thumb
1.0.0
Una biblioteca de pruebas sencilla y rápida para LLM.
pip install thumb
import os
import thumb
# Set your API key: https://platform.openai.com/account/api-keys
os . environ [ "OPENAI_API_KEY" ] = "YOUR_API_KEY_HERE"
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ])Cada mensaje se ejecuta 10 veces de forma asincrónica de forma predeterminada, lo que es aproximadamente 9 veces más rápido que ejecutarlos de forma secuencial. En Jupyter Notebooks se muestra una interfaz de usuario sencilla para las respuestas de calificación ciega (no se ve qué mensaje generó la respuesta).
Una vez que se hayan calificado todas las respuestas, se calculan las siguientes estadísticas de rendimiento desglosadas por plantilla de mensaje:
avg_score cantidad de comentarios positivos como porcentaje de todas las ejecucionesavg_tokens : cuántos tokens se utilizaron en el mensaje y la respuestaavg_cost : una estimación de cuánto cuesta ejecutar el aviso en promedio Se muestra un informe simple en el cuaderno y los datos completos se guardan en un archivo CSV thumb/ThumbTest-{TestID}.csv .

Los casos de prueba ocurren cuando desea probar una plantilla de solicitud con diferentes variables de entrada. Por ejemplo, si desea probar una plantilla de mensaje que incluye una variable para el nombre de un comediante, puede configurar casos de prueba para diferentes comediantes.
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke in the style of {comedian}"
prompt_b = "tell me a family friendly joke in the style of {comedian}"
# set test cases with different input variables
cases = [
{ "comedian" : "chris rock" },
{ "comedian" : "ricky gervais" },
{ "comedian" : "robin williams" }
]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )Cada caso de prueba se ejecutará en cada plantilla de solicitud, por lo que en este ejemplo obtendrá 6 combinaciones (3 casos de prueba x 2 plantillas de solicitud), cada una de las cuales se ejecutará 10 veces (60 llamadas en total a OpenAI). Cada caso de prueba debe incluir un valor para cada variable en la plantilla de solicitud.
Las indicaciones pueden tener múltiples variables en cada caso de prueba. Por ejemplo, si desea probar una plantilla de mensaje que incluye una variable para el nombre de un comediante y un tema de chiste, puede configurar casos de prueba para diferentes comediantes y temas.
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke about {subject} in the style of {comedian}"
prompt_b = "tell me a family friendly joke about {subject} in the style of {comedian}"
# set test cases with different input variables
cases = [
{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "joe biden" , "comedian" : "ricky gervais" },
{ "subject" : "donald trump" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "ricky gervais" },
]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )Cada caso se prueba con cada indicación para obtener una comparación justa del rendimiento de cada indicación dados los mismos datos de entrada. Con 4 casos de prueba y 2 mensajes, obtendrá 8 combinaciones (4 casos de prueba x 2 plantillas de mensajes), cada una de las cuales se ejecutará 10 veces (80 llamadas en total a OpenAI).
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], models = [ "gpt-4" , "gpt-3.5-turbo" ])Esto ejecutará cada mensaje con cada modelo, para obtener una comparación justa del rendimiento de cada mensaje con los mismos datos de entrada. Con 2 mensajes y 2 modelos, obtendrá 4 combinaciones (2 mensajes x 2 modelos), cada una de las cuales se ejecutará 10 veces (40 llamadas en total a OpenAI).
# set up a prompt templates for the a/b test
system_message = "You are the comedian {comedian}"
prompt_a = [ system_message , "tell me a funny joke about {subject}" ]
prompt_b = [ system_message , "tell me a hillarious joke {subject}" ]
cases = [{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "chris rock" }]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases ) Las indicaciones pueden ser una cadena o una serie de cadenas. Si el mensaje es una matriz, la primera cadena se utiliza como mensaje del sistema y el resto de los mensajes alternan entre mensajes humanos y de asistente ( [system, human, ai, human, ai, ...] ). Esto es útil para probar indicaciones que incluyen un mensaje del sistema o que utilizan precalentamiento (insertando mensajes previos en el chat para guiar a la IA hacia el comportamiento deseado).
# set up a prompt templates for the a/b test
system_message = "You are the comedian {comedian}"
prompt_a = [ system_message , # system
"tell me a funny joke about {subject}" , # human
"Sorry, as an AI language model, I am not capable of humor" , # assistant
"That's fine just try your best" ] # human
prompt_b = [ system_message , # system
"tell me a hillarious joke about {subject}" , # human
"Sorry, as an AI language model, I am not capable of humor" , # assistant
"That's fine just try your best" ] # human
cases = [{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "chris rock" }]
# generate the responses
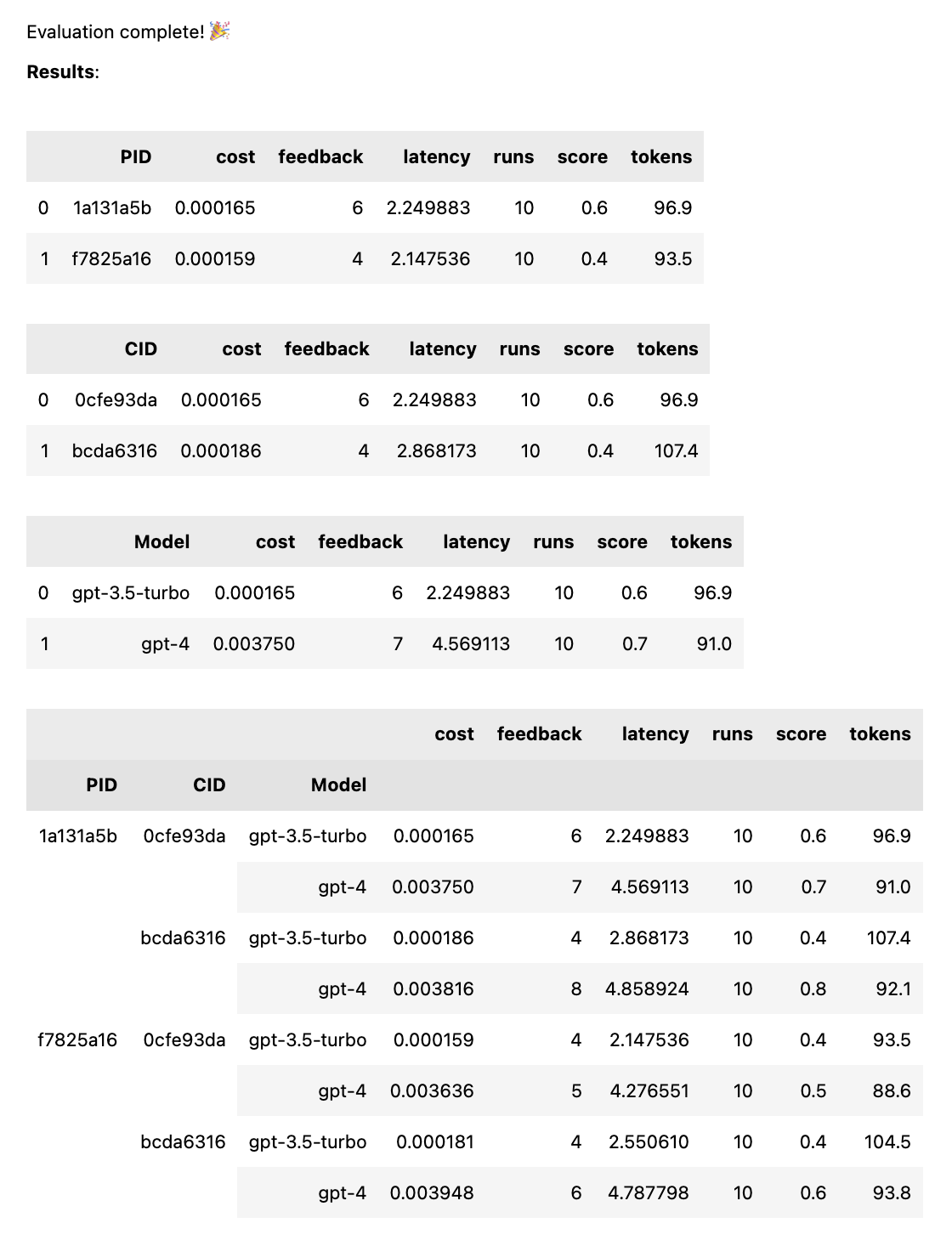
test = thumb . test ([ prompt_a , prompt_b ], cases )Cuando se completa la prueba, obtiene un informe de evaluación completo, desglosado por PID, CID y modelo, así como un informe general desglosado por todas las combinaciones. Si solo prueba un modelo o un caso, estas averías se eliminarán. El informe muestra una clave en la parte inferior para ver qué ID corresponde a qué mensaje o caso.
La función thumb.test toma los siguientes parámetros:
None )10 )gpt-3.5-turbo ])True ) Si tiene 10 ejecuciones de prueba con 2 plantillas de solicitud y 3 casos de prueba, son 10 x 2 x 3 = 60 llamadas a OpenAI. Tenga cuidado: ¡particularmente con GPT-4 los costos pueden aumentar rápidamente!
El seguimiento de Langchain a LangSmith se habilita automáticamente si LANGCHAIN_API_KEY se establece como una variable de entorno (opcional).
la función .test() devuelve un objeto ThumbTest . Puede agregar más indicaciones o casos a la prueba, o ejecutarla más veces. También puede generar, evaluar y exportar los datos de prueba en cualquier momento.
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ])
# add more prompts
test . add_prompts ([ "tell me a knock knock joke" , "tell me a knock knock joke about {subject}" ])
# add more cases
test . add_cases ([{ "subject" : "joe biden" }, { "subject" : "donald trump" }])
# run each prompt and case 5 more times
test . add_runs ( 5 )
# generate the responses
test . generate ()
# rate the responses
test . evaluate ()
# export the test data for analysis
test . export_to_csv () Cada plantilla de solicitud obtiene los mismos datos de entrada de cada caso de prueba, pero no es necesario que la solicitud utilice todas las variables del caso de prueba. Como en el ejemplo anterior, el mensaje tell me a knock knock joke no utiliza la variable subject , pero aún así se genera una vez (sin variables) para cada caso de prueba.
Los datos de prueba se almacenan en caché en un archivo JSON local thumb/.cache/{TestID}.json después de que se genera cada conjunto de ejecuciones para una combinación de solicitud y caso. Si su prueba se interrumpe o desea agregar algo más, puede usar la función thumb.load para cargar los datos de la prueba desde el caché.
# load a previous test
test_id = "abcd1234" # replace with your test id
test = thumb . load ( f"thumb/.cache/ { test_id } .json" )
# run each prompt and case 2 more times
test . add_runs ( 2 )
# generate the responses
test . generate ()
# rate the responses
test . evaluate ()
# export the test data for analysis
test . export_to_csv () Cada ejecución de cada combinación de mensaje y caso se almacena en el objeto (y en la caché) y, por lo tanto, volver a llamar a test.generate() no generará ninguna respuesta nueva si no se agregan más mensajes, casos o ejecuciones. De manera similar, volver a llamar test.evaluate() no volverá a calificar las respuestas que ya calificó y simplemente volverá a mostrar los resultados si la prueba ha finalizado.
La diferencia entre las personas que simplemente juegan con ChatGPT y aquellas que usan IA en producción es la evaluación. Los LLM responden de manera no determinista, por lo que es importante probar cómo se ven los resultados cuando se amplían a una amplia gama de escenarios. Sin un marco de evaluación, te quedarás adivinando ciegamente qué funciona (o no) en tus indicaciones.
Los ingenieros serios están probando y aprendiendo qué entradas conducen a resultados útiles o deseados, de manera confiable y a escala. Este proceso se llama optimización rápida y tiene este aspecto:
Las pruebas manuales llenan el vacío entre los mecanismos de evaluación profesional a gran escala y las indicaciones ciegas mediante prueba y error. Si está realizando la transición de un mensaje a un entorno de producción, usar thumb para probar su mensaje puede ayudarlo a detectar casos extremos y obtener comentarios tempranos de los usuarios o del equipo sobre los resultados.
Estas personas desarrollan thumb para divertirse en su tiempo libre. ?
martillo-mt |


