Descubriendo conexiones ocultas en datos financieros no estructurados utilizando Amazon Bedrock y Amazon Neptune
Este repositorio contiene código para implementar una solución prototipo que demuestra cómo se pueden combinar la IA generativa y el gráfico de conocimiento para crear un sistema escalable, sin servidor y controlado por eventos para procesar datos no estructurados para servicios financieros. Esta solución puede ayudar a los administradores de activos de su organización a descubrir conexiones ocultas en sus carteras de inversión y proporciona una interfaz de usuario de muestra fácil de usar para consumir noticias financieras y comprender sus conexiones con sus carteras de inversión.
Caso de uso empresarial
Los administradores de activos generalmente invierten en una gran cantidad de empresas en sus carteras y necesitan poder realizar un seguimiento de cualquier noticia relacionada con esas empresas porque estas noticias les ayudarían a mantenerse por delante de los movimientos del mercado, identificar oportunidades de inversión y gestionar mejor su inversión. cartera.
Generalmente, el seguimiento de las noticias se puede realizar fácilmente configurando una simple alerta de noticias basada en palabras clave utilizando el nombre de la empresa en la que se invierte, pero esto se vuelve cada vez más difícil cuando el evento noticioso no afecta directamente a la empresa en la que se invierte. Por ejemplo, el impacto podría afectar a un proveedor de una empresa participada, lo que potencialmente alteraría la cadena de suministro de la empresa. O el impacto podría ser para un cliente de un cliente de su empresa participada. Si estas empresas concentran sus ingresos en unos pocos clientes clave, esto podría tener un impacto financiero negativo en su inversión.
Estos impactos de segundo o tercer orden son difíciles de identificar y aún más difíciles de rastrear. Con esta solución automatizada, los administradores de activos pueden crear un gráfico de conocimiento de las relaciones que rodean su cartera de inversiones y luego utilizar este conocimiento para extraer correlaciones y conocimientos de las últimas noticias.
Arquitectura
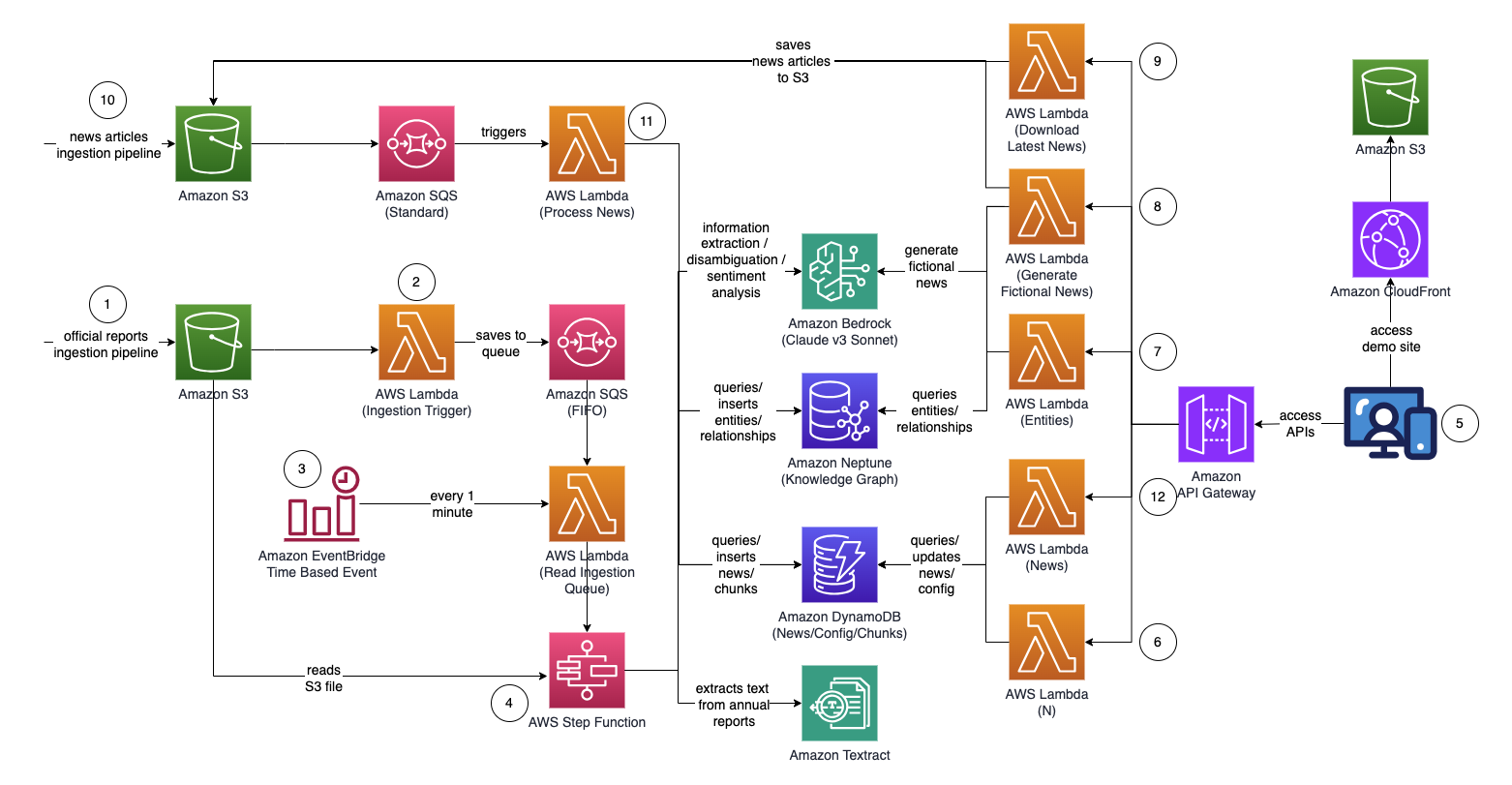
Gráfico de función de paso (desde el punto 4)
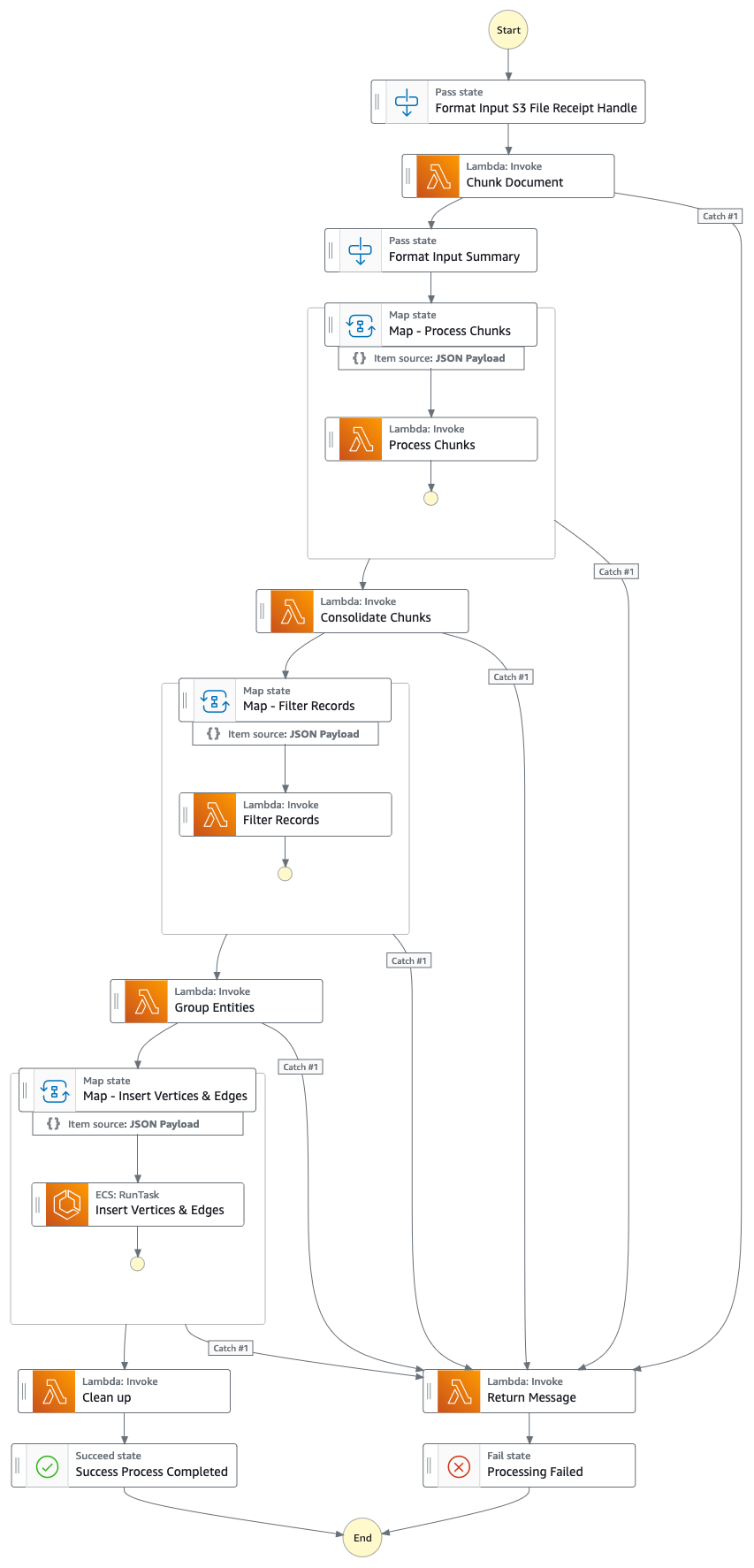
Flujo de solución (paso a paso)
- Cargue informes proxy/anuales/10k oficiales (.PDF) al depósito de Amazon S3.
- El nombre del depósito de S3 al que se va a cargar se puede recuperar desde la consola de CloudFormation - salida de la pila principal - "IngestionBucket"
- Tenga en cuenta que los informes utilizados deben ser informes publicados oficialmente para minimizar la inclusión de datos inexactos en su gráfico de conocimiento (a diferencia de noticias/tabloides).
- La notificación de eventos de S3 activa una función de AWS Lambda que envía el nombre del archivo o depósito de S3 a una cola de servicio de cola simple (FIFO) de Amazon.
- El uso de la cola FIFO es para garantizar que el proceso de ingesta de informes se realice de forma secuencial para reducir la probabilidad de introducir datos duplicados en su gráfico de conocimiento.
- Un evento basado en tiempo de Amazon EventBridge se ejecuta cada minuto para invocar una función de AWS Lambda. La función recuperará el siguiente mensaje de cola disponible de SQS e iniciará la ejecución de una función de paso de AWS de forma asincrónica.
- Una máquina de estado de función de pasos ejecuta una serie de tareas para procesar el documento cargado extrayendo información clave e insertándola en su gráfico de conocimiento.
- Tareas
- Con Amazon Textract, extraiga el contenido de texto del archivo de informe proxy/anual/10k (PDF) en Amazon S3 y divídalo en varios fragmentos de texto más pequeños para su procesamiento. Almacene los fragmentos de texto en Amazon DynamoDB.
- Utilizando Claude v3 Sonnet de Anthropic en Amazon Bedrock, procese los primeros fragmentos de texto para determinar la entidad principal a la que se refiere el informe, junto con los atributos relevantes (por ejemplo, industria).
- Recupera los fragmentos de texto de DynamoDB y, para cada fragmento de texto, invoca una función lambda para extraer entidades (empresa/persona) y su relación (cliente/proveedor/socio/competidor/director) con la entidad principal mediante Amazon Bedrock.
- Consolidar toda la información extraída
- Filtra ruido/entidades irrelevantes (es decir, términos genéricos como "consumidores") utilizando Amazon Bedrock.
- Utilice Amazon Bedrock para realizar la desambiguación razonando utilizando la información extraída en comparación con la lista de entidades similares del gráfico de conocimiento. Si la entidad no existe, insértela. De lo contrario, utilice la entidad que ya existe en el gráfico de conocimiento. Inserta todas las relaciones extraídas.
- Realice la limpieza eliminando el mensaje de la cola SQS y el archivo S3.
- Una vez que se completa este paso, su gráfico de conocimiento estará actualizado y listo para usar.
- Un usuario accede a una aplicación web basada en React para ver los artículos de noticias que están enriquecidos con información de entidad/sentimiento/ruta de conexión.
- La URL de la aplicación web se puede copiar desde la consola de CloudFormation - salida de la pila de la aplicación web - "WebApplicationURL"
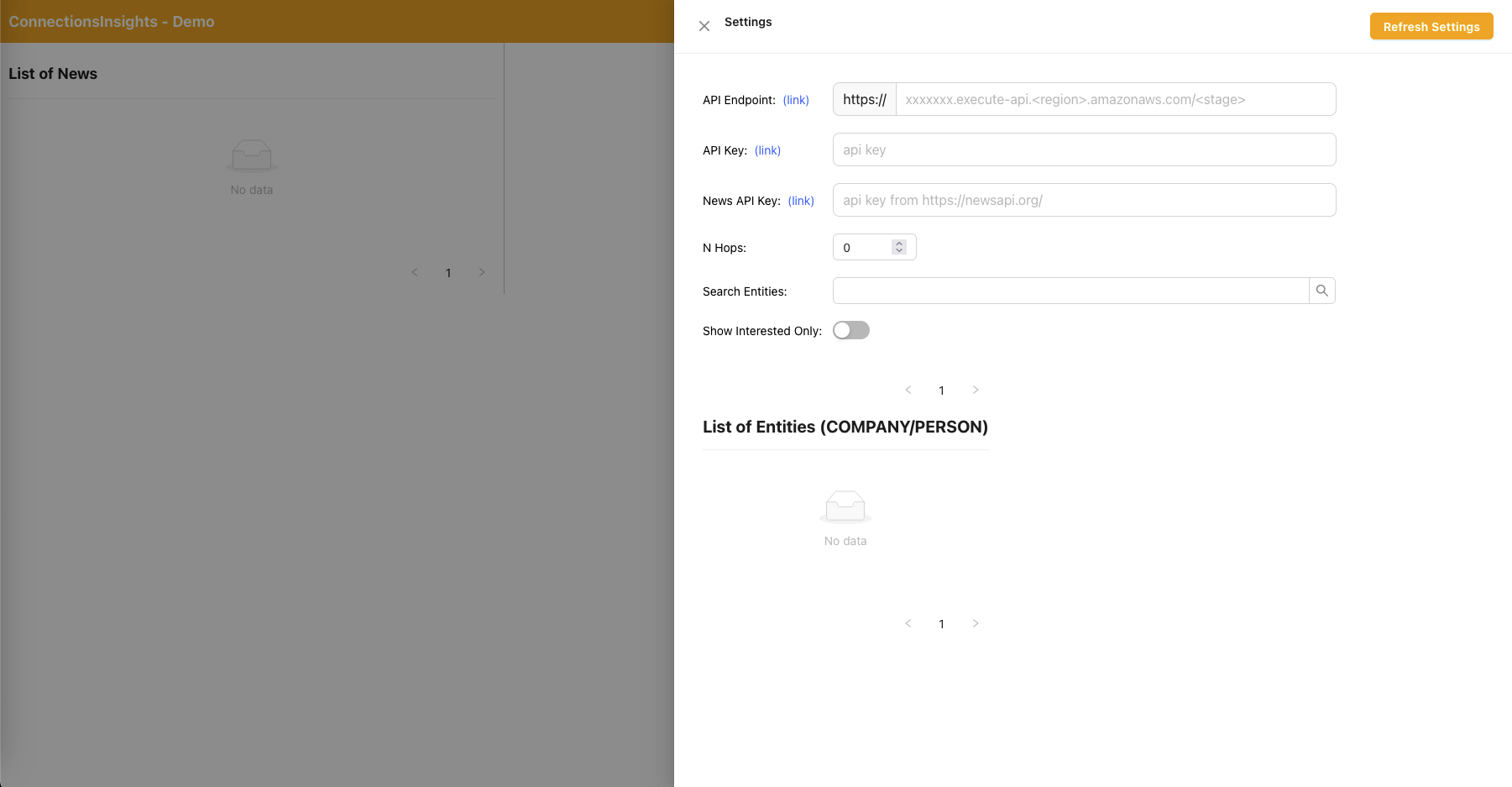
- Como se trata de una solución de muestra para fines de demostración, el usuario especifica el punto final de API, la clave de API y la clave de API de noticias en la aplicación web haciendo clic en el ícono de ajustes en la esquina superior derecha.
- El punto final de API se puede copiar desde la consola de CloudFormation - salida de la pila principal - "APIEndpoint".
- La clave API se puede copiar desde la consola de claves API de API Gateway: pila principal.
- La clave API de noticias se puede obtener en NewsAPI.org después de crear una cuenta de forma gratuita.
- Haga clic en el botón "Actualizar configuración" después de completar los valores.
- Al utilizar la aplicación web, un usuario especifica la cantidad de saltos (predeterminado N=2) en la ruta de conexión a monitorear.
- Para hacerlo, haga clic en el ícono de ajustes en la esquina superior derecha y luego especifique el valor de N.
- Al utilizar la aplicación web, un usuario especifica la lista de entidades a rastrear.
- Para hacerlo, haga clic en el ícono de ajustes en la esquina superior derecha y luego active el interruptor "Interesado" que marca la entidad correspondiente como INTERESADO=SÍ/NO.
- Este es un paso importante y debe realizarse antes de procesar cualquier artículo de noticias.
- Para generar noticias ficticias, un usuario hace clic en el botón "Generar noticias de muestra" para generar 10 noticias financieras de muestra con contenido aleatorio que se incluirán en el proceso de ingesta de noticias.
- El contenido se genera utilizando Amazon Bedrock y es puramente ficticio.
- Para descargar noticias reales, un usuario hace clic en el botón "Descargar últimas noticias" para descargar las principales noticias que suceden hoy (con tecnología de NewsAPI.org).
- Cargue noticias (.TXT) al depósito S3.
- El nombre del depósito de S3 al que se va a cargar se puede recuperar desde la consola de CloudFormation - salida de la pila principal - "NewsBucket"
- Los pasos 8 o 9 han cargado noticias en el depósito S3 automáticamente, pero también puede crear integraciones con su proveedor de noticias preferido, como AWS Data Exchange o cualquier proveedor de noticias externo, para colocar artículos de noticias como archivos en el depósito S3.
- El contenido del archivo de datos de noticias debe tener el formato: <fecha>{dd mmm aaaa}</date><title>{title}</title><text>{news content}</text>
- La notificación de eventos S3 envía el nombre del archivo/depósito S3 a SQS (estándar), lo que activa múltiples funciones lambda para procesar los datos de noticias en paralelo.
- Al utilizar Amazon Bedrock, la función lambda extrae las entidades mencionadas en las noticias junto con cualquier información, relaciones y sentimientos relacionados con la entidad mencionada.
- Luego lo compara con el gráfico de conocimiento y utiliza Amazon Bedrock para realizar la desambiguación mediante el razonamiento utilizando la información disponible en las noticias y dentro del gráfico de conocimiento para identificar la entidad correspondiente.
- Una vez que se ha localizado la entidad, busca y devuelve cualquier ruta de conexión que conecte con entidades marcadas con INTERESADO=SÍ en el gráfico de conocimiento que se encuentren a N=2 saltos de distancia.
- La aplicación web se actualiza automáticamente cada segundo para extraer el último conjunto de noticias procesadas y mostrarlas en la aplicación web.
Aplicación web React: configuración
Explorador de gráficos
Este repositorio también implementa Graph Explorer (github/aws/graphexplorer), que es una aplicación web basada en React que permite a los usuarios visualizar las entidades y relaciones extraídas.
- Para acceder a Graph Explorer, recupere la URL de la consola de CloudFormation - salida de la pila principal - "GraphExplorer"
- Al acceder a la aplicación web, recibirá una advertencia sobre un posible riesgo de seguridad en su navegador, ya que el certificado utilizado para el sitio está autofirmado. Puede continuar. Para deshacerse de la advertencia, lea esto.
- Una vez iniciada, la aplicación se conectará automáticamente a la base de datos de AWS Neptune y sincronizará sus datos. Puede hacer clic en el icono de actualización en cualquier momento para volver a sincronizar los datos.
- Haga clic en "Abrir Graph Explorer" en la parte superior derecha para comenzar a visualizar el gráfico de conocimiento.
- Vaya a github/aws/graphexplorer para obtener más información sobre Graph Explorer.
- Tenga en cuenta que Graph Explorer no es necesario como parte de la solución, pero le facilita explorar las relaciones extraídas.
Demostración: introducción a Graph Explorer
empezando-con-graph-explorer.mp4
Aquí hay otra demostración en video sobre las características de Graph Explorer: enlace a la demostración en video
Explorador de gráficos: gráfico de conocimiento
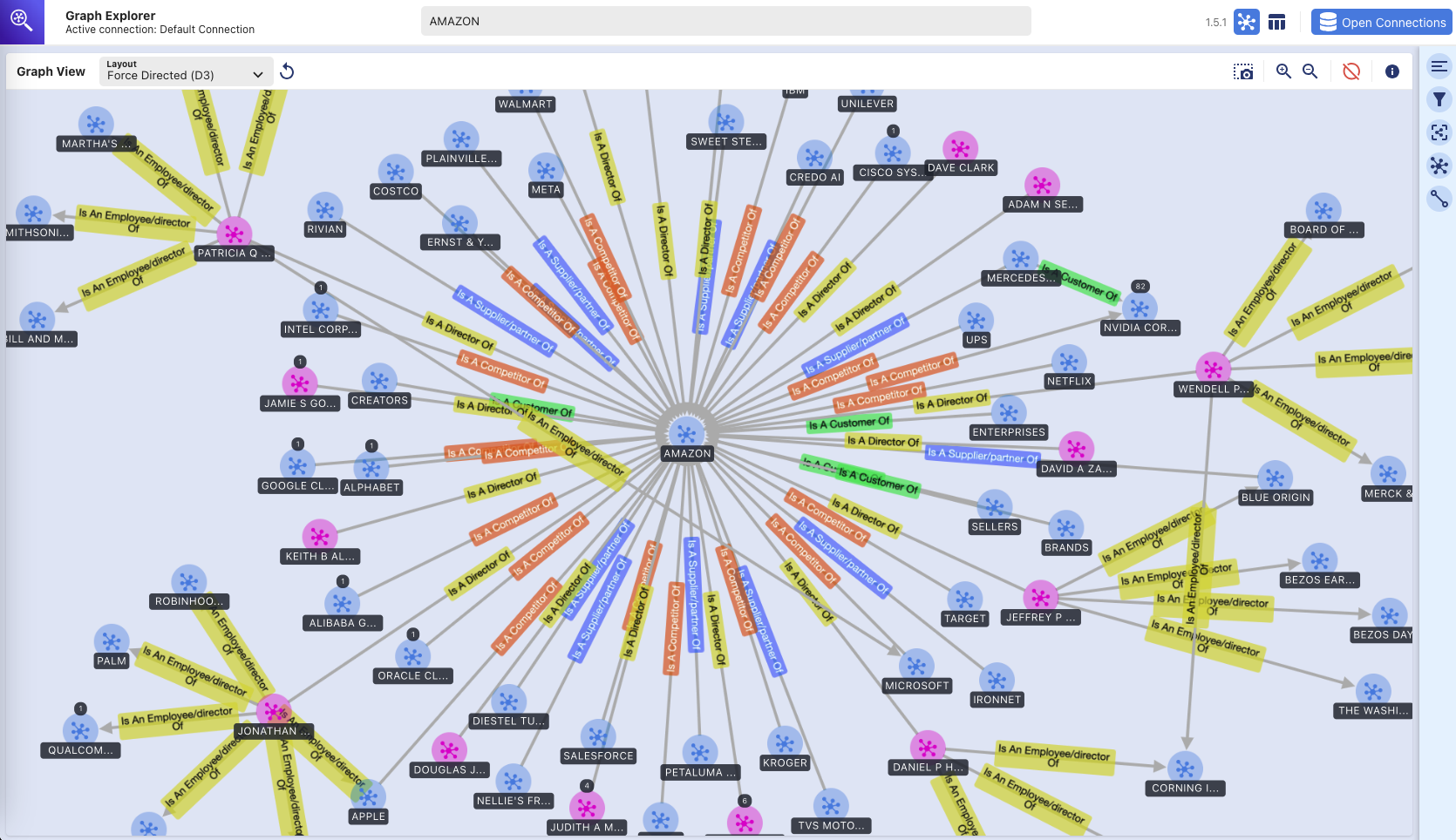
(exploración visual de la base de datos gráfica de Amazon Neptune utilizando la herramienta Graph Explorer)
Instrucciones de implementación
Este repositorio proporciona una aplicación CDK que implementará toda la solución prototipo en dos pilas de CDK:
- pila de aplicaciones principal ("pila principal") que se puede implementar en cualquier región (por ejemplo, us-east-1, us-west-2) que tenga los servicios requeridos y los modelos de Amazon Bedrock.
- Pila de aplicaciones web ("pila de aplicaciones web") que solo se puede implementar en us-east-1 ya que requiere AWS WAF.
Puede desplegar las dos pilas en regiones diferentes o en la misma región (es decir, us-east-1).
Servicios de AWS utilizados
- Roca Amazónica
- Amazonas Neptuno
- Extracto de Amazon
- AmazonDynamoDB
- Función de paso de AWS
- AWS Lambda
- Servicio de cola simple de Amazon (SQS)
- Puente de eventos de Amazon
- Servicio de almacenamiento simple de Amazon (S3)
- Amazon CloudFront
- WAF de AWS
- Nube informática elástica de Amazon (EC2)
- VPC de Amazon
- Puerta de enlace API de Amazon
- Gestión de acceso e identidad de AWS
Requisitos previos
- Amazon Bedrock: necesitará acceso a Anthropic Claude v3 Sonnet. Para configurar el acceso al modelo en Amazon Bedrock, lea esto.
- Python: necesitarás Python 3 y superior.
- Nodo: necesitará v18.0.0 y superior.
- Docker: necesitará v24.0.0 y superior con Docker Buildx y tendrá el demonio de Docker ejecutándose.
Configurar entorno virtual
Para crear manualmente un virtualenv en MacOS y Linux:
Una vez que se completa el proceso de inicio y se crea el virtualenv, puede utilizar el siguiente paso para activar su virtualenv.
$ source .venv/bin/activate
Si tiene una plataforma Windows, activaría virtualenv de esta manera:
% .venvScriptsactivate.bat
Una vez que virtualenv esté activado, puede instalar las dependencias necesarias.
$ pip install -r requirements.txt
Pre-implementación
Si es la primera vez que implementa su código a través de CDK en su cuenta de AWS, primero deberá iniciar su cuenta de AWS tanto en us-east-1 como en la región en la que está implementando. De lo contrario, puedes saltarte este paso.
$ cdk bootstrap aws://<account no>/us-east-1 aws://<account no>/<aws region to deploy main application stack>
Luego proceda a ejecutar el siguiente comando para:
- construir la aplicación web basada en React
- descargue las dependencias de Python necesarias para crear la capa AWS Lambda
- copiar biblioteca personalizada (connectionsinsights)
Desplegar
Para implementar la solución (tarda aproximadamente 30 minutos):
$ ./deploy.sh <aws region to deploy main application stack>
Limpiar
Para destruir la solución:
$ ./destroy.sh <aws region where main application stack was deployed>
Si encuentra un error de eliminación debido a que los depósitos de S3 no están vacíos, esto podría deberse a archivos de registro de acceso escritos en los depósitos de S3 después de que se vaciaron como parte del proceso de destrucción del cdk. Si esto sucede, simplemente vacíe esos depósitos y vuelva a ejecutar el comando de limpieza.


