Machine Learning Guide
1.0.0
Nota: Puede convertir fácilmente este archivo Markdown a un PDF en VSCode utilizando esta práctica extensión Markdown PDF.

Marcos de aprendizaje automático/aprendizaje profundo.
Recursos de aprendizaje para ML
Marcos, bibliotecas y herramientas de aprendizaje automático
Algoritmos
Desarrollo de PyTorch
Desarrollo de TensorFlow
Desarrollo central de aprendizaje automático
Desarrollo de aprendizaje profundo
Desarrollo del aprendizaje por refuerzo
Desarrollo de visión por computadora
Desarrollo del procesamiento del lenguaje natural (PNL)
Bioinformática
Desarrollo CUDA
DesarrolloMATLAB
Desarrollo C/C++
Desarrollo Java
Desarrollo de Python
Desarrollo escalal
Desarrollo R
Desarrollo Julia
Volver a la cima
Machine Learning es una rama de la inteligencia artificial (IA) centrada en crear aplicaciones utilizando algoritmos que aprenden de modelos de datos y mejoran su precisión con el tiempo sin necesidad de programación.

Volver a la cima
Mejores prácticas de procesamiento del lenguaje natural (NLP) de Microsoft
El libro de recetas de conducción autónoma de Microsoft
Aprendizaje automático de Azure: aprendizaje automático como servicio | MicrosoftAzure
Cómo ejecutar Jupyter Notebooks en su espacio de trabajo de Azure Machine Learning
Aprendizaje automático e inteligencia artificial | Servicios web de Amazon
Programación de cuadernos de Jupyter en instancias efímeras de Amazon SageMaker
IA y aprendizaje automático | Nube de Google
Uso de Jupyter Notebooks con Apache Spark en Google Cloud
Aprendizaje automático | Desarrollador de Apple
Inteligencia artificial y piloto automático | tesla
Herramientas de metainteligencia artificial | Facebook
Tutoriales de PyTorch
Tutoriales de TensorFlow
JupyterLab
Difusión estable con Core ML en Apple Silicon
Volver a la cima
Aprendizaje automático de la Universidad de Stanford de Andrew Ng | Coursera
Cursos de capacitación y certificación de AWS para aprendizaje automático (ML)
Programa de becas de aprendizaje automático para Microsoft Azure | Udacidad
Certificado de Microsoft: asociado científico de datos de Azure
Certificado de Microsoft: ingeniero asociado de inteligencia artificial de Azure
Capacitación e implementación de Azure Machine Learning
Aprendizaje Aprendizaje automático e inteligencia artificial de Google Cloud Training
Curso intensivo de aprendizaje automático para Google Cloud
Cursos de aprendizaje automático en línea | Udemy
Cursos de aprendizaje automático en línea | Coursera
Aprenda el aprendizaje automático con cursos y clases en línea | edX
Volver a la cima
Introducción al aprendizaje automático (PDF)
Inteligencia artificial: un enfoque moderno por Stuart J. Russel y Peter Norvig
Aprendizaje profundo por Ian Goodfellow, Yoshoua Bengio y Aaron Courville
El libro de cien páginas sobre aprendizaje automático de Andriy Burkov
Aprendizaje automático por Tom M. Mitchell
Programación de inteligencia colectiva: creación de aplicaciones web 2.0 inteligentes por Toby Segaran
Aprendizaje automático: una perspectiva algorítmica, segunda edición
Reconocimiento de patrones y aprendizaje automático por Christopher M. Bishop
Procesamiento del lenguaje natural con Python por Steven Bird, Ewan Klein y Edward Loper
Aprendizaje automático de Python: un enfoque técnico del aprendizaje automático para principiantes por Leonard Eddison
Razonamiento bayesiano y aprendizaje automático por David Barber
Aprendizaje automático para principiantes absolutos: una introducción sencilla en inglés por Oliver Theobald
Aprendizaje automático en acción por Ben Wilson
Aprendizaje automático práctico con Scikit-Learn, Keras y TensorFlow: conceptos, herramientas y técnicas para construir sistemas inteligentes por Aurélien Géron
Introducción al aprendizaje automático con Python: una guía para científicos de datos por Andreas C. Müller y Sarah Guido
Aprendizaje automático para piratas informáticos: estudios de casos y algoritmos para comenzar por Drew Conway y John Myles White
Los elementos del aprendizaje estadístico: minería de datos, inferencia y predicción por Trevor Hastie, Robert Tibshirani y Jerome Friedman
Patrones de aprendizaje automático distribuido: libro (lectura gratuita en línea) + código
Aprendizaje automático del mundo real [Capítulos gratuitos]
Introducción al aprendizaje estadístico - Libro + Código R
Elementos del aprendizaje estadístico - Libro
Think Bayes - Libro + Código Python
Minería de conjuntos de datos masivos
Un primer encuentro con el aprendizaje automático
Introducción al aprendizaje automático: Alex Smola y SVN Vishwanathan
Una teoría probabilística del reconocimiento de patrones
Introducción a la recuperación de información
Previsión: principios y práctica.
Introducción al aprendizaje automático - Amnon Shashua
Aprendizaje por refuerzo
Aprendizaje automático
Una búsqueda de la IA
Programación R para ciencia de datos
Minería de datos: herramientas y técnicas prácticas de aprendizaje automático
Aprendizaje automático con TensorFlow
Sistemas de aprendizaje automático
Fundamentos del aprendizaje automático: Mehryar Mohri, Afshin Rostamizadeh y Ameet Talwalkar
Búsqueda impulsada por IA: Trey Grainger, Doug Turnbull, Max Irwin -
Métodos conjuntos para el aprendizaje automático - Gautam Kunapuli
Ingeniería de aprendizaje automático en acción - Ben Wilson
Aprendizaje automático que preserva la privacidad: J. Morris Chang, Di Zhuang, G. Dumindu Samaraweera
Aprendizaje automático automatizado en acción: Qingquan Song, Haifeng Jin y Xia Hu
Patrones de aprendizaje automático distribuido - Yuan Tang
Gestión de proyectos de aprendizaje automático: desde el diseño hasta la implementación - Simon Thompson
Aprendizaje automático causal - Robert Ness
Optimización bayesiana en acción - Quan Nguyen
Algoritmos de aprendizaje automático en profundidad) - Vadim Smolyakov
Algoritmos de optimización - Alaa Khamis
Aumento práctico de gradiente por Guillaume Saupin
Volver a la cima
Volver a la cima
TensorFlow es una plataforma de código abierto de un extremo a otro para el aprendizaje automático. Tiene un ecosistema integral y flexible de herramientas, bibliotecas y recursos comunitarios que permite a los investigadores impulsar lo último en ML y a los desarrolladores crear e implementar fácilmente aplicaciones basadas en ML.
Keras es una API de redes neuronales de alto nivel, escrita en Python y capaz de ejecutarse sobre TensorFlow, CNTK o Theano. Fue desarrollada con el objetivo de permitir una experimentación rápida. Es capaz de ejecutarse sobre TensorFlow, Microsoft Cognitive Toolkit, R, Theano o PlaidML.
PyTorch es una biblioteca para el aprendizaje profundo de datos de entrada irregulares, como gráficos, nubes de puntos y variedades. Desarrollado principalmente por el laboratorio de investigación de inteligencia artificial de Facebook.
Amazon SageMaker es un servicio totalmente administrado que brinda a todos los desarrolladores y científicos de datos la capacidad de crear, entrenar e implementar modelos de aprendizaje automático (ML) rápidamente. SageMaker elimina el trabajo pesado de cada paso del proceso de aprendizaje automático para facilitar el desarrollo de modelos de alta calidad.
Azure Databricks es un servicio de análisis de big data rápido y colaborativo basado en Apache Spark diseñado para ciencia e ingeniería de datos. Azure Databricks configura su entorno Apache Spark en minutos, escala automáticamente y colabora en proyectos compartidos en un espacio de trabajo interactivo. Azure Databricks admite Python, Scala, R, Java y SQL, así como bibliotecas y marcos de ciencia de datos, incluidos TensorFlow, PyTorch y scikit-learn.
Microsoft Cognitive Toolkit (CNTK) es un conjunto de herramientas de código abierto para el aprendizaje profundo distribuido de nivel comercial. Describe las redes neuronales como una serie de pasos computacionales a través de un gráfico dirigido. CNTK permite al usuario realizar y combinar fácilmente tipos de modelos populares, como DNN de avance, redes neuronales convolucionales (CNN) y redes neuronales recurrentes (RNN/LSTM). CNTK implementa el aprendizaje de descenso de gradiente estocástico (SGD, retropropagación de errores) con diferenciación y paralelización automáticas en múltiples GPU y servidores.
Apple CoreML es un marco que ayuda a integrar modelos de aprendizaje automático en su aplicación. Core ML proporciona una representación unificada para todos los modelos. Su aplicación utiliza API Core ML y datos de usuario para hacer predicciones y entrenar o ajustar modelos, todo en el dispositivo del usuario. Un modelo es el resultado de aplicar un algoritmo de aprendizaje automático a un conjunto de datos de entrenamiento. Se utiliza un modelo para hacer predicciones basadas en nuevos datos de entrada.
Apache OpenNLP es una biblioteca de código abierto para un conjunto de herramientas basado en aprendizaje automático que se utiliza en el procesamiento de texto en lenguaje natural. Cuenta con una API para casos de uso como reconocimiento de entidades nombradas, detección de oraciones, etiquetado POS (parte del discurso), extracción de funciones de tokenización, fragmentación, análisis y resolución de correferencia.
Apache Airflow es una plataforma de gestión de flujo de trabajo de código abierto creada por la comunidad para crear, programar y monitorear flujos de trabajo mediante programación. Instalar. Principios. Escalable. Airflow tiene una arquitectura modular y utiliza una cola de mensajes para organizar una cantidad arbitraria de trabajadores. Airflow está listo para escalar hasta el infinito.
Open Neural Network Exchange (ONNX) es un ecosistema abierto que permite a los desarrolladores de IA elegir las herramientas adecuadas a medida que evoluciona su proyecto. ONNX proporciona un formato de código abierto para modelos de IA, tanto de aprendizaje profundo como de aprendizaje automático tradicional. Define un modelo de gráfico de cálculo extensible, así como definiciones de operadores integrados y tipos de datos estándar.
Apache MXNet es un marco de aprendizaje profundo diseñado para brindar eficiencia y flexibilidad. Le permite combinar programación simbólica e imperativa para maximizar la eficiencia y la productividad. En esencia, MXNet contiene un programador de dependencias dinámico que paraleliza automáticamente operaciones simbólicas e imperativas sobre la marcha. Una capa de optimización de gráficos además hace que la ejecución simbólica sea rápida y eficiente en la memoria. MXNet es portátil y liviano, y se escala de manera efectiva a múltiples GPU y múltiples máquinas. Soporte para Python, R, Julia, Scala, Go, Javascript y más.
AutoGluon es un conjunto de herramientas para aprendizaje profundo que automatiza las tareas de aprendizaje automático, lo que le permite lograr fácilmente un sólido rendimiento predictivo en sus aplicaciones. Con solo unas pocas líneas de código, puede entrenar e implementar modelos de aprendizaje profundo de alta precisión en datos tabulares, de imágenes y de texto.
Anaconda es una plataforma de ciencia de datos muy popular para aprendizaje automático y aprendizaje profundo que permite a los usuarios desarrollar modelos, entrenarlos e implementarlos.
PlaidML es un compilador de tensor avanzado y portátil para permitir el aprendizaje profundo en computadoras portátiles, dispositivos integrados u otros dispositivos donde el hardware informático disponible no es compatible o la pila de software disponible contiene restricciones de licencia desagradables.
OpenCV es una biblioteca altamente optimizada que se centra en aplicaciones de visión por computadora en tiempo real. Las interfaces C++, Python y Java son compatibles con Linux, MacOS, Windows, iOS y Android.
Scikit-Learn es un módulo de Python para aprendizaje automático creado sobre SciPy, NumPy y matplotlib, lo que facilita la aplicación de implementaciones sólidas y simples de muchos algoritmos populares de aprendizaje automático.
Weka es un software de aprendizaje automático de código abierto al que se puede acceder a través de una interfaz gráfica de usuario, aplicaciones de terminal estándar o una API de Java. Se utiliza ampliamente para la enseñanza, la investigación y aplicaciones industriales, contiene una gran cantidad de herramientas integradas para tareas estándar de aprendizaje automático y, además, brinda acceso transparente a cajas de herramientas conocidas como scikit-learn, R y Deeplearning4j.
Caffe es un marco de aprendizaje profundo creado teniendo en cuenta la expresión, la velocidad y la modularidad. Está desarrollado por Berkeley AI Research (BAIR)/The Berkeley Vision and Learning Center (BVLC) y contribuyentes de la comunidad.
Theano es una biblioteca de Python que le permite definir, optimizar y evaluar expresiones matemáticas que involucran matrices multidimensionales de manera eficiente, incluida una estrecha integración con NumPy.
nGraph es una biblioteca, compilador y tiempo de ejecución de C++ de código abierto para aprendizaje profundo. nGraph Compiler tiene como objetivo acelerar el desarrollo de cargas de trabajo de IA utilizando cualquier marco de aprendizaje profundo y su implementación en una variedad de objetivos de hardware. Proporciona libertad, rendimiento y facilidad de uso a los desarrolladores de IA.
NVIDIA cuDNN es una biblioteca de primitivas acelerada por GPU para redes neuronales profundas. cuDNN proporciona implementaciones altamente optimizadas para rutinas estándar como convolución hacia adelante y hacia atrás, agrupación, normalización y capas de activación. cuDNN acelera marcos de aprendizaje profundo ampliamente utilizados, incluidos Caffe2, Chainer, Keras, MATLAB, MxNet, PyTorch y TensorFlow.
Huginn es un sistema autohospedado para crear agentes que realizan tareas automatizadas en línea. Puede leer la web, observar eventos y tomar medidas en su nombre. Los agentes de Huginn crean y consumen eventos, propagándolos a lo largo de un gráfico dirigido. Piense en ello como una versión pirateable de IFTTT o Zapier en su propio servidor.
Netron es un visor de modelos de redes neuronales, aprendizaje profundo y aprendizaje automático. Es compatible con ONNX, TensorFlow Lite, Caffe, Keras, Darknet, PaddlePaddle, ncnn, MNN, Core ML, RKNN, MXNet, MindSpore Lite, TNN, Barracuda, Tengine, CNTK, TensorFlow.js, Caffe2 y UFF.
La dopamina es un marco de investigación para la creación rápida de prototipos de algoritmos de aprendizaje por refuerzo.
DALI es una biblioteca acelerada por GPU que contiene bloques de construcción altamente optimizados y un motor de ejecución para el procesamiento de datos para acelerar las aplicaciones de inferencia y entrenamiento de aprendizaje profundo.
MindSpore Lite es un nuevo marco de inferencia/entrenamiento de aprendizaje profundo de código abierto que podría usarse para escenarios móviles, de borde y de nube.
Darknet es un marco de red neuronal de código abierto escrito en C y CUDA. Es rápido, fácil de instalar y admite cálculo de CPU y GPU.
PaddlePaddle es una plataforma de aprendizaje profundo fácil de usar, eficiente, flexible y escalable, desarrollada originalmente por científicos e ingenieros de Baidu con el propósito de aplicar el aprendizaje profundo a muchos productos de Baidu.
GoogleNotebookLM es una herramienta experimental de inteligencia artificial que utiliza el poder de los modelos de lenguaje combinados con su contenido existente para obtener información crítica más rápidamente. Similar a un asistente de investigación virtual que puede resumir hechos, explicar ideas complejas y generar nuevas conexiones basadas en las fuentes que seleccione.
Unilm es una capacitación previa autosupervisada a gran escala que abarca tareas, idiomas y modalidades.
Semantic Kernel (SK) es un SDK liviano que permite la integración de modelos de lenguajes grandes (LLM) de IA con lenguajes de programación convencionales. El modelo de programación extensible SK combina funciones semánticas de lenguaje natural, funciones nativas de código tradicional y memoria basada en incrustaciones, lo que desbloquea un nuevo potencial y agrega valor a las aplicaciones con IA.
Pandas AI es una biblioteca de Python que integra capacidades de inteligencia artificial generativa en Pandas, haciendo que los marcos de datos sean conversacionales.
NCNN es un marco de inferencia de redes neuronales de alto rendimiento optimizado para la plataforma móvil.
MNN es un marco de aprendizaje profundo increíblemente rápido y liviano, probado en casos de uso críticos para el negocio en Alibaba.
MediaPipe está optimizado para el rendimiento de un extremo a otro en una amplia gama de plataformas. Ver demostraciones Más información ML complejo en el dispositivo, simplificado Hemos abstraído las complejidades de hacer que el ML en el dispositivo sea personalizable, esté listo para producción y sea accesible en todas las plataformas.
MegEngine es un marco de aprendizaje profundo rápido, escalable y fácil de usar con 3 características clave: Marco unificado tanto para entrenamiento como para inferencia.
ML.NET es una biblioteca de aprendizaje automático diseñada como una plataforma extensible para que pueda consumir otros marcos de aprendizaje automático populares (TensorFlow, ONNX, Infer.NET y más) y tener acceso a aún más escenarios de aprendizaje automático, como clasificación de imágenes, detección de objetos y más.
Ludwig es un marco de aprendizaje automático declarativo que facilita la definición de canales de aprendizaje automático mediante un sistema de configuración basado en datos simple y flexible.
MMdnn es una herramienta integral y transversal para convertir, visualizar y diagnosticar modelos de aprendizaje profundo (DL). "MM" significa gestión de modelos y "dnn" es el acrónimo de red neuronal profunda. Convierta modelos entre Caffe, Keras, MXNet, Tensorflow, CNTK, PyTorch Onnx y CoreML.
Horovod es un marco de capacitación distribuido de aprendizaje profundo para TensorFlow, Keras, PyTorch y Apache MXNet.
Vaex es una biblioteca de Python de alto rendimiento para marcos de datos fuera del núcleo (similares a Pandas), para visualizar y explorar grandes conjuntos de datos tabulares.
GluonTS es un paquete de Python para modelado probabilístico de series de tiempo, centrándose en modelos basados en aprendizaje profundo, basados en PyTorch y MXNet.
MindsDB es un servidor ML-SQL que permite flujos de trabajo de aprendizaje automático para las bases de datos y almacenes de datos más potentes que utilizan SQL.
Jupyter Notebook es una aplicación web de código abierto que le permite crear y compartir documentos que contienen código en vivo, ecuaciones, visualizaciones y texto narrativo. Jupyter se utiliza ampliamente en industrias que realizan limpieza y transformación de datos, simulación numérica, modelado estadístico, visualización de datos, ciencia de datos y aprendizaje automático.
Apache Spark es un motor de análisis unificado para el procesamiento de datos a gran escala. Proporciona API de alto nivel en Scala, Java, Python y R, y un motor optimizado que admite gráficos de cálculo general para el análisis de datos. También admite un amplio conjunto de herramientas de nivel superior que incluyen Spark SQL para SQL y DataFrames, MLlib para aprendizaje automático, GraphX para procesamiento de gráficos y Structured Streaming para procesamiento de secuencias.
Apache Spark Connector para SQL Server y Azure SQL es un conector de alto rendimiento que le permite utilizar datos transaccionales en análisis de big data y conservar resultados para consultas o informes ad hoc. El conector le permite utilizar cualquier base de datos SQL, local o en la nube, como fuente de datos de entrada o receptor de datos de salida para trabajos de Spark.
Apache PredictionIO es un marco de aprendizaje automático de código abierto para desarrolladores, científicos de datos y usuarios finales. Admite la recopilación de eventos, la implementación de algoritmos, la evaluación y la consulta de resultados predictivos a través de API REST. Se basa en servicios escalables de código abierto como Hadoop, HBase (y otras bases de datos), Elasticsearch, Spark e implementa lo que se llama arquitectura Lambda.
Cluster Manager para Apache Kafka (CMAK) es una herramienta para administrar clústeres de Apache Kafka.
BigDL es una biblioteca distribuida de aprendizaje profundo para Apache Spark. Con BigDL, los usuarios pueden escribir sus aplicaciones de aprendizaje profundo como programas Spark estándar, que pueden ejecutarse directamente sobre los clústeres Spark o Hadoop existentes.
Eclipse Deeplearning4J (DL4J) es un conjunto de proyectos destinados a respaldar todas las necesidades de una aplicación de aprendizaje profundo basada en JVM (Scala, Kotlin, Clojure y Groovy). Esto significa comenzar con los datos sin procesar, cargarlos y preprocesarlos desde cualquier lugar y en cualquier formato para construir y ajustar una amplia variedad de redes de aprendizaje profundo simples y complejas.
Tensorman es una utilidad para una fácil gestión de contenedores de Tensorflow desarrollada por System76. Tensorman permite que Tensorflow opere en un entorno aislado del resto del sistema. Este entorno virtual puede funcionar independientemente del sistema base, lo que le permite utilizar cualquier versión de Tensorflow en cualquier versión de una distribución de Linux que admita el tiempo de ejecución de Docker.
Numba es un compilador de optimización compatible con NumPy de código abierto para Python patrocinado por Anaconda, Inc. Utiliza el proyecto del compilador LLVM para generar código de máquina a partir de la sintaxis de Python. Numba puede compilar un gran subconjunto de Python centrado numéricamente, incluidas muchas funciones de NumPy. Además, Numba admite la paralelización automática de bucles, la generación de código acelerado por GPU y la creación de ufuncs y devoluciones de llamadas en C.
Chainer es un marco de aprendizaje profundo basado en Python que busca flexibilidad. Proporciona API de diferenciación automática basadas en el enfoque de definición por ejecución (gráficos computacionales dinámicos), así como API de alto nivel orientadas a objetos para construir y entrenar redes neuronales. También admite CUDA/cuDNN utilizando CuPy para entrenamiento e inferencia de alto rendimiento.
XGBoost es una biblioteca optimizada de aumento de gradiente distribuido diseñada para ser altamente eficiente, flexible y portátil. Implementa algoritmos de aprendizaje automático bajo el marco de Gradient Boosting. XGBoost proporciona un impulso de árbol paralelo (también conocido como GBDT, GBM) que resuelve muchos problemas de ciencia de datos de forma rápida y precisa. Admite capacitación distribuida en múltiples máquinas, incluidos los clústeres de AWS, GCE, Azure y Yarn. Además, se puede integrar con Flink, Spark y otros sistemas de flujo de datos en la nube.
cuML es un conjunto de bibliotecas que implementan algoritmos de aprendizaje automático y funciones matemáticas primitivas que comparten API compatibles con otros proyectos RAPIDS. cuML permite a los científicos de datos, investigadores e ingenieros de software ejecutar tareas tabulares de ML tradicionales en GPU sin entrar en detalles de la programación CUDA. En la mayoría de los casos, la API Python de cuML coincide con la API de scikit-learn.
Emu es una biblioteca GPGPU para Rust centrada en la portabilidad, la modularidad y el rendimiento. Es una abstracción específica de computación estilo CUDA sobre WebGPU que proporciona una funcionalidad específica para hacer que WebGPU se sienta más como CUDA.
Scalene es un perfilador de CPU, GPU y memoria de alto rendimiento para Python que hace una serie de cosas que otros perfiladores de Python no hacen ni pueden hacer. Ejecuta órdenes de magnitud más rápido que muchos otros generadores de perfiles y, al mismo tiempo, ofrece información mucho más detallada.
MLpack es una biblioteca de aprendizaje automático C++ rápida y flexible escrita en C++ y construida sobre la biblioteca de álgebra lineal Armadillo, la biblioteca de optimización numérica ensmallen y partes de Boost.
Netron es un visor de modelos de redes neuronales, aprendizaje profundo y aprendizaje automático. Es compatible con ONNX, TensorFlow Lite, Caffe, Keras, Darknet, PaddlePaddle, ncnn, MNN, Core ML, RKNN, MXNet, MindSpore Lite, TNN, Barracuda, Tengine, CNTK, TensorFlow.js, Caffe2 y UFF.
Lightning es una herramienta que crea y entrena modelos de PyTorch y los conecta al ciclo de vida de ML utilizando plantillas de aplicaciones Lightning, sin manejar infraestructura de bricolaje, gestión de costos, escalado, etc.
OpenNN es una biblioteca de redes neuronales de código abierto para aprendizaje automático. Contiene algoritmos y utilidades sofisticados para hacer frente a muchas soluciones de inteligencia artificial.
H20 es una plataforma de IA en la nube que resuelve problemas comerciales complejos y acelera el descubrimiento de nuevas ideas con resultados que puede comprender y en los que puede confiar.
Gensim es una biblioteca de Python para modelado de temas, indexación de documentos y recuperación de similitudes con grandes corpus. El público objetivo es la comunidad de procesamiento del lenguaje natural (PNL) y recuperación de información (IR).
llama.cpp es un puerto del modelo LLaMA de Facebook en C/C++.
hmmlearn es un conjunto de algoritmos para el aprendizaje y la inferencia no supervisados de modelos ocultos de Markov.
Nextjournal es un cuaderno para investigaciones reproducibles. Ejecuta todo lo que puedas poner en un contenedor Docker. Mejore su flujo de trabajo con cuadernos políglotas, control de versiones automático y colaboración en tiempo real. Ahorre tiempo y dinero con el aprovisionamiento bajo demanda, incluida la compatibilidad con GPU.
IPython proporciona una rica arquitectura para informática interactiva con:
Veles es una plataforma distribuida para el desarrollo rápido de aplicaciones de aprendizaje profundo actualmente desarrollada por Samsung.
DyNet es una biblioteca de redes neuronales desarrollada por la Universidad Carnegie Mellon y muchas otras. Está escrito en C++ (con enlaces en Python) y está diseñado para ser eficiente cuando se ejecuta en CPU o GPU, y para funcionar bien con redes que tienen estructuras dinámicas que cambian para cada instancia de entrenamiento. Este tipo de redes son particularmente importantes en tareas de procesamiento del lenguaje natural, y DyNet se ha utilizado para construir sistemas de última generación para análisis sintáctico, traducción automática, inflexión morfológica y muchas otras áreas de aplicación.
Ray es un marco unificado para escalar aplicaciones de IA y Python. Consiste en un tiempo de ejecución distribuido central y un conjunto de herramientas de bibliotecas (Ray AIR) para acelerar las cargas de trabajo de ML.
Whisper.cpp es una inferencia de alto rendimiento del modelo de reconocimiento automático de voz (ASR) Whisper de OpenAI.
ChatGPT Plus es un plan de suscripción piloto ( $20/mes ) para ChatGPT, una IA conversacional que puede chatear con usted, responder preguntas de seguimiento y desafiar suposiciones incorrectas.
Auto-GPT es un "agente de IA" que, dado un objetivo en lenguaje natural, puede intentar lograrlo dividiéndolo en subtareas y utilizando Internet y otras herramientas en un bucle automático. Utiliza las API GPT-4 o GPT-3.5 de OpenAI y se encuentra entre los primeros ejemplos de una aplicación que utiliza GPT-4 para realizar tareas autónomas.
Chatbot UI de mckaywrigley es un kit de chatbot avanzado para los modelos de chat de OpenAI creado sobre Chatbot UI Lite utilizando Next.js, TypeScript y Tailwind CSS. Esta versión de ChatBot UI es compatible con los modelos GPT-3.5 y GPT-4. Las conversaciones se almacenan localmente en su navegador. Puede exportar e importar conversaciones para protegerlas contra la pérdida de datos. Ver una demostración.
Chatbot UI Lite de mckaywrigley es un kit de inicio de chatbot simple para el modelo de chat de OpenAI que utiliza Next.js, TypeScript y Tailwind CSS. Ver una demostración.
MiniGPT-4 es una mejora de la comprensión visión-lenguaje con modelos avanzados de lenguaje grande.
GPT4All es un ecosistema de chatbots de código abierto entrenados en colecciones masivas de datos limpios de asistentes, incluidos códigos, historias y diálogos basados en LLaMa.
GPT4All UI es una aplicación web Flask que proporciona una interfaz de usuario de chat para interactuar con el chatbot GPT4All.
Alpaca.cpp es un modelo rápido similar a ChatGPT localmente en su dispositivo. Combina el modelo básico LLaMA con una reproducción abierta de Stanford Alpaca, un ajuste fino del modelo base para obedecer instrucciones (similar al RLHF utilizado para entrenar ChatGPT) y un conjunto de modificaciones a llama.cpp para agregar una interfaz de chat.
llama.cpp es un puerto del modelo LLaMA de Facebook en C/C++.
OpenPlayground es un campo de juegos para ejecutar modelos similares a ChatGPT localmente en su dispositivo.
Vicuña es un chatbot de código abierto entrenado mediante ajustes LLaMA. Aparentemente logra más del 90% de calidad de chatgpt y entrenarlo cuesta $300.
Yeagar ai es un creador de Langchain Agent diseñado para ayudarlo a crear, crear prototipos e implementar agentes impulsados por IA con facilidad.
Vicuña se crea ajustando un modelo base de LLaMA utilizando aproximadamente 70.000 conversaciones compartidas por usuarios recopiladas de ShareGPT.com con API públicas. Para garantizar la calidad de los datos, convierte el HTML nuevamente en rebajas y filtra algunas muestras inapropiadas o de baja calidad.
ShareGPT es un lugar para compartir tus conversaciones ChatGPT más locas con un solo clic. Con 198.404 conversaciones compartidas hasta el momento.
FastChat es una plataforma abierta para capacitar, atender y evaluar chatbots basados en modelos de lenguaje grandes.
Haystack es un marco de PNL de código abierto para interactuar con sus datos utilizando modelos Transformer y LLM (GPT-4, ChatGPT y similares). Ofrece herramientas listas para producción para crear rápidamente aplicaciones complejas de toma de decisiones, respuesta a preguntas, búsqueda semántica, generación de texto y más.
StableLM (Stability AI Language Models) es una serie de modelos de lenguaje StableLM y se actualizará continuamente con nuevos puntos de control.
Dolly de Databricks es un modelo de lenguaje grande que sigue instrucciones y se entrena en la plataforma de aprendizaje automático de Databricks y que tiene licencia para uso comercial.
GPTCach es una biblioteca para crear caché semántica para consultas LLM.
AlaC es un generador de infraestructura como código de inteligencia artificial.
Adrenaline es una herramienta que te permite hablar con tu código base. Está impulsado por análisis estático, búsqueda de vectores y modelos de lenguaje grandes.
OpenAssistant es un asistente basado en chat que comprende tareas, puede interactuar con sistemas de terceros y recuperar información dinámicamente para hacerlo.
DoctorGPT es un binario autónomo y liviano que monitorea los registros de su aplicación en busca de problemas y los diagnostica.
HttpGPT es un complemento de Unreal Engine 5 que facilita la integración con los servicios basados en GPT de OpenAI (ChatGPT y DALL-E) a través de solicitudes REST asíncronas, lo que facilita a los desarrolladores la comunicación con estos servicios. También incluye herramientas de edición para integrar Chat GPT y generación de imágenes DALL-E directamente en el motor.
PaLM 2 es un modelo de lenguaje grande de próxima generación que se basa en el legado de investigación innovadora de Google en aprendizaje automático e inteligencia artificial responsable. Incluye tareas de razonamiento avanzado, que incluyen código y matemáticas, clasificación y respuesta a preguntas, traducción y dominio multilingüe, y generación de lenguaje natural mejor que nuestros LLM de última generación anteriores.
Med-PaLM es un modelo de lenguaje grande (LLM) diseñado para brindar respuestas de alta calidad a preguntas médicas. Aprovecha el poder de los grandes modelos de lenguaje de Google, que hemos alineado con el ámbito médico con un conjunto de demostraciones de expertos médicos cuidadosamente seleccionadas.
Sec-PaLM es un modelo de lenguaje grande (LLM) que acelera la capacidad de ayudar a las personas responsables de mantener seguras sus organizaciones. Estos nuevos modelos no sólo brindan a las personas una forma más natural y creativa de comprender y gestionar la seguridad.
Volver a la cima
Volver a la cima
Volver a la cima
Localai es una API local compatible con OpenAI, impulsada por la comunidad, impulsada por la comunidad. Reemplazo de entrega para OpenAI Running LLMS en hardware de grado consumidor sin necesidad de GPU. Es una API para ejecutar modelos compatibles con GGML: LLAMA, GPT4All, RWKV, Whisper, Vicuna, Koala, Gpt4all-J, Cerebras, Falcon, Dolly, Starcoder y muchos otros.
Llama.cpp es un modelo de LLAMA de puerto de Facebook en C/C ++.
Ollama es una herramienta para correr con Llama 2 y otros modelos de idiomas grandes localmente.
Localai es una API local compatible con OpenAI, impulsada por la comunidad, impulsada por la comunidad. Reemplazo de entrega para OpenAI Running LLMS en hardware de grado consumidor sin necesidad de GPU. Es una API para ejecutar modelos compatibles con GGML: LLAMA, GPT4All, RWKV, Whisper, Vicuna, Koala, Gpt4all-J, Cerebras, Falcon, Dolly, Starcoder y muchos otros.
Serge es una interfaz web para chatear con Alpaca a través de Llama.cpp. Totalmente autohospedado y dockerized, con una API fácil de usar.
OpenLLM es una plataforma abierta para operar modelos de idiomas grandes (LLM) en producción. Tune, servir, implementar y monitorear cualquier LLM con facilidad.
Llama-GPT es un chatbot con forma de chatgpt egoísta, fuera de línea. Impulsado por Llama 2. 100% privado, sin datos que salen de su dispositivo.
LLAMA2 WebUI es una herramienta para ejecutar cualquier Llama 2 localmente con UI de Gradio en GPU o CPU desde cualquier lugar (Linux/Windows/Mac). Use llama2-wrapper como su backend local LLAMA2 para agentes/aplicaciones generativos.
Llama2.C es una herramienta para entrenar la arquitectura LLAMA 2 LLM en Pytorch y luego inferirla con un simple archivo C de 700 líneas (run.c).
Alpaca.cpp es un modelo rápido similar a ChatGPT localmente en su dispositivo. Combina el modelo de la Fundación LLAMA con una reproducción abierta de Stanford Alpaca, un ajuste del modelo base para obedecer las instrucciones (similar al RLHF utilizado para entrenar chatgpt) y un conjunto de modificaciones a llama.cpp para agregar una interfaz de chat.
GPT4All es un ecosistema de chatbots de código abierto entrenados en una colección masiva de datos de asistente limpio que incluyen código, historias y diálogo basados en LLAMA.
Minigpt-4 es una comprensión en el idioma de visión mejorada con modelos de lenguaje grandes avanzados
Lollms WebUI es un HUB para modelos LLM (modelo de lenguaje grande). Su objetivo es proporcionar una interfaz fácil de usar para acceder y utilizar varios modelos LLM para una amplia gama de tareas. Ya sea que necesite ayuda para escribir, codificar, organizar datos, generar imágenes o buscar respuestas a sus preguntas.
LM Studio es una herramienta para descubrir, descargar y ejecutar LLM locales.
La interfaz de usuario web de Gradio es una herramienta para modelos de idiomas grandes. Admite Transformers, GPTQ, Llama.CPP (GGML/GGUF), modelos LLAMA.
OpenPlay Ground es un juego de juego para ejecutar modelos similares a ChatGPT localmente en su dispositivo.
Vicuna es un chatbot de código abierto entrenado por Fine Tuning Llama. Aparentemente logra más del 90% de calidad de chatgpt y cuesta $ 300 para entrenar.
Yeagar AI es un creador de agentes de Langchain diseñado para ayudarlo a construir, prototipos y implementar agentes con facilidad con facilidad.
Koboldcpp es un software de generación de texto de IA fácil de usar para los modelos GGML. Es una sola distribución de Concedo, que se basa en Llama.cpp, y agrega un punto final versátil de la API de Kobold, soporte de formato adicional, compatibilidad con atraso, así como una interfaz de usuario elegante con historias persistentes, herramientas de edición, formatos de guardado, memoria, mundo. Información, nota del autor, personajes y escenarios.
Volver a la cima
Fuzzy Logic es un enfoque heurístico que permite un procesamiento más avanzado del árbol de decisiones y una mejor integración con la programación basada en reglas.
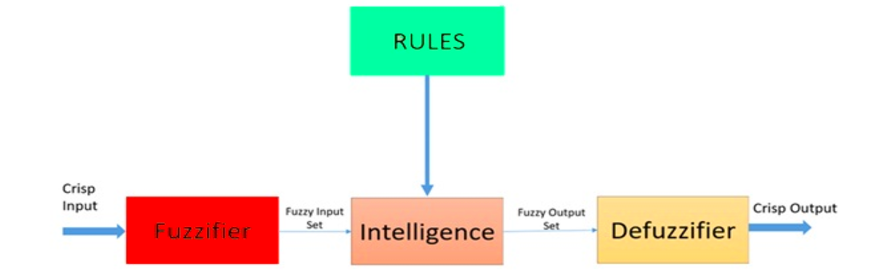
Arquitectura de un sistema lógico difuso. Fuente: Researchgate
Support Vector Machine (SVM) es un modelo de aprendizaje automático supervisado que utiliza algoritmos de clasificación para problemas de clasificación de dos grupos.

Máquina de vectores de soporte (SVM). Fuente: OpenClipart
Las redes neuronales son un subconjunto de aprendizaje automático y están en el corazón de los algoritmos de aprendizaje profundo. El nombre/estructura está inspirado en el cerebro humano que copia el proceso que las neuronas/nodos biológicos se señalan entre sí.
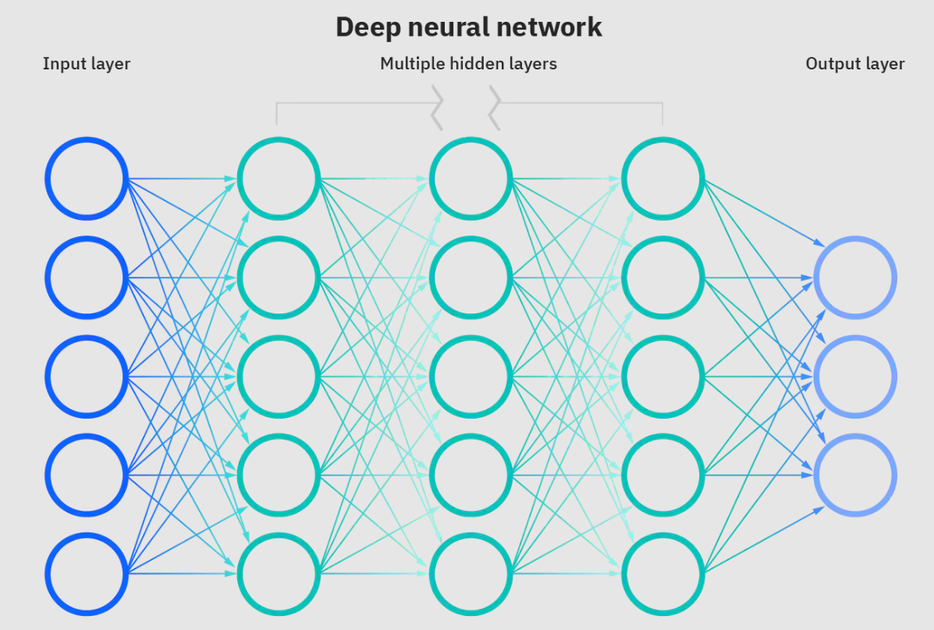
Red neuronal profunda. Fuente: IBM
Las redes neuronales convolucionales (R-CNN) es un algoritmo de detección de objetos que primero segmenta la imagen para encontrar posibles cuadros limitados relevantes y luego ejecutar el algoritmo de detección para encontrar la mayoría de los objetos probables en esos cuadros delimitadores.
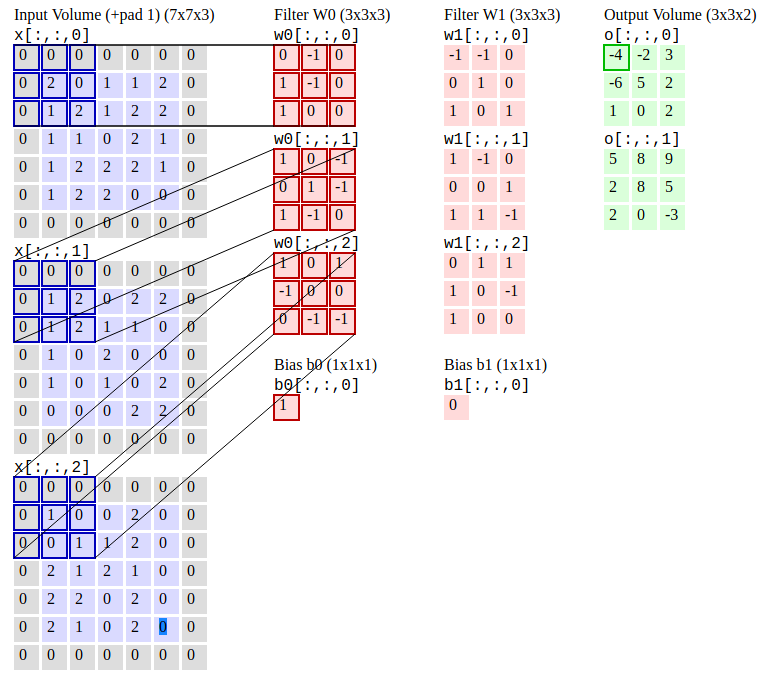
Redes neuronales convolucionales. Fuente: CS231N
Las redes neuronales recurrentes (RNN) es un tipo de red neuronal artificial que utiliza datos secuenciales o datos de series de tiempo.
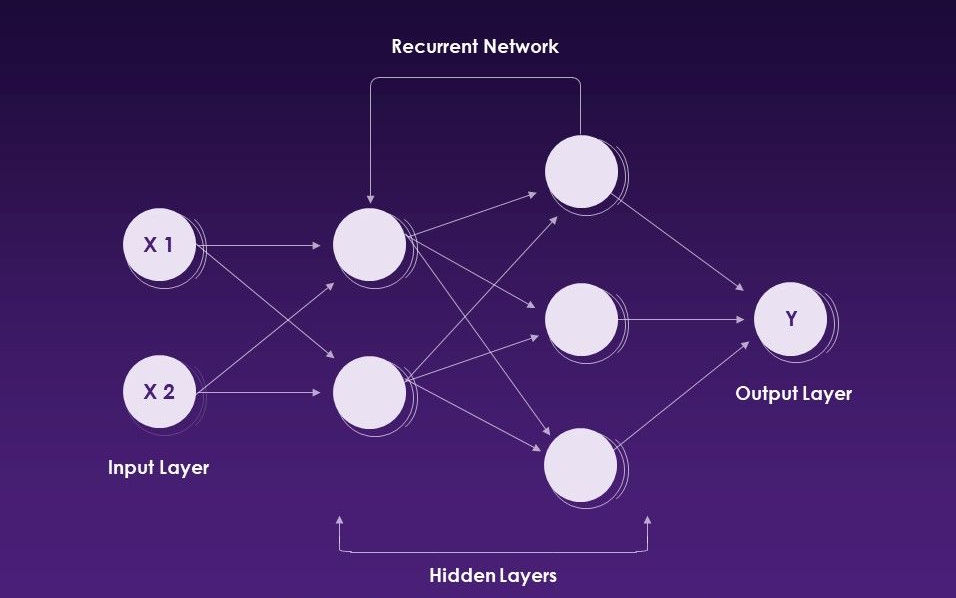
Redes neuronales recurrentes. Fuente: Slideteam
Los perceptrones multicapa (MLP) son redes neuronales de múltiples capas compuestas de múltiples capas de perceptrones con una activación umbral.
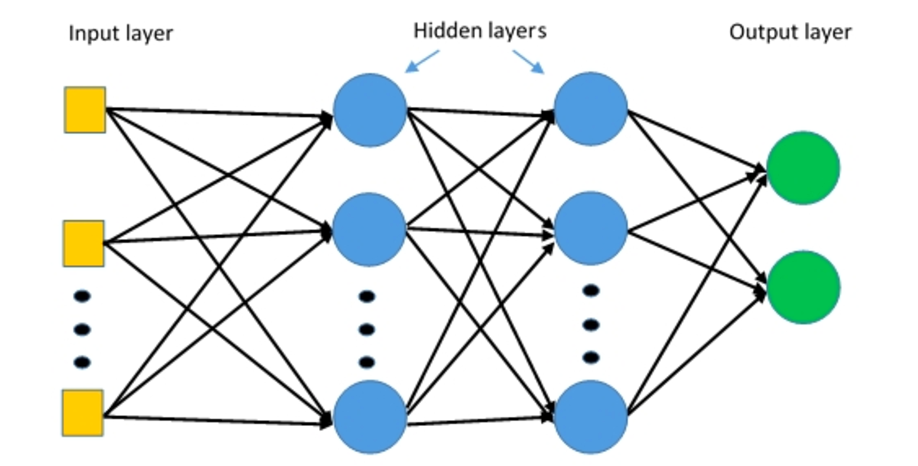
Perceptrones de múltiples capas. Fuente: Deepai
El bosque aleatorio es un algoritmo de aprendizaje automático de uso común, que combina la producción de múltiples árboles de decisión para alcanzar un solo resultado. No se puede podar un árbol de decisión en un bosque para el muestreo y, por lo tanto, la selección de predicción. Su facilidad de uso y flexibilidad ha alimentado su adopción, ya que maneja los problemas de clasificación y regresión.
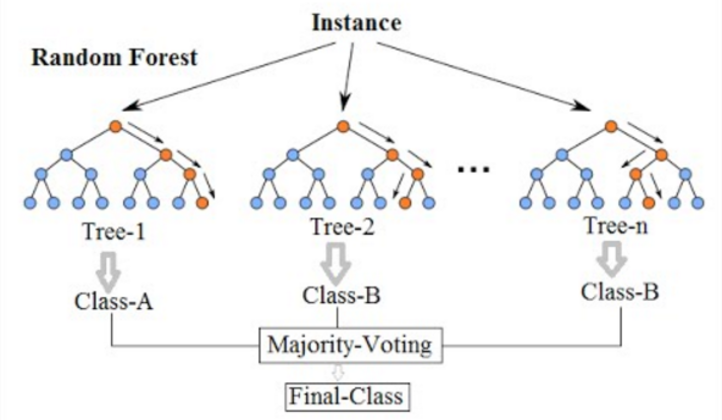
Bosque aleatorio. Fuente: Wikimedia
Los árboles de decisión son modelos estructurados en árboles para la clasificación y la regresión.
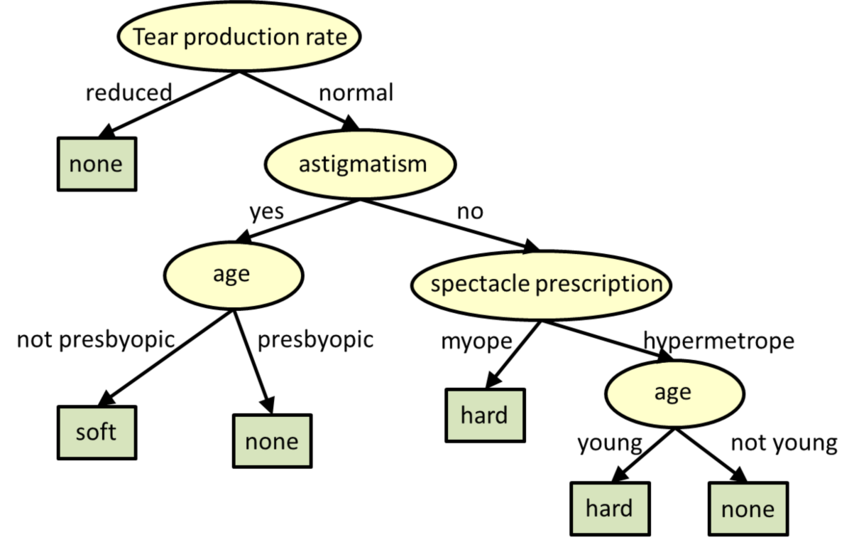
** Árboles de decisión. Fuente: CMU
Naive Bayes es un algoritmo de aprendizaje automático que se utiliza problemas de clasificación de cal. Se basa en la aplicación del teorema de Bayes con fuertes supuestos de independencia entre las características.

Teorema de Bayes. Fuente: Mathisfun
Volver a la cima

Pytorch es un marco de aprendizaje profundo de código abierto que acelera el camino de la investigación a la producción, utilizado para aplicaciones como la visión por computadora y el procesamiento del lenguaje natural. Pytorch es desarrollado por el laboratorio de investigación de IA de Facebook.
Empezando con Pytorch
Documentación de Pytorch
Foro de discusión de Pytorch
Top Pytorch Courses Online | Coursera
Top Pytorch Courses Online | Udemy
Aprenda Pytorch con cursos y clases en línea | edx
Fundamentos de Pytorch - Learn | Microsoft Docs
Introducción al aprendizaje profundo con Pytorch | Idacacidad
Desarrollo de Pytorch en Código Visual Studio
Pytorch on Azure - Aprendizaje profundo con Pytorch | MicrosoftAzure
Pytorch - Azure Databricks | Microsoft Docs
Aprendizaje profundo con Pytorch | Servicios web de Amazon (AWS)
Comenzando con Pytorch en Google Cloud
Pytorch Mobile es un flujo de trabajo ML de extremo a extremo desde la capacitación hasta la implementación para dispositivos móviles iOS y Android.
Torchscript es una forma de crear modelos serializables y optimizables a partir del código Pytorch. Esto permite que cualquier programa Torchscript se guarde en un proceso de Python y se cargue en un proceso donde no hay dependencia de Python.
Torchserve es una herramienta flexible y fácil de usar para servir modelos Pytorch.
Keras es una API de redes neuronales de alto nivel, escrita en Python y capaz de funcionar sobre TensorFlow, CNTK o Theano.In se desarrolló con un enfoque en habilitar la experimentación rápida. Es capaz de ejecutarse sobre TensorFlow, Microsoft Cognitive Toolkit, R, Thano o PlaidMl.
El tiempo de ejecución de ONNX es un acelerador multiplataforma de inferencia y entrenamiento de ML de alto rendimiento. Admite modelos de marcos de aprendizaje profundo como Pytorch y TensorFlow/Keras, así como bibliotecas clásicas de aprendizaje automático como Scikit-Learn, LightGBM, XGBOost, etc.
Kornia es una biblioteca de visión por computadora diferenciable que consiste en un conjunto de rutinas y módulos diferenciables para resolver problemas genéricos de CV (visión por computadora).
Pytorch-NLP es una biblioteca para el procesamiento del lenguaje natural (NLP) en Python. Está construido con la última investigación en mente, y fue diseñado desde el primer día para apoyar la prototipos rápidos. Pytorch-NLP viene con incrustaciones previamente capacitadas, muestreadores, cargadores de conjuntos de datos, métricas, módulos de red neuronales y codificadores de texto.
Ignite es una biblioteca de alto nivel para ayudar con la capacitación y la evaluación de las redes neuronales en Pytorch de manera flexible y transparente.
Hummingbird es una biblioteca para compilar modelos ML tradicionales entrenados en cálculos de tensor. Permite a los usuarios aprovechar a la perfección los marcos de redes neuronales (como Pytorch) para acelerar los modelos ML tradicionales.
Deep Graph Library (DGL) es un paquete de Python creado para una fácil implementación de la familia de modelos de red neuronal Graph, encima de Pytorch y otros marcos.
Tensorly es una API de alto nivel para métodos de tensor y redes neuronales tensorizadas profundas en Python que tiene como objetivo simplificar el aprendizaje tensor.
GpyTorch es una biblioteca de procesos gaussiana implementada con Pytorch, diseñada para crear modelos de procesos gaussianos escalables y flexibles.
Poutyne es un marco similar a Keras para Pytorch y maneja gran parte del código básico necesario para entrenar redes neuronales.
Forte es un kit de herramientas para construir tuberías NLP con componentes compuestos, interfaces de datos convenientes e interacción de tarea cruzada.
Torchmetrics es una métrica de aprendizaje automático para aplicaciones de Pytorch escalables distribuidas.
Captum es una biblioteca de código abierto y extensible para la interpretabilidad del modelo construida en Pytorch.
Transformer es un procesamiento de lenguaje natural de última generación para Pytorch, TensorFlow y Jax.
Hydra es un marco para configurar elegantemente aplicaciones complejas.
Accelerate es una forma simple de entrenar y usar modelos Pytorch con Multi-GPU, TPU, precisión mixta.
Ray es un marco rápido y simple para construir y ejecutar aplicaciones distribuidas.
Parlai es una plataforma unificada para compartir, capacitar y evaluar modelos de diálogo en muchas tareas.
Pytorchvideo es una biblioteca de aprendizaje profundo para la investigación de comprensión de video. Alojan varios modelos, conjuntos de datos, tuberías de entrenamiento y más centrados en videos.
Opacus es una biblioteca que permite capacitar modelos de Pytorch con privacidad diferencial.
Pytorch Lightning es una biblioteca ML similar a Keras para Pytorch. Le deja la lógica de entrenamiento y validación del núcleo y automatiza el resto.
Pytorch geométrico temporal es una biblioteca de extensión temporal (dinámica) para la geométrica de Pytorch.
Pytorch geométrico es una biblioteca para el aprendizaje profundo en datos de entrada irregulares, como gráficos, nubes de puntos y colectores.
Raster Vision es un marco de código abierto para el aprendizaje profundo en imágenes satelitales e aéreas.
Crypten es un marco para la privacidad de la preservación de ML. Su objetivo es hacer que las técnicas de computación seguras sean accesibles para los practicantes de ML.
Optuna es un marco de optimización de hiperparameter de código abierto para automatizar la búsqueda de hiperparameter.
Pyro es un lenguaje de programación probabilístico universal (PPL) escrito en Python y con el apoyo de Pytorch en el backend.
Albumentations es una biblioteca de aumento de imagen rápida y extensible para diferentes tareas CV como clasificación, segmentación, detección de objetos y estimación de pose.
Skorch es una biblioteca de alto nivel para Pytorch que proporciona compatibilidad completa de Scikit-Learn.
MMF es un marco modular para la investigación multimodal de visión e idiomas de Facebook AI Research (Fair).
ADAPTDL es un marco de capacitación y programación de aprendizaje profundo adaptativo a recursos.
Polyaxon es una plataforma para construir, capacitar y monitorear aplicaciones de aprendizaje profundo a gran escala.
TextBrewer es un kit de herramientas de destilación de conocimiento basado en Pytorch para el procesamiento del lenguaje natural
Advertorch es una caja de herramientas para la investigación de robustez adversa. Contiene módulos para generar ejemplos adversos y defender contra ataques.
NEMO es un kit de herramientas AA para IA conversacional.
Clinicadl es un marco para la clasificación reproducible de la enfermedad de Alzheimer
Las líneas de base estables3 (SB3) es un conjunto de implementaciones confiables de algoritmos de aprendizaje de refuerzo en Pytorch.
Torchio es un conjunto de herramientas para leer, preprocesar, probar, aumentar y escribir imágenes médicas 3D en aplicaciones de aprendizaje profundo escritas en Pytorch.
Pysyft es una biblioteca de Python para el aprendizaje profundo encriptado y de privacidad.
Flair es un marco muy simple para el procesamiento del lenguaje natural (PNL) de última generación.
GLOW es un compilador ML que acelera el rendimiento de los marcos de aprendizaje profundo en diferentes plataformas de hardware.
Fairscale es una biblioteca de extensión de Pytorch para entrenamiento de alto rendimiento y gran escala en una o múltiples máquinas/nodos.
Monai es un marco de aprendizaje profundo que proporciona capacidades fundamentales optimizadas por el dominio para desarrollar flujos de trabajo de capacitación de imágenes en salud.
PFRL es una biblioteca de aprendizaje de refuerzo profundo que implementa varios algoritmos de refuerzo profundo de última generación en Python usando Pytorch.
Einops es una operación tensor flexible y potente para un código legible y confiable.
Pytorch3d es una biblioteca de aprendizaje profundo que proporciona componentes eficientes y reutilizables para la investigación de visión por computadora 3D con Pytorch.
Ensemble Pytorch es un marco de conjunto unificado para Pytorch para mejorar el rendimiento y la robustez de su modelo de aprendizaje profundo.
Ligeramente es un marco de visión por computadora para el aprendizaje auto-supervisado.
Higher es una biblioteca que facilita la implementación de algoritmos de meta-aprendizaje basados en gradientes arbitrariamente complejos y bucles de optimización anidados con pytorch casi anidadores.
Horovod es una biblioteca de capacitación distribuida para marcos de aprendizaje profundo. Horovod tiene como objetivo hacer que el DL distribuido sea rápido y fácil de usar.
Pennylane es una biblioteca de ML cuántica, diferenciación automática y optimización de cálculos clásicos cuánticos híbridos.
Detectron2 es la plataforma de próxima generación de Fair para la detección y segmentación de objetos.
Fastai es una biblioteca que simplifica las redes neuronales rápidas y precisas de la capacitación utilizando las mejores prácticas modernas.
Volver a la cima

TensorFlow es una plataforma de código abierto de extremo a extremo para el aprendizaje automático. Tiene un ecosistema integral y flexible de herramientas, bibliotecas y recursos comunitarios que permite a los investigadores impulsar el estado del arte en ML y los desarrolladores construyen e implementan fácilmente aplicaciones alimentadas con ML.
Comenzando con TensorFlow
Tutoriales de tensorflow
Certificado de desarrollador de TensorFlow | TensorFlow
Comunidad de TensorFlow
Modelos y conjuntos de datos de tensorflow
Nube tensorflow
Educación de aprendizaje automático | TensorFlow
Top TensorFlow Cours en línea | Coursera
Top TensorFlow Cours en línea | Udemy
Aprendizaje profundo con TensorFlow | Udemy
Aprendizaje profundo con TensorFlow | edx
Introducción a TensorFlow para el aprendizaje profundo | Idacacidad
Introducción a TensorFlow: curso de bloqueo de aprendizaje automático | Desarrolladores de Google
Entrenar e implementar un modelo TensorFlow - Azure Machine Learning
Aplicar modelos de aprendizaje automático en funciones de Azure con Python y TensorFlow | MicrosoftAzure
Aprendizaje profundo con TensorFlow | Servicios web de Amazon (AWS)
Tensorflow - Amazon EMR | Documentación de AWS
TensorFlow Enterprise | Nube de Google
Tensorflow Lite es un marco de aprendizaje profundo de código abierto para implementar modelos de aprendizaje automático en dispositivos móviles y IoT.
Tensorflow.js es una biblioteca de JavaScript que le permite desarrollar o ejecutar modelos ML en JavaScript, y usar ML directamente en el lado del cliente del navegador, lado del servidor a través de Node.js, móvil nativo a través de React Native, Desktop nativo a través de Electron e incluso en IoT Dispositivos a través de Node.js en Raspberry Pi.
Tensorflow_macos es una versión optimizada MAC de TensorFlow y TensorFlow Addons para MacOS 11.0+ acelerado utilizando el marco de cómputo ML de Apple.
Google Colaboratory es un entorno de cuaderno Jupyter gratuito que no requiere configuración y se ejecuta completamente en la nube, lo que le permite ejecutar el código TensorFlow en su navegador con un solo clic.
La herramienta de WHIF IF es una herramienta para el sondeo sin código de modelos de aprendizaje automático, útil para la comprensión del modelo, la depuración y la equidad. Disponible en TensorBoard y Jupyter o cuadernos Colab.
TensorBoard es un conjunto de herramientas de visualización para comprender, depurar y optimizar los programas de TensorFlow.
Keras es una API de redes neuronales de alto nivel, escrita en Python y capaz de funcionar sobre TensorFlow, CNTK o Theano.In se desarrolló con un enfoque en habilitar la experimentación rápida. Es capaz de ejecutarse sobre TensorFlow, Microsoft Cognitive Toolkit, R, Thano o PlaidMl.
XLA (álgebra lineal acelerada) es un compilador específico de dominio para álgebra lineal que optimiza los cálculos de flujo de tensor. Los resultados son mejoras en la velocidad, el uso de la memoria y la portabilidad en las plataformas de servidor y móviles.
ML PERF es una amplia suite de referencia ML para medir el rendimiento de los marcos de software ML, los aceleradores de hardware ML y las plataformas ML en la nube.
Tensorflow Playground es un entorno de desarrollo para jugar con una red neuronal en su navegador.
TPU Research Cloud (TRC) es un programa permite a los investigadores solicitar acceso a un clúster de más de 1,000 TPU de nubes sin cargo para ayudarlos a acelerar la próxima ola de avances de investigación.
MLIR es un nuevo marco de representación intermedia y compilador.
La red es una biblioteca para soluciones ML flexibles, controladas e interpretables con limitaciones de forma de sentido común.
Tensorflow Hub es una biblioteca para el aprendizaje automático reutilizable. Descargue y reutilice los últimos modelos capacitados con una cantidad mínima de código.
Tensorflow Cloud es una biblioteca para conectar su entorno local a Google Cloud.
TensorFlow Model Optimization Toolkit es un conjunto de herramientas para optimizar modelos ML para la implementación y ejecución.
TensorFlow Recomenders es una biblioteca para construir modelos de sistemas de recomendación.
El texto de TensorFlow es una colección de clases y operaciones relacionadas con NLP y OPS listos para usar con TensorFlow 2.
TensorFlow Graphics es una biblioteca de funcionalidades de gráficos de computadora que van desde cámaras, luces y materiales hasta renderizadores.
TensorFlow Federated es un marco de código abierto para el aprendizaje automático y otros cálculos en datos descentralizados.
La probabilidad de TensorFlow es una biblioteca para el razonamiento probabilístico y el análisis estadístico.
Tensor2Tensor es una biblioteca de modelos de aprendizaje profundo y conjuntos de datos diseñados para hacer que el aprendizaje profundo sea más accesible y acelerar la investigación de ML.
TensorFlow Privacy es una biblioteca de Python que incluye implementaciones de optimizadores de TensorFlow para capacitar a modelos de aprendizaje automático con privacidad diferencial.
TensorFlow Ranking es una biblioteca para el aprendizaje de las técnicas de clasificar (LTR) en la plataforma TensorFlow.
TensorFlow Agents es una biblioteca para el aprendizaje de refuerzo en TensorFlow.
TensorFlow Addons es un depósito de contribuciones que se ajustan a patrones de API bien establecidos, pero implementan una nueva funcionalidad no disponible en TensorFlow central, mantenida por SIG Addons. TensorFlow es de forma nativa que admite una gran cantidad de operadores, capas, métricas, pérdidas y optimizadores.
TensorFlow E/S es un conjunto de datos, transmisión y extensiones del sistema de archivos, mantenidas por Sig Io.
TensorFlow Quantum es una biblioteca de aprendizaje automático cuántico para la prototipos rápidos de modelos ML de clásicos cuánticos híbridos.
La dopamina es un marco de investigación para la prototipos rápidos de los algoritmos de aprendizaje de refuerzo.
TRFL es una biblioteca para los bloques de construcción de aprendizaje de refuerzo creados por DeepMind.
Mesh TensorFlow es un idioma para el aprendizaje profundo distribuido, capaz de especificar una amplia clase de cálculos de tensor distribuidos.
RaggedTensors es una API que facilita almacenar y manipular datos con forma no uniforme, incluidos texto (palabras, oraciones, caracteres) y lotes de longitud variable.
Unicode OPS es una API que admite trabajar con texto Unicode directamente en TensorFlow.
Magenta es un proyecto de investigación que explora el papel del aprendizaje automático en el proceso de creación de arte y música.
Nucleus es una biblioteca de código Python y C ++ diseñado para facilitar la lectura, escribir y analizar datos en formatos de archivo genómicos comunes como SAM y VCF.
Sonnet es una biblioteca de DeepMind para construir redes neuronales.
El aprendizaje estructurado neural es un marco de aprendizaje para capacitar a las redes neuronales aprovechando señales estructuradas además de las entradas de entradas.
La remediación del modelo es una biblioteca para ayudar a crear y entrenar modelos de una manera que reduzca o elimine el daño del usuario resultante de los sesgos de rendimiento subyacentes.
Los indicadores de equidad es una biblioteca que permite el cálculo fácil de métricas de equidad comúnmente identificadas para clasificadores binarios y multiclase.
Decision Forests es un algoritmos de última generación para capacitar, servir e interpretar modelos que utilizan bosques de decisión para la clasificación, regresión y clasificación.
Volver a la cima

Core ML es un marco de Apple para integrar modelos de aprendizaje automático en aplicaciones que se ejecutan en dispositivos Apple (incluidos iOS, WatchOS, MacOS y TVOS). Core ML introduce un formato de archivo público (.mlmodel) para un amplio conjunto de métodos ML que incluyen redes neuronales profundas (tanto convolucionales como recurrentes), conjuntos de árboles con impulso y modelos lineales generalizados. Los modelos en este formato se pueden integrar directamente en aplicaciones a través de Xcode.
Introducción a Core ML
Integrando un modelo ML central en su aplicación
Modelos ML Core ML
Referencia de API de Core ML
Especificación ML del núcleo
Foros de desarrolladores de Apple para Core ML
Cursos ML de Top Core en línea | Udemy
Cursos ML de Top Core en línea | Coursera
IBM Watson Services para Core ML | IBM
Genere activos ML Core utilizando IBM Maximo Visual Inspection | IBM
Core ML Tools es un proyecto que contiene herramientas de soporte para la conversión, edición y validación del modelo Core ML.
Create ML es una herramienta que proporciona nuevas formas de capacitar a los modelos de aprendizaje automático en su Mac. Saca la complejidad del entrenamiento modelo mientras produce modelos ML centrales potentes.
Tensorflow_macos es una versión optimizada para Mac de Tensorfl


