gptty
0.2.7
Envoltorio ChatGPT en su TTY
Nota
¡Esta versión es compatible con gpt4 y gpt4-turbo!
gptty es una interfaz de shell de ChatGPT que le permite (1) interactuar con ChatGPT de manera similar a la aplicación web, pero sin necesidad de depender de la estabilidad de la aplicación web; (2) preservar el contexto en las sesiones de chat y estructurar tus conversaciones como quieras; (3) guarde copias locales de sus conversaciones para consultarlas fácilmente.
Quizás usted sea un administrador de sistemas que esté configurando un servidor web para su empleador. Está accediendo al sistema desde una interfaz física, con conexión a Internet pero sin entorno de escritorio ni interfaz gráfica de usuario. Mientras configura el servidor web, recibe un error inexplicable que lo redirige a un archivo, pero no quiere tener que pasar por obstáculos para copiarlo a otro sistema con un navegador para poder buscar el error. En su lugar, instala gptty y redirige el error al cliente de chat con comandos como gptty query --tag error --question "$(cat app.error | tr 'n' ' ')" (que eliminará los saltos de línea para ti) o cat app.error | xargs -d 'n' -I {} gptty query --tag error --question "{}" (que supone que su error abarca solo una línea).
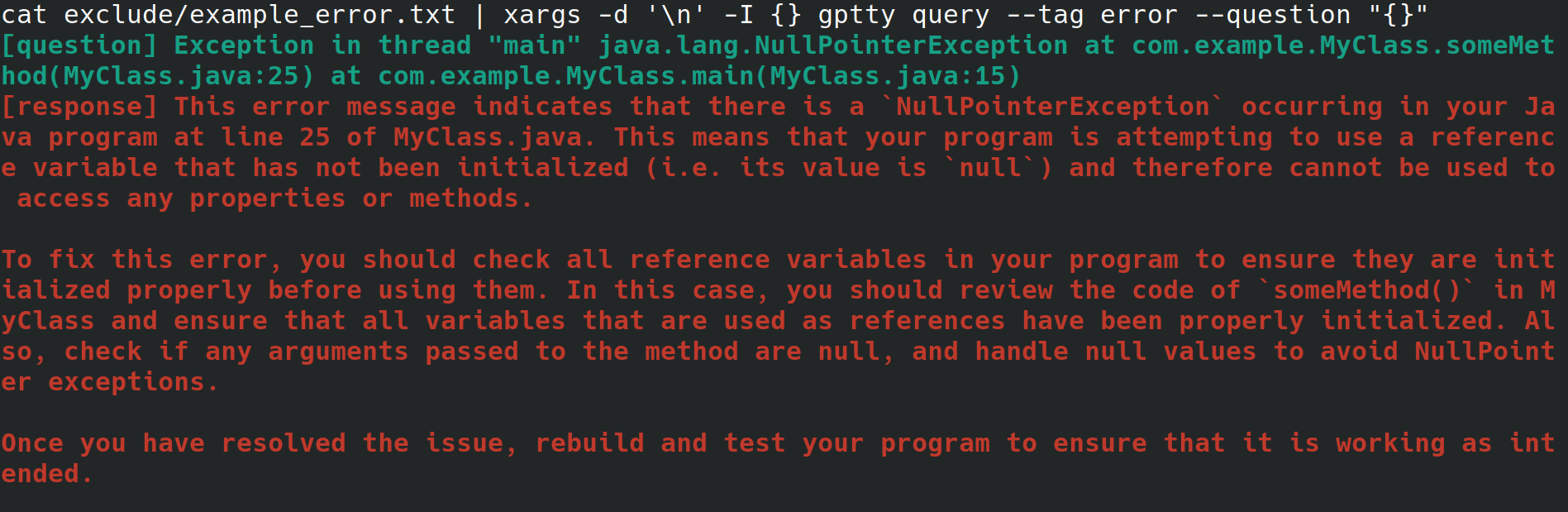
Alternativamente, usted es un desarrollador de software o un científico de datos que desea canalizar datos a través de ChatGPT, pero quiere emplear una API altamente abstracta para realizar estas solicitudes en lugar de familiarizarse íntimamente con la API OpenAI y sus diversos envoltorios específicos de idiomas. Cuando desee actualizar su base de código para usar un modelo diferente, deberá poder modificar un único archivo de configuración y esperar que el formato de respuesta de la consulta permanezca consistente en varios modelos.
O tal vez sea un entusiasta que quiera conservar copias locales de sus conversaciones o quiera ejercer un control más directo sobre los métodos de categorización que emplea para estas conversaciones.
OpenAI pone a disposición varios modelos a través de su API. [1] Actualmente, gptty admite Completions (davinci, curie) y ChatCompletions (gpt-3.5-turbo, gpt-4). Todo lo que necesita hacer es especificar el nombre del modelo en su configuración (el valor predeterminado es text-davinci-003) y la aplicación se encargará del resto.
Puedes instalar gptty en pip:
pip install gptty
También puedes instalar desde git:
cd ~/Code # replace this with whatever directory you want to use
git clone https://github.com/signebedi/gptty.git
cd gptty/
# now install the requirements
python3 -m venv venv
source venv/bin/activate
pip install -e .
Ahora puedes verificar que funciona ejecutando gptty --help . Si experimenta un error, intente configurar la aplicación.
gptty lee los ajustes de configuración de un archivo llamado gptty.ini , que la aplicación espera que esté ubicado en el mismo directorio desde el que ejecuta gptty , a menos que pase un config_file personalizado. El archivo utiliza el formato de archivo INI, que consta de secciones, cada una con sus propios pares clave-valor.
| Llave | Tipo | Valor predeterminado | Descripción |
|---|---|---|---|
| api_key | Cadena | "" | Su clave API para el servicio GPT de OpenAI |
| id_org | Cadena | "" | El ID de su organización para el servicio GPT de OpenAI |
| Su nombre | Cadena | "pregunta" | El nombre del mensaje de entrada. |
| nombre_gpt | Cadena | "respuesta" | El nombre de la respuesta generada. |
| archivo_salida | Cadena | "salida.txt" | El nombre del archivo donde se guardará la salida. |
| modelo | Cadena | "texto-davinci-003" | El nombre del modelo GPT a utilizar. |
| temperatura | Flotar | 0.0 | La temperatura a utilizar para el muestreo. |
| tokens_max | Entero | 250 | El número máximo de tokens a generar para la respuesta. |
| longitud_contexto_max | Entero | 150 | La longitud máxima del contexto de entrada. |
| contexto_palabras_clave_solo | booleano | Verdadero | Tokenizar palabras clave para reducir el uso de API |
| preservar_nuevas_líneas | booleano | FALSO | Mantener el formato original de la respuesta. |
| verificar_internet_endpoint | Cadena | "google.com" | Dirección para validar conexión a internet |
Puede modificar la configuración en el archivo de configuración para adaptarla a sus necesidades. Si una clave no está presente en el archivo de configuración, se utilizará el valor predeterminado. La sección [principal] se utiliza para especificar la configuración del programa.
[main]
api_key =my_api_key Este repositorio proporciona un archivo de configuración de muestra assets/gptty.ini.example que puede utilizar como punto de partida.
La función de chat proporciona una interfaz de chat interactiva para comunicarse con ChatGPT. Puede hacer preguntas y recibir respuestas en tiempo real.
Para iniciar la interfaz de chat, ejecute gptty chat . También puede especificar una ruta de archivo de configuración personalizada ejecutando:
gptty chat --config_path /path/to/your/gptty.ini
Dentro de la interfaz de chat, puedes escribir tus preguntas o comandos directamente. Para ver la lista de comandos disponibles, escriba :help , que mostrará las siguientes opciones.
| Metacomando | Descripción |
|---|---|
| :ayuda | Muestra una lista de comandos disponibles y sus descripciones. |
| :abandonar | Salga de ChatGPT. |
| : registros | Muestra los ajustes de configuración actuales. |
| : contexto [a: b] | Muestra el historial de contexto, especificando opcionalmente un rango a y b. En desarrollo |
Para usar un comando, simplemente escríbalo en el símbolo del sistema y presione Entrar. Por ejemplo, utilice el siguiente comando para mostrar los ajustes de configuración actuales en la terminal:
> :configs
api_key: SOME_KEY_HERE
org_id: org-SOME_CHARS_HERE
your_name: question
gpt_name: response
output_file: output.txt
model: text-davinci-003
temperature: 0.0
max_tokens: 250
max_context_length: 5000
Puede escribir una pregunta en el mensaje en cualquier momento y generará una respuesta para usted. Si desea compartir contexto entre consultas, consulte la sección de contexto a continuación.
La función de consulta le permite enviar una o varias preguntas a ChatGPT y recibir las respuestas directamente en la línea de comando.
Para utilizar la función de consulta, ejecute algo como:
gptty query --question "What is the capital of France?" --question "What is the largest mammal?"
También puede proporcionar una etiqueta opcional para categorizar su consulta:
gptty query --question "What is the capital of France?" --tag "geography"
Puede especificar una ruta de archivo de configuración personalizada si es necesario:
gptty query --config_path /path/to/your/gptty.ini --question "What is the capital of France?"
Recuerde que gptty utiliza un archivo de configuración (por defecto gptty.ini) para almacenar configuraciones como claves API, configuraciones de modelos y rutas de archivos de salida. Asegúrese de tener un archivo de configuración válido antes de ejecutar los comandos gptty.
Al agregar la etiqueta --verbose al final de su chat y de los comandos de consulta, la aplicación proporcionará datos de depuración adicionales, incluido el recuento de tokens para cada solicitud. Esto puede resultar útil cuando necesita realizar un seguimiento de las tasas de uso de API.

Al agregar la opción --additional_context [some_string_here] a sus comandos de consulta, la aplicación agregará cualquier cadena que pase como contexto externo adicional para su pregunta.
Al agregar la etiqueta --json al final de los comandos de consulta, la aplicación omitirá la escritura de texto legible por humanos en la salida estándar y, en su lugar, escribirá las preguntas y respuestas como objetos json como [{"question":QUESTION_1, "response":RESPONSE_1},{"question":QUESTION_1, "response":RESPONSE_1},...] .

Al agregar la etiqueta --quiet al final de sus comandos de consulta, la aplicación omitirá escribir nada en la salida estándar, pero aún escribirá respuestas en el output_file designado en el archivo de configuración de la aplicación.
Etiquetar texto para contexto al usar los subcomandos query y chat en esta aplicación puede ayudar a mejorar la precisión de las respuestas generadas. Así es como la aplicación maneja el contexto con el subcomando chat :
bananas o shakespeare .[tag] . Por ejemplo, si el contexto de tu pregunta es "cocina", puedes etiquetarla como [cooking] . Asegúrese de utilizar la misma etiqueta de forma constante para todas las consultas relacionadas. A continuación se muestra un ejemplo de cómo se vería esto, utilizando preguntas etiquetadas como [shakespeare] . Observe cómo, en la segunda pregunta, el nombre 'William Shakespeare' no se menciona en absoluto.
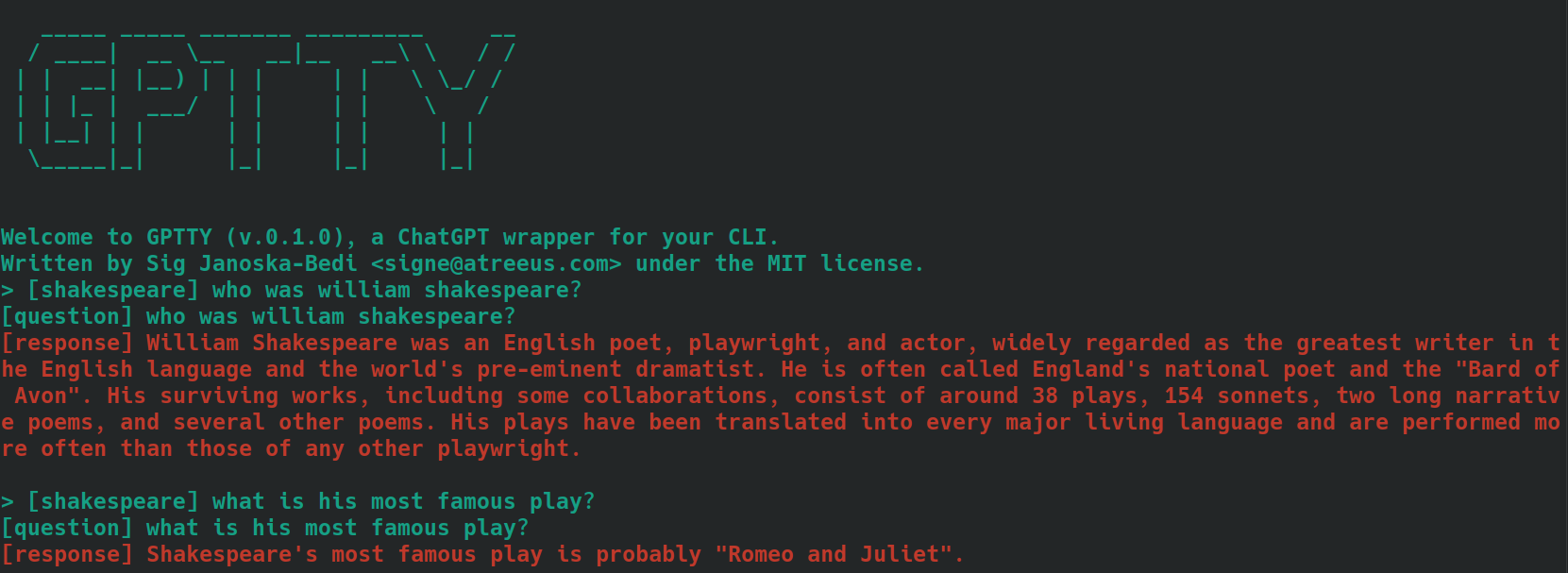
Cuando utilice el subcomando query , siga los mismos pasos descritos anteriormente pero, en lugar de anteponer el texto de sus preguntas con la etiqueta deseada, use la opción --tag para incluir la etiqueta al enviar su consulta. Por ejemplo, si el contexto de tu pregunta es "cocina", puedes utilizar:
gptty --question "some question" --tag cooking
La aplicación guardará su pregunta y respuesta etiquetadas en el archivo de salida especificado en el archivo de configuración.
Puede automatizar el proceso de envío de varias preguntas al comando gptty query utilizando un script bash. Esto puede resultar especialmente útil si tiene una lista de preguntas almacenadas en un archivo y desea procesarlas todas a la vez. Por ejemplo, digamos que tiene un archivo questions.txt con cada pregunta en una nueva línea, como se muestra a continuación.
What are the key differences between machine learning, deep learning, and artificial intelligence?
How do I choose the best programming language for a specific project or task?
Can you recommend some best practices for code optimization and performance improvement?
What are the essential principles of good software design and architecture?
How do I get started with natural language processing and text analysis in Python?
What are some popular Python libraries or frameworks for building web applications?
Can you suggest some resources to learn about data visualization and its implementation in Python?
What are some important concepts in cybersecurity, and how can I apply them to my projects?
How do I ensure that my machine learning models are fair, ethical, and unbiased?
Can you recommend strategies for staying up-to-date with the latest trends and advancements in technology and programming?
Puede enviar cada pregunta desde el archivo questions.txt al comando gptty query usando el siguiente resumen de bash:
xargs -d ' n ' -I {} gptty query --question " {} " < questions.txt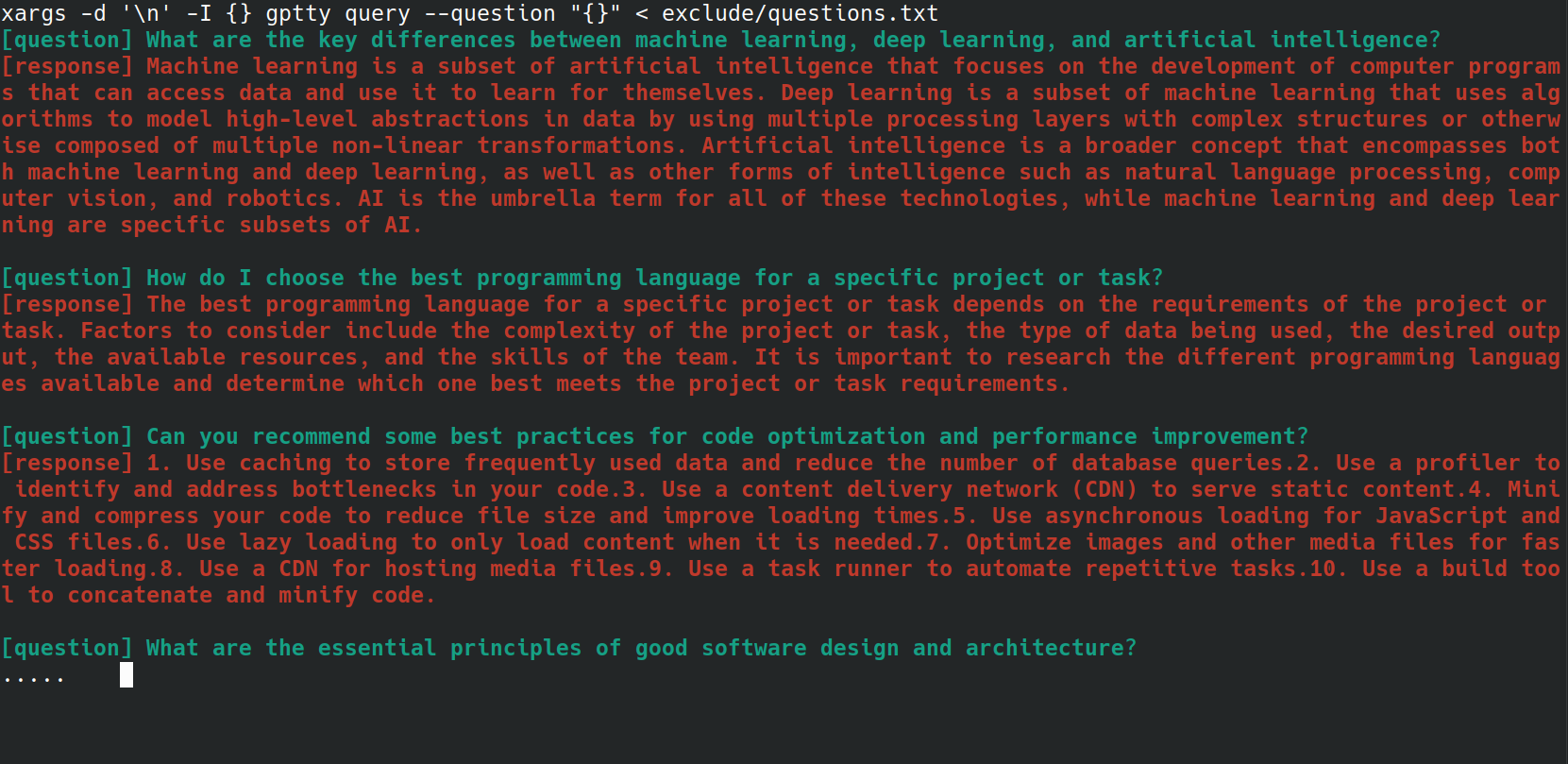
La clase UniversalCompletion proporciona una interfaz unificada para interactuar con los modelos de lenguaje de OpenAI, (principalmente) abstrayendo los detalles de si la aplicación está usando el modo Finalización o ChatCompletion. La idea principal es facilitar la creación, configuración y gestión de los modelos de lenguaje. A continuación se muestran algunos ejemplos de uso.
# First, import the UniversalCompletion class from the gptty library.
from gptty import UniversalCompletion
# Now, we instantiate a new UniversalCompletion object.
# The 'api_key' parameter is your OpenAI API key, which you get when you sign up for the API.
# The 'org_id' parameter is your OpenAI organization ID, which is also provided when you sign up.
g = UniversalCompletion ( api_key = "sk-SOME_CHARS_HERE" , org_id = "org-SOME_CHARS_HERE" )
# This connects to the OpenAI API using the provided API key and organization ID.
g . connect ()
# Now we specify which language model we want to use.
# Here, 'gpt-3.5-turbo' is specified, which is a version of the GPT-3 model.
g . set_model ( 'gpt-3.5-turbo' )
# This method is used to verify the model type.
# It returns a string that represents the endpoint for the current model in use.
g . validate_model_type ( g . model ) # Returns: 'v1/chat/completions'
# We send a request to the language model here.
# The prompt is a question, given in a format that the model understands.
# The model responds with a completion - an extension of the prompt based on what it has learned during training.
# The returned object is a representation of the response from the model.
g . fetch_response ( prompt = [{ "role" : "user" , "content" : "What is an abstraction?" }])
# Returns a JSON response with the assistant's message.

