llm4data
v0.0.9
LLM4Data es una biblioteca de Python diseñada para facilitar la aplicación de grandes modelos de lenguaje (LLM) e inteligencia artificial para el desarrollo de datos y el descubrimiento de conocimientos. Su objetivo es capacitar a los usuarios y organizaciones para que descubran e interactúen con datos de desarrollo de maneras innovadoras a través del lenguaje natural.
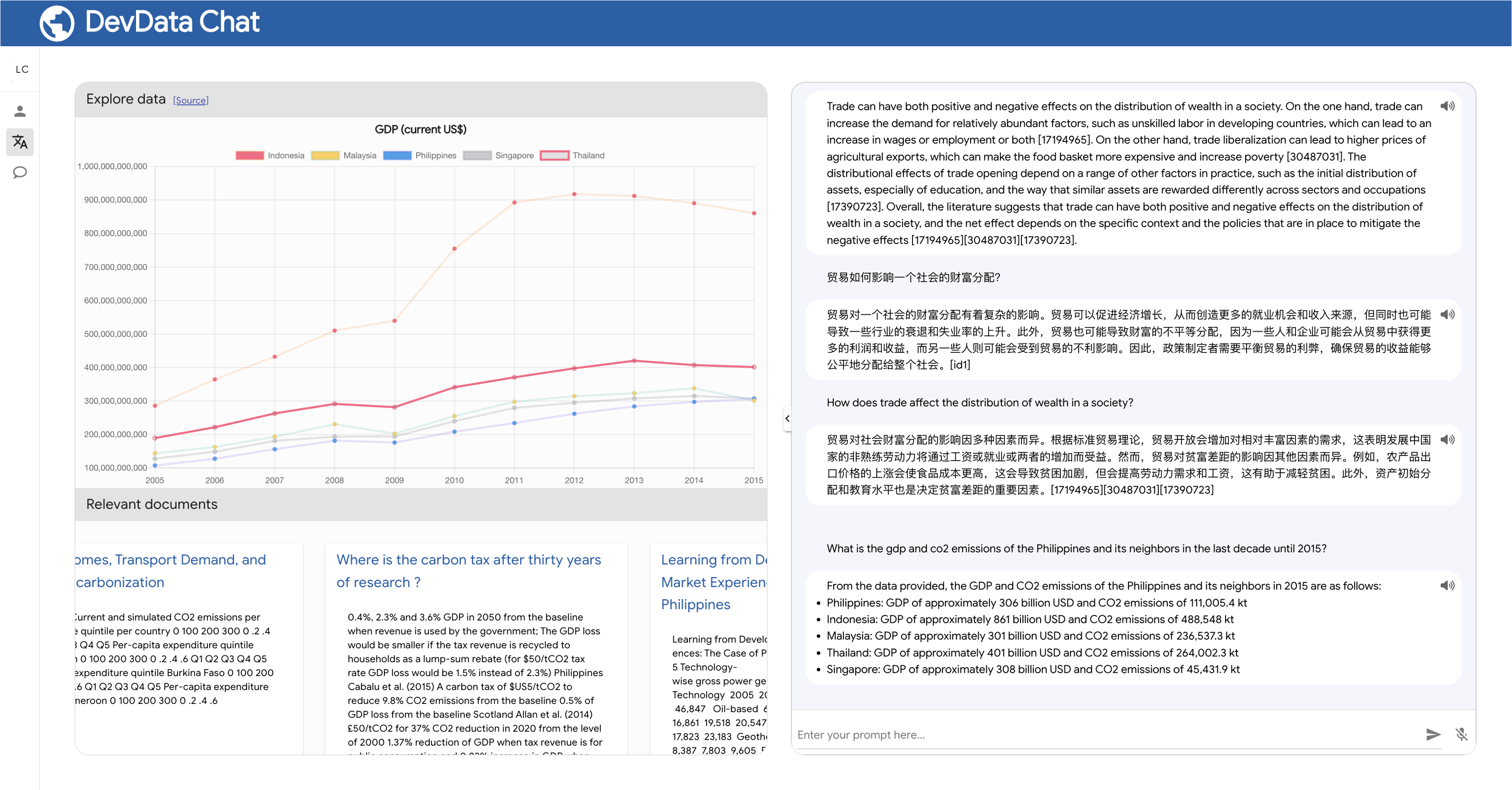
LLM4Data impulsa la aplicación DevData Chat, que pronto estará disponible como proyecto de código abierto. Esta aplicación demuestra las diversas formas en que el LLM (modelo de lenguaje) y la IA mejoran el descubrimiento y la interacción con datos y conocimientos, brindando soluciones innovadoras para ayudar a abordar las brechas de descubrimiento y accesibilidad.
La biblioteca LLM4Data contiene una colección de soluciones de descubrimiento y aumento de datos para varios tipos de datos, incluidos documentos, indicadores, microdatos, datos geoespaciales y más. La versión actual de la biblioteca incluye soluciones para los indicadores WDI. Se agregarán soluciones adicionales en versiones futuras.
Construidos en torno a esquemas y estándares de metadatos existentes, los usuarios y las organizaciones pueden beneficiarse de los LLM para mejorar las aplicaciones basadas en datos, permitiendo el procesamiento del lenguaje natural, la generación de texto y más con LLM4Data. La biblioteca sirve como puente entre los LLM y los datos de desarrollo utilizando bibliotecas de código abierto, ofreciendo una interfaz perfecta para aprovechar las capacidades de estos potentes modelos de lenguaje.
Utilice el pip del administrador de paquetes para instalar LLM4Data.
pip install llm4dataLos siguientes ejemplos demuestran cómo usar LLM4Data para generar URL de API WDI y consultas SQL a partir de mensajes.
Se pueden encontrar ejemplos adicionales aquí.
This example uses the OpenAI API. Before you proceed, make sure to set your API keys in the `.env` file. See the [setup instructions](https://worldbank.github.io/llm4data/notebooks/examples/getting-started/openai-api.html) for more details.
from llm4data . prompts . indicators import wdi
# Create a WDI API prompt object
wdi_api = wdi . WDIAPIPrompt ()
# Send a prompt to the LLM to get a WDI API URL relevant to the prompt
response = wdi_api . send_prompt (
"What is the gdp and the co2 emissions of the philippines and its neighbors in the last decade?"
)
# Parse the response to get the WDI API URL
wdi_api_url = wdi_api . parse_response ( response )
print ( wdi_api_url )El resultado será similar al siguiente:
https://api.worldbank.org/v2/country/PHL;IDN;MYS;SGP;THA;VNM/indicator/NY.GDP.MKTP.CD;EN.ATM.CO2E.KT?date=2013:2022&format=json&source=2
Observe que la URL generada ya incluye los códigos de país y los indicadores relevantes para el mensaje. Entiende qué países son vecinos de Filipinas. También comprende qué códigos de indicadores pueden proporcionar datos relevantes sobre el PIB y las emisiones de CO2.
La URL también incluye el intervalo de fechas, el formato y la fuente de los datos. Luego, el usuario puede modificar la URL según sea necesario y utilizarla para consultar la API de WDI.
Make sure you have set up your environment first. The example below requires a working database engine, e.g., postgresql. If you want to use SQLite, make sure to update the `.env` file and set the environment variables.
Si bien los datos WDI se pueden cargar en un marco de datos de Pandas, no siempre es práctico hacerlo; por ejemplo, desarrollar aplicaciones que puedan responder preguntas sobre datos arbitrarios.
La biblioteca LLM4Data incluye una interfaz SQL para datos WDI, lo que permite a los usuarios consultar los datos mediante SQL.
Esta interfaz permitirá a los usuarios consultar los datos utilizando SQL y devolver los resultados como un marco de datos de Pandas. La interfaz también permite a los usuarios consultar los datos mediante SQL y devolver los resultados como un objeto JSON.
import json
from llm4data . prompts . indicators import templates , wdi
from llm4data . llm . indicators import wdi_sql
prompt = "What is the GDP and army spending of the Philippines in 2020?"
sql_data = wdi_sql . WDISQL (). llm2sql_answer ( prompt , as_dict = True )
print ( sql_data )
# # {'sql': "SELECT country, value AS gdp, (SELECT value FROM wdi WHERE country_iso3 = 'PHL' AND indicator = 'MS.MIL.XPND.GD.ZS' AND year = 2020) AS army_spending FROM wdi WHERE country_iso3 = 'PHL' AND indicator = 'NY.GDP.MKTP.CD' AND year = 2020 AND value IS NOT NULL",
# # 'params': {},
# # 'data': {'data': [{'country': 'Philippines',
# # 'gdp': 361751116292.541,
# # 'army_spending': 1.01242392260698}],
# # 'sample': [{'country': 'Philippines',
# # 'gdp': 361751116292.541,
# # 'army_spending': 1.01242392260698}]},
# # 'num_samples': 20}La biblioteca LLM4Data también incluye soporte para generar explicaciones narrativas de respuestas a consultas SQL. Esto es útil para generar descripciones de datos en lenguaje natural, que pueden usarse para proporcionar contexto a los usuarios y explicar los resultados de las consultas de datos.
from llm4data . prompts . indicators import templates
# Send the prompt to the LLM for a narrative explanation of the response.
# This is optional and can be skipped.
# Note that we pass only a sample in the `context_data`.
# This could limit the quality of the response.
# This is a limitation of the current version of the LLM which is constrained by the context length and cost.
explainer = templates . IndicatorPrompt ()
description = explainer . send_prompt ( prompt = prompt , context_data = json . dumps ( sql_data [ "data" ][ "sample" ]))
print ( description [ "content" ])
# # Based on the data provided, the GDP of the Philippines in 2020 was approximately 362 billion USD. Meanwhile, the country's army spending in the same year was around 1.01 billion USD. It is worth noting that while army spending is an important aspect of a country's budget, it is not the only factor that contributes to its economic growth and development. Other factors such as infrastructure, education, and healthcare also play a crucial role in shaping a country's economy. Langchain es una gran biblioteca y tiene un contenedor para bases de datos SQL que le permite consultarlas utilizando lenguaje natural. El contenedor se llama SQLDatabaseChain y se puede utilizar de la siguiente manera:
from langchain import OpenAI , SQLDatabase , SQLDatabaseChain
db = SQLDatabase . from_uri ( "sqlite:///../llm4dev/data/sqldb/wdi.db" )
llm = OpenAI ( temperature = 0 , verbose = True )
db_chain = SQLDatabaseChain . from_llm ( llm , db , verbose = True , return_intermediate_steps = True )
out = db_chain ( "What is the GDP and army spending of the Philippines in 2020?" ) > Entering new SQLDatabaseChain chain...
What is the GDP and army spending of the Philippines in 2020 ?
SQLQuery:SELECT " value " FROM wdi WHERE " name " = ' GDP (current US$) ' AND " country_iso3 " = ' PHL ' AND " year " = 2020
UNION
SELECT " value " FROM wdi WHERE " name " = ' Military expenditure (% of GDP) ' AND " country_iso3 " = ' PHL ' AND " year " = 2020
SQLResult: [(1.01242392260698,), (361751116292.541,)]
Answer:The GDP of the Philippines in 2020 was 1.01242392260698 and the military expenditure (% of GDP) was 361751116292.541.
> Finished chain. Lamentablemente, la respuesta The GDP of the Philippines in 2020 was 1.01242392260698 and the military expenditure (% of GDP) was 361751116292.541. es incorrecto porque los valores se han intercambiado.
Uno de los objetivos de LLM4Data es desarrollar soluciones en torno a las limitaciones de las soluciones de código abierto existentes aplicadas al desarrollo de datos y al descubrimiento de conocimientos.
Las solicitudes de extracción son bienvenidas. Para cambios importantes, primero abra un problema para discutir lo que le gustaría cambiar.
Consulte CONTRIBUTING.md para obtener más información.
LLM4Data tiene licencia según el Acuerdo maestro de licencia comunitaria del Banco Mundial.


