llm data annotation
1.0.0
Este marco combina la experiencia humana con la eficiencia de los modelos de lenguajes grandes (LLM) como GPT-3.5 de OpenAI para simplificar la anotación de conjuntos de datos y la mejora del modelo. El enfoque iterativo garantiza la mejora continua de la calidad de los datos y, en consecuencia, el rendimiento de los modelos ajustados con estos datos. Esto no solo ahorra tiempo sino que también permite la creación de LLM personalizados que aprovechan tanto los anotadores humanos como la precisión basada en LLM.
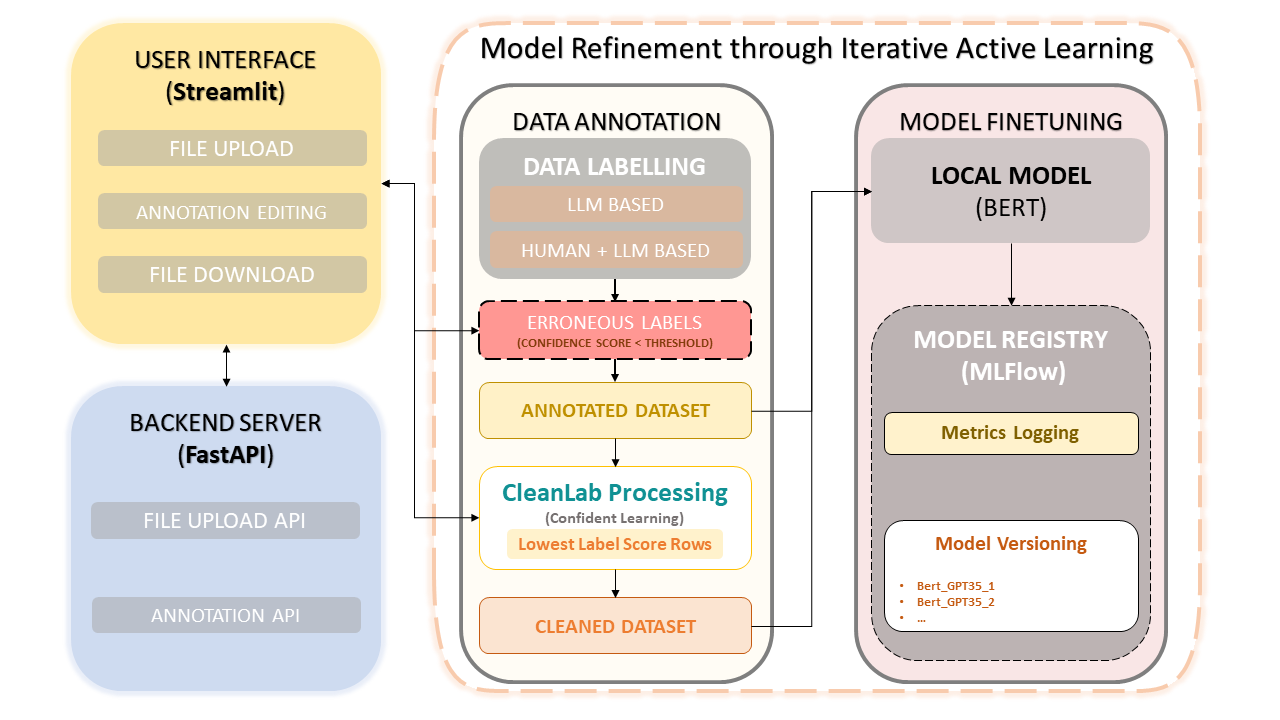
Carga y anotación de conjuntos de datos
Correcciones de anotaciones manuales
CleanLab: enfoque de aprendizaje seguro
Versionado y guardado de datos
Entrenamiento modelo
pip install -r requirements.txtInicie el backend de FastAPI :
uvicorn app:app --reloadEjecute la aplicación Streamlit :
streamlit run frontend.pyInicie la interfaz de usuario de MLflow : para ver modelos, métricas y modelos registrados, puede acceder a la interfaz de usuario de MLflow con el siguiente comando:
mlflow uiAcceda a los enlaces proporcionados en su navegador web :
http://127.0.0.1:5000 .Siga las instrucciones en pantalla para cargar, anotar, corregir y entrenar en su conjunto de datos.
El aprendizaje seguro se ha convertido en una técnica innovadora en el aprendizaje supervisado y la supervisión débil. Su objetivo es caracterizar el ruido de las etiquetas, encontrar errores en las etiquetas y aprender de manera eficiente con etiquetas ruidosas. Al eliminar datos ruidosos y clasificar ejemplos para entrenar con confianza, este método garantiza un conjunto de datos limpio y confiable, lo que mejora el rendimiento general del modelo.
Este proyecto es de código abierto bajo la licencia MIT.


