FinGLM
1.0.0
Enlace de preguntas del concurso | Página de promoción de preguntas del concurso
? FinGLM : Comprometido con la construcción de un gran proyecto de modelo financiero abierto, de bienestar público y duradero, utilizando código abierto para promover "IA + finanzas".
[Actualización del 23/11/2023] Se agregó contenido del curso para los modelos ChatGLM-6B de 1.a, 2.a y 3.a generación, incluidos PPT, videos y documentos técnicos.
【Actualización del 17/11/2023】Se agregó una nueva solución "Nómbrelo como sea"
? Un sistema inteligente interactivo conversacional diseñado para analizar en profundidad los informes anuales de las empresas cotizadas. Frente a los términos profesionales y la información implícita en los textos financieros, nos comprometemos a utilizar la IA para lograr un análisis financiero de nivel experto.
En el campo de la IA, aunque se han logrado avances en el diálogo de texto, los escenarios reales de interacción financiera siguen siendo un gran desafío. Varias instituciones organizaron conjuntamente este concurso para explorar los límites de la IA en el campo financiero.
El informe anual de una empresa que cotiza en bolsa presenta a los inversores el estado operativo, el estado financiero y los planes futuros de la empresa. La experiencia es la clave para la interpretación y nuestro objetivo es hacer que este proceso sea más fácil y preciso a través de la tecnología de inteligencia artificial.
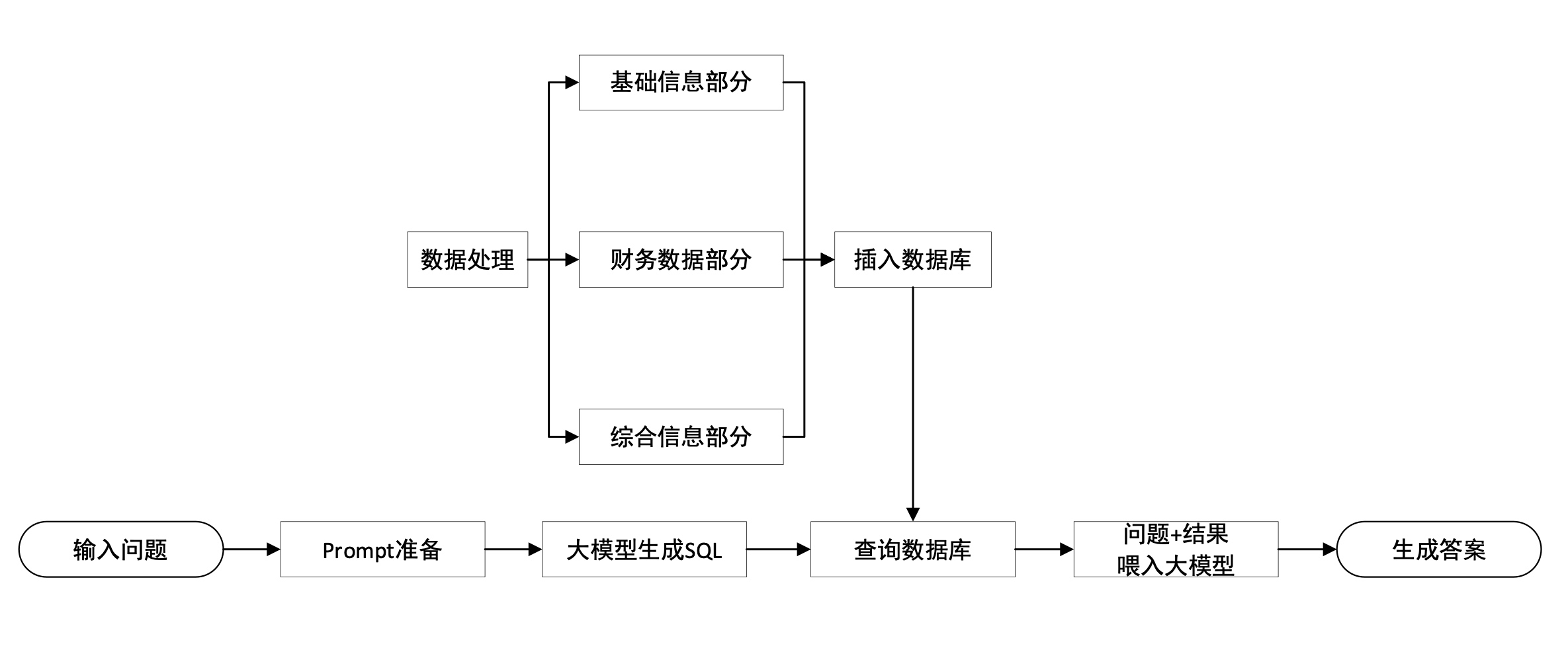
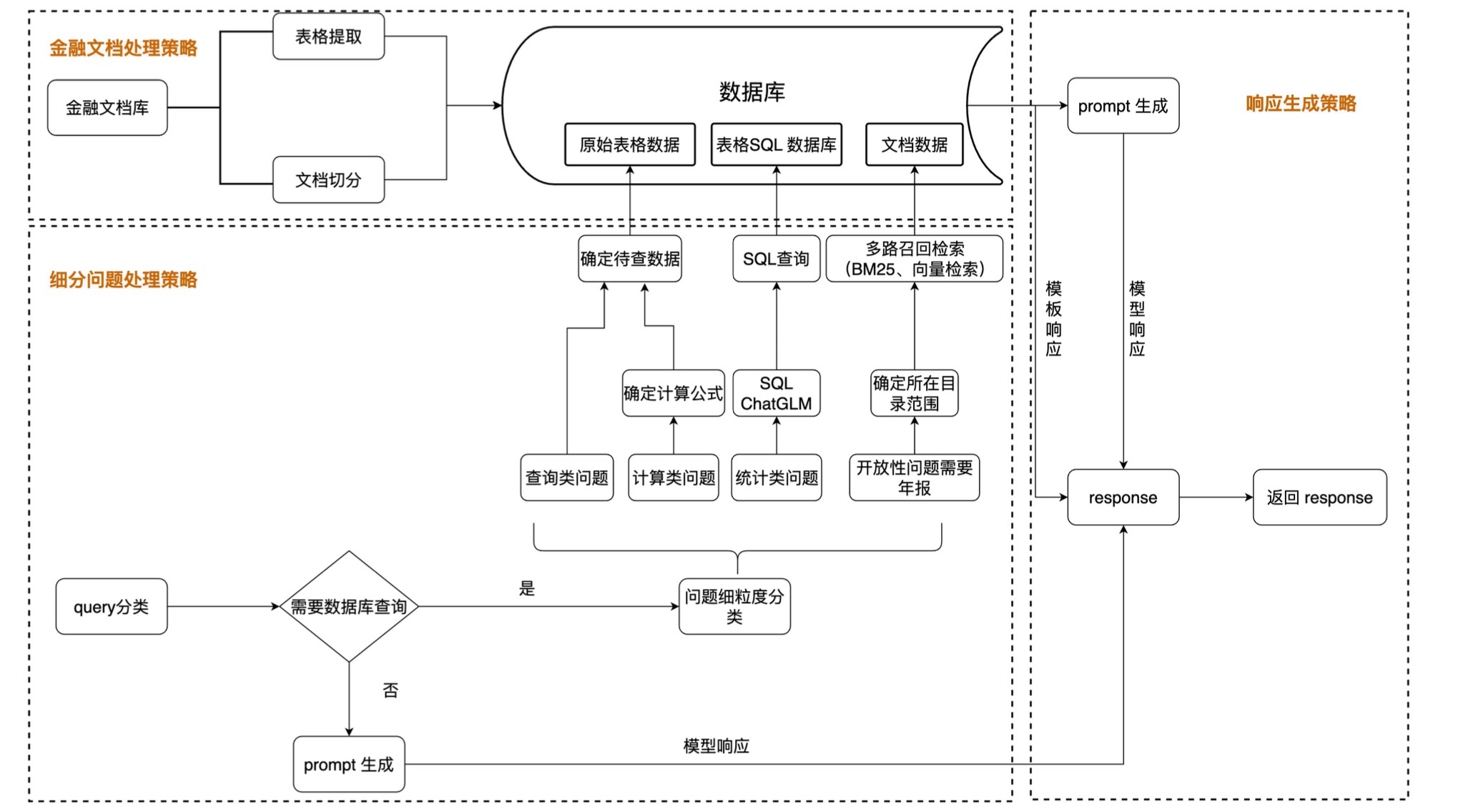
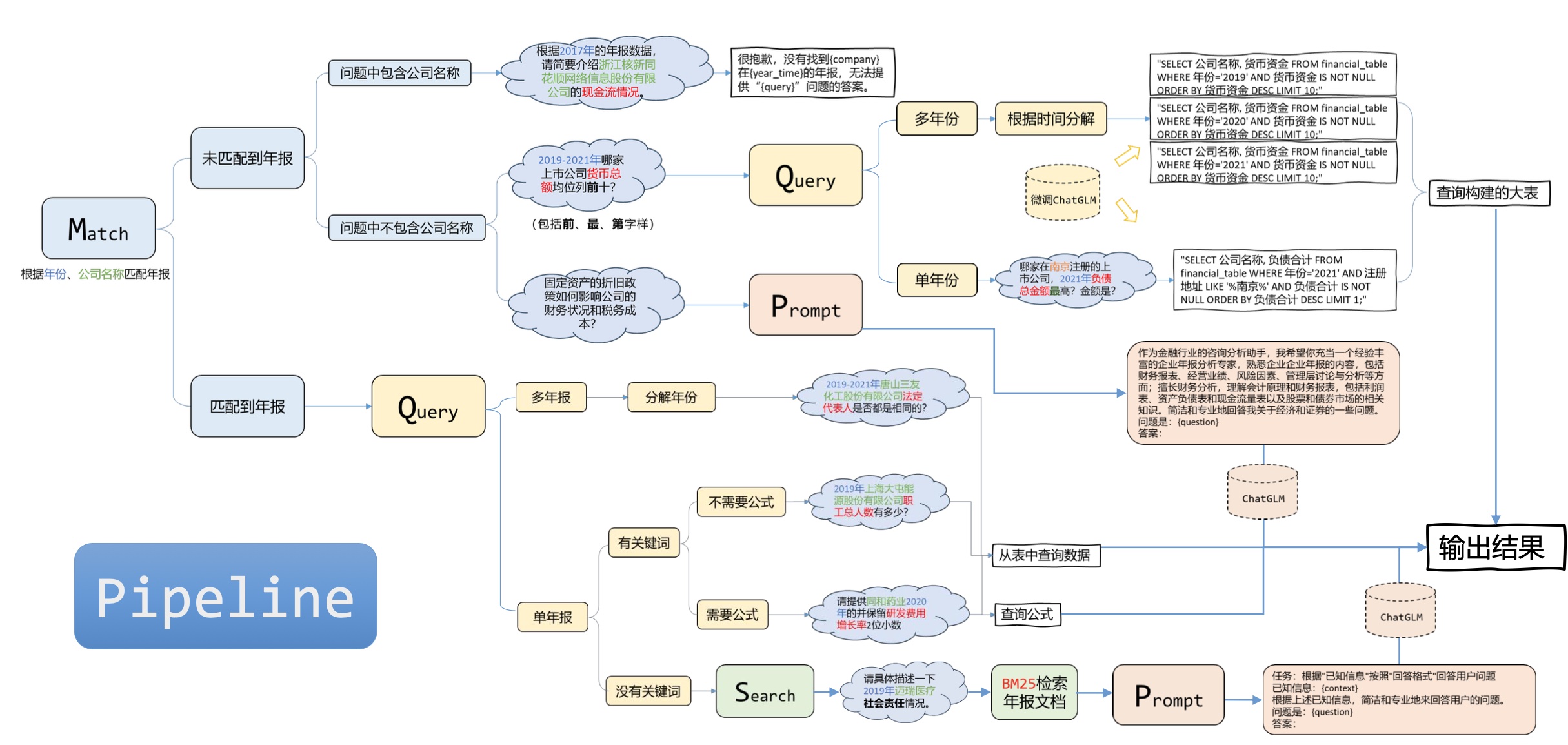
PDF a TXT :
Segmentación de datos :
Procesamiento de datos :
Guardar en la base de datos :
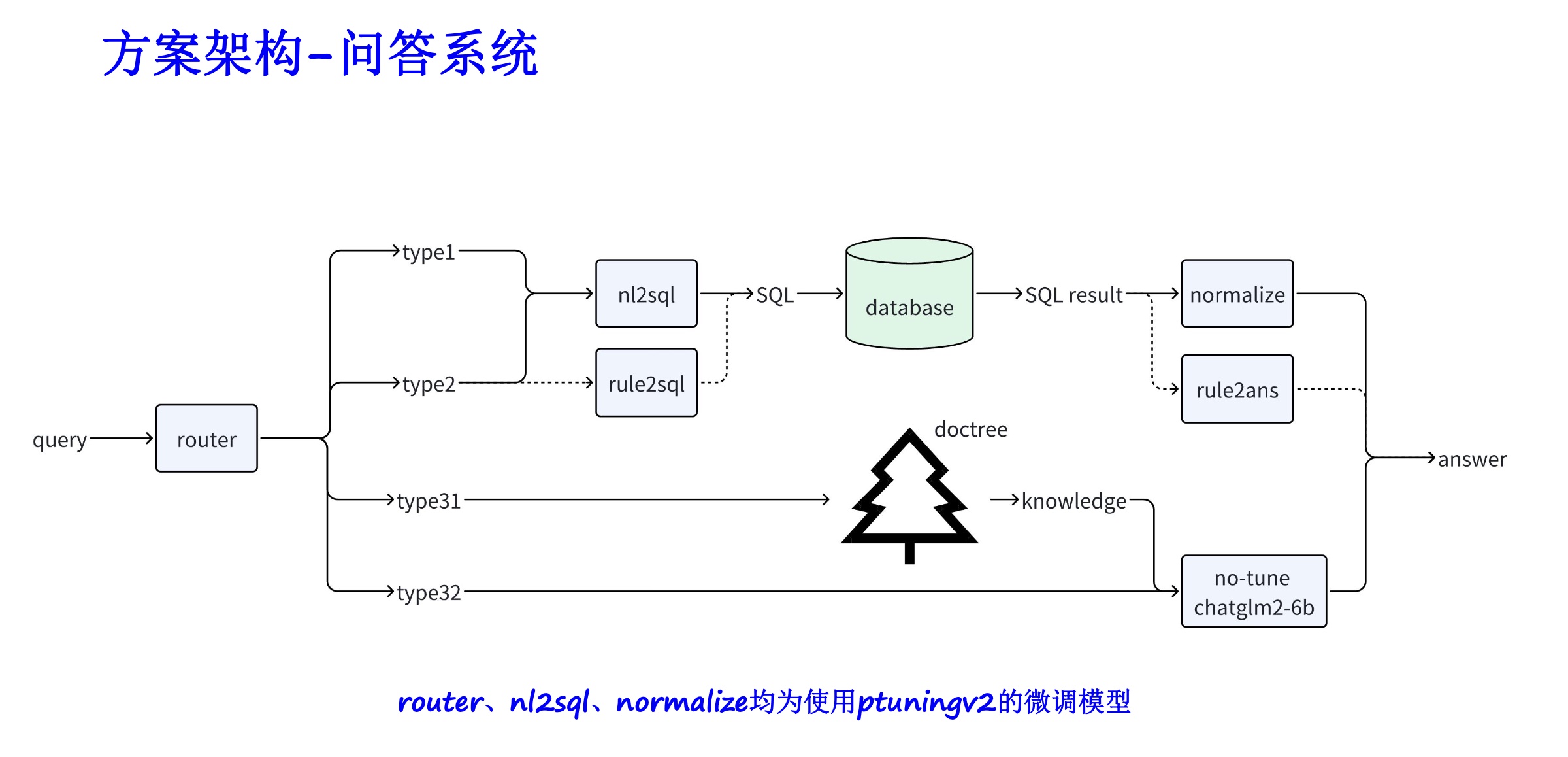
Clasificación de datos : como datos SQL, datos ES, etc.
Seleccione una estrategia de ajuste : como ptuningv2, lora, etc.
Realizar ajustes : según la estrategia seleccionada.
1) Transformación de eventos
2) Datos de código abierto
3) Soluciones/códigos/modelos de código abierto
4) Comunicación abierta
5) Tutoriales de estudio
6) Fondo de recursos del proyecto
Primer número:
pdf2txt.py para analizar archivos PDF. Segunda cuestión:
Blog de introducción del proyecto:
[PPT] [Vídeo][Código]
Este proyecto es una integración del equipo empresarial de exploración ocular de Anshuoshuo basado en su propio proyecto y los proyectos de varios otros equipos. Continuaremos iterando y actualizando este proyecto en el futuro.
[PPT] [Vídeo] [Código] 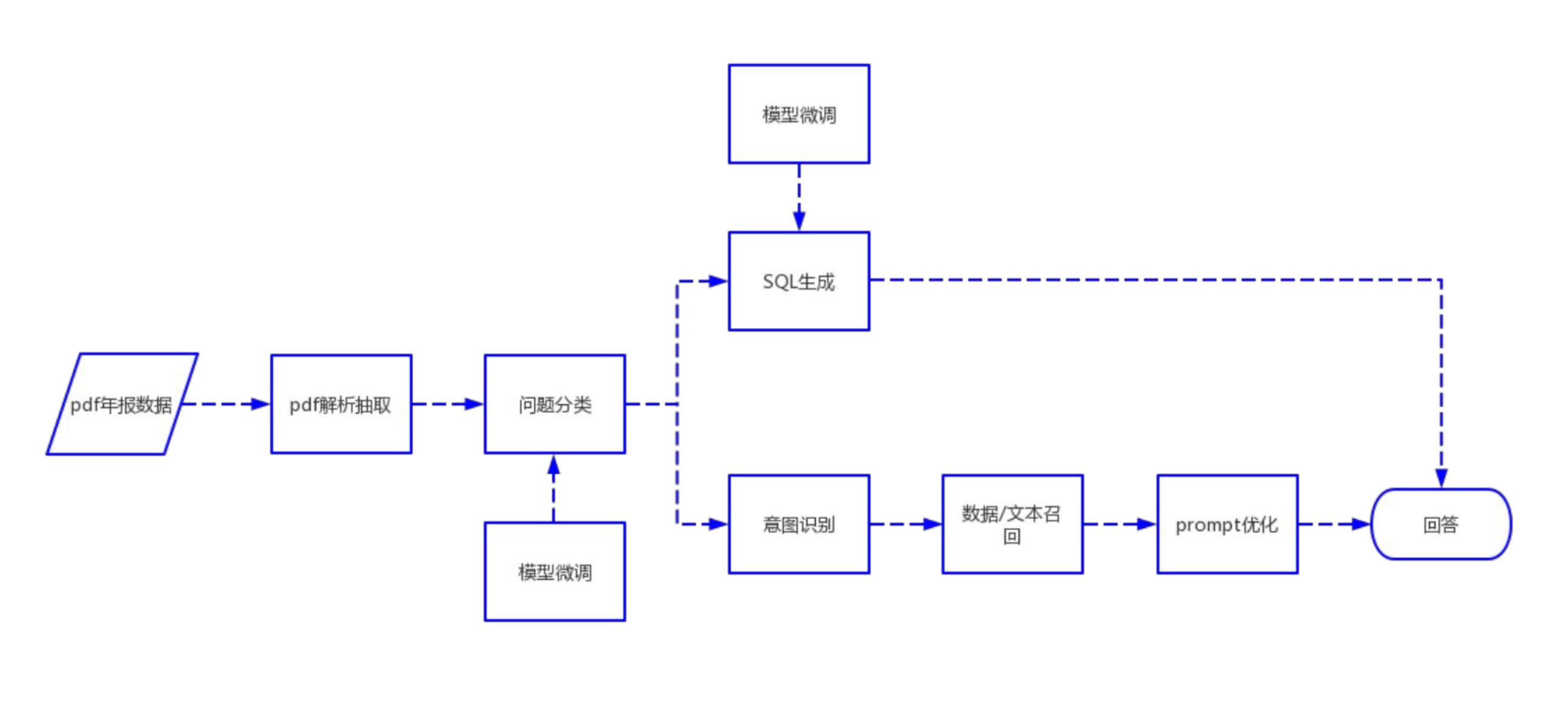
[PPT] [Vídeo] [Código]
[PPT] [Vídeo] [Código]
[PPT] [Vídeo] [Código]
[PPT] [Vídeo] [Código]

[PPT] [Vídeo] [Código]
[PPT] [Vídeo] [Código]
[PPT] [Vídeo] [Código]
[PPT] [Vídeo] [Código]
[PPT] [Vídeo][Código]
Nuestro conjunto de datos de código abierto cubre los informes anuales de algunas empresas que cotizan en bolsa de 2019 a 2021. Este conjunto de datos contiene un total de 11588 archivos PDF detallados (lista). Puede utilizar el contenido de estos archivos PDF para crear la base de datos o biblioteca de vectores que necesita. Para evitar el desperdicio de recursos informáticos, también convertimos los archivos correspondientes en archivos TXT y HTML para que todos puedan usarlos.
Tamaño: 69 GB Formato de archivo: archivo pdf Número de archivos: 11588
carga de git
# 要求安装 git lfs
git clone http://www.modelscope.cn/datasets/modelscope/chatglm_llm_fintech_raw_dataset.git
cargando SDK
# Note:
# 1. 【重要】请将modelscope sdk升级到v1.7.2rc0,执行: pip3 install "modelscope==1.7.2rc0" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
# 2. 【重要】datasets版本限制为 >=2.8.0, <=2.13.0,可执行: pip3 install datasets==2.13.0
from modelscope.msdatasets import MsDataset
# 使用流式方式加载「推荐」
# 无需全量加载到cache,随下随处理
# 其中,通过设置 stream_batch_size 可以使用batch的方式加载
ds = MsDataset.load('chatglm_llm_fintech_raw_dataset', split='train', use_streaming=True, stream_batch_size=1)
for item in ds:
print(item)
# 加载结果示例(单条,pdf:FILE字段值为该pdf文件本地缓存路径,文件名做了SHA转码,可以直接打开)
{'name': ['2020-03-24__北京鼎汉技术集团股份有限公司__300011__鼎汉技术__2019年__年度报告.pdf'], 'pdf:FILE': ['~/.cache/modelscope/hub/datasets/modelscope/chatglm_llm_fintech_raw_dataset/master/data_files/430da7c46fb80d4d095a57b4fb223258ffa1afe8bf53d0484e3f2650f5904b5c']}
# 备注:
1. 自定义缓存路径,可以自行设置cache_dir参数,即 MsDataset.load(..., cache_dir='/to/your/path')
2. 补充数据加载(从9493条增加到11588条),sdk加载注意事项
a) 删除缓存中的csv映射文件(默认路径为): ~/.cache/modelscope/hub/datasets/modelscope/chatglm_llm_fintech_raw_dataset/master/data_files/732dc4f3b18fc52380371636931af4c8
b) 使用MsDataset.load(...) 加载,默认会reuse已下载过的文件,不会重复下载。
Nota: Convierta un archivo de formato pdf a txt para reutilizarlo fácilmente (un archivo está dañado, por lo que el número total es 1 menos que el pdf, 11587 en total)
# Linux
wget https://sail-moe.oss-cn-hangzhou.aliyuncs.com/open_data/hackathon_chatglm_fintech/alltxt.zip
# Windows示例
Invoke-WebRequest -Uri https://sail-moe.oss-cn-hangzhou.aliyuncs.com/open_data/hackathon_chatglm_fintech/alltxt.zip -OutFile D:\alltxt.zip
Nota: Convierta archivos de formato pdf a html para reutilizarlos fácilmente (un archivo está dañado, por lo que el número total es menor que pdf, 11582 en total)
# Linux
wget https://sail-moe.oss-cn-hangzhou.aliyuncs.com/open_data/hackathon_chatglm_fintech/allhtml.zip
# Windows示例
Invoke-WebRequest -Uri https://sail-moe.oss-cn-hangzhou.aliyuncs.com/open_data/hackathon_chatglm_fintech/allhtml.zip -OutFile D:\allhtml.zip
Estos son nuestros pasos recomendados:
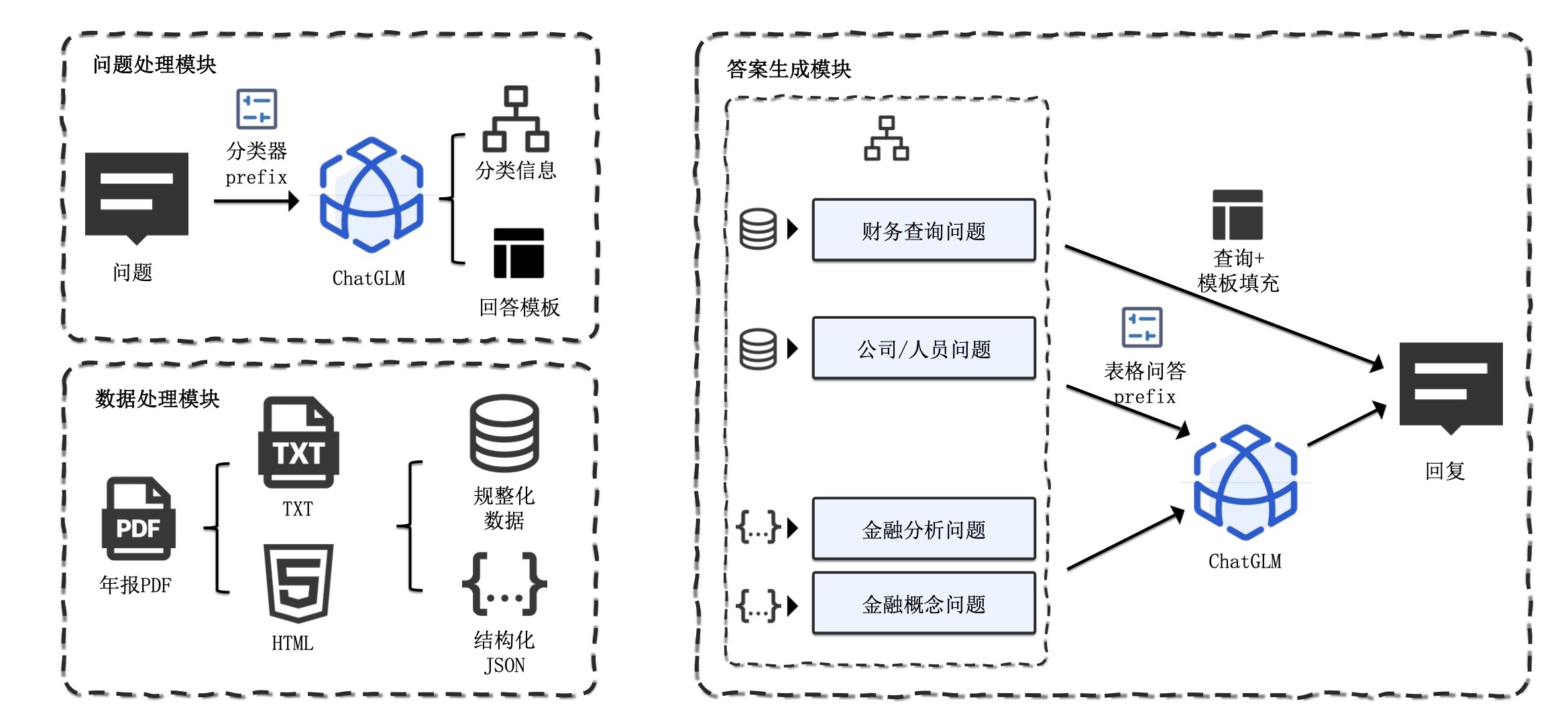
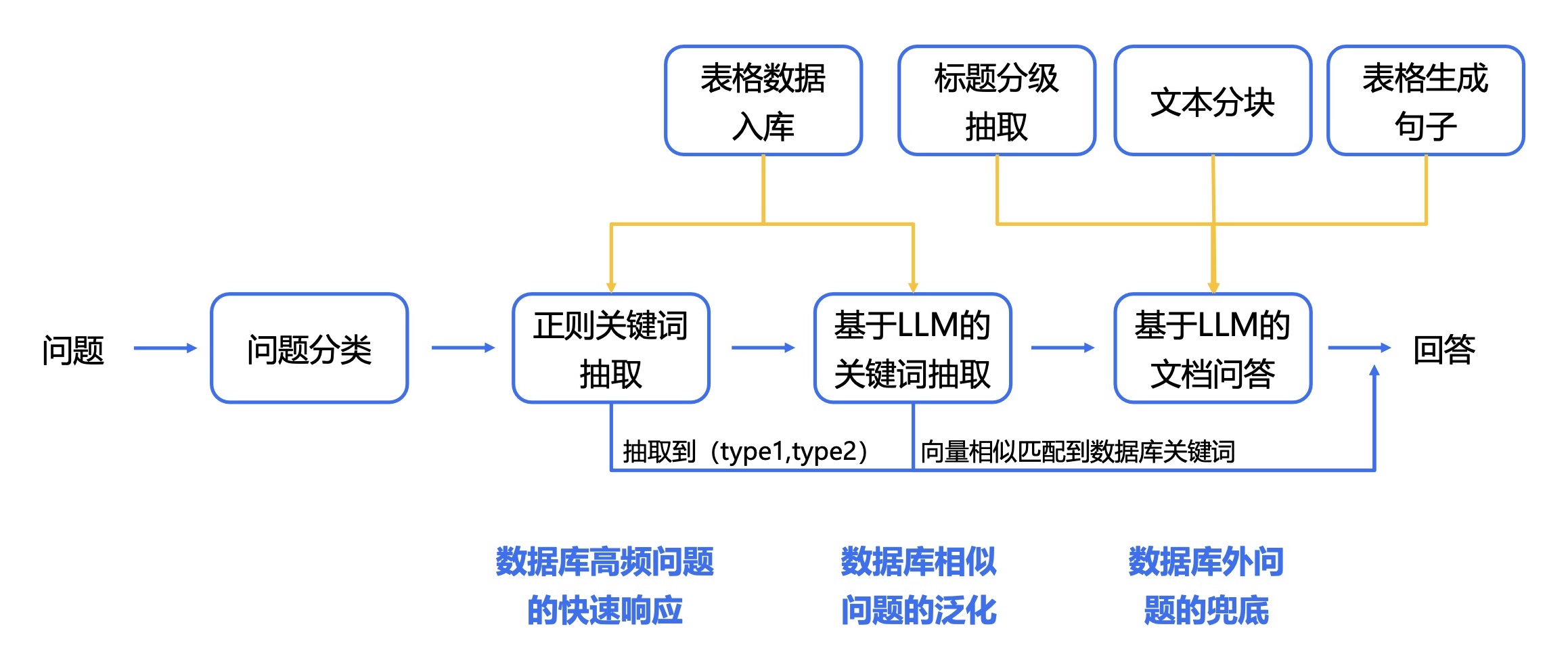
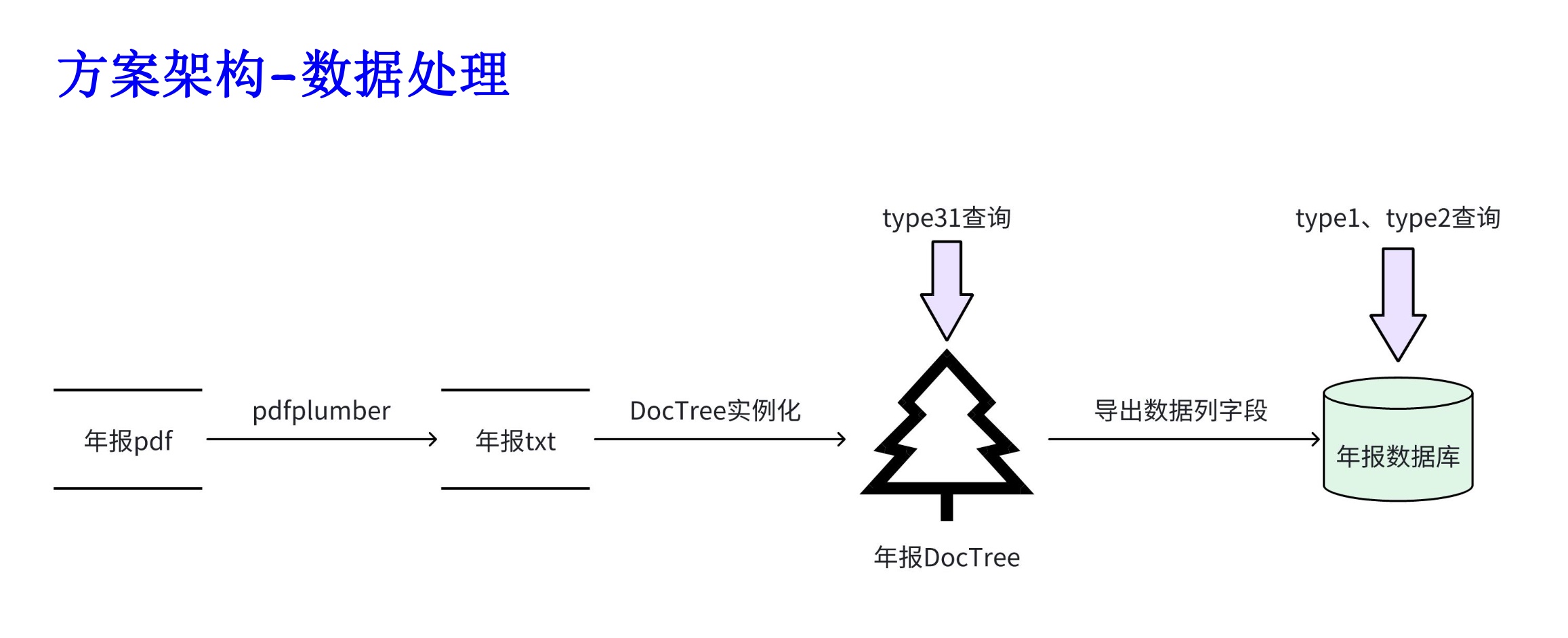
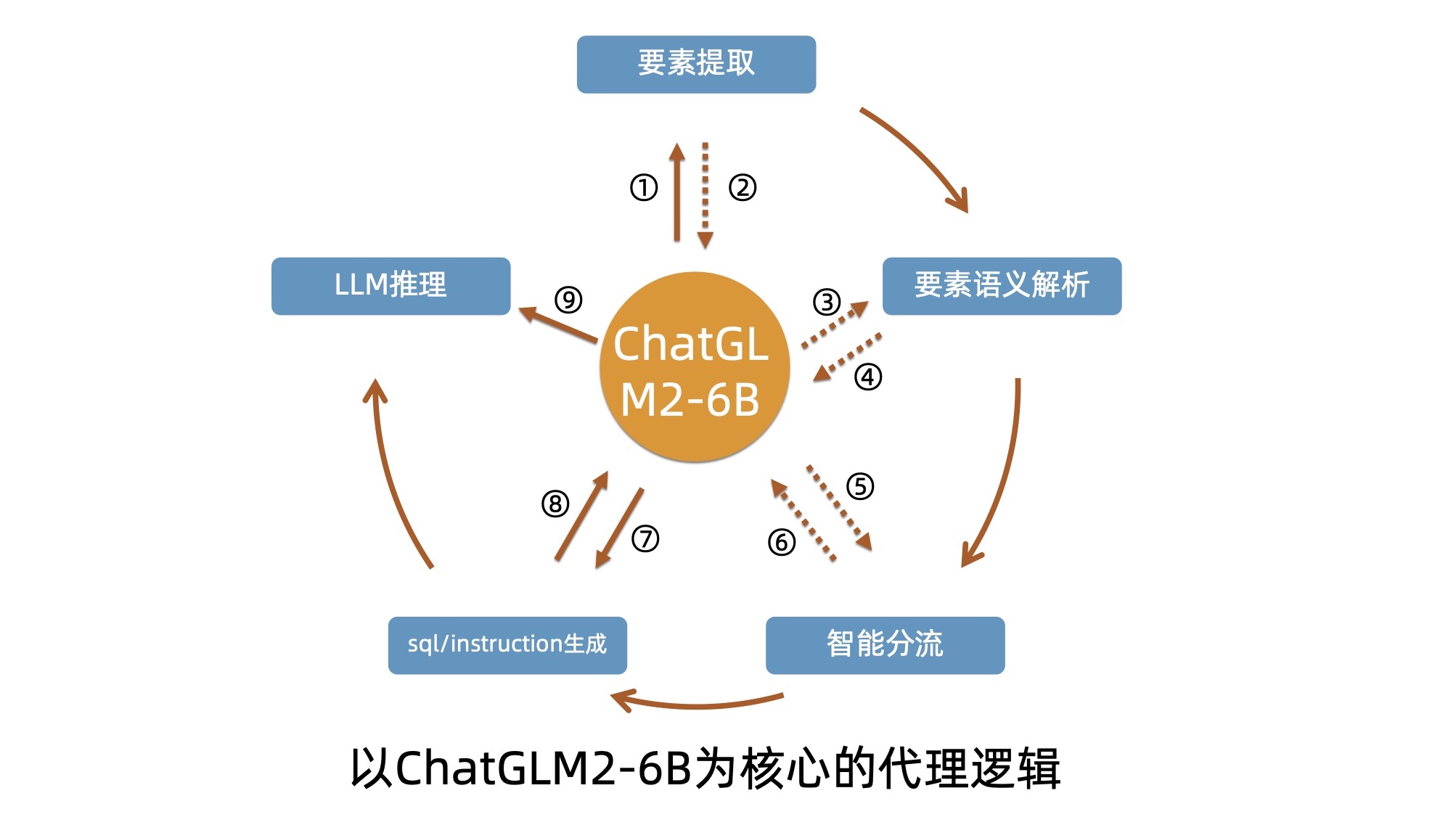
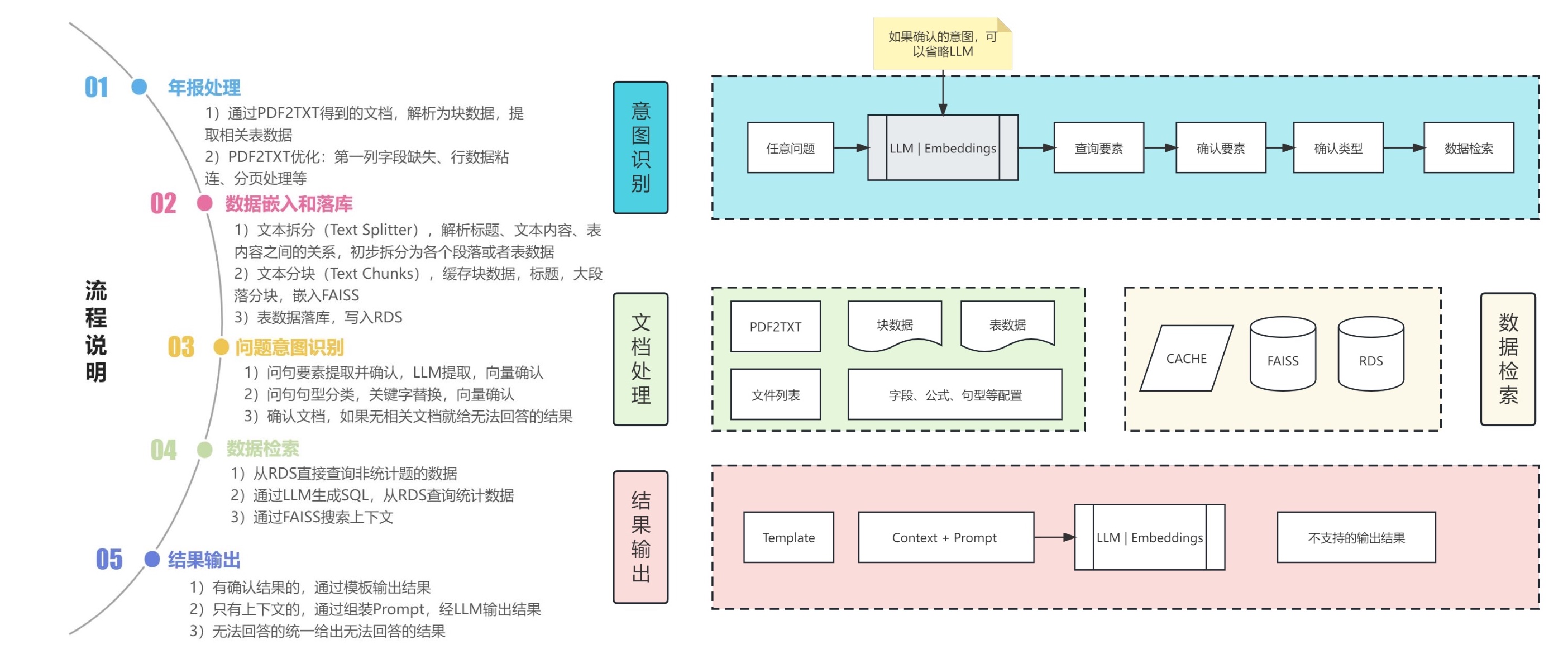
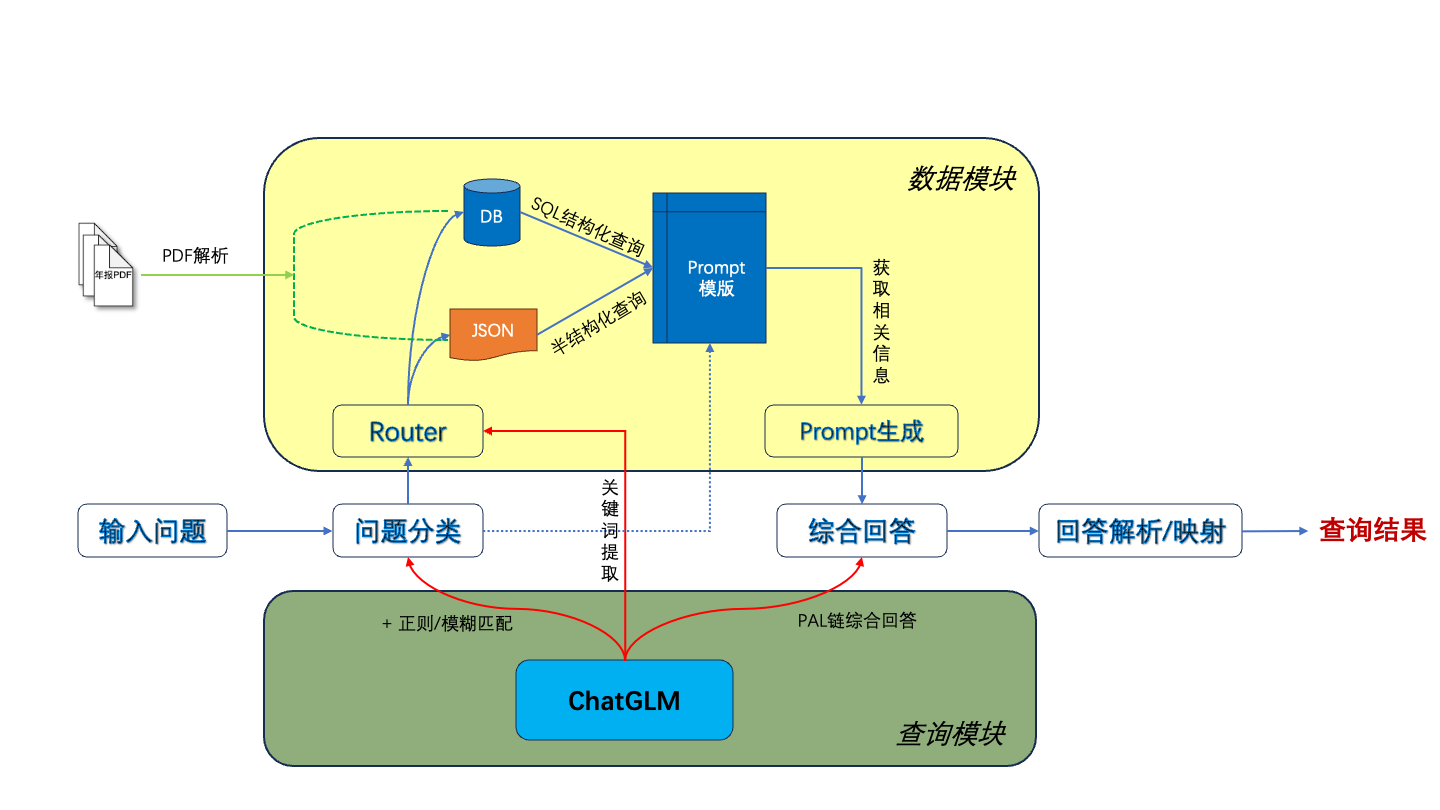
1. Extracción de tablas y textos PDF: puede utilizar kits de herramientas como pdfplomber y pdfminer para extraer texto y datos de tablas de archivos PDF.
2. Segmentación de datos: según la información del directorio, subdirectorio y capítulo del archivo PDF, el contenido se segmenta con precisión.
3. Cree una base de datos financiera básica: diseñe campos y formatos de bases de datos financieras profesionales basados en conocimientos financieros y contenido PDF. Por ejemplo, defina el balance, el estado de flujo de caja, la cuenta de resultados, etc.
4. Extracción de información: utilice las capacidades de extracción de información de modelos grandes y tecnología PNL para extraer la información del campo financiero correspondiente. Por ejemplo, utilice el modo json para generar el contenido del directorio, con el nombre del capítulo como clave y el número de página como valor. Al mismo tiempo, extraiga los datos de la tabla en detalle y envíelos en formato JSON.
5. Construya una base de datos de preguntas y respuestas sobre conocimientos financieros: en combinación con la base de datos financiera construida, aplique modelos grandes para crear una base de datos básica de preguntas y respuestas financieras. Por ejemplo,
{"question":"某公司2021年的财务费用为多少元?", "answer": "某公司2021年的财务费用为XXXX元。"}
prompt:用多种句式修改question及answer的内容。
{"question":"为什么财务费用可以是负的?", "answer": ""}
prompt:请模仿上面的question给出100个类似的问题与对应的答案,用json输出。
6. Cree una biblioteca de vectores: con la ayuda de tecnologías como Word2Vec y Text2Vec, se extraen vectores semánticos de datos de texto originales. Utilice pgvector, una extensión basada en PostgreSQL, para almacenar e indexar estos vectores y crear una biblioteca de vectores a gran escala que pueda consultarse de manera eficiente.
7. Aplicación: combinada con bibliotecas vectoriales, modelos grandes, langchain y otras herramientas para mejorar los efectos de la aplicación.
En el SMP 2023 ChatGLM Financial Large Model Challenge, llevamos a cabo la ronda preliminar, la semifinal A, la semifinal B y la semifinal C respectivamente. Para estas rondas de competición, anotamos manualmente los datos relevantes, con un total de 10.000 entradas.
Ejemplo de datos:
{ "ID" : 1 ,
"question" : "2019年中国工商银行财务费用是多少元?" ,
"answer" : "2019年中国工商银行财务费用是12345678.9元。" }
{ "ID" : 2 ,
"question" : "工商银行2019年营业外支出和营业外收入分别是多少元?" ,
"answer" : "工商银行2019年营业外支出为12345678.9元,营业外收入为2345678.9元。" }
{ "ID" : 3 ,
"question" : "中国工商银行2021年净利润增长率是多少?保留2位小数。" ,
"answer" : "中国工商银行2020年净利润为12345678.90元,2021年净利润为22345678.90元,根据公式,净利润增长率=(净利润-上年净利润)/上年净利润,得出结果中国工商银行2021年净利润增长率81.00%。" }Al mismo tiempo, también escribimos código de revisión para la competencia. Nos basamos en:
Ejemplo de evaluación:
{ "question" : "2019年中国工商银行财务费用是多少元?" ,
"prompt" : { "财务费用" : "12345678.9元" , "key_word" : "财务费用、2019" , "prom_answer" : "12345678.9元" },
"answer" : [
"2019年中国工商银行财务费用是12345678.9元。" ,
"2019年工商银行财务费用是12345678.9元。" ,
"中国工商银行2019年的财务费用是12345678.9元。" ]
}Ejemplo de cálculo de evaluación:
Respuesta 1: Los gastos financieros del ICBC en 2019 fueron de 123.456.78,9 yuanes.
oraciones más similares:
Los gastos financieros del ICBC en 2019 fueron de 12345678,9 yuanes. (Puntuación: 0,9915)
Los gastos financieros del Banco Industrial y Comercial de China en 2019 fueron de 12345678,9 yuanes. (Puntuación: 0,9820)
Los gastos financieros del Banco Industrial y Comercial de China en 2019 fueron de 12345678,9 yuanes. (Puntuación: 0,9720)
Calificación: 0,25+0,25+0,9915*0,5=0,9958 puntos.
Explicación de la puntuación: prom_answer es correcto, contiene todas las palabras clave y tiene la similitud más alta de 0,9915.
Respuesta 2: Los gastos financieros del ICBC en 2019 ascendieron a 335.768,91 yuanes.
Calificación: 0 puntos.
Explicación de la puntuación: los errores de Prom_answer no se puntúan.
Respuesta tres: 12345678,9 yuanes.
oraciones más similares:
Los gastos financieros del ICBC en 2019 fueron de 12345678,9 yuanes. (Puntuación: 0,6488)
Los gastos financieros del Banco Industrial y Comercial de China en 2019 fueron de 12345678,9 yuanes. (Puntuación: 0,6409)
Los gastos financieros del Banco Industrial y Comercial de China en 2019 fueron de 12345678,9 yuanes. (Puntuación: 0,6191)
Calificación: 0,25+0+0,6488*0,5=0,5744 puntos.
Explicación de la puntuación: prom_answer es correcto, no contiene todas las palabras clave y tiene la similitud más alta de 0,6488.
{ "id" : 0 , "question" : "2021年其他流动资产第12高的是哪家上市公司?" , "answer" : "2021年其他流动资产第12高的公司是苏美达股份有限公司。" }
{ "id" : 1 , "question" : "注册地址在重庆的上市公司中,2021年营业收入大于5亿的有多少家?" , "answer" : "2021年注册在重庆,营业收入大于5亿的公司一共有4家。" }
{ "id" : 2 , "question" : "广东华特气体股份有限公司2021年的职工总人数为?" , "answer" : "2021年广东华特气体股份有限公司职工总人数是1044人。" }
{ "id" : 3 , "question" : "在保留两位小数的情况下,请计算出金钼股份2019年的流动负债比率" , "answer" : "2019金钼股份流动负债比率是61.10%。其中流动负债是1068418275.97元;总负债是1748627619.69元;" }
{ "id" : 4 , "question" : "2019年负债总金额最高的上市公司为?" , "answer" : "2019年负债合计最高的是上海汽车集团股份有限公司。" }
{ "id" : 5 , "question" : "2019年总资产最高的前五家上市公司是哪些家?" , "answer" : "2019年资产总计最高前五家是上海汽车集团股份有限公司、中远海运控股股份有限公司、国投电力控股股份有限公司、华域汽车系统股份有限公司、广州汽车集团股份有限公司。" }
{ "id" : 6 , "question" : "2020年营业收入最高的3家并且曾经在宁波注册的上市公司是?金额是?" , "answer" : "注册在宁波,2020年营业收入最高的3家是宁波均胜电子股份有限公司营业收入47889837616.15元;宁波建工股份有限公司营业收入19796854240.57元;宁波继峰汽车零部件股份有限公司营业收入15732749552.37元。" }
{ "id" : 7 , "question" : "注册地址在苏州的上市公司中,2020年利润总额大于5亿的有多少家?" , "answer" : "2020年注册在苏州,利润总额大于5亿的公司一共有2家。" }
{ "id" : 8 , "question" : "浙江运达风电股份有限公司在2019年的时候应收款项融资是多少元?" , "answer" : "2019年浙江运达风电股份有限公司应收款项融资是51086824.07元。" }
{ "id" : 9 , "question" : "神驰机电股份有限公司2020年的注册地址为?" , "answer" : "2020年神驰机电股份有限公司注册地址是重庆市北碚区童家溪镇同兴北路200号。" }
{ "id" : 10 , "question" : "2019年山东惠发食品股份有限公司营业外支出和营业外收入分别是多少元?" , "answer" : "2019年山东惠发食品股份有限公司营业外收入是1018122.97元;营业外支出是2513885.46元。" }
{ "id" : 11 , "question" : "福建广生堂药业股份有限公司2020年年报中提及的财务费用增长率具体是什么?" , "answer" : "2020福建广生堂药业股份有限公司财务费用增长率是34.33%。其中,财务费用是7766850.48元;上年财务费用是5781839.51元。" }
{ "id" : 12 , "question" : "华灿光电股份有限公司2021年的法定代表人与上年相比相同吗?" , "answer" : "不相同,华灿光电股份有限公司2020年法定代表人是俞信华,2021年法定代表人是郭瑾。" }
{ "id" : 13 , "question" : "请具体描述一下2020年仲景食品控股股东是否发生变更。" , "answer" : "2020年,仲景食品控股股东没有发生变更。" }
{ "id" : 14 , "question" : "什么是其他债权投资?" , "answer" : "其他债权投资是指企业或机构投资者通过购买债券、贷款、定期存款等金融产品获得的固定收益。这些金融产品通常由政府、公司或其他机构发行,具有一定的信用等级和风险。 n n其他债权投资是企业或机构投资组合中的一部分,通常用于稳定收益和分散风险。与股票投资相比,其他债权投资的风险较低,但收益也相对较低。 n n其他债权投资的管理和投资策略与其他资产类别类似,包括分散投资、风险控制、收益最大化等。然而,由于其他债权投资的种类繁多,其投资和管理也存在一定的特殊性。" }[PPT] [Vídeo][Documentación técnica]
[PPT] [Vídeo][Documentación técnica]
[PPT] [Vídeo][Documentación técnica]
Los siguientes son los equipos e individuos que contribuyeron a este proyecto:
El proyecto de código abierto FinGLM tiene fines completamente de bienestar público y todos los desarrolladores pueden postularse para unirse. Por supuesto, realizaremos una revisión estricta. Si está interesado, por favor complete el formulario.
Los recursos relacionados con este proyecto son solo para investigación y comunicación y, en general, no se recomiendan para uso comercial. Si se utilizan con fines comerciales, asuma los riesgos legales causados por ello.
Cuando se trata del uso comercial de modelos, asegúrese de seguir los protocolos de los modelos relevantes, como ChatGLM-6B.





