uniflow llm based pdf extraction text cleaning data clustering
0.0.31
uniflow proporciona una interfaz LLM unificada para extraer y transformar documentos sin procesar.
Uniflow aborda dos desafíos clave en la preparación de datos de capacitación de LLM para científicos de ML:
Por lo tanto, creamos Uniflow, una interfaz LLM unificada para extraer y transformar documentos sin procesar.
Uniflow tiene como objetivo ayudar a cada científico de datos a generar sus propios conjuntos de datos de capacitación listos para usar y preservados de la privacidad para el ajuste de LLM y, por lo tanto, hacer que el ajuste de LLM sea más accesible para todos:cohete:.
Consulte las soluciones prácticas de Uniflow:
La instalación de uniflow tarda entre 5 y 10 minutos si sigue los 3 pasos siguientes:
Cree un entorno conda en su terminal usando:
conda create -n uniflow python=3.10 -y
conda activate uniflow # some OS requires `source activate uniflow`
Instale el pytorch compatible según su sistema operativo.
nvcc -V . pip3 install --pre torch --index-url https://download.pytorch.org/whl/nightly/cu121 # cu121 means cuda 12.1
pip3 install torch
Instalar uniflow :
pip3 install uniflow
(Opcional) Si está ejecutando uno de los siguientes flujos OpenAI , deberá configurar su clave API de OpenAI. Para hacerlo, cree un archivo .env en su carpeta raíz de Uniflow. Luego agregue la siguiente línea al archivo .env :
OPENAI_API_KEY=YOUR_API_KEY
(Opcional) Si está ejecutando HuggingfaceModelFlow , también necesitará instalar las bibliotecas transformers , accelerate , bitsandbytes y scipy :
pip3 install transformers accelerate bitsandbytes scipy
(Opcional) Si está ejecutando LMQGModelFlow , también necesitará instalar las bibliotecas lmqg y spacy :
pip3 install lmqg spacy
¡Felicidades, has terminado la instalación!
Si está interesado en contribuir con nosotros, aquí están las configuraciones de desarrollo preliminares.
conda create -n uniflow python=3.10 -y
conda activate uniflow
cd uniflow
pip3 install poetry
poetry install --no-root
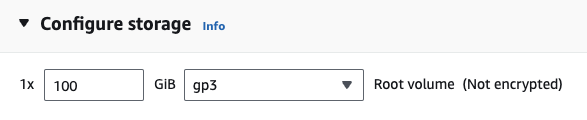
Si está en EC2, puede iniciar una instancia de GPU con la siguiente configuración:
g4dn.xlarge (si desea ejecutar un LLM previamente entrenado con parámetros 7B)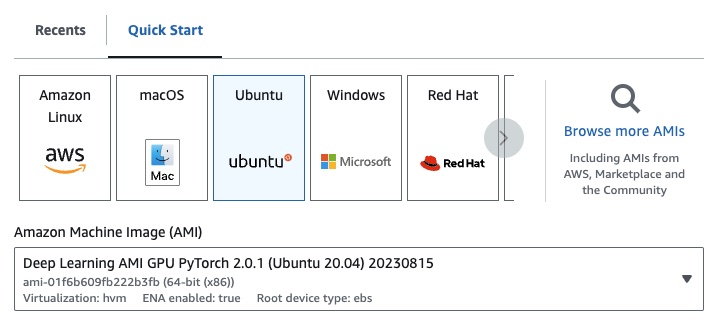
Si está ejecutando uno de los siguientes flujos OpenAI , deberá configurar su clave API de OpenAI.
Para hacerlo, cree un archivo .env en su carpeta raíz de Uniflow. Luego agregue la siguiente línea al archivo .env :
OPENAI_API_KEY=YOUR_API_KEY
Para utilizar uniflow , siga tres pasos principales:
Elija una Config
Esto determina el LLM y los diferentes parámetros configurables.
Construya sus Prompts
Construya el contexto que desea utilizar para impulsar su modelo. Puede configurar instrucciones y ejemplos personalizados utilizando la clase PromptTemplate .
Ejecute su Flow
Ejecute el flujo en sus datos de entrada y genere resultados desde su LLM.
Nota: Actualmente también estamos creando flujos
Preprocessingpara ayudar a procesar datos de diferentes fuentes, comohtml,Markdowny más.
La Config determina qué LLM se utiliza y cómo se serializan y deserializan los datos de entrada. También tiene parámetros que son específicos del LLM.
Aquí hay una tabla de las diferentes configuraciones predefinidas que puede usar y sus LLM correspondientes:
| configuración | LLM |
|---|---|
| configuración | gpt-3.5-turbo-1106 |
| AbrirAIConfig | gpt-3.5-turbo-1106 |
| HuggingfaceConfig | mistralai/Mistral-7B-Instruct-v0.1 |
| Configuración LMQG | lmqg/t5-base-squad-qg-ae |
Puede ejecutar cada configuración con los valores predeterminados o puede pasar parámetros personalizados, como temperature o batch_size a la configuración para su caso de uso. Consulte la sección de configuración personalizada avanzada para obtener más detalles.
De forma predeterminada, uniflow está configurado para generar preguntas y respuestas basadas en el Context que ingresa. Para hacerlo, tiene una instrucción predeterminada y ejemplos breves que utiliza para guiar el LLM.
Aquí está la instrucción predeterminada:
Generate one question and its corresponding answer based on the last context in the last example. Follow the format of the examples below to include context, question, and answer in the response
Estos son los ejemplos predeterminados de algunos disparos:
context="The quick brown fox jumps over the lazy brown dog.",
question="What is the color of the fox?",
answer="brown."
context="The quick brown fox jumps over the lazy black dog.",
question="What is the color of the dog?",
answer="black."
Para ejecutar estas instrucciones y ejemplos predeterminados, todo lo que necesita hacer es pasar una lista de objetos Context al flujo. Luego, uniflow generará un mensaje personalizado con las instrucciones y ejemplos breves para cada objeto Context para enviar al LLM. Consulte la sección Ejecución del flujo para obtener más detalles.
La clase Context se utiliza para pasar el contexto del mensaje LLM. Un Context consta de una propiedad context , que es una cadena de texto.
Para ejecutar uniflow con las instrucciones predeterminadas y ejemplos breves, puede pasar una lista de objetos Context al flujo. Por ejemplo:
from uniflow.op.prompt import Context
data = [
Context(
context="The quick brown fox jumps over the lazy brown dog.",
),
...
]
client.run(data)
Para obtener una descripción general más detallada de la ejecución del flujo, consulte la sección Ejecución del flujo.
Si desea ejecutar con una instrucción de solicitud personalizada o ejemplos breves, puede utilizar el objeto PromptTemplate . Tiene propiedades instruction y example .
| Propiedad | Tipo | Descripción |
|---|---|---|
instruction | cadena | Instrucciones detalladas para el LLM |
examples | Lista[Contexto] | Los ejemplos de pocos disparos. |
Puede sobrescribir cualquiera de los valores predeterminados según sea necesario.
Para ver un ejemplo de cómo usar PromptTemplate para ejecutar uniflow con una instruction personalizada, ejemplos breves y campos Context personalizados para generar un resumen, consulte el cuaderno openai_pdf_source_10k_summary.
Una vez que haya decidido su Config y estrategia de solicitud, puede ejecutar el flujo en los datos de entrada.
Importe los objetos Client , Config y Context uniflow .
from uniflow.flow.client import TransformClient
from uniflow.flow.config import TransformOpenAIConfig, OpenAIModelConfig
from uniflow.op.prompt import Context
Preprocese sus datos en fragmentos para pasarlos al flujo. En el futuro tendremos flujos Preprocessing para ayudar con este paso, pero por ahora puedes usar una biblioteca de tu elección, como pypdf, para fragmentar tus datos.
raw_input_context = ["It was a sunny day and the sky color is blue.", "My name is bobby and I am a talent software engineer working on AI/ML."]
Cree una lista de objetos Context para pasar sus datos al flujo.
data = [
Context(context=c)
for c in raw_input_context
]
[Opcional] Si desea utilizar instrucciones y/o ejemplos personalizados, cree un PromptTemplate .
from uniflow.op.prompt import PromptTemplate
guided_prompt = PromptTemplate(
instruction="Generate a one sentence summary based on the last context below. Follow the format of the examples below to include context and summary in the response",
few_shot_prompt=[
Context(
context="When you're operating on the maker's schedule, meetings are a disaster. A single meeting can blow a whole afternoon, by breaking it into two pieces each too small to do anything hard in. Plus you have to remember to go to the meeting. That's no problem for someone on the manager's schedule. There's always something coming on the next hour; the only question is what. But when someone on the maker's schedule has a meeting, they have to think about it.",
summary="Meetings disrupt the productivity of those following a maker's schedule, dividing their time into impractical segments, while those on a manager's schedule are accustomed to a continuous flow of tasks.",
),
],
)
Cree un objeto Config para pasarlo al objeto Client .
config = TransformOpenAIConfig(
prompt_template=guided_prompt,
model_config=OpenAIModelConfig(
response_format={"type": "json_object"}
),
)
client = TransformClient(config)
Utilice el objeto client para ejecutar el flujo en los datos de entrada.
output = client.run(data)
Procese los datos de salida. De forma predeterminada, la salida de LLM será una lista de dictados de salida, uno para cada Context pasado al flujo. Cada dictado tiene una propiedad response que tiene la respuesta LLM, así como cualquier error. Por ejemplo output[0]['output'][0] se vería así:
{
'response': [{'context': 'It was a sunny day and the sky color is blue.',
'question': 'What was the color of the sky?',
'answer': 'blue.'}],
'error': 'No errors.'
}
Para obtener más ejemplos, consulte la carpeta de ejemplos.
También puede configurar los flujos pasando configuraciones o argumentos personalizados al objeto Config si desea ajustar aún más parámetros específicos como el modelo LLM, la cantidad de subprocesos, la temperatura y más.
Cada configuración tiene los siguientes parámetros:
| Parámetro | Tipo | Descripción |
|---|---|---|
prompt_template | PromptTemplate | La plantilla que se utilizará para la indicación guiada. |
num_threads | entero | El número de subprocesos que se utilizarán para el flujo. |
model_config | ModelConfig | La configuración para pasar al modelo. |
Puede configurar aún más model_config pasando una de las Model Configs con parámetros personalizados.
La configuración del modelo es una configuración que se pasa al objeto Config base y determina qué modelo LLM se utiliza y tiene parámetros que son específicos del modelo LLM.
La configuración base se llama ModelConfig y tiene los siguientes parámetros:
| Parámetro | Tipo | Por defecto | Descripción |
|---|---|---|---|
model_name | cadena | gpt-3.5-turbo-1106 | Sitio abierto AI |
OpenAIModelConfig hereda de ModelConfig y tiene los siguientes parámetros adicionales:
| Parámetro | Tipo | Por defecto | Descripción |
|---|---|---|---|
num_calls | entero | 1 | La cantidad de llamadas a realizar a la API de OpenAI. |
temperature | flotar | 1.5 | La temperatura que se utilizará para la API OpenAI. |
response_format | Dictado[cadena, cadena] | {"tipo": "texto"} | El formato de respuesta que se utilizará para la API de OpenAI. Puede ser "texto" o "json" |
HuggingfaceModelConfig hereda de ModelConfig , pero anula el parámetro model_name para usar el modelo mistralai/Mistral-7B-Instruct-v0.1 de forma predeterminada.
| Parámetro | Tipo | Por defecto | Descripción |
|---|---|---|---|
model_name | cadena | mistralai/Mistral-7B-Instruct-v0.1 | Sitio de cara de abrazo |
batch_size | entero | 1 | El tamaño de lote que se utilizará para la API Hugging Face. |
LMQGModelConfig hereda de ModelConfig , pero anula el parámetro model_name para usar el modelo lmqg/t5-base-squad-qg-ae de forma predeterminada.
| Parámetro | Tipo | Por defecto | Descripción |
|---|---|---|---|
model_name | cadena | lmqg/t5-escuadrón-base-qg-ae | Sitio de cara de abrazo |
batch_size | entero | 1 | El tamaño de lote que se utilizará para la API LMQG. |
A continuación se muestra un ejemplo de cómo pasar una configuración personalizada al objeto Client :
from uniflow.flow.client import TransformClient
from uniflow.flow.config import TransformOpenAIConfig, OpenAIModelConfig
from uniflow.op.prompt import Context
contexts = ["It was a sunny day and the sky color is blue.", "My name is bobby and I am a talent software engineer working on AI/ML."]
data = [
Context(
context=c
)
for c in contexts
]
config = OpenAIConfig(
num_threads=2,
model_config=OpenAIModelConfig(
model_name="gpt-4",
num_calls=2,
temperature=0.5,
),
)
client = TransformClient(config)
output = client.run(data)
Como puede ver, estamos pasando parámetros personalizados a OpenAIModelConfig a las configuraciones OpenAIConfig de acuerdo con nuestras necesidades.


