Kosmos X
0.0.1

pip3 install --upgrade kosmosx import torch
from kosmosx . model import Kosmos
# Create a sample text token tensor
text_tokens = torch . randint ( 0 , 32002 , ( 1 , 50 ), dtype = torch . long )
# Create a sample image tensor
images = torch . randn ( 1 , 3 , 224 , 224 )
# Instantiate the model
model = Kosmos ()
text_tokens = text_tokens . long ()
# Pass the sample tensors to the model's forward function
output = model . forward (
text_tokens = text_tokens ,
images = images
)
# Print the output from the model
print ( f"Output: { output } " ) Establezca su configuración con: accelerate config luego: accelerate launch train.py
KOSMOS-1 utiliza una arquitectura Transformer solo decodificador basada en Magneto (Foundation Transformers), es decir, una arquitectura que emplea un enfoque llamado sub-LN donde la normalización de capas se agrega antes del módulo de atención (pre-ln) y después (post-LN). ln) combinar las ventajas que tienen ambos enfoques para el modelado del lenguaje y la comprensión de imágenes, respectivamente. El modelo también se inicializa de acuerdo con una métrica específica que también se describe en el artículo, lo que permite una capacitación más estable a tasas de aprendizaje más altas.
Codifican imágenes en características de imagen utilizando un modelo CLIP VIT-L/14 y utilizan un remuestreador de percepción introducido en Flamingo para agrupar las características de la imagen de 256 -> 64 tokens. Las características de la imagen se combinan con las incrustaciones de tokens agregándolas a la secuencia de entrada rodeada de tokens especiales <image> y </image> . Un ejemplo es <s> <image> image_features </image> text </s> . Esto permite que las imágenes se entrelacen con el texto en la misma secuencia.
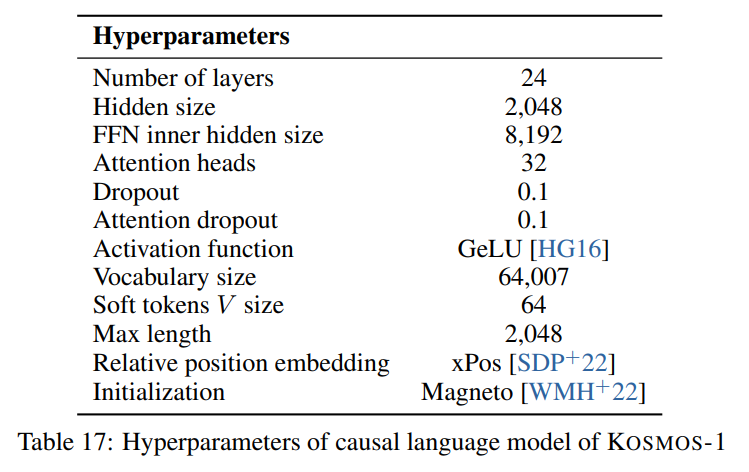
Seguimos los hiperparámetros descritos en el artículo visible en la siguiente imagen:
Usamos la implementación a escala de antorcha de la arquitectura Transformer solo decodificadora de Foundation Transformers:
from torchscale . architecture . config import DecoderConfig
from torchscale . architecture . decoder import Decoder
config = DecoderConfig (
decoder_layers = 24 ,
decoder_embed_dim = 2048 ,
decoder_ffn_embed_dim = 8192 ,
decoder_attention_heads = 32 ,
dropout = 0.1 ,
activation_fn = "gelu" ,
attention_dropout = 0.1 ,
vocab_size = 32002 ,
subln = True , # sub-LN approach
xpos_rel_pos = True , # rotary positional embeddings
max_rel_pos = 2048
)
decoder = Decoder (
config ,
embed_tokens = embed ,
embed_positions = embed_positions ,
output_projection = output_projection
)Para el modelo de imagen (CLIP VIT-L/14) utilizamos un modelo OpenClip previamente entrenado:
from transformers import CLIPModel
clip_model = CLIPModel . from_pretrained ( "laion/CLIP-ViT-L-14-laion2B-s32B-b82K" ). vision_model
# projects image to [batch_size, 256, 1024]
features = clip_model ( pixel_values = images )[ "last_hidden_state" ]Seguimos los hiperparámetros predeterminados para el remuestreador del perceptor ya que no se proporcionan hiperparámetros en el documento:
from flamingo_pytorch import PerceiverResampler
perceiver = PerceiverResampler (
dim = 1024 ,
depth = 2 ,
dim_head = 64 ,
heads = 8 ,
num_latents = 64 ,
num_media_embeds = 256
)
# projects image features to [batch_size, 64, 1024]
self . perceive ( images ). squeeze ( 1 ) Debido a que el modelo espera una dimensión oculta de 2048 , usamos una capa nn.Linear para proyectar las características de la imagen a la dimensión correcta e inicializarla de acuerdo con el esquema de inicialización de Magneto:
image_proj = torch . nn . Linear ( 1024 , 2048 , bias = False )
torch . nn . init . normal_ (
image_proj . weight , mean = 0 , std = 2048 ** - 0.5
)
scaled_image_features = image_proj ( image_features ) El artículo describe un SentencePiece con un vocabulario de 64007 tokens. Para simplificar (ya que no tenemos el corpus de entrenamiento disponible), utilizamos la siguiente mejor alternativa de código abierto, que es el tokenizador grande T5 previamente entrenado de HuggingFace. Este tokenizador tiene un vocabulario de 32002 tokens.
from transformers import T5Tokenizer
tokenizer = T5Tokenizer . from_pretrained (
"t5-large" ,
additional_special_tokens = [ "<image>" , "</image>" ],
extra_ids = 0 ,
model_max_length = 1984 # 2048 - 64 (image features)
) Luego incrustamos los tokens con una capa nn.Embedding . De hecho, usamos bnb.nn.Embedding de bitandbytes que nos permite usar AdamW de 8 bits más adelante.
import bitsandbytes as bnb
embed = bnb . nn . Embedding (
32002 , # Num embeddings
2048 , # Embedding dim
padding_idx
)Para incrustaciones posicionales, utilizamos:
from torchscale . component . embedding import PositionalEmbedding
embed_positions = PositionalEmbedding (
2048 , # Num embeddings
2048 , # Embedding dim
padding_idx
)Además, agregamos una capa de proyección de salida para proyectar la dimensión oculta al tamaño del vocabulario e inicializarla de acuerdo con el esquema de inicialización de Magneto:
output_projection = torch . nn . Linear (
2048 , 32002 , bias = False
)
torch . nn . init . normal_ (
output_projection . weight , mean = 0 , std = 2048 ** - 0.5
) Tuve que hacer algunos pequeños cambios en el decodificador para permitirle aceptar funciones ya integradas en el pase directo. Esto era necesario para permitir la secuencia de entrada más compleja descrita anteriormente. Los cambios son visibles en la siguiente diferencia en la línea 391 de torchscale/architecture/decoder.py :
+ if kwargs.get("passed_x", None) is None:
+ x, _ = self.forward_embedding(
+ prev_output_tokens, token_embeddings, incremental_state
+ )
+ else:
+ x = kwargs["passed_x"]
- x, _ = self.forward_embedding(
- prev_output_tokens, token_embeddings, incremental_state
- )Aquí hay una tabla de rebajas con metadatos para los conjuntos de datos mencionados en el artículo:
| Conjunto de datos | Descripción | Tamaño | Enlace |
|---|---|---|---|
| la pila | Diverso corpus de textos en inglés. | 800GB | abrazando cara |
| rastreo común | Datos de rastreo web | - | rastreo común |
| LAION-400M | Pares de imagen y texto de Common Crawl | 400 millones de pares | abrazando cara |
| LAION-2B | Pares de imagen y texto de Common Crawl | pares 2B | ArXiv |
| COYO | Pares de imagen y texto de Common Crawl | 700 millones de pares | GitHub |
| Leyendas conceptuales | Pares de imagen y texto alternativo | 15 millones de pares | ArXiv |
| Datos CC entrelazados | Texto e imágenes de rastreo común | 71 millones de documentos | Conjunto de datos personalizado |
| HistoriaCloze | Razonamiento de sentido común | 16k ejemplos | Antología ACL |
| HellaSwag | NLI de sentido común | 70k ejemplos | ArXiv |
| Esquema de Winogrado | Ambigüedad de la palabra | 273 ejemplos | PKRR 2012 |
| Winogrande | Ambigüedad de la palabra | 1,7k ejemplos | AAAI 2020 |
| PIQA | Control de calidad físico de sentido común | 16k ejemplos | AAAI 2020 |
| boolq | control de calidad | 15k ejemplos | ACL 2019 |
| CB | Inferencia del lenguaje natural | 250 ejemplos | Sinn und Bedeutung 2019 |
| COPA | razonamiento causal | 1k ejemplos | Simposio de primavera de AAAI 2011 |
| Tamaño relativo | Razonamiento de sentido común | 486 pares | ARXIV 2016 |
| Color de memoria | Razonamiento de sentido común | 720 ejemplos | ARXIV 2021 |
| Términos de color | Razonamiento de sentido común | 320 ejemplos | ACL 2012 |
| Prueba de coeficiente intelectual | razonamiento no verbal | 50 ejemplos | Conjunto de datos personalizado |
| Subtítulos de COCO | Subtítulos de imagen | 413k imágenes | PAMI 2015 |
| Flickr30k | Subtítulos de imagen | 31k imágenes | TACL 2014 |
| VQAv2 | Control de calidad visual | 1 millón de pares de control de calidad | CVPR 2017 |
| VizWiz | Control de calidad visual | 31.000 pares de control de calidad | CVPR 2018 |
| WebSRC | Control de calidad web | 1,4k ejemplos | EMNLP 2021 |
| ImagenNet | Clasificación de imágenes | 1,28 millones de imágenes | CVPR 2009 |
| CACHORRO | Clasificación de imágenes | 200 especies de aves | TOG 2011 |
APACHE


