CDial GPT
1.0.0
Este proyecto proporciona un conjunto de datos de conversación en chino a gran escala y un modelo de preentrenamiento de conversación en chino (modelo GPT chino) en este conjunto de datos. Para obtener más información, consulte nuestro documento.
El código de este proyecto se modifica de TransferTransfo y utiliza la versión HuggingFace Pytorch de la biblioteca Transformers, que se puede utilizar para entrenamiento previo y ajuste.
from datasets import load_dataset
dataset = load_dataset ( "lccc" , "base" ) # or "large" El conjunto de datos LCCC (Conversación china limpia a gran escala) que proporcionamos consta principalmente de dos partes: LCCC-base (Baidu Netdisk, Google Drive) y LCCC-large (Baidu Netdisk, Google Drive). Diseñamos un estricto proceso de filtrado de datos para. garantizar la calidad de los datos de conversación en este conjunto de datos. Este proceso de filtrado de datos incluye una serie de reglas manuales y varios clasificadores basados en algoritmos de aprendizaje automático. El ruido que filtramos incluye: palabras sucias, caracteres especiales, expresiones faciales, oraciones gramaticales, diálogos irrelevantes, etc.
Las estadísticas de este conjunto de datos se muestran en la siguiente tabla. Entre ellos, llamamos al diálogo que contiene solo dos oraciones "diálogo de un solo turno", y al diálogo que contiene más de dos oraciones lo llamamos "diálogo de múltiples turnos". Utilice la segmentación de palabras de Jieba al contar el tamaño de la lista de palabras.
| Base LCCC (Disco en la nube de Baidu, Google Drive) | conversación de un solo turno | Múltiples rondas de diálogo |
|---|---|---|
| el diálogo total gira | 3.354.232 | 3.466.274 |
| Total de frases de diálogo. | 6.708.464 | 13.365.256 |
| Caracteres totales | 68.559.367 | 163.690.569 |
| Tamaño del vocabulario | 372.063 | 666.931 |
| Número promedio de palabras en oraciones conversacionales | 6,79 | 8.32 |
| Número promedio de oraciones por ronda de conversación | 2 | 3.86 |
Tenga en cuenta que el proceso de limpieza del conjunto de datos base LCCC es más estricto que el del LCCC grande, por lo que su tamaño también es menor.
| LCCC-grande (Disco en la nube de Baidu, Google Drive) | conversación de un solo turno | Múltiples rondas de diálogo |
|---|---|---|
| el diálogo total gira | 7.273.804 | 4.733.955 |
| Total de frases de diálogo. | 14.547.608 | 18.341.167 |
| Caracteres totales | 162.301.556 | 217.776.649 |
| Tamaño del vocabulario | 662,514 | 690.027 |
| Número de palabras de evaluación para oraciones conversacionales. | 7.45 | 8.14 |
| Número promedio de oraciones por ronda de conversación | 2 | 3.87 |
Los datos de conversación originales en el conjunto de datos base LCCC provienen de conversaciones de Weibo, y los datos de conversación originales en el conjunto de datos grande de LCCC se integran con otros conjuntos de datos de conversación de código abierto basados en estas conversaciones de Weibo:
| conjunto de datos | el diálogo total gira | Ejemplo de conversación |
|---|---|---|
| Corpus de Weibo | 79M | P: Comí estofado siete u ocho veces en Chengdu, Chongqing. R: ¡Jajajaja! ¡Entonces mi boca podría pudrirse! |
| Corpus de chismes de PTT | 0,4 millones | P: ¿Por qué los aldeanos siempre intimidan a los estudiantes de secundaria? P: Si crees que si eliges una buena materia te convertirás en Bill Gates, entonces también podrías abandonar la escuela. |
| Corpus de subtítulos | 2,74 millones | Pregunta: La gente en la ópera de Beijing no es libre. R: Ponen a la gente en jaulas. |
| Corpus Xiaohuangji | 0,45 millones | P: ¿Alguna vez has estado enamorado? A: ¿Alguna vez has estado enamorado? Oh, no lo menciones, estoy triste... |
| Corpus Tieba | 2,32 millones | P: En primera fila, todos los fanáticos de Lu se están levantando, ¿verdad? R: El título dice asistencias, pero después de ver esa pelota, es realmente una ironía viviente. |
| Corpus Qingyun | 0,1 millones | P: Parece que amas mucho el dinero. R: Oh, ¿en serio? Entonces ya casi has llegado |
| Corpus de conversación de Douban | 0,5 millones | P: Aprende inglés puro viendo películas originales en inglés R: Me encanta Friends y lo he visto muchas veces P: Estoy casi agotado de ver el mismo CD R: Entonces tu inglés debería ser bastante bueno ahora |
| Corpus de conversación comercial electrónica | 0,5 millones | P: ¿Será una buena oferta? R: Todavía no. P: ¿Estará disponible en el futuro? R: No estoy seguro. |
| Corpus de chat chino | 0,5 millones | P: Mis piernas están inútiles hoy. Ustedes están celebrando la festividad, así que moveré ladrillos. R: Es un trabajo duro, incluso fui a ganar mucho dinero en Navidad. Soy una persona sin novio. Es lo mismo para cualquier día festivo. |
También proporcionamos una serie de modelos chinos de preentrenamiento (modelos GPT chinos). El proceso de preentrenamiento de estos modelos se divide en dos pasos: primero, el preentrenamiento con datos novedosos chinos y luego el preentrenamiento con datos LCCC. colocar.
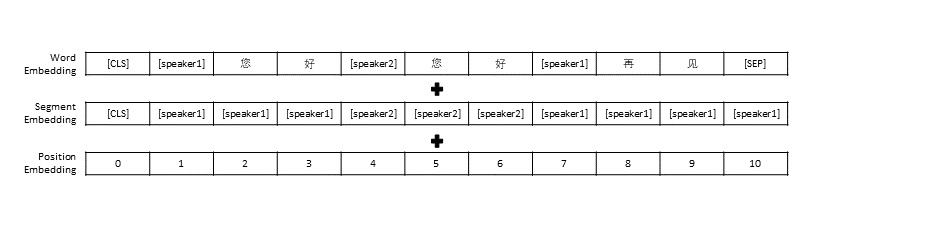
Seguimos la configuración de preprocesamiento de datos en TransferTransfo, que unió todo el historial de conversaciones en una oración y luego usamos esta oración como entrada del modelo para predecir la respuesta de la conversación. Además de la representación vectorial de cada palabra, la entrada de nuestro modelo también incluye la representación vectorial del hablante y la representación vectorial de posición.
| Modelo previamente entrenado | Número de parámetros | Datos utilizados para el entrenamiento previo. | describir |
|---|---|---|---|
| Novela GPT | 95,5 millones | datos de novelas chinas | Modelo GPT chino previamente entrenado creado en base a datos novedosos chinos (los datos novedosos incluyen un total de 1,3 mil millones de palabras) |
| CDial-GPT LCCC-base | 95,5 millones | Base LCCC | Basado en GPT Novel , utilice el modelo GPT chino previamente entrenado por LCCC-base |
| CDial-GPT2 base LCCC | 95,5 millones | Base LCCC | Basado en GPT Novel , utilice el modelo GPT2 chino previamente entrenado con LCCC-base |
| CDial-GPT LCCC-grande | 95,5 millones | LCCC-grande | Basado en GPT Novel , utilice el modelo GPT chino previamente entrenado por LCCC-large |
Instalar directamente desde la fuente:
git clone https://github.com/thu-coai/CDial-GPT.git
cd CDial-GPT
pip install -r requirements.txt
Paso 1: Prepare el conjunto de datos requerido para el modelo de entrenamiento previo y el ajuste fino (como el conjunto de datos STC o los datos de juguete "data/toy_data.json" en el directorio del proyecto. Tenga en cuenta que si los datos contienen inglés, deben separarse por letras, como: hola)
# 下载 STC 数据集 中的训练集和验证集 并将其解压至 "data_path" 目录 (如果微调所使用的数据集为 STC)
git lfs install
git clone https://huggingface.co/thu-coai/CDial-GPT_LCCC-large # 您可自行下载模型或者OpenAIGPTLMHeadModel.from_pretrained("thu-coai/CDial-GPT_LCCC-large")
PD: puede utilizar los siguientes enlaces para descargar el conjunto de capacitación y el conjunto de verificación de STC (Baidu Cloud Disk, Google Drive)
Paso 2: entrenar el modelo
python train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # 使用单个GPU进行训练
o
python -m torch.distributed.launch --nproc_per_node=8 train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # 以分布式的方式在8块GPU上训练
El parámetro train_path también se proporciona en nuestro script de capacitación, que permite a los usuarios leer archivos de texto sin formato en porciones. Si está utilizando un sistema con memoria limitada, considere usar este parámetro para leer los datos de entrenamiento. Si usa train_path debe dejar data_path vacío.
Paso 3: generar texto
# YOUR_MODEL_PATH: 你要使用的模型的路径,每次微调后的模型目录保存在./runs/中
python infer.py --model_checkpoint YOUR_MODEL_PATH --datapath data/STC_test.json --out_path STC_result.txt # 在测试数据上生成回复
python interact.py --model_checkpoint YOUR_MODEL_PATH # 在命令行中与模型进行交互
PD: puede utilizar el siguiente enlace para descargar el conjunto de prueba STC (Baidu Cloud Disk, Google Drive)
Parámetros del script de entrenamiento
| parámetro | tipo | valor predeterminado | describir |
|---|---|---|---|
| modelo_punto de control | cadena | "" | Ruta o URL de los archivos del modelo (directorio del modelo previo al entrenamiento y archivos de configuración/vocab) |
| preentrenado | booleano | FALSO | Si es falso, entrene el modelo desde cero. |
| ruta_datos | cadena | "" | Ruta del conjunto de datos |
| conjunto de datos_cache | cadena | predeterminado="conjunto de datos_cache" | Ruta o URL de la caché del conjunto de datos |
| ruta_del_tren | cadena | "" | Ruta del conjunto de entrenamiento para un conjunto de datos distribuido |
| ruta_válida | cadena | "" | Ruta del conjunto de validación para el conjunto de datos distribuido |
| archivo_registro | cadena | "" | Registros de salida a un archivo en esta ruta |
| numero_trabajadores | entero | 1 | Número de subprocesos para carga de datos. |
| n_épocas | entero | 70 | Número de épocas de entrenamiento |
| tren_lote_tamaño | entero | 8 | Tamaño del lote para entrenamiento |
| tamaño_lote_válido | entero | 8 | Tamaño de lote para validación |
| max_historia | entero | 15 | Número de intercambios anteriores para mantener en la historia |
| planificador | cadena | "noam" | Método de optimizador |
| n_emd | entero | 768 | Número de n_emd en el archivo de configuración (para noam) |
| evaluación_antes_de_inicio | booleano | FALSO | Si es cierto, comience la evaluación antes del entrenamiento. |
| pasos_de_calentamiento | entero | 5000 | Pasos de calentamiento |
| pasos_validos | entero | 0 | Realice la validación cada X pasos, si no es 0 |
| pasos_de_acumulación_gradiente | entero | 64 | Acumular gradientes en varios pasos. |
| norma_max | flotar | 1.0 | Norma de gradiente de recorte |
| dispositivo | cadena | "cuda" si torch.cuda.is_available() si no "cpu" | Dispositivo (cuda o cpu) |
| fp16 | cadena | "" | Establezca en O0, O1, O2 u O3 para el entrenamiento fp16 (consulte la documentación de Apex) |
| rango_local | entero | -1 | Rango local para entrenamiento distribuido (-1: no distribuido) |
Evaluamos el modelo de preentrenamiento de diálogo ajustado utilizando el conjunto de datos STC (conjunto de entrenamiento/conjunto de validación (Baidu Netdisk, Google Drive), conjunto de prueba (Baidu Netdisk, Google Drive)). Todas las respuestas se muestrearon utilizando Nucleus Sampling (p=0,9, temperatura=0,7).
| Modelo | Tamaño del modelo | PPL | AZUL-2 | AZUL-4 | Dist-1 | Dist-2 | Coincidencia codiciosa | Promedio de incrustación |
|---|---|---|---|---|---|---|---|---|
| A la atención de-Seq2seq | 73M | 34.20 | 3.93 | 0,90 | 8.5 | 11.91 | 65,84 | 83,38 |
| Transformador | 113M | 22.10 | 6.72 | 3.14 | 8.8 | 13,97 | 66.06 | 83,55 |
| Charla GPT2 | 88M | - | 2.28 | 0,54 | 10.3 | 16.25 | 61,54 | 78,94 |
| Novela GPT | 95,5 millones | 21.27 | 5.96 | 2.71 | 8.0 | 11.72 | 66.12 | 83,34 |
| Base GPT LCCC | 95,5 millones | 18.38 | 6.48 | 3.08 | 8.3 | 12,68 | 66.21 | 83,54 |
| Base GPT2 LCCC | 95,5 millones | 22,76 | 5.69 | 2.50 | 7.7 | 10.87 | 66,24 | 83,46 |
| GPT LCCC-grande | 95,5 millones | 18.23 | 6.63 | 3.20 | 8.3 | 12.71 | 66,25 | 83,63 |
Tomamos una muestra de 200 respuestas para cada modelo e invitamos a 3 anotadores en la plataforma de subcontratación para evaluar manualmente estas respuestas. Las dimensiones de evaluación fueron fluidez conversacional, relevancia contextual y diversidad de respuestas. El rango de puntuación para cada dimensión es 2/1/0. Consulte nuestro documento para obtener más detalles.
| Modelo | +2 | +1 | +0 | Kappa |
|---|---|---|---|---|
| Atención-Seq2Seq | 27,1% | 21,4% | 51,4% | 0.4544 |
| Transformador | 42,4% | 23,6% | 34,0% | 0.4429 |
| Charla GPT2 | 24,3% | 19,1% | 56,6% | 0.3941 |
| Base GPT LCCC | 46,7% | 21,8% | 31,5% | 0.3954 |
| GPT LCCC-grande | 48,6% | 24,5% | 27,0% | 0.4203 |
Tomamos una muestra aleatoria de 1000 respuestas de conversaciones y contamos las malas respuestas entre estas respuestas:
| Contiene declaraciones repetidas | Contiene malas palabras | Otras malas respuestas |
|---|---|---|
| veintitrés | 9 | 2 |
Ajustamos los parámetros del modelo GPT LCCC-large en el conjunto de datos STC y utilizamos este modelo ajustado para generar el siguiente ejemplo de conversación:
| Correo | Respuesta |
|---|---|
| En realidad, esto es Beijing, no Harbin. | El clima en Harbin parece ser mejor que en Beijing. Aquí llueve ligeramente y hay fuertes vientos durante el día. |
| ¡El concurso de publicidad del campus del operador fue muy divertido! Jajaja. | Pensé que era el anuncio de Jack Ma. |
| Vestido de novia Delsa S posa candy color series, rosa, azul, rojo y morado, juguetón y fresco, ¿te gusta? | ¡El último es tan hermoso, tan hermoso! |
También utilizamos el modelo ajustado anterior para obtener los siguientes resultados de interacción:
| rol | Respuesta |
|---|---|
| Usuario | No me ames en vano |
| Bot | El amor infructuoso es tan doloroso. |
| Usuario | Pero está bien si te ha encantado |
| Bot | A veces el amor es un juego. |
| Usuario | siempre pierdo |
| Bot | Te amo tanto como te amo. |
| Usuario | ¿Puedes tirarlo? |
| Bot | Puedes tirarlo. |
| Usuario | no me imites |
| Bot | Lo que digo es que no puedes hacerlo. |
| Usuario | Me obligas a hacerlo, ¿verdad? |
| Bot | No, te estoy obligando a hablar, ¿verdad? |
Yida Wang, Pei Ke, Yinhe Zheng, Kaili Huang, Yong Jiang, Xiaoyan Zhu, Minlie Huang
Zuoxian Ye, Yao Wang, Yifan Pan
El conjunto de datos LCCC y el modelo de diálogo previamente entrenado proporcionado por este proyecto son solo para fines de investigación científica. Las conversaciones en el conjunto de datos de LCCC se recopilan de diferentes fuentes. Aunque hemos diseñado un proceso estricto de limpieza de datos, no garantizamos que se haya filtrado todo el contenido inapropiado. Todo el contenido y las opiniones contenidas en estos datos son independientes de los autores de este proyecto. El modelo y el código proporcionados en este proyecto son solo un componente del sistema de diálogo completo. Los guiones de decodificación que proporcionamos son solo para fines de investigación científica. Todo el contenido de diálogo generado utilizando los modelos y guiones de este proyecto no tiene nada que ver con el autor. este proyecto.
Si encuentra útil nuestro proyecto, cite nuestro artículo:
@inproceedings{wang2020chinese,
title={A Large-Scale Chinese Short-Text Conversation Dataset},
author={Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle={NLPCC},
year={2020},
url={https://arxiv.org/abs/2008.03946}
}
Este proyecto proporciona un conjunto de datos de conversación en chino limpio a gran escala y un modelo GPT chino previamente entrenado en este conjunto de datos. Consulte nuestro documento para obtener más detalles.
Nuestro código utilizado para el entrenamiento previo está adaptado del modelo TransferTransfo basado en la biblioteca Transformers. Los códigos utilizados tanto para el entrenamiento previo como para el ajuste se proporcionan en este repositorio.
Presentamos un corpus de conversación en chino limpio (LCCC) a gran escala que contiene: LCCC-base (Baidu Netdisk, Google Drive) y LCCC-large (Baidu Netdisk, Google Drive). Se ha diseñado un riguroso proceso de limpieza de datos para garantizar la calidad de la conversación. corpus. Este canal incluye un conjunto de reglas y varios filtros basados en clasificadores. Se incluyen ruidos como palabras ofensivas o sensibles, símbolos especiales, emojis, oraciones gramaticalmente incorrectas y conversaciones incoherentes. filtrado.
Las estadísticas de nuestro corpus se presentan a continuación. Los diálogos con solo dos expresiones se consideran "de un solo turno" y los diálogos con más de tres expresiones se consideran "de múltiples expresiones". Jieba se utiliza para convertir cada expresión en palabras.
| Base LCCC (Baidu Netdisk, Google Drive) | Una sola vuelta | multivuelta |
|---|---|---|
| Sesiones | 3.354.382 | 3.466.607 |
| Declaraciones | 6.708.554 | 13.365.268 |
| Personajes | 68.559.727 | 163.690.614 |
| Vocabulario | 372.063 | 666.931 |
| Promedio de palabras por enunciado | 6,79 | 8.32 |
| Promedio de declaraciones por sesión | 2 | 3.86 |
Tenga en cuenta que LCCC-base se limpia utilizando reglas más estrictas en comparación con LCCC-large.
| LCCC-grande (Baidu Netdisk, Google Drive) | Una sola vuelta | multivuelta |
|---|---|---|
| Sesiones | 7.273.804 | 4.733.955 |
| Declaraciones | 14.547.608 | 18.341.167 |
| Personajes | 162.301.556 | 217.776.649 |
| Vocabulario | 662,514 | 690.027 |
| Promedio de palabras por enunciado | 7.45 | 8.14 |
| Promedio de declaraciones por sesión | 2 | 3.87 |
Los diálogos sin procesar para LCCC-base se originan a partir de un Weibo Corpus que rastreamos desde Weibo, y los diálogos sin procesar para LCCC-large se crean combinando varios conjuntos de datos de conversación además del Weibo Corpus:
| Conjunto de datos | Sesiones | Muestra |
|---|---|---|
| Corpus de Weibo | 79M | P: Comí estofado siete u ocho veces en Chengdu, Chongqing. R: ¡Jajajaja! ¡Entonces mi boca podría pudrirse! |
| Corpus de chismes de PTT | 0,4 millones | P: ¿Por qué los aldeanos siempre intimidan a los estudiantes de secundaria? P: Si crees que si eliges una buena materia te convertirás en Bill Gates, entonces también podrías abandonar la escuela. |
| Corpus de subtítulos | 2,74 millones | Pregunta: La gente en la ópera de Beijing no es libre. R: Ponen a la gente en jaulas. |
| Corpus Xiaohuangji | 0,45 millones | P: ¿Alguna vez has estado enamorado? A: ¿Alguna vez has estado enamorado? Oh, no lo menciones, estoy triste... |
| Corpus Tieba | 2,32 millones | P: En primera fila, todos los fanáticos de Lu se están levantando, ¿verdad? R: El título dice asistencias, pero después de ver esa pelota, es realmente una ironía viviente. |
| Corpus Qingyun | 0,1 millones | P: Parece que amas mucho el dinero. R: Oh, ¿en serio? Entonces ya casi has llegado |
| Corpus de conversación de Douban | 0,5 millones | P: Aprende inglés puro viendo películas originales en inglés R: Me encanta Friends y lo he visto muchas veces P: Estoy casi agotado de ver el mismo CD R: Entonces tu inglés debería ser bastante bueno ahora |
| Corpus de conversación comercial electrónica | 0,5 millones | P: ¿Será una buena oferta? R: Todavía no. P: ¿Estará disponible en el futuro? R: No estoy seguro. |
| Corpus de chat chino | 0,5 millones | P: Mis piernas están inútiles hoy. Ustedes están celebrando la festividad, así que moveré ladrillos. R: Es un trabajo duro, incluso fui a ganar mucho dinero en Navidad. Soy una persona sin novio. Es lo mismo para cualquier día festivo. |
También presentamos una serie de modelos GPT chinos que primero se entrenan previamente en un conjunto de datos novedoso chino y luego se entrenan posteriormente en nuestro conjunto de datos LCCC.
De manera similar a TransferTransfo, concatenamos todos los historiales de diálogo en una oración de contexto y usamos esta oración para predecir la respuesta. La entrada de nuestro modelo consiste en la incrustación de palabras, la incrustación del hablante y la incrustación posicional de cada palabra.
| Modelos | Tamaño del parámetro | Conjunto de datos previo al entrenamiento | Descripción |
|---|---|---|---|
| Novela GPT | 95,5 millones | novela china | Un modelo GPT previamente entrenado en un conjunto de datos de novela china (1.300 millones de palabras, tenga en cuenta que no proporcionamos detalles de este modelo) |
| CDial-GPT base LCCC | 95,5 millones | Base LCCC | Un modelo GPT entrenado posteriormente en un conjunto de datos basado en LCCC de GPT Novel |
| CDial-GPT2 base LCCC | 95,5 millones | Base LCCC | Un modelo GPT2 post-entrenado en un conjunto de datos basado en LCCC de GPT Novel |
| CDial-GPT LCCC-grande | 95,5 millones | LCCC-grande | Un modelo GPT entrenado posteriormente en un gran conjunto de datos LCCC de GPT Novel |
Instalar desde los códigos fuente:
git clone https://github.com/thu-coai/CDial-GPT.git
cd CDial-GPT
pip install -r requirements.txt
Paso 1: Prepare los datos para el ajuste fino (p. ej., conjunto de datos STC o "data/toy_data.json" en nuestro repositorio) y el modelo probado previamente:
# Download the STC dataset and unzip into "data_path" dir (fine-tuning on STC)
git lfs install
git clone https://huggingface.co/thu-coai/CDial-GPT_LCCC-large # or OpenAIGPTLMHeadModel.from_pretrained("thu-coai/CDial-GPT_LCCC-large")
PD: Puede descargar el tren y la división válida de STC desde los siguientes enlaces: (Baidu Netdisk, Google Drive)
Paso 2: entrenar el modelo
python train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # Single GPU training
o
python -m torch.distributed.launch --nproc_per_node=8 train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # Training on 8 GPUs
Nota: También proporcionamos el argumento train_path en el script de entrenamiento para leer el conjunto de datos en texto sin formato, que se dividirá y manejará de forma distributiva. Puede considerar utilizar este argumento si el conjunto de datos es demasiado grande para la memoria de su sistema (además, recuerde dejar el argumento data_path vacío si está utilizando train_path ).
Paso 3: modo de inferencia
# YOUR_MODEL_PATH: the model path used for generation
python infer.py --model_checkpoint YOUR_MODEL_PATH --datapath data/STC_test.json --out_path STC_result.txt # Do Inference on a corpus
python interact.py --model_checkpoint YOUR_MODEL_PATH # Interact on the terminal
PD: Puede descargar la división de prueba de STC desde los siguientes enlaces: (Baidu Netdisk, Google Drive)
Argumentos de entrenamiento
| Argumentos | Tipo | Valor predeterminado | Descripción |
|---|---|---|---|
| modelo_punto de control | cadena | "" | Ruta o URL de los archivos del modelo (directorio del modelo previo al entrenamiento y archivos de configuración/vocab) |
| preentrenado | booleano | FALSO | Si es falso, entrene el modelo desde cero. |
| ruta_datos | cadena | "" | Ruta del conjunto de datos |
| conjunto de datos_cache | cadena | predeterminado = "conjunto de datos_cache" | Ruta o URL de la caché del conjunto de datos |
| ruta_del_tren | cadena | "" | Ruta del conjunto de entrenamiento para un conjunto de datos distribuido |
| ruta_válida | cadena | "" | Ruta del conjunto de validación para el conjunto de datos distribuido |
| archivo_registro | cadena | "" | Registros de salida a un archivo en esta ruta |
| numero_trabajadores | entero | 1 | Número de subprocesos para carga de datos. |
| n_épocas | entero | 70 | Número de épocas de entrenamiento |
| tren_lote_tamaño | entero | 8 | Tamaño del lote para entrenamiento |
| tamaño_lote_válido | entero | 8 | Tamaño de lote para validación |
| max_historia | entero | 15 | Número de intercambios anteriores para mantener en la historia |
| planificador | cadena | "noam" | Método de optimizador |
| n_emd | entero | 768 | Número de n_emd en el archivo de configuración (para noam) |
| evaluación_antes_de_inicio | booleano | FALSO | Si es cierto, comience la evaluación antes del entrenamiento. |
| pasos_de_calentamiento | entero | 5000 | Pasos de calentamiento |
| pasos_validos | entero | 0 | Realice la validación cada X pasos, si no es 0 |
| pasos_de_acumulación_gradiente | entero | 64 | Acumular gradientes en varios pasos. |
| norma_max | flotar | 1.0 | Norma de gradiente de recorte |
| dispositivo | cadena | "cuda" si torch.cuda.is_available() si no "cpu" | Dispositivo (cuda o cpu) |
| fp16 | cadena | "" | Establezca en O0, O1, O2 u O3 para el entrenamiento fp16 (consulte la documentación de Apex) |
| rango_local | entero | -1 | Rango local para entrenamiento distribuido (-1: no distribuido) |
La evaluación se realiza sobre los resultados generados por modelos ajustados en
Conjunto de datos STC (división de tren/válido (Baidu Netdisk, Google Drive), división de prueba (Baidu Netdisk, Google Drive)). Todas las respuestas se generan utilizando el esquema de muestreo Nucleus con un umbral de 0,9 y una temperatura de 0,7.
| Modelos | Tamaño del modelo | PPL | AZUL-2 | AZUL-4 | Dist-1 | Dist-2 | Coincidencia codiciosa | Promedio de incrustación |
|---|---|---|---|---|---|---|---|---|
| A la atención de-Seq2seq | 73M | 34.20 | 3.93 | 0,90 | 8.5 | 11.91 | 65,84 | 83,38 |
| Transformador | 113M | 22.10 | 6.72 | 3.14 | 8.8 | 13,97 | 66.06 | 83,55 |
| Charla GPT2 | 88M | - | 2.28 | 0,54 | 10.3 | 16.25 | 61,54 | 78,94 |
| Novela GPT | 95,5 millones | 21.27 | 5.96 | 2.71 | 8.0 | 11.72 | 66.12 | 83,34 |
| Base GPT LCCC | 95,5 millones | 18.38 | 6.48 | 3.08 | 8.3 | 12,68 | 66.21 | 83,54 |
| Base GPT2 LCCC | 95,5 millones | 22,76 | 5.69 | 2.50 | 7.7 | 10.87 | 66,24 | 83,46 |
| GPT LCCC-grande | 95,5 millones | 18.23 | 6.63 | 3.20 | 8.3 | 12.71 | 66,25 | 83,63 |
También empleamos 3 anotadores de fuentes colaborativas para evaluar 200 muestras de cada modelo sobre fluidez, relevancia y diversidad según un esquema de puntuación 2/1/0. Consulte nuestro artículo para obtener más detalles.
| Modelos | +2 | +1 | +0 | Kappa |
|---|---|---|---|---|
| Atención-Seq2Seq | 27,1% | 21,4% | 51,4% | 0.4544 |
| Transformador | 42,4% | 23,6% | 34,0% | 0.4429 |
| Charla GPT2 | 24,3% | 19,1% | 56,6% | 0.3941 |
| Base GPT LCCC | 46,7% | 21,8% | 31,5% | 0.3954 |
| GPT LCCC-grande | 48,6% | 24,5% | 27,0% | 0.4203 |
Seleccionamos aleatoriamente 1000 muestras generadas y realizamos una estadística de generación tóxica:
| Repetición | palabra sucia | Otros casos malos |
|---|---|---|
| veintitrés | 9 | 2 |
Ejemplos generados en un solo giro a partir del conjunto de datos STC (ajustados en STC):
| Correo | Respuesta |
|---|---|
| En realidad, esto es Beijing, no Harbin. | El clima en Harbin parece ser mejor que en Beijing. Aquí llueve ligeramente y hay fuertes vientos durante el día. |
| ¡El concurso de publicidad del campus del operador fue muy divertido! Jajaja. | Pensé que era el anuncio de Jack Ma. |
| Vestido de novia Delsa S posa candy color series, rosa, azul, rojo y morado, juguetón y fresco, ¿te gusta? | ¡El último es tan hermoso, tan hermoso! |
Ejemplos generados en varios turnos utilizando el script interactivo:
| rol | Respuesta |
|---|---|
| Usuario | No me ames en vano |
| Bot | El amor infructuoso es tan doloroso. |
| Usuario | Pero está bien si te ha encantado |
| Bot | A veces el amor es un juego. |
| Usuario | siempre pierdo |
| Bot | Te amo tanto como te amo. |
| Usuario | ¿Puedes tirarlo? |
| Bot | Puedes tirarlo. |
| Usuario | no me imites |
| Bot | Lo que digo es que no puedes hacerlo. |
| Usuario | Me obligas a hacerlo, ¿verdad? |
| Bot | No, te estoy obligando a hablar, ¿verdad? |
Yida Wang, Pei Ke, Yinhe Zheng, Kaili Huang, Yong Jiang, Xiaoyan Zhu, Minlie Huang
Zuoxian Ye, Yao Wang, Yifan Pan
El conjunto de datos LCCC y los modelos previamente entrenados tienen como objetivo facilitar la investigación para la generación de conversaciones. El conjunto de datos LCCC proporcionado en este repositorio proviene de varias fuentes. Aunque se ha llevado a cabo un proceso de limpieza riguroso, no hay garantía de que se hayan eliminado todos los contenidos inapropiados. Se ha filtrado por completo. Todo el contenido de este conjunto de datos no representa la opinión de los autores. Este repositorio contiene solo una parte de la maquinaria de modelado necesaria para producir realmente un modelo de diálogo. El script de decodificación proporcionado en este repositorio es solo para fines de investigación. No somos responsables de cualquier contenido generado utilizando nuestro modelo.
Por favor cite nuestro artículo si utiliza los conjuntos de datos o modelos en su investigación:
@inproceedings{wang2020chinese,
title={A Large-Scale Chinese Short-Text Conversation Dataset},
author={Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle={NLPCC},
year={2020},
url={https://arxiv.org/abs/2008.03946}
}


