SimplyRetrieve
Dependencies Update
? Noticias : 21 de agosto de 2023 : los usuarios ahora pueden crear y agregar conocimientos sobre la marcha a través de la Knowledge Tab recién agregada en la GUI. Además, se agregaron barras de progreso en las pestañas Configuración y Conocimiento.
SimplyRetrieve es una herramienta de código abierto con el objetivo de proporcionar una plataforma GUI y API totalmente localizada, liviana y fácil de usar para el enfoque de generación centrada en la recuperación (RCG) para la comunidad de aprendizaje automático.
Crea una herramienta de chat con tus documentos y modelos de lenguaje, altamente personalizable. Las características son:
Un informe técnico sobre esta herramienta está disponible en arXiv.
Un breve vídeo sobre esta herramienta está disponible en YouTube.
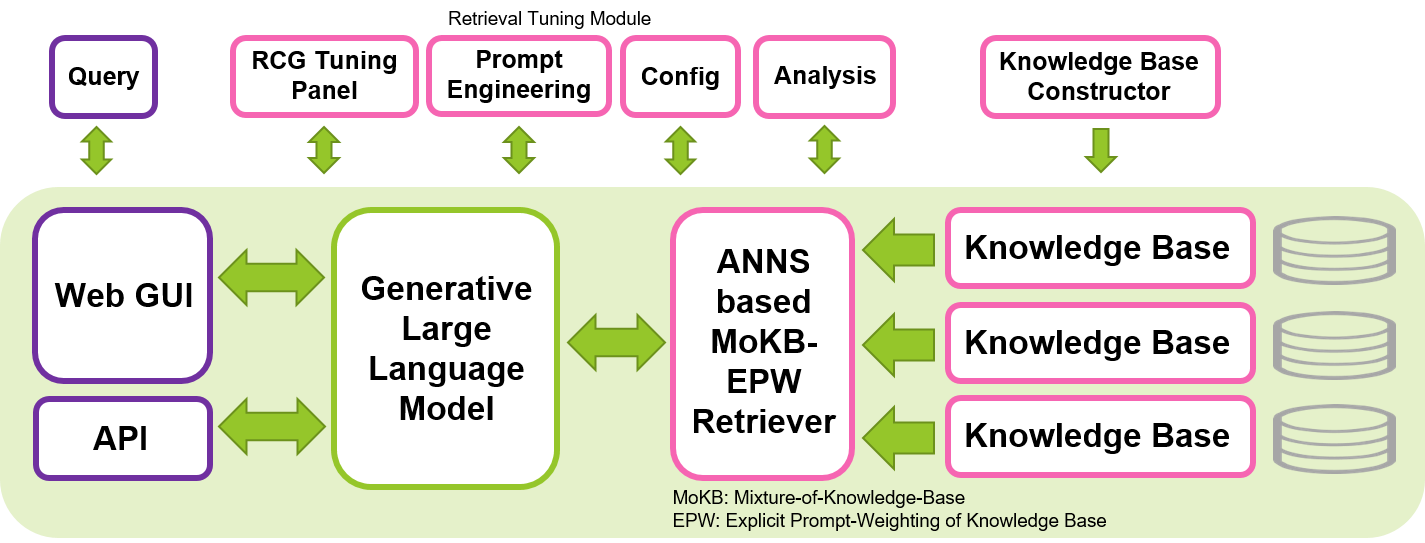
Nuestro objetivo es contribuir al desarrollo de LLM seguros, interpretables y responsables compartiendo nuestra herramienta de código abierto para implementar el enfoque RCG. Esperamos que esta herramienta permita a la comunidad de aprendizaje automático explorar el uso de LLM de una manera más eficiente, manteniendo la privacidad y la implementación local. La generación centrada en la recuperación, que se basa en el concepto de generación aumentada de recuperación (RAG) al enfatizar el papel crucial de los LLM en la interpretación del contexto y confiar la memorización del conocimiento al componente del recuperador, tiene el potencial de producir una generación más eficiente e interpretable, y reducir la escala de LLM necesarios para tareas generativas. Esta herramienta se puede ejecutar en una única GPU Nvidia, como T4, V100 o A100, lo que la hace accesible a una amplia gama de usuarios.
Esta herramienta está construida basándose principalmente en las increíbles y familiares bibliotecas de Hugging Face, Gradio, PyTorch y Faiss. El LLM predeterminado configurado en esta herramienta es el Wizard-Vicuna-13B-Uncensored con instrucciones ajustadas. El modelo de integración predeterminado para Retriever es multilingüe-e5-base. Descubrimos que estos modelos funcionan bien en este sistema, así como en muchos otros tamaños de LLM y recuperadores de código abierto disponibles en Hugging Face. Esta herramienta se puede ejecutar en otros idiomas además del inglés, seleccionando LLM apropiados y personalizando las plantillas de mensajes según el idioma de destino.
pip install -r requirements.txtchat/data/ y ejecute el script de preparación de datos ( cd chat/ luego el siguiente comando) CUDA_VISIBLE_DEVICES=0 python prepare.py --input data/ --output knowledge/ --config configs/default_release.json
pdf, txt, doc, docx, ppt, pptx, html, md, csv y se pueden ampliar fácilmente editando el archivo de configuración. Siga los consejos sobre este problema si se produjo un error relacionado con NLTK.Knowledge Tab de la herramienta GUI. Los usuarios ahora pueden agregar conocimientos sobre la marcha. No es necesario ejecutar el script prepare.py anterior antes de ejecutar la herramienta. Después de configurar los requisitos previos anteriores, establezca la ruta actual al directorio chat ( cd chat/ ), ejecute el siguiente comando. ¡Entonces grab a coffee! ya que sólo tardará unos minutos en cargarse.
CUDA_VISIBLE_DEVICES=0 python chat.py --config configs/default_release.json
Luego, acceda a la GUI basada en web desde su navegador favorito navegando a http://<LOCAL_SERVER_IP>:7860 . Reemplace <LOCAL_SERVER_IP> con la dirección IP de su servidor GPU. Y esto es todo, ¡estás listo para comenzar!
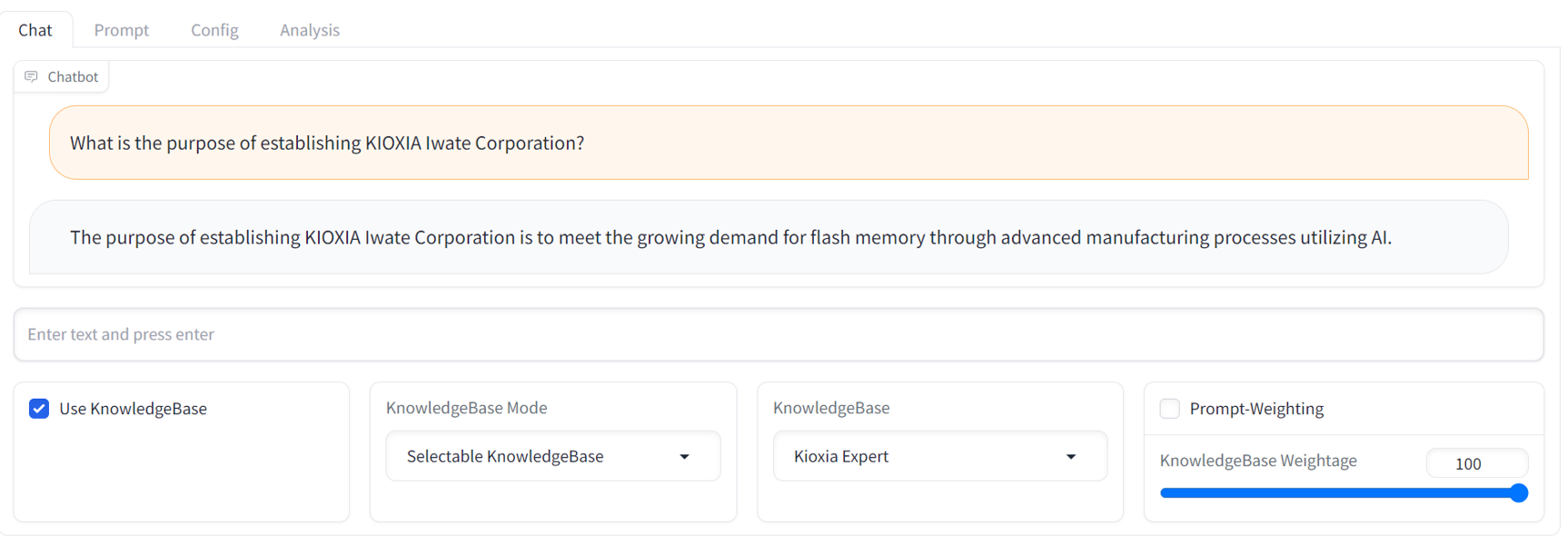
GUI operation manual , consulte el archivo Léame de la GUI ubicado en el directorio docs/ .API access manual , consulte el archivo Léame de la API y los scripts de muestra ubicados en el directorio examples/ .A continuación se muestra una captura de pantalla de chat de muestra de la GUI. Proporciona una interfaz familiar de chatbot de transmisión con un completo panel de ajuste de RCG.
¿No tienes un servidor GPU local para ejecutar esta herramienta en este momento? Ningún problema. Visita este Repositorio. Muestra las instrucciones para probar esta herramienta en la plataforma en la nube AWS EC2.
No dude en enviarnos cualquier opinión y comentario. Agradecemos mucho cualquier discusión y contribución sobre esta herramienta, incluidas nuevas funciones, mejoras y mejor documentación. No dudes en abrir un problema o discusión. Aún no tenemos ningún modelo para problemas o discusiones, por lo que cualquier cosa servirá por ahora.
Desarrollos futuros
Es importante señalar que esta herramienta no proporciona una solución infalible para garantizar una respuesta completamente segura y responsable de los modelos generativos de IA, incluso dentro de un enfoque centrado en la recuperación. El desarrollo de sistemas de IA más seguros, interpretables y responsables sigue siendo un área activa de investigación y esfuerzo continuo.
Los textos generados a partir de esta herramienta pueden presentar variaciones, incluso cuando solo modifican ligeramente las indicaciones o consultas, debido al comportamiento de predicción del próximo token de los LLM de la generación actual. Esto significa que es posible que los usuarios necesiten ajustar cuidadosamente tanto las indicaciones como las consultas para obtener respuestas óptimas.
Si encuentra útil nuestro trabajo, cítenos de la siguiente manera:
@article{ng2023simplyretrieve,
title={SimplyRetrieve: A Private and Lightweight Retrieval-Centric Generative AI Tool},
author={Youyang Ng and Daisuke Miyashita and Yasuto Hoshi and Yasuhiro Morioka and Osamu Torii and Tomoya Kodama and Jun Deguchi},
year={2023},
eprint={2308.03983},
archivePrefix={arXiv},
primaryClass={cs.CL},
journal={arXiv preprint arXiv:2308.03983}
}
?️ Afiliación: Instituto de Investigación y Desarrollo de Tecnología de la Memoria, Kioxia Corporation, Japón


