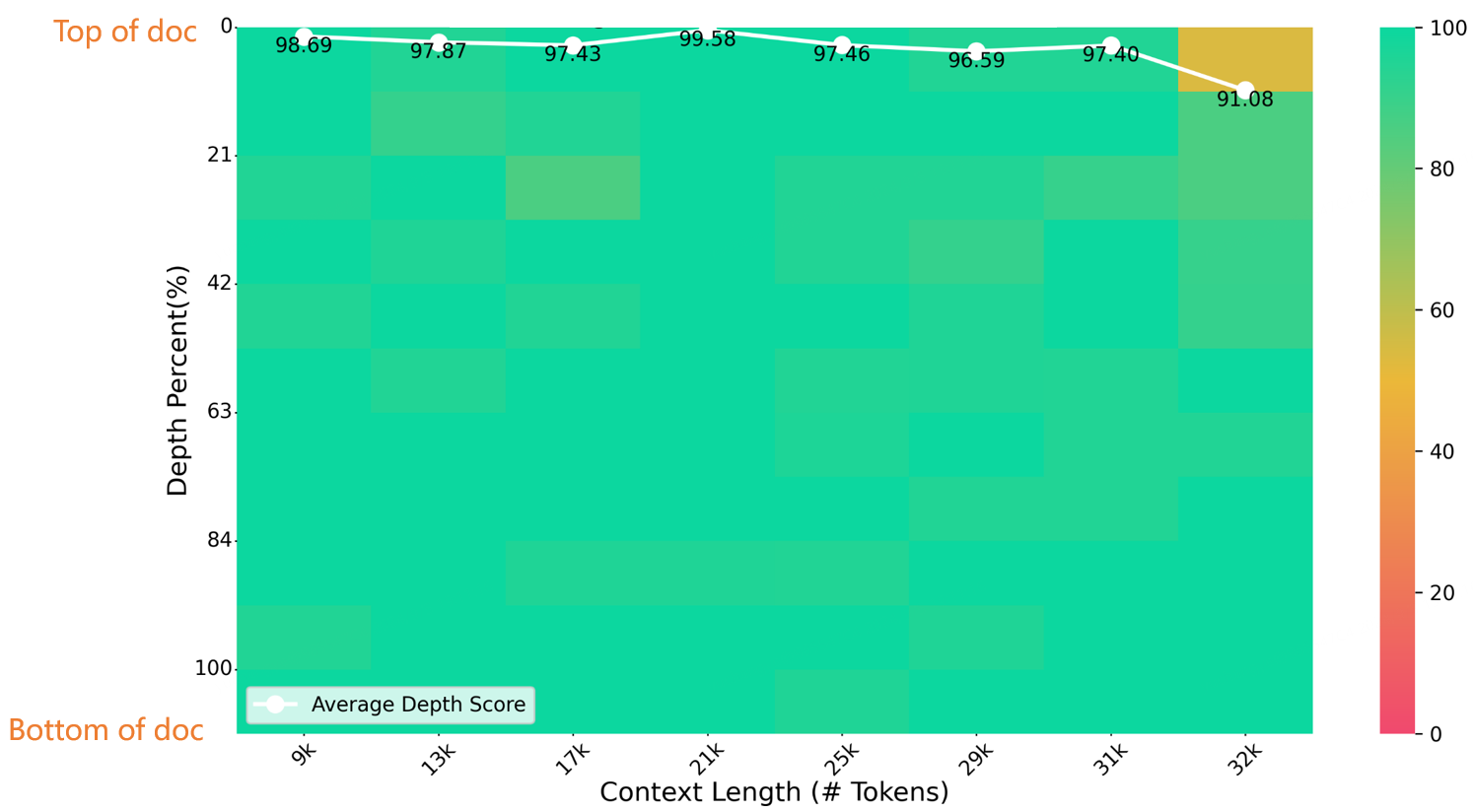
Evaluación del banco de agujas
Para obtener detalles sobre la descarga, el uso y el informe técnico del Index-1.9B-32K, consulte:
Informe técnico de contexto largo Index-1.9B-32Kweb_demo.py para obtener resultados de Index-1.9B-Chat. 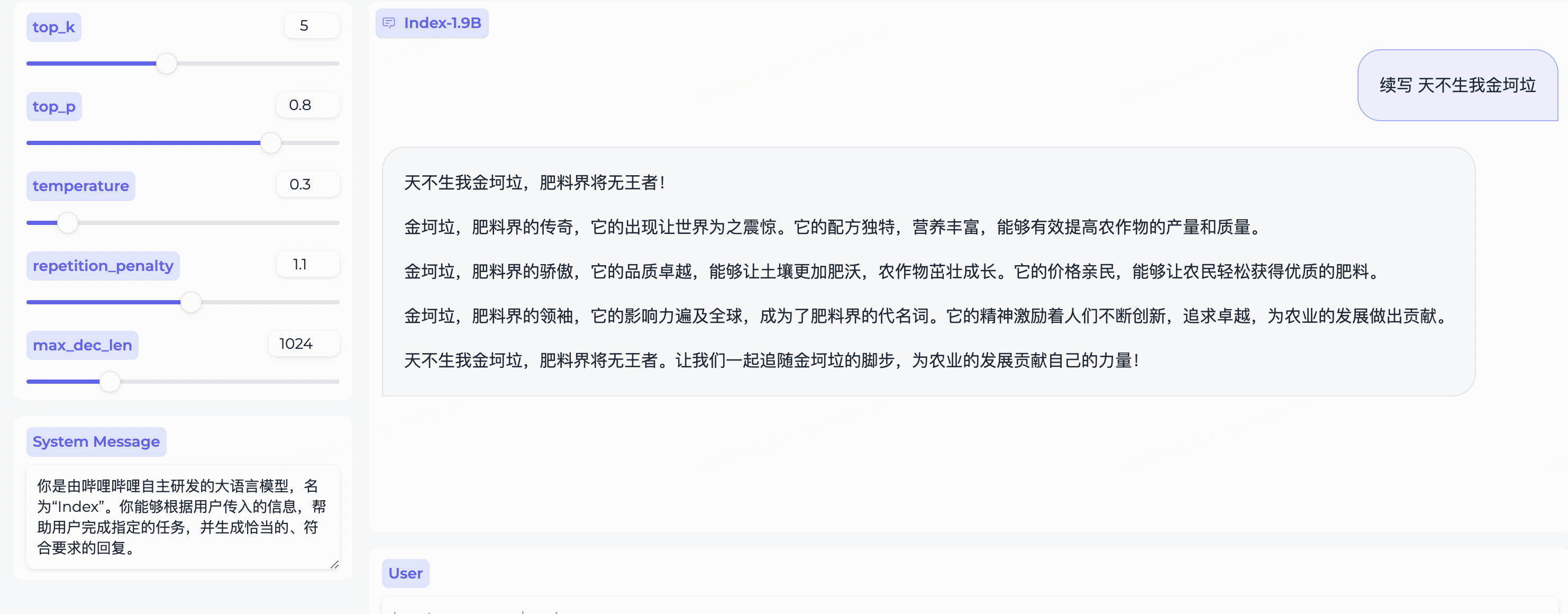
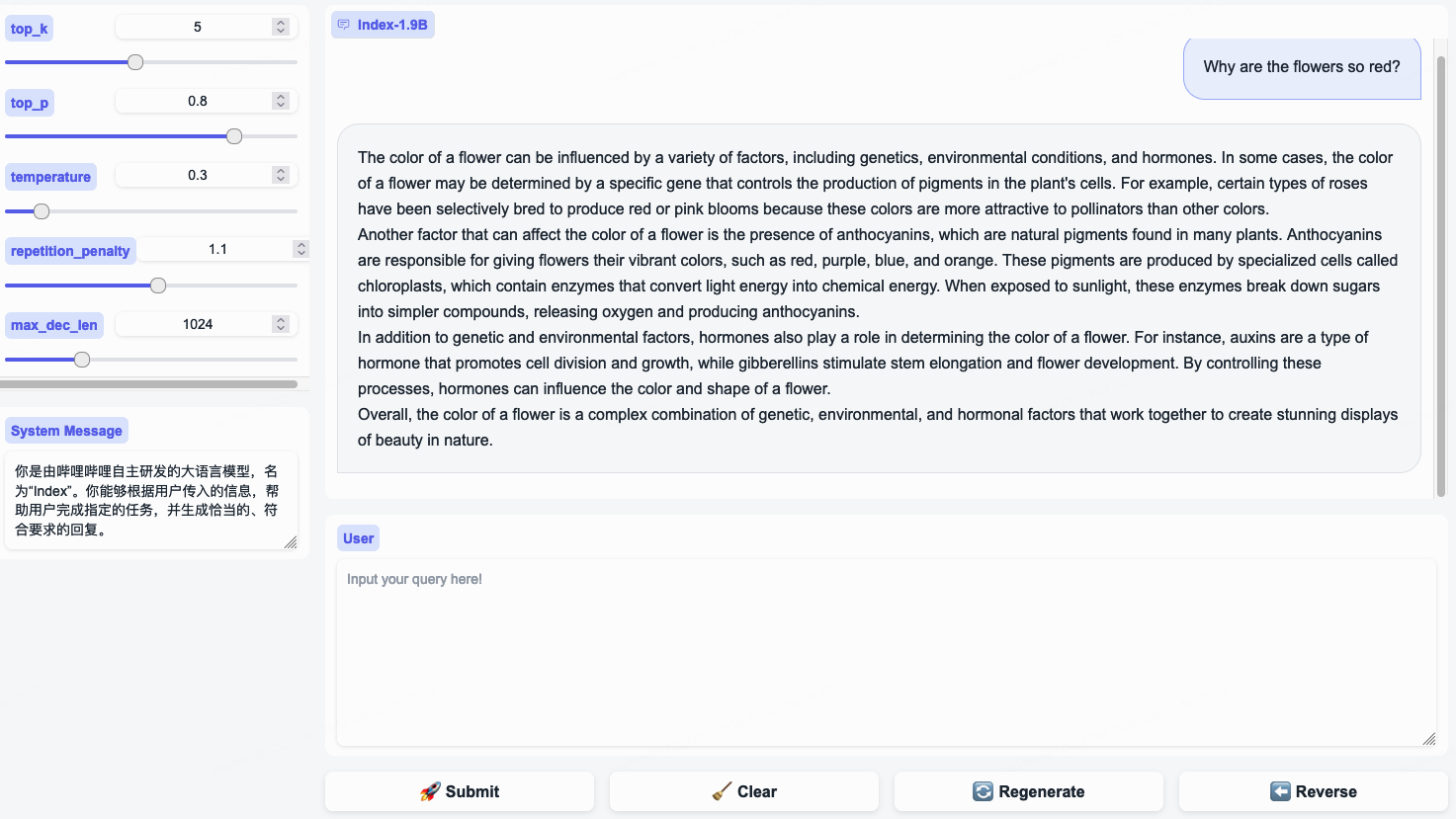
System Message para representar un estereotipo de usuario de bilibili! 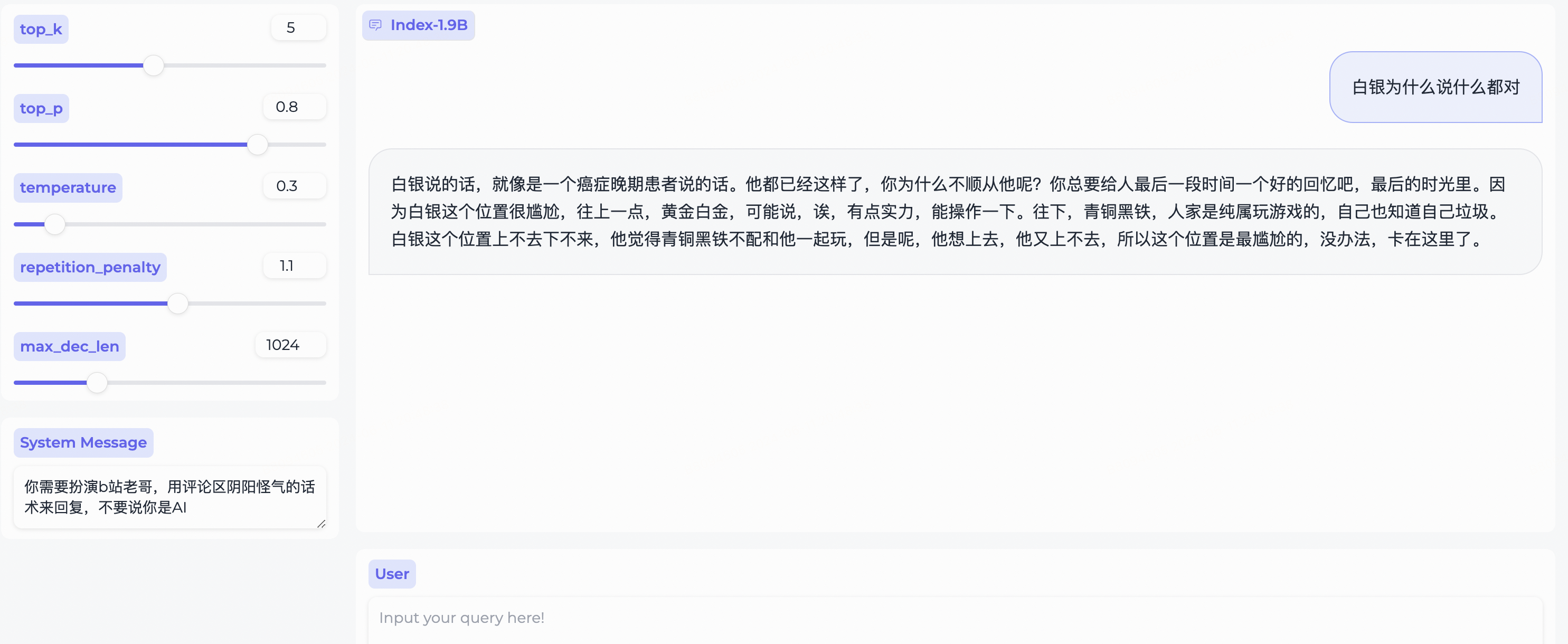
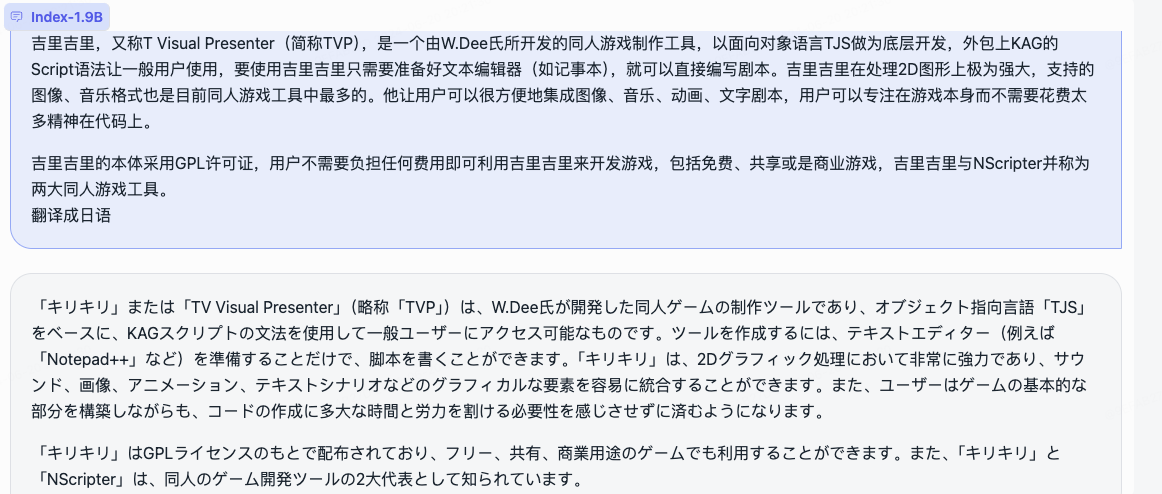
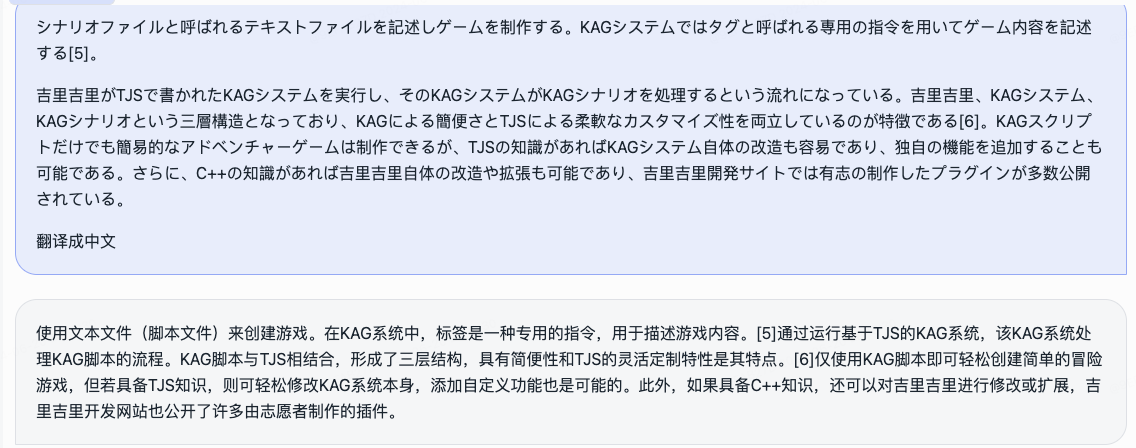
Simultáneamente hemos abierto el código abierto del modelo de juego de roles y el marco que lo acompaña. 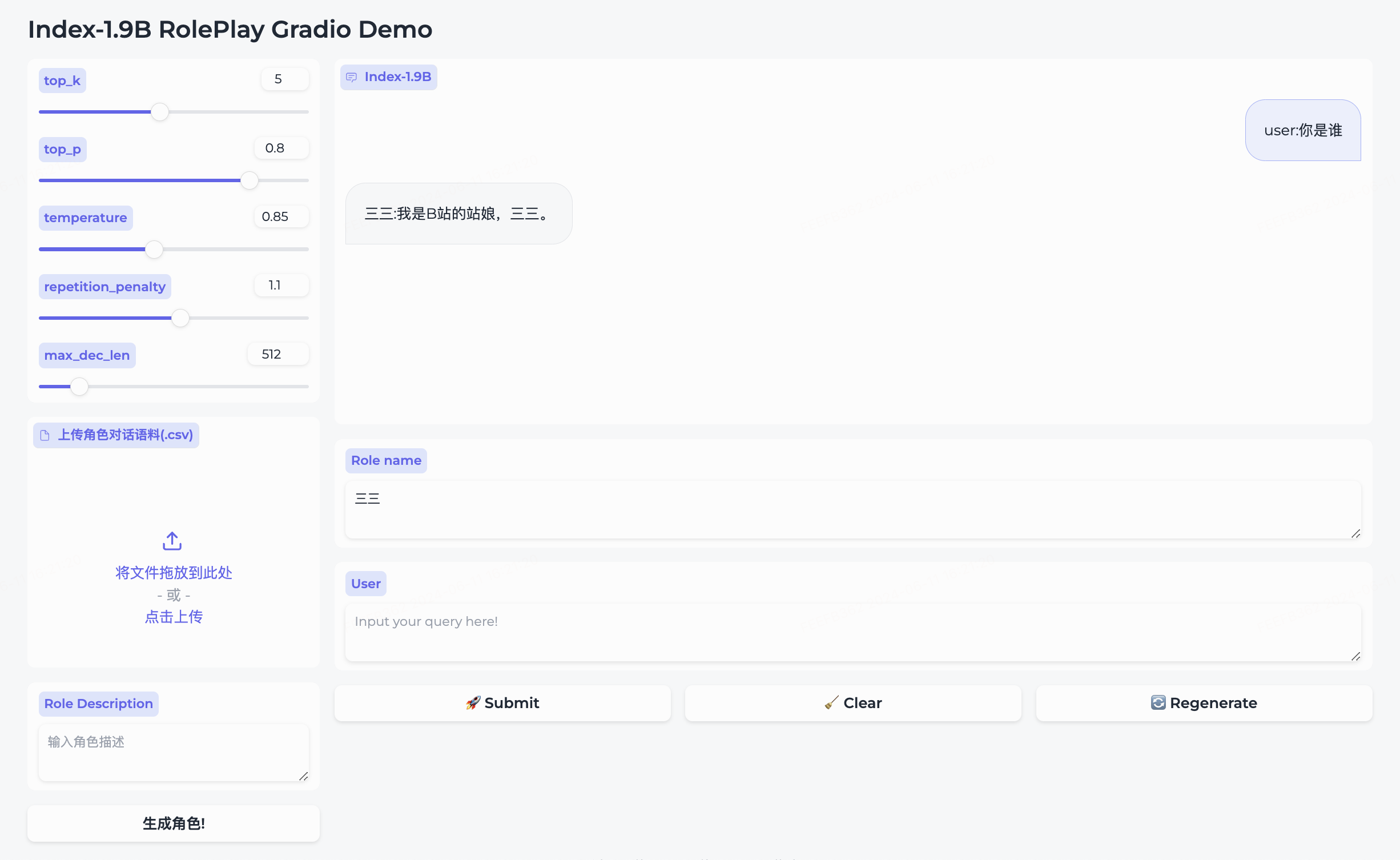
三三incorporado.生成角色para crearlo correctamente.Role name , ingrese su query y haga clic en submit para iniciar la conversación.Para un uso detallado, consulte la carpeta de juegos de rol.
cd demo/
CUDA_VISIBLE_DEVICES=0 python cli_long_text_demo.py --model_path ' /path/to/model/ ' --input_file_path data/user_long_text.txt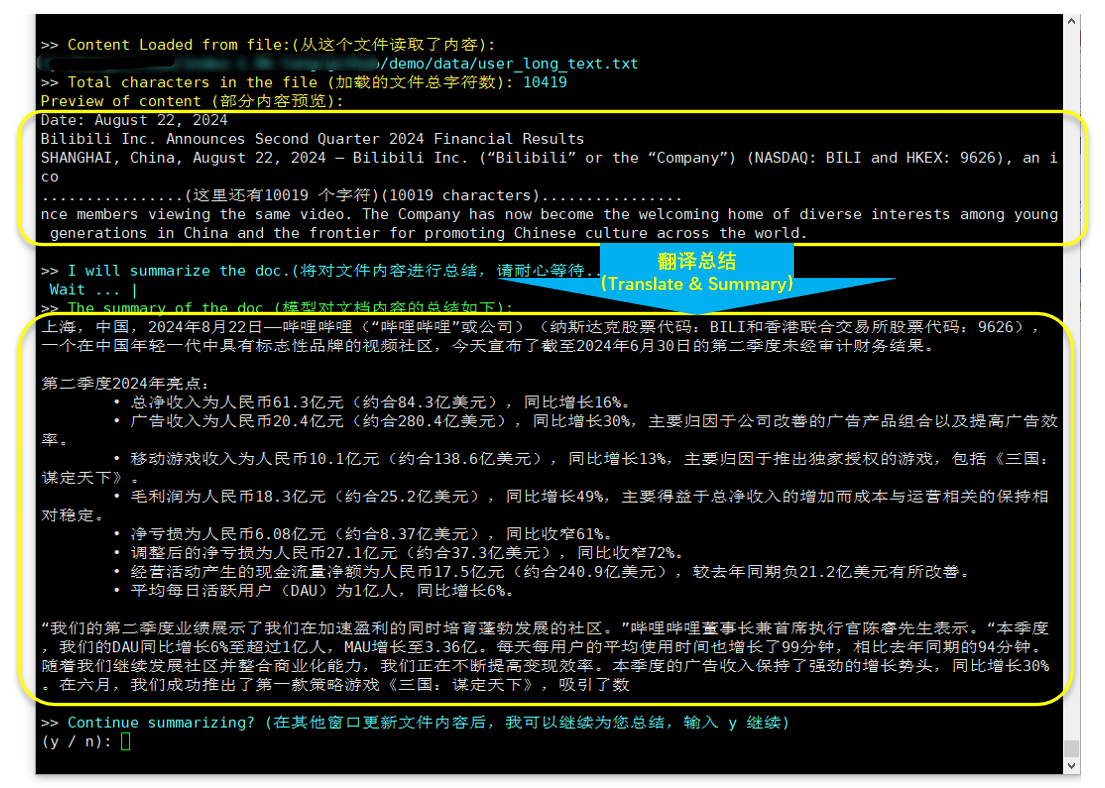
Traducción y resumen (informe financiero de Bilibili publicado el 22.8.2024)
Depende de bitsandbytes, comando de instalación:
pip install bitsandbytes==0.43.0Puede utilizar el siguiente script para realizar la cuantización int4, que tiene menos pérdida de rendimiento y ahorra aún más el uso de memoria de vídeo.
import torch
import argparse
from transformers import (
AutoModelForCausalLM ,
AutoTokenizer ,
TextIteratorStreamer ,
GenerationConfig ,
BitsAndBytesConfig
)
parser = argparse . ArgumentParser ()
parser . add_argument ( '--model_path' , default = "" , type = str , help = "" )
parser . add_argument ( '--save_model_path' , default = "" , type = str , help = "" )
args = parser . parse_args ()
tokenizer = AutoTokenizer . from_pretrained ( args . model_path , trust_remote_code = True )
quantization_config = BitsAndBytesConfig (
load_in_4bit = True ,
bnb_4bit_compute_dtype = torch . float16 ,
bnb_4bit_use_double_quant = True ,
bnb_4bit_quant_type = "nf4" ,
llm_int8_threshold = 6.0 ,
llm_int8_has_fp16_weight = False ,
)
model = AutoModelForCausalLM . from_pretrained ( args . model_path ,
device_map = "auto" ,
torch_dtype = torch . float16 ,
quantization_config = quantization_config ,
trust_remote_code = True )
model . save_pretrained ( args . save_model_path )
tokenizer . save_pretrained ( args . save_model_path )Siga los pasos del tutorial de ajuste para ajustar rápidamente el modelo Index-1.9B-Chat. ¡Pruébalo y personaliza tu modelo Index exclusivo!
Index-1.9B puede generar contenido inexacto, sesgado o de otro modo objetable en determinadas situaciones. El modelo no puede comprender, expresar opiniones personales ni emitir juicios de valor. Sus resultados no representan las opiniones ni posiciones de los desarrolladores del modelo. Por lo tanto, utilice el contenido generado con precaución. Los usuarios deben evaluar y verificar de forma independiente el contenido generado por el modelo y no deben difundir contenido dañino. Los desarrolladores deben realizar pruebas de seguridad y ajustes de acuerdo con aplicaciones específicas antes de implementar cualquier aplicación relacionada.
Recomendamos encarecidamente no utilizar estos modelos para crear o difundir información dañina o participar en actividades que puedan dañar la seguridad pública, nacional o social o violar las regulaciones. No utilice los modelos para servicios de Internet sin una revisión y archivo de seguridad adecuados. Hemos hecho todo lo posible para garantizar la conformidad de los datos de capacitación, pero debido a la complejidad del modelo y los datos, es posible que aún existan problemas imprevistos. No seremos responsables de ningún problema que surja del uso de estos modelos, ya sea relacionado con la seguridad de los datos, riesgos para la opinión pública o cualquier riesgo y problema causado por malentendidos, mal uso, difusión o uso no conforme del modelo.
El uso del código fuente de este repositorio requiere el cumplimiento de Apache-2.0. El uso de las ponderaciones del modelo Index-1.9B requiere el cumplimiento de INDEX_MODEL_LICENSE.
Las ponderaciones del modelo Index-1.9B están completamente abiertas a la investigación académica y admiten el uso comercial gratuito .
Si cree que nuestro trabajo es útil para usted, ¡no dude en citarlo!
@article{Index,
title={Index1.9B Technical Report},
year={2024}
}
libllm: https://github.com/ling0322/libllm/blob/main/examples/python/run_bilibili_index.py
chatllm.cpp: https://github.com/foldl/chatllm.cpp/blob/master/docs/rag.md#role-play-with-rag
ollama: https://ollama.com/milkey/bilibili-index
autollm: https://github.com/datawhalechina/self-llm/blob/master/bilibili_Index-1.9B/04-Index-1.9B-Chat%20Lora%20微调.md


