bida
v0.9.4
pip install -U bida from bida import ChatLLM
llm = ChatLLM (
model_type = 'openai' , # 调用openai的chat模型
model_name = 'gpt-4' ) # 设定模型为:gpt-4,默认是gpt3.5
result = llm . chat ( "从1加到100等于多少?只计算奇数相加呢?" )
print ( result ) from bida import ChatLLM
llm = ChatLLM (
model_type = "baidu" , # 调用百度文心一言
stream_callback = ChatLLM . stream_callback_func ) # 使用默认的流式输出函数
llm . chat ( "你好呀,请问你是谁?" ) | empresa modelo | tipo de modelo | Nombre del modelo | Ya sea para apoyar | ilustrar |
|---|---|---|---|---|
| AbiertoAI | Charlar | gpt-3.5, gpt-4 | √ | Soporta todos los modelos gpt3.5 y gpt4 |
| Completar texto | texto-davinci-003 | √ | Modelo de clase de generación de texto. | |
| Incrustaciones | incrustación-de-texto-ada-002 | √ | modelo vectorizado | |
| Baidu-Wen Xin Yiyan | Charlar | ernie-bot, ernie-bot-turbo | √ | Modelo de chat comercial de Baidu |
| Incrustaciones | incrustación_v1 | √ | Modelo de vectorización comercial de Baidu. | |
| Modelo alojado | Varios modelos de código abierto | √ | Para varios modelos de código abierto alojados en Baidu, configúrelos usted mismo utilizando el protocolo de acceso a modelos de terceros de Baidu. Para obtener más información, consulte la sección de acceso a modelos a continuación. | |
| Alibaba Cloud-Tongyi Qianwen | Charlar | qwen-v1, qwen-plus-v1, qwen-7b-chat-v1 | √ | Modelos de chat comerciales y de código abierto de Alibaba Cloud |
| Incrustaciones | incrustación de texto-v1 | √ | Modelo de vectorización comercial de Alibaba Cloud | |
| Modelo alojado | Varios modelos de código abierto | √ | Para otros tipos de modelos de código abierto alojados en Alibaba Cloud, configúrelos usted mismo utilizando el protocolo de acceso a modelos de terceros de Alibaba Cloud. Para obtener más información, consulte la sección de acceso a modelos a continuación. | |
| minimax | Charlar | abab5, abab5.5 | √ | Modelo de chat comercial MiniMax |
| chat profesional | abab5.5 | √ | El modelo de chat comercial MiniMax, que utiliza el modo profesional Chatcompletion personalizado, admite escenarios de conversación entre varias personas y varios robots, conversaciones de muestra, restricciones de formato de devolución, llamadas a funciones, complementos y otras funciones. | |
| Incrustaciones | embo-01 | √ | Modelo de vector comercial MiniMax | |
| Sabiduría AI-ChatGLM | Charlar | ChatGLM-Pro, estándar, Lite, carácterglm | √ | Modelo grande comercial multiversión Zhipu AI |
| Incrustaciones | Incrustación de texto | √ | Modelo vectorial de texto comercial Zhipu AI | |
| iFlytek-Spark | Charlar | SparkDesk V1.5, V2.0 | √ | Modelo grande cognitivo iFlytek Spark |
| Incrustaciones | incrustar | √ | Modelo de vector de texto iFlytek Spark | |
| SenseTime-RiRiXin | Charlar | nova-ptc-xl-v1, nova-ptc-xs-v1 | √ | SenseNova SenseTime diario nuevo modelo grande |
| Inteligencia de Baichuan | Charlar | baichuan-53b-v1.0.0 | √ | Baichuan 53B modelo grande |
| Tencent-Hunyuan | Charlar | Tencent Hunyuan | √ | Tencent Hunyuan modelo grande |
| Modelo de código abierto autoimplementado | Chat, finalización, incrustaciones | Varios modelos de código abierto | √ | Al utilizar modelos de código abierto implementados por FastChat y otras implementaciones, la interfaz API web proporcionada sigue las API RESTful compatibles con OpenAI y puede ser compatible directamente. Para obtener más detalles, consulte el capítulo de acceso al modelo a continuación. |
Aviso :
Las dos tecnologías del modelo LLM y la palabra rápida Prompt en AIGC son muy nuevas y se están desarrollando rápidamente. La teoría, los tutoriales, las herramientas, la ingeniería y otros aspectos son muy deficientes. La pila de tecnología utilizada casi no se superpone con la experiencia de los desarrolladores principales actuales. :
| Clasificación | Desarrollo general actual | Proyecto rápido | Desarrollar modelos, ajustar modelos |
|---|---|---|---|
| lenguaje de desarrollo | Java, .Net, Javscript, ABAP, etc. | Lenguaje natural, Python | Pitón |
| herramientas de desarrollo | mucho y maduro | ninguno | Maduro |
| Umbral de desarrollo | inferior y maduro | bajo pero muy inmaduro | muy alto |
| tecnología de desarrollo | claro y estable | Es fácil comenzar pero es muy difícil lograr un resultado constante. | complejo y variado |
| Técnicas comúnmente utilizadas | Orientado a objetos, base de datos, big data | ajuste rápido, aprendizaje incontexto, incorporación | Transformador, RLHF, ajuste fino, LoRA |
| Soporte de código abierto | rico y maduro | Muy confuso en el nivel inferior. | rico pero inmaduro |
| costo de desarrollo | Bajo | más alto | muy alto |
| Revelador | Rico | Extremadamente escaso | muy escaso |
| Desarrollar un modelo colaborativo | Desarrollar según documentos entregados por el gerente de producto. | Una persona o un equipo minimalista puede manejar todas las operaciones, desde los requisitos hasta la entrega. | Desarrollado según direcciones de investigación teórica. |
En la actualidad, casi todas las empresas de tecnología, empresas de Internet y empresas de big data están en esta dirección, pero las empresas más tradicionales todavía están en un estado de confusión. No es que las empresas tradicionales no lo necesiten, sino que: 1) no tienen reservas de talento técnico, por lo que no saben qué hacer; 2) no tienen reservas de hardware y no las tienen; tienen la capacidad para hacerlo; 3) El grado de digitalización empresarial es bajo y la transformación y actualización de AIGC tiene un ciclo largo y resultados lentos.
En la actualidad, hay demasiados modelos comerciales y de código abierto en el país y en el extranjero, y se están desarrollando muy rápidamente. Sin embargo, las API y los objetos de datos de los modelos son diferentes cuando se enfrenta a un nuevo modelo (o incluso uno). nueva versión), tenemos que leer los documentos de desarrollo y Modificar el código de su propia aplicación para adaptarlo. Creo que cada desarrollador de aplicaciones ha probado muchos modelos y debe haber sufrido por ello.
De hecho, aunque las capacidades del modelo son diferentes, los modos para proporcionar capacidades son generalmente los mismos. Por lo tanto, tener un marco que pueda adaptarse a una gran cantidad de API modelo y proporcionar un modo de llamada unificado se ha convertido en una necesidad urgente para muchos desarrolladores.
En primer lugar, bida no pretende reemplazar a langchain, pero sus conceptos de desarrollo y posicionamiento de objetivos también son muy diferentes:
| Clasificación | cadena larga | oferta |
|---|---|---|
| grupo objetivo | El pleno desarrollo se dirige hacia AIGC | Desarrolladores que tienen una necesidad urgente de combinar AIGC con el desarrollo de aplicaciones |
| Soporte de modelo | Admite varios modelos para implementación local o remota | Solo se admiten llamadas de modelos que proporcionan API web. Actualmente, la mayoría de los modelos comerciales la proporcionan también pueden proporcionar API web después de implementarse utilizando marcos como FastChat. |
| estructura del marco | Debido a que proporciona muchas capacidades y una estructura muy compleja, en agosto de 2023, el código central tiene más de 1700 archivos y 150 000 líneas de código, y el umbral de aprendizaje es alto. | Hay más de diez códigos principales y alrededor de 2000 líneas de código. Es relativamente fácil aprender y modificar el código. |
| Soporte de funciones | Proporcionar una cobertura completa de diversos modelos, tecnologías y campos de aplicación en la dirección de AIGC. | Actualmente, brinda soporte para ChatCompletions, Completaciones, Incrustaciones, Llamadas a funciones y otras funciones, y en un futuro próximo se lanzarán funciones multimodales como voz e imagen. |
| Inmediato | Se proporcionan plantillas de avisos, pero los avisos utilizados por sus propias funciones están integrados en el código, lo que dificulta la depuración y modificación. | Se proporcionan plantillas de avisos. Actualmente, no hay una función incorporada para usar Aviso. Si se usa en el futuro, se usará el modo de carga posterior basado en configuración para facilitar los ajustes del usuario. |
| Conversación y Memoria | Admite y proporciona múltiples métodos de administración de memoria. | Soporte, soporte de persistencia de conversación (guardado en duckdb), la memoria proporciona capacidades de sesión de archivo limitadas y el marco de extensión puede ampliar otras capacidades. |
| Función y complemento | Admite y proporciona ricas capacidades de expansión, pero el efecto de uso depende de las propias capacidades del modelo grande. | Compatible con modelos grandes que utilizan la especificación de llamada de función de OpenAI |
| Agente y cadena | Admite y proporciona ricas capacidades de expansión, pero el efecto de uso depende de las propias capacidades del modelo grande. | No es compatible, planeamos abrir otro proyecto para implementarlo, o podemos expandirnos y desarrollarnos por nuestra cuenta según el marco actual. |
| Otras funciones | Admite muchas otras funciones, como la división de documentos (incrustación después de la división, utilizada para implementar chatpdf y otras funciones similares) | Actualmente no hay otras funciones. Si se agregan, se implementarán abriendo un nuevo proyecto compatible. Actualmente, se pueden implementar utilizando la combinación de capacidades proporcionadas por otros productos. |
| Eficiencia operativa | Muchos desarrolladores informan que es más lento que llamar directamente a la API y se desconoce el motivo. | Solo encapsula el proceso de llamada y unifica la interfaz de llamada, y el rendimiento no es diferente de llamar a la API directamente. |
Como proyecto líder de código abierto en la industria, langchain ha hecho grandes contribuciones a la promoción de modelos grandes y AGI. También lo hemos aplicado en el proyecto. Al mismo tiempo, también aprovechamos muchos de sus modelos e ideas durante el desarrollo. bida. Pero langchain quiere ser una herramienta grande y completa, lo que inevitablemente conduce a muchas deficiencias. Los siguientes artículos tienen opiniones similares: Max Woolf - chino, Hacker News - chino.
Un dicho popular en el círculo lo resume muy bien: langchain es un libro de texto que todos aprenderán, pero que eventualmente desecharán.
Instale la última bida desde pip o pip3
pip install -U bidaClonar el código del proyecto desde github al directorio local:
git clone https://github.com/pfzhou/bida.git
pip install -r requirements.txtModifique el archivo en el directorio raíz del código actual: la extensión de ".env.template" se convierte en el archivo de variable de entorno ".env" . Configure la clave del modelo que ha solicitado según las instrucciones del archivo.
Tenga en cuenta : este archivo se ha agregado a la lista de ignorados y no se transmitirá al servidor git.
ejemplos1.Entorno de inicialización.ipynb
El siguiente código de demostración utilizará una variedad de modelos compatibles con bida. Modifique y reemplace el valor **[model_type]** en el código con el nombre de la empresa del modelo correspondiente según el modelo que compró. Puede cambiar rápidamente entre varios modelos. por experiencia:
# 更多信息参看bidamodels*.json中的model_type配置
# openai
llm = ChatLLM ( model_type = "openai" )
# baidu
llm = ChatLLM ( model_type = "baidu" )
# baidu third models(llama-2...)
llm = ChatLLM ( model_type = "baidu-third" )
# aliyun
llm = ChatLLM ( model_type = "aliyun" )
# minimax
llm = ChatLLM ( model_type = "minimax" )
# minimax ccp
llm = ChatLLM ( model_type = "minimax-ccp" )
# zhipu ai
llm = ChatLLM ( model_type = "chatglm2" )
# xunfei xinghuo
llm = ChatLLM ( model_type = "xfyun" )
# senstime
llm = ChatLLM ( model_type = "senstime" )
# baichuan ai
llm = ChatLLM ( model_type = "baichuan" )
# tencent ai
llm = ChatLLM ( model_type = "tencent" )Modo de chat: ChatCompletion, el modo de interacción LLM principal actual, bida admite la gestión de sesiones, la persistencia y la gestión de memoria.
from bida import ChatLLM
llm = ChatLLM ( model_type = 'baidu' )
result = llm . chat ( "你好呀,请问你是谁?" )
print ( result ) from bida import ChatLLM
# stream调用
llm = ChatLLM ( model_type = "baidu" , stream_callback = ChatLLM . stream_callback_func )
result = llm . chat ( "你好呀,请问你是谁?" ) from bida import ChatLLM
llm = ChatLLM ( model_type = "baidu" , stream_callback = ChatLLM . stream_callback_func )
result = llm . chat ( "你是一个服务助理,请简洁回答我的问题。我的名字是老周。" )
result = llm . chat ( "我的名字是?" )Para obtener el código detallado anterior y más ejemplos funcionales, consulte el cuaderno a continuación:
ejemplos2.1.Modo chat.ipynb
Construir chatbot usando gradiente
Gradio es un marco de interfaz de procesamiento de lenguaje natural muy popular.
bida + grario puede crear una aplicación utilizable con solo unas pocas líneas de código
import gradio as gr
from bida import ChatLLM
llm = ChatLLM ( model_type = 'openai' )
def predict ( message , history ):
answer = llm . chat ( message )
return answer
gr . ChatInterface ( predict ). launch ()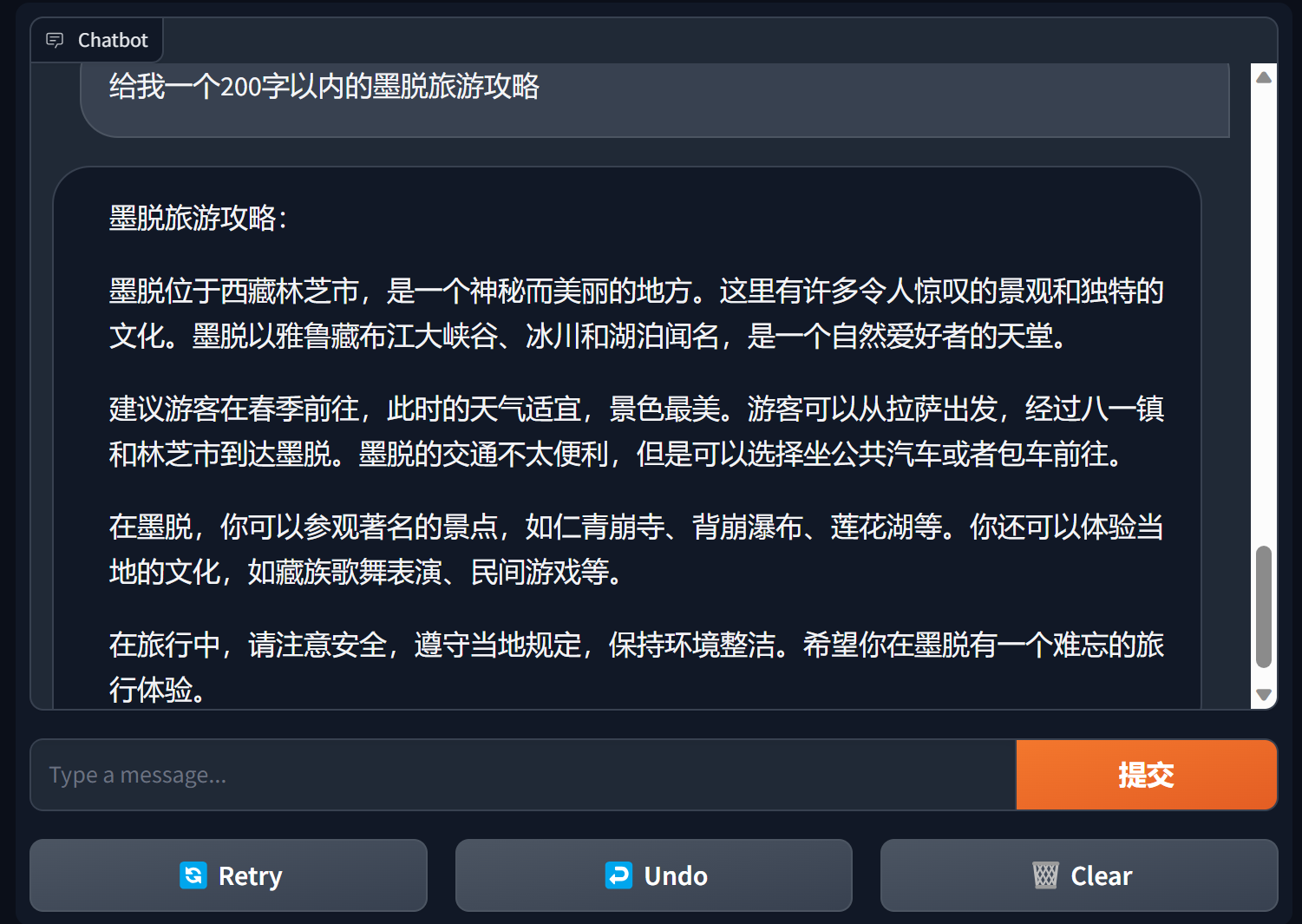
Para más detalles, consulte: demostración del chatbot de bida+gradio
Modo de finalización: Finalizaciones o TextCompletions, el modo de interacción LLM de la generación anterior, solo admite conversaciones de una sola ronda, no guarda registros de chat y cada llamada es una nueva comunicación.
Tenga en cuenta: en el artículo de OpenAI del 6 de julio de 2023, este modelo indica claramente que se eliminará gradualmente. Los nuevos modelos básicamente no proporcionan funciones relevantes. Incluso se estima que los modelos compatibles seguirán a OpenAI y se espera que se eliminen gradualmente. futuro. .
from bida import TextLLM
llm = TextLLM ( model_type = "openai" )
result = llm . completion ( "你是一个服务助理,请简洁回答我的问题。我的名字是老周。" )
print ( result )Para obtener detalles del código de muestra, consulte:
ejemplos2.2.Modo de finalización.ipynb
La palabra rápida Prompt es la función más importante en el modelo de lenguaje grande. Subvierte el modelo de desarrollo tradicional orientado a objetos y lo transforma en: Proyecto Prompt . Este marco se implementa mediante "Prompt Templete", que admite funciones como etiquetas de reemplazo, configuración de diferentes palabras de aviso para múltiples modelos y reemplazo automático cuando el modelo interactúa.
Actualmente se proporciona PromptTemplate_Text : admite el uso de cadenas de texto para generar plantillas de mensajes, bida también admite plantillas personalizadas flexibles y planea brindar la capacidad de cargar plantillas desde json y bases de datos en el futuro.
Consulte el siguiente archivo para obtener un código de muestra detallado:
ejemplos2.3.Solicitud de aviso word.ipynb
Instrucciones importantes en las palabras clave.
En general, se recomienda que las palabras clave sigan una estructura de tres párrafos: establecer roles, aclarar tareas y dar contexto (información relacionada o ejemplos) . Puede consultar el método de escritura en los ejemplos.
Serie de cursos de Andrew Ng https://learn.deeplearning.ai/login, versión china, interpretación
libro de cocina openai https://github.com/openai/openai-cookbook
Documentación de Microsoft Azure: Introducción a la ingeniería de puntas, tecnología de ingeniería de puntas
La guía de ingeniería rápida más popular en Github, versión china
Function Calling es una función lanzada por OpenAI el 13 de junio de 2023. Todos sabemos que los datos entrenados por ChatGPT se basan en antes de 2021. Si desea hacer algunas preguntas relacionadas en tiempo real, no podremos responderle. y la llamada de funciones permite obtener datos de la red en tiempo real, como verificar pronósticos del tiempo, verificar acciones, recomendar películas recientes, etc.
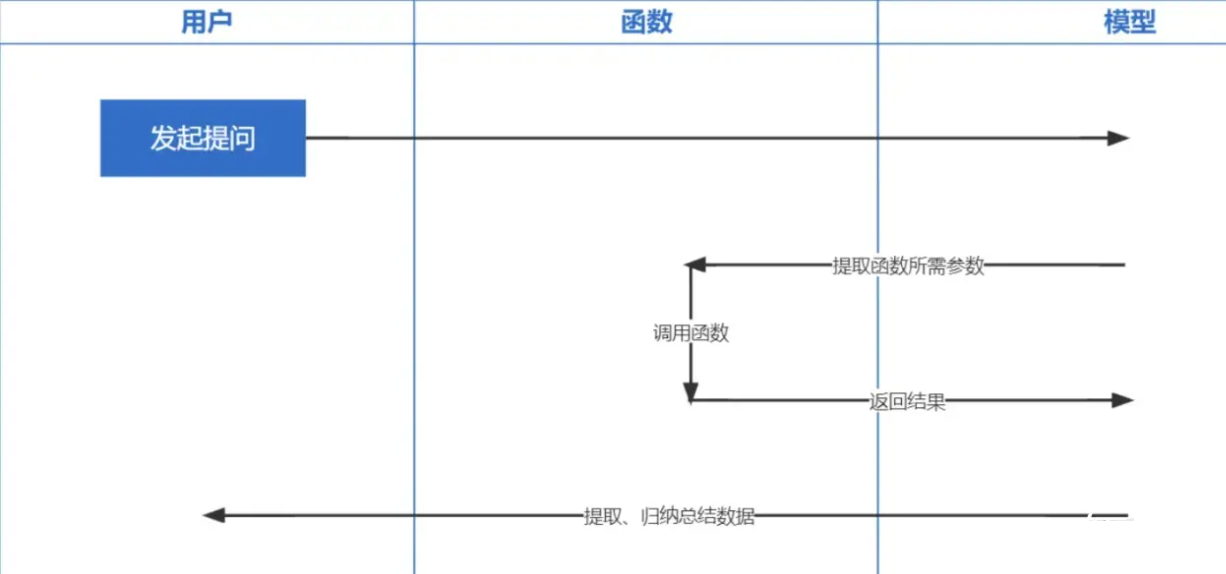
La tecnología de incrustación es la tecnología más importante para implementar Prompt inContext Learning. En comparación con la recuperación de palabras clave anterior, es un paso adelante.
Nota : La incorporación de datos de diferentes modelos no es universal, por lo que se debe utilizar el mismo modelo para incorporar la pregunta durante la recuperación.
| Nombre del modelo | Dimensiones de salida | Número de registros de lote | Límite de token de texto único |
|---|---|---|---|
| AbiertoAI | 1536 | Sin límite | 8191 |
| Baidu | 384 | 16 | 384 |
| Alí | 1536 | 10 | 2048 |
| minimax | 1536 | Sin límite | 4096 |
| Espectro de sabiduría IA | 1024 | Soltero | 512 |
| chispa iFlytek | 1024 | Soltero | 256 |
Nota: la interfaz de incrustación de bida admite el procesamiento por lotes. Si se excede el límite de procesamiento por lotes del modelo, se procesará automáticamente en lotes y se devolverá juntos. Si el contenido de un solo fragmento de texto excede el número limitado de tokens, según la lógica del modelo, algunos informarán un error y otros lo truncarán.
Para obtener ejemplos detallados, consulte: ejemplos2.6.Embeddingsembeddingmodel.ipynb
├─bida # bida框架主目录
│ ├─core # bida框架核心代码
│ ├─functions # 自定义function文件
│ ├─ *.json # function定义
│ ├─ *.py # 对应的调用代码
│ ├─models # 接入模型文件
│ ├─ *.json # 模型配置定义:openai.json、baidu.json等
│ ├─ *_api.py # 模型接入代码:openai_api.py、baidu_api.py等
│ ├─ *_sdk.py # 模型sdk代码:baidu_sdk.py等
│ ├─prompts # 自定义prompt模板文件
│ ├─*.py # 框架其他代码文件
├─docs # 帮助文档
├─examples # 演示代码、notebook文件和相关数据文件
├─test # pytest测试代码
│ .env.template # .env的模板
│ LICENSE # MIT 授权文件
│ pytest.ini # pytest配置文件
│ README.md # 本说明文件
│ requirements.txt # 相关依赖包
Esperamos adaptarnos a más modelos y agradecemos sus valiosas opiniones para brindar a los desarrolladores mejores productos juntos.


