L2MAC
1.0.0
Pionero en el primer marco práctico de computadora automática de programa almacenado de propósito general basado en LLM (arquitectura von Neumann) en un sistema multiagente basado en LLM, para resolver tareas complejas mediante la generación de resultados amplios y consistentes, sin límites por la restricción de ventana de contexto fija de LLM. .
? Puede. 7 - 11 de 2024: Presentaremos L2MAC en la Conferencia Internacional sobre Representaciones del Aprendizaje (ICLR) 2024. ¡Ven a conocernos en ICLR en Viena, Austria! Comuníquese conmigo en sih31 (arroba) cam.ac.uk para que podamos reunirnos. ¡También se aceptan reuniones virtuales!
? Abril. 23 de diciembre de 2024: L2MAC es completamente de código abierto con la versión inicial lanzada.
16 de enero de 2024: ¡Se acepta para su presentación en ICLR 2024 el artículo L2MAC: Computadora automática con modelo de lenguaje grande para generación extensiva de código!
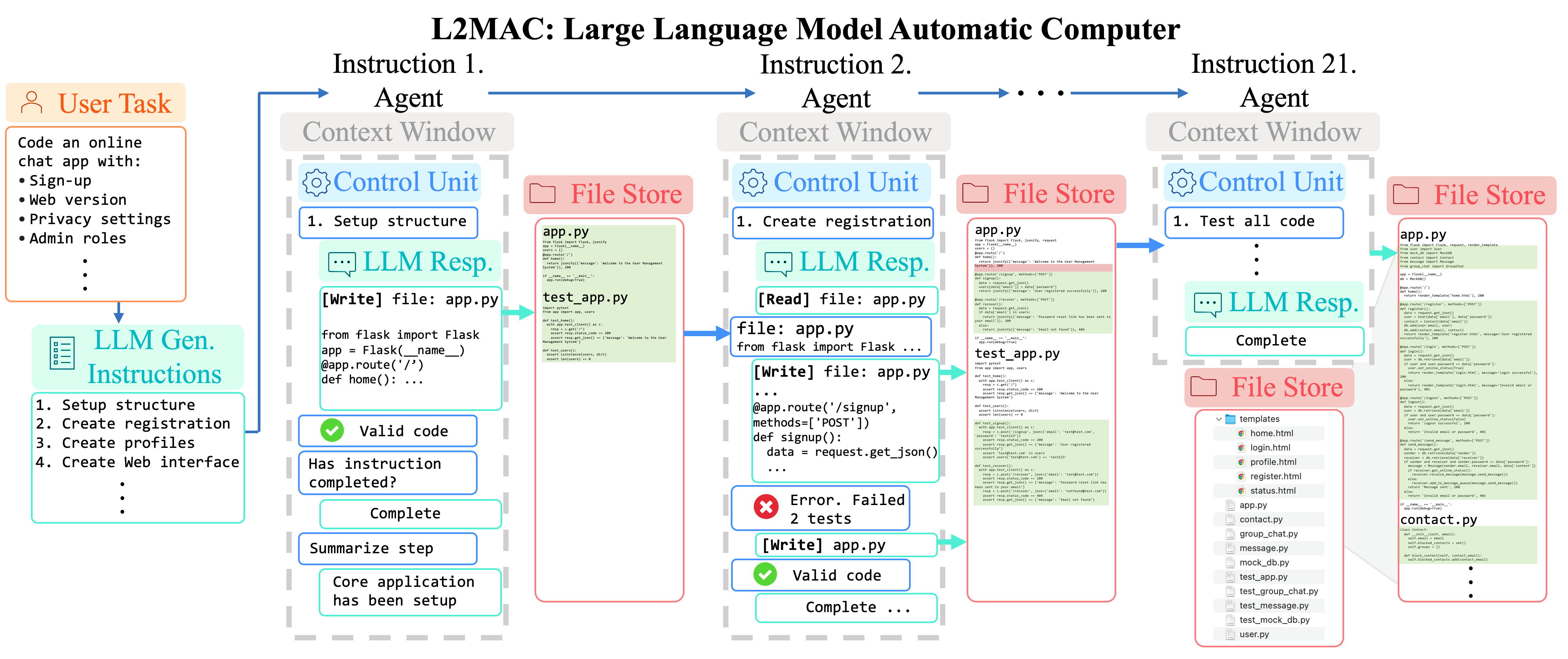
Creación de instancias de LLM-Automatic Computer (L2MAC) para codificar una base de código grande y compleja para una aplicación completa basada en un único mensaje de usuario . Aquí proporcionamos a L2MAC herramientas adicionales para verificar si hay errores de sintaxis dentro del código y ejecutar pruebas unitarias si existen.
Asegúrese de que Python 3.7+ esté instalado en su sistema. Puedes verificar esto usando:
python --version. Puedes usar conda de esta manera:conda create -n l2mac python=3.9 && conda activate l2mac
pip install --upgrade l2mac
# or `pip install --upgrade git+https://github.com/samholt/l2mac`
# or `git clone https://github.com/samholt/l2mac && cd l2mac && pip install --upgrade -e .`Para obtener una guía de instalación detallada, consulte instalación
Puede iniciar la configuración de L2MAC ejecutando el siguiente comando o crear manualmente el archivo ~/.L2MAC/config.yaml :
# Check https://samholt.github.io/L2MAC/guide/get_started/configuration.html for more details
l2mac --init-config # it will create ~/.l2mac/config.yaml, just modify it to your needs Puede configurar ~/.l2mac/config.yaml según el ejemplo y el documento:
llm :
api_type : " openai " # or azure etc. Check ApiType for more options
model : " gpt-4-turbo-preview " # or "gpt-4-turbo"
base_url : " https://api.openai.com/v1 " # or forward url / other llm url
api_key : " YOUR_API_KEY "Después de la instalación, puede utilizar L2MAC CLI
l2mac " Create a beautiful, playable and simple snake game with pygame. Make the snake and food be aligned to the same 10-pixel grid. " # this will create a codebase repo in ./workspaceo usarlo como biblioteca
from l2mac import generate_codebase
codebase : dict = generate_codebase ( "Create a beautiful, playable and simple snake game with pygame. Make the snake and food be aligned to the same 10-pixel grid." )
print ( codebase ) # it will print the codebase (repo) complete with all the files as a dictionary, and produce a local codebase folder in ./workspace? ¡Únete a nuestro canal de Discord! ¡Espero verte allí! ?
Si tiene alguna pregunta o comentario sobre este proyecto, no dude en contactarnos. ¡Apreciamos mucho sus sugerencias!
Responderemos a todas las preguntas dentro de 2-3 días hábiles.
Para mantenerse actualizado con las últimas investigaciones y desarrollos, siga a @samianholt en Twitter.
Para citar L2MAC en publicaciones, utilice la siguiente entrada BibTeX.
@inproceedings {
holt2024lmac,
title = { L2{MAC}: Large Language Model Automatic Computer for Unbounded Code Generation } ,
author = { Samuel Holt and Max Ruiz Luyten and Mihaela van der Schaar } ,
booktitle = { The Twelfth International Conference on Learning Representations } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=EhrzQwsV4K }
}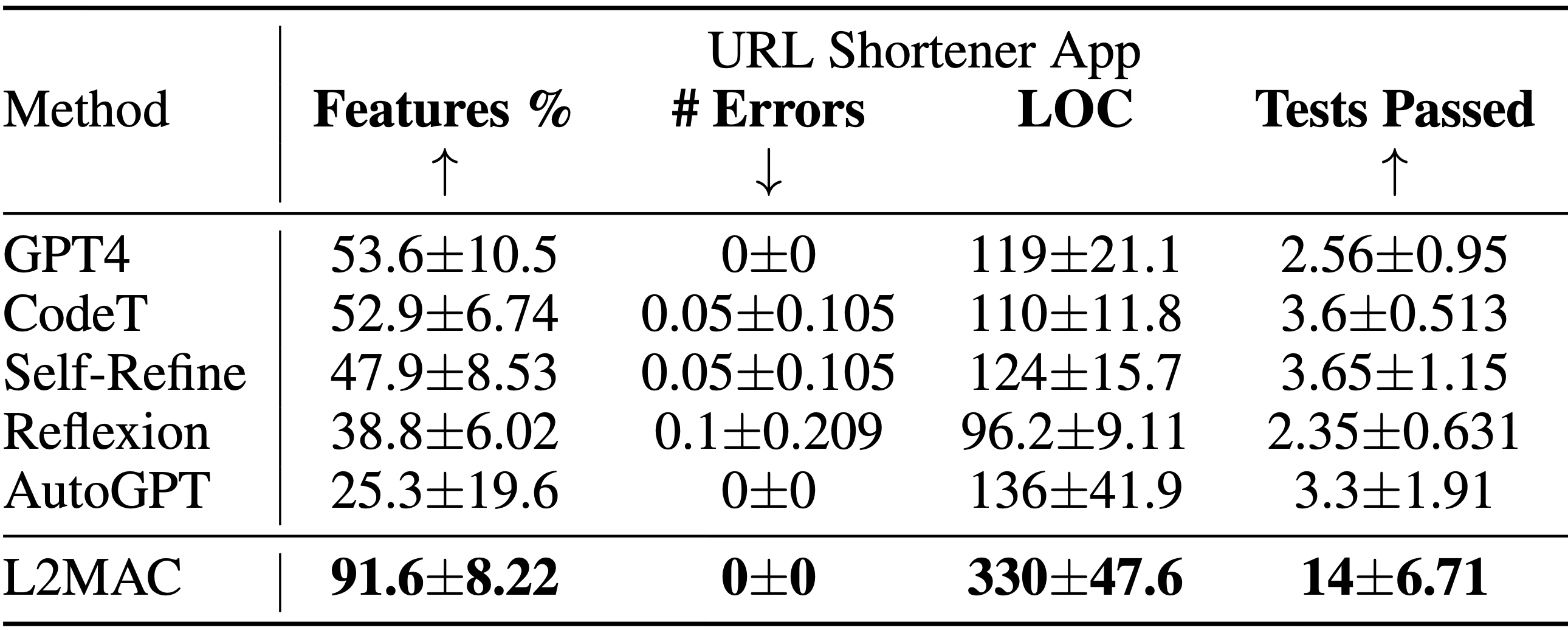
Creación de instancias de LLM-Automatic Computer (L2MAC) para codificar una base de código grande y compleja para una aplicación completa basada en un único mensaje de usuario . Los resultados de la tarea de diseño del sistema de generación de base de código muestran el porcentaje de características funcionales especificadas que están completamente implementadas ( Features % ), la cantidad de errores sintácticos en el código generado ( # Errors ), la cantidad de líneas de código ( LOC ) y la cantidad de pasar pruebas ( Pruebas aprobadas ). L2MAC implementa completamente el porcentaje más alto de requisitos de características de tareas especificadas por el usuario en todas las tareas al generar código completamente funcional que tiene errores sintácticos mínimos y una gran cantidad de pruebas unitarias autogeneradas que pasan, por lo tanto, es lo último en tecnología para el generación de grandes bases de código de salida, y igualmente competitivo para la generación de grandes tareas de salida. Los resultados se promedian sobre 10 semillas aleatorias.
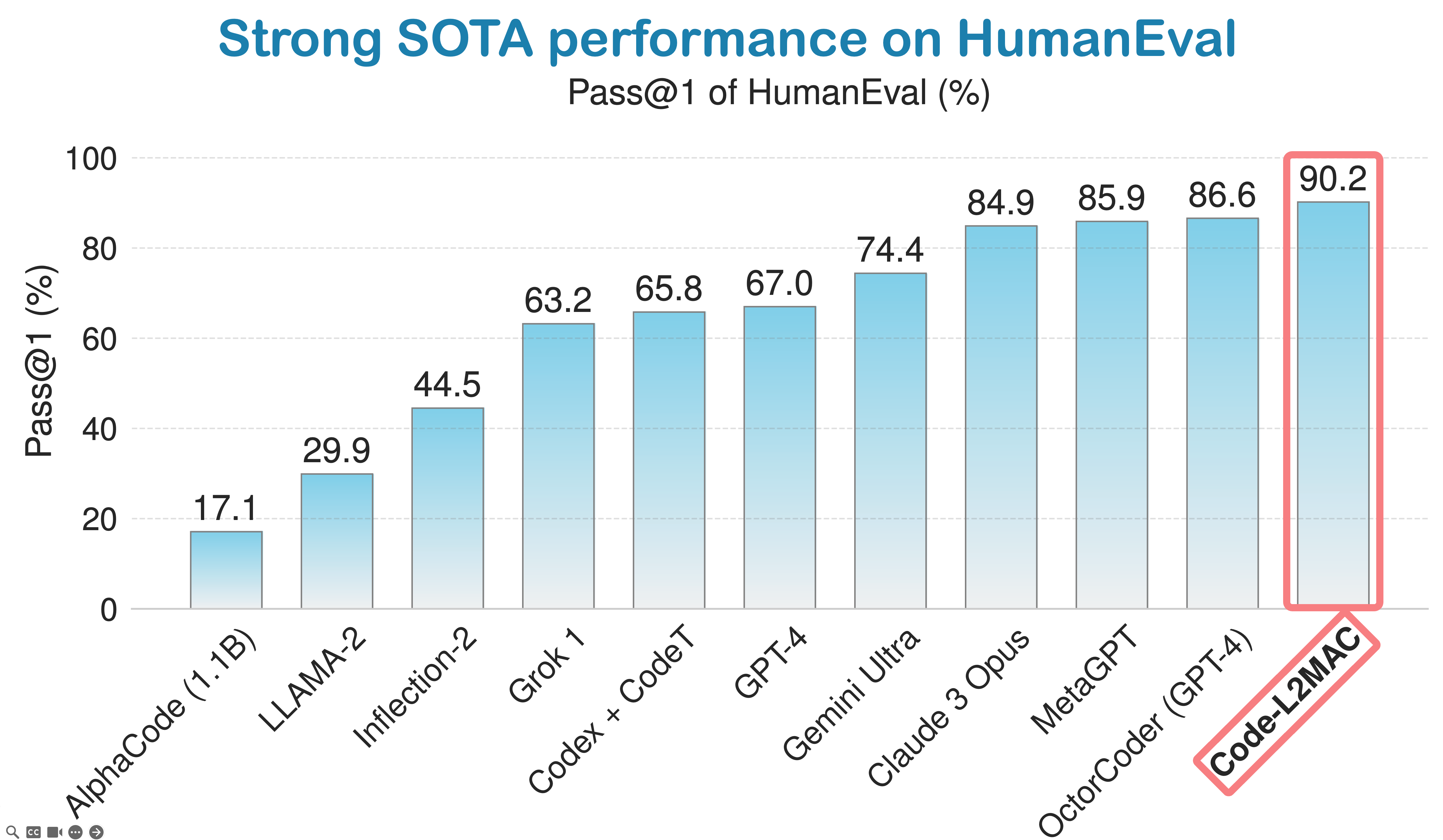
LLM-Automatic Computer (L2MAC) logra un sólido rendimiento en el punto de referencia de codificación HumanEval y actualmente ocupa el tercer lugar como el tercer mejor agente de codificación de IA del mundo en la clasificación global de estándares de la industria de codificación de HumanEval.
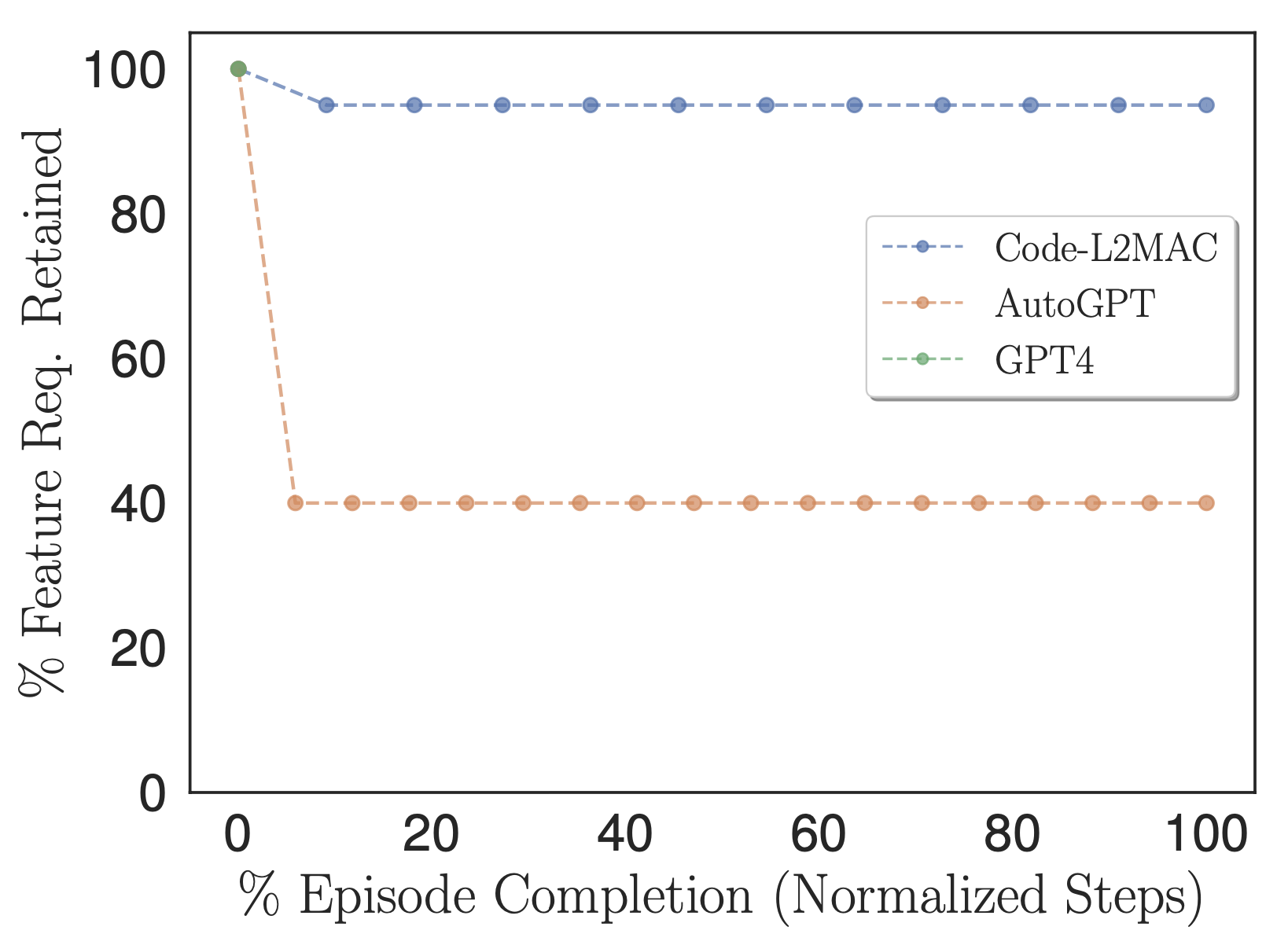
Porcentaje de requisitos de funciones especificados por el usuario que se conservan en las instrucciones de la tarea de métodos y se utilizan en contexto.
Para explorar si los métodos evaluados durante la operación contienen la información dentro de su contexto para completar la tarea directamente, adaptamos nuestra métrica de % de características para contar la cantidad de requisitos de características de la tarea especificados por el usuario que se retienen dentro de las instrucciones de la tarea de los métodos, es decir, aquellos instrucciones que eventualmente se introducen en su ventana contextual durante su operación, como se muestra en la figura anterior. Empíricamente, observamos que L2MAC es capaz de retener una gran cantidad de requisitos de funciones de tareas especificadas por el usuario dentro de su programa rápido y realizar tareas de larga duración orientadas a instrucciones. Observamos que AutoGPT también traduce inicialmente los requisitos de funciones de tareas especificadas por el usuario en instrucciones de tareas; sin embargo, lo hace con una mayor compresión: condensando la información en una simple descripción de seis oraciones. Este proceso da como resultado la pérdida de información de la tarea crucial necesaria para completar correctamente la tarea general, de modo que se alinee con la tarea detallada especificada por el usuario.
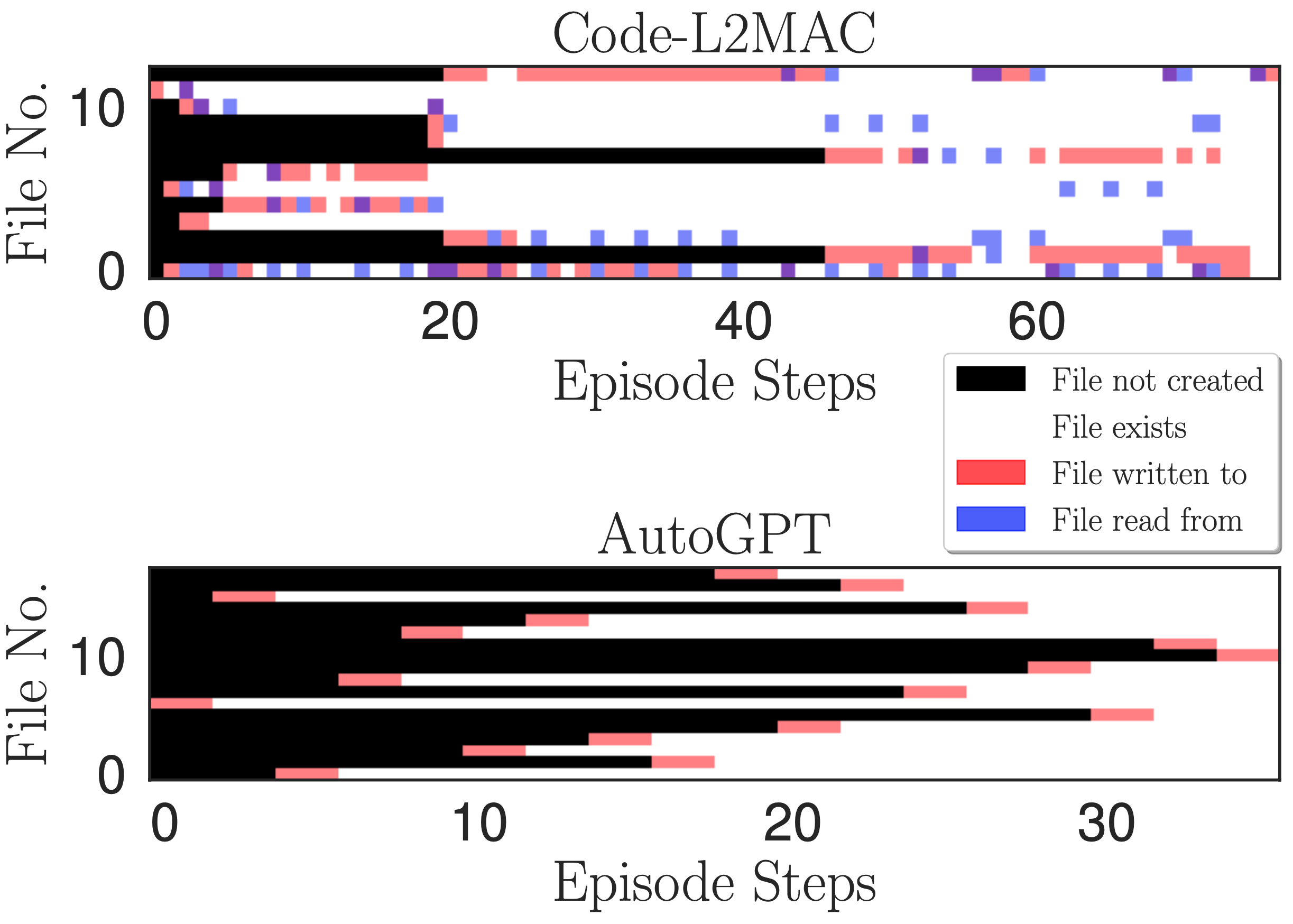
Mapa de calor de acceso a archivos. Indicar lectura, escritura y cuándo se crean archivos en cada paso de la operación de escritura durante un episodio para la tarea de la aplicación de chat en línea.
Deseamos comprender, durante la operación de ejecución de una instrucción de tarea, si L2MAC puede comprender los archivos de código generados existentes dentro del código base, que podrían haberse creado hace muchas instrucciones, y a través de su comprensión, crear nuevos archivos que se interrelacionen con el archivos existentes y, lo más importante, actualizar los archivos de código existentes a medida que se implementan nuevas funciones. Para obtener información, trazamos un mapa de calor de la lectura, la escritura y el momento en que se crean los archivos en cada paso de la operación de escritura durante un episodio en la figura anterior. Observamos que L2MAC comprende el código generado existente que le permite actualizar los archivos de código existentes, incluso aquellos creados originalmente hace muchos pasos de instrucción, y puede ver los archivos cuando no está seguro y actualizarlos escribiendo en los archivos. Por el contrario, AutoGPT a menudo solo escribe en los archivos una vez, cuando los crea inicialmente, y solo puede actualizar los archivos que conoce y que se conservan dentro de su ventana de contexto actual. Aunque también tiene una herramienta de lectura de archivos, a menudo se olvida de los archivos que creó hace muchas iteraciones debido a su enfoque de manejo de ventanas contextuales de resumir los mensajes de diálogo más antiguos en su ventana contextual, es decir, una compresión continua y con pérdida del progreso realizado anteriormente. durante la operación de completar la tarea.
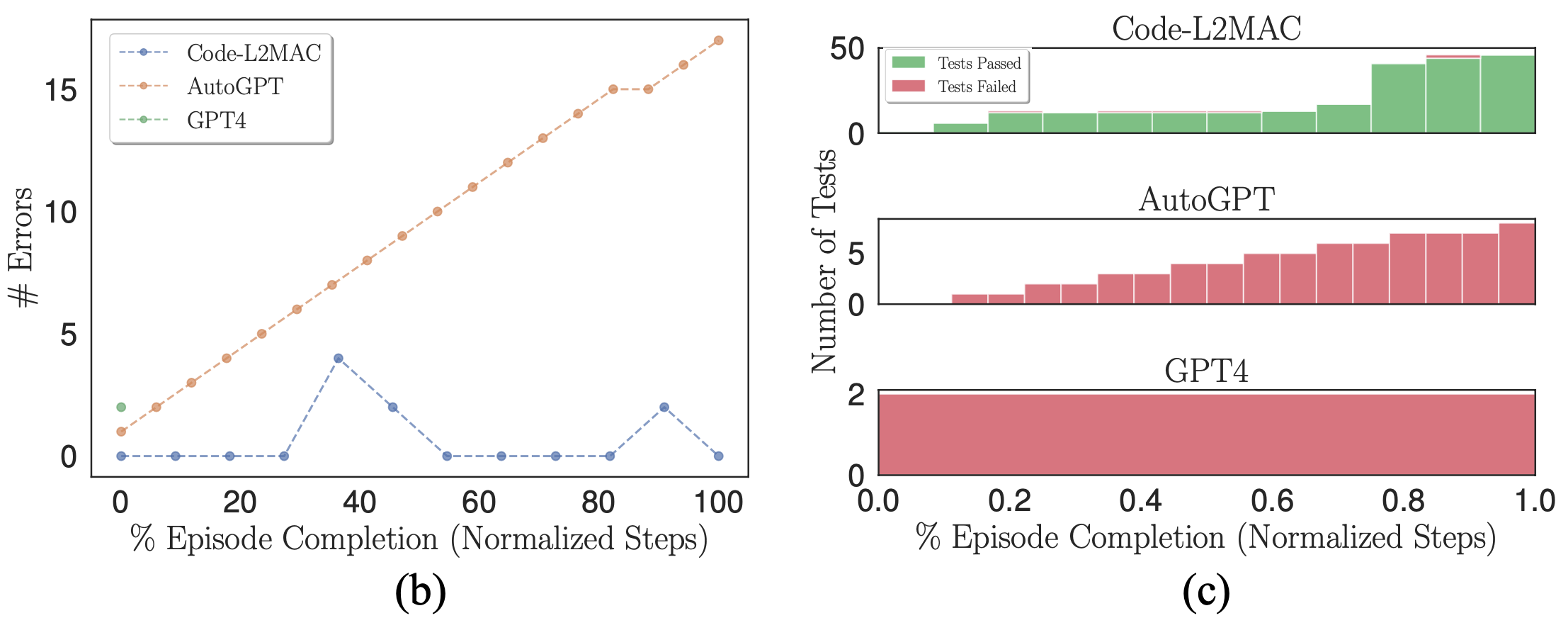
(b) Número de errores sintácticos dentro del código base. (c) Histogramas apilados de pruebas unitarias autogeneradas que aprobaron y reprobaron.
Cuando se utiliza un modelo probabilístico (LLM) como generador para generar código, naturalmente pueden ocurrir errores en sus resultados. Por lo tanto, deseamos verificar si, cuando aparecen errores, los respectivos métodos de referencia pueden corregir errores en el código base. Trazamos el número de errores sintácticos en el código base durante una ejecución donde se cometen errores en la figura (b) anterior. Observamos que L2MAC puede corregir correctamente los errores del código base generado previamente que contiene errores, que podrían surgir de errores sintácticos del último archivo escrito u otros archivos que dependen del archivo escrito más reciente, que ahora contienen errores. Para ello, se le presenta la salida del error cuando surge y modifica el código base para resolver el error mientras se completa la instrucción actual. Por el contrario, AutoGPT no puede detectar cuándo se ha cometido un error en el código base y continúa funcionando, lo que puede agravar la cantidad de errores que se forman dentro del código base.
Además, L2MAC genera pruebas unitarias junto con el código funcional y las utiliza como un verificador de errores para inspeccionar las funcionalidades del código base a medida que se genera y puede usar estos errores para corregir el código base y pasar las pruebas unitarias que ahora fallan después de actualizar parte de un código funcional. archivo. Mostramos esto en la figura anterior (c) y observamos que AutoGPT, aunque se le solicita que también escriba pruebas unitarias para todo el código generado, no puede usar estas pruebas como una verificación de errores de integridad, lo que podría verse agravado por la observación de que AutoGPT olvida qué archivos que ha creado previamente y, por lo tanto, no puede modificar los archivos de código olvidados existentes a medida que se realizan nuevas modificaciones, lo que genera archivos de código incompatibles.
Presentamos L2MAC, el primer marco informático de programa almacenado de propósito general basado en LLM que aumenta de manera efectiva y escalable los LLM con un almacén de memoria para tareas largas de generación de resultados donde esto no se había logrado anteriormente con éxito. Específicamente, L2MAC, cuando se aplica a tareas largas de generación de código, supera las soluciones existentes y es una herramienta inmensamente útil para un desarrollo rápido. Agradecemos las contribuciones y lo alentamos a utilizar y citar el proyecto. Haga clic aquí para comenzar.
Incluimos una galería de aplicaciones de ejemplo producidas íntegramente por LLM Automatic Computer (L2MAC) a partir de un único mensaje de entrada. L2MAC se destaca en la resolución de tareas grandes y complejas, como ser lo último en generación de bases de código grandes, o incluso puede escribir libros completos, todo lo cual evita las restricciones tradicionales de la ventana de contexto fija de LLM.
Simplemente escribe l2mac "Create a beautiful, playable and simple snake game with pygame. Make the snake and food be aligned to the same 10-pixel grid." , obtendrás una base de código completa para un juego totalmente jugable, como se muestra aquí.
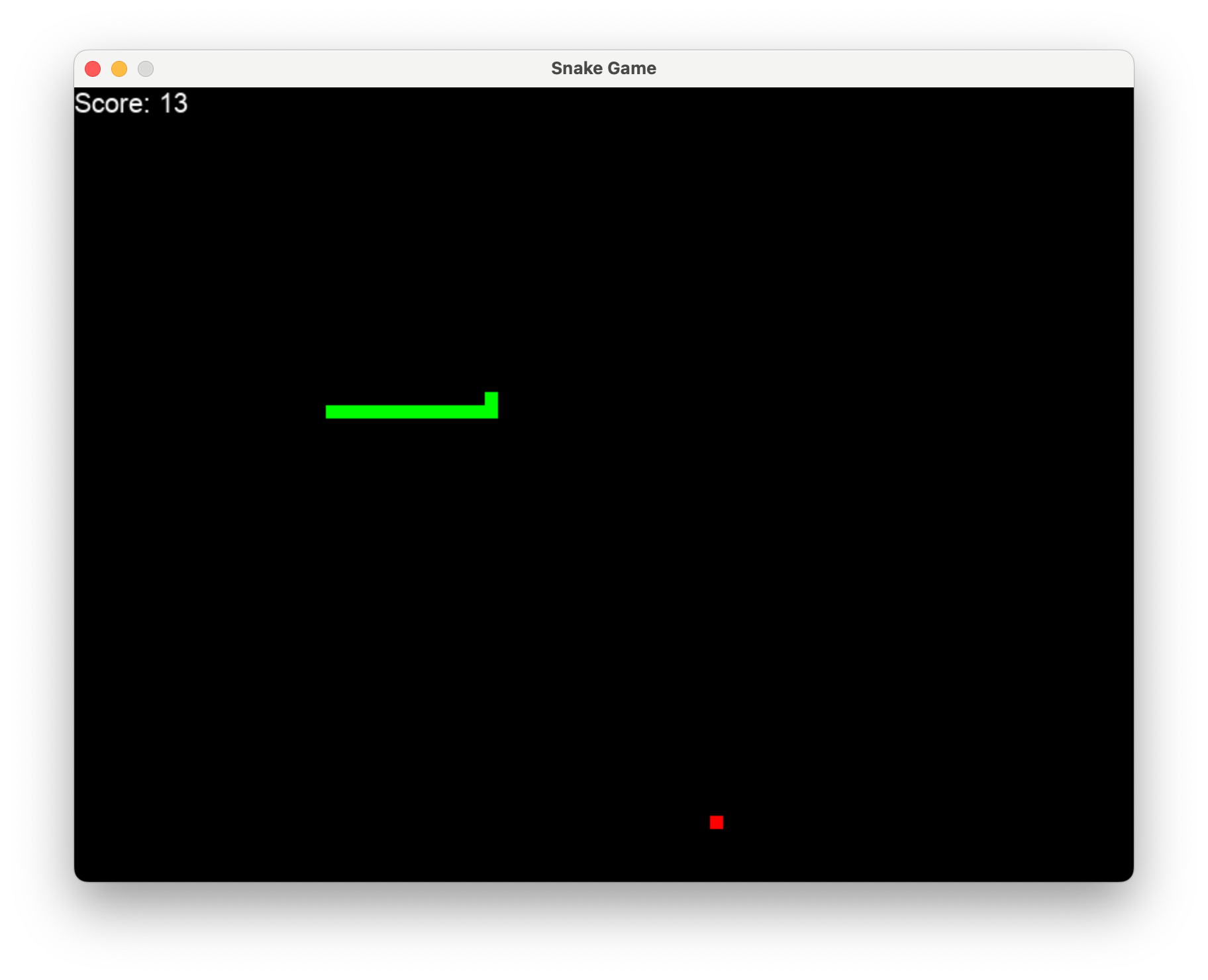
Haga clic aquí para ver los archivos completos en github o descárguelos aquí. El código y el mensaje para generar esto están aquí.
Haga clic aquí para ver los archivos completos en github o descárguelos aquí. El código y el mensaje para generar esto están aquí.
Simplemente dale a L2MAC el mensaje " Write a complete recipe book for the following book title of "Twirls & Tastes: A Journey Through Italian Pasta". Description: "Twirls & Tastes" invites you on a flavorful expedition across Italy, exploring the diverse pasta landscape from the sun-drenched hills of Tuscany to the bustling streets of Naples. Discover regional specialties, learn the stories behind each dish, and master the art of pasta making with easy-to-follow recipes that promise to delight your senses. y puede generar automáticamente un libro completo de 26 páginas.

Haga clic aquí para ver el libro completo; L2MAC produjo todo el texto del libro y todas las imágenes fueron creadas con DALLE.
Los archivos de texto de salida completos están en github; puedes descargarlos aquí. El código y el mensaje para generar esto están aquí.
Haga clic aquí para ver los archivos completos en github o descárguelos aquí. El código y el mensaje para generar esto están aquí.
Estamos buscando activamente que cargue sus propias aplicaciones increíbles aquí enviando un PR con la aplicación que creó, compartiéndolo con un problema de GitHub o compartiéndolo en el canal de Discord.


