airllm
1.0.0

Inicio rápido | Configuraciones | Mac OS | Cuadernos de ejemplo | Preguntas frecuentes
AirLLM optimiza el uso de la memoria de inferencia, lo que permite que 70 mil millones de modelos de lenguaje grandes ejecuten inferencia en una sola tarjeta GPU de 4 GB sin cuantificación, destilación ni poda. Y ahora puedes ejecutar 405B Llama3.1 en 8 GB de vram .
[2024/08/20] v2.11.0: Compatible con Qwen2.5
[2024/08/18] v2.10.1 Admite inferencia de CPU. Admite modelos no fragmentados. ¡Gracias @NavodPeiris por el gran trabajo!
[30/07/2024] Soporte Llama3.1 405B (portátil de ejemplo). Admite cuantificación de 8 bits/4 bits .
[2024/04/20] AirLLM ya es compatible con Llama3 de forma nativa. Ejecute Llama3 70B en una GPU única de 4 GB.
[2023/12/25] v2.8.2: Admite MacOS con 70.000 millones de modelos de idiomas grandes.
[2023/12/20] v2.7: Soporte AirLLMMixtral.
[2023/12/20] v2.6: AutoModel agregado, detecta automáticamente el tipo de modelo, no es necesario proporcionar la clase de modelo para inicializar el modelo.
[2023/12/18] v2.5: se agregó captura previa para superponer la carga y el cálculo del modelo. 10% de mejora de velocidad.
[03/12/2023] ¡Se agregó soporte para ChatGLM , QWen , Baichuan , Mistral , InternLM !
[2023/12/02] se agregó soporte para tensores de seguridad. Ahora admite los 10 mejores modelos en la clasificación de Open LLM.
[2023/12/01] airllm 2.0. Compresiones de soporte: ¡acelera el tiempo de ejecución 3 veces más!
[2023/11/20] airllm ¡Versión inicial!
Primero, instale el paquete airllm pip.
pip install airllmLuego, inicialice AirLLMLlama2, pase el ID del repositorio de huggingface del modelo que se está utilizando o la ruta local, y la inferencia se puede realizar de manera similar a un modelo de transformador normal.
( También puede especificar la ruta para guardar el modelo en capas dividido a través de Layer_shards_served_path cuando inicia AirLLMLlama2.
from airllm import AutoModel
MAX_LENGTH = 128
# could use hugging face model repo id:
model = AutoModel . from_pretrained ( "garage-bAInd/Platypus2-70B-instruct" )
# or use model's local path...
#model = AutoModel.from_pretrained("/home/ubuntu/.cache/huggingface/hub/models--garage-bAInd--Platypus2-70B-instruct/snapshots/b585e74bcaae02e52665d9ac6d23f4d0dbc81a0f")
input_text = [
'What is the capital of United States?' ,
#'I like',
]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = False )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 20 ,
use_cache = True ,
return_dict_in_generate = True )
output = model . tokenizer . decode ( generation_output . sequences [ 0 ])
print ( output )Nota: Durante la inferencia, el modelo original primero se descompondrá y se guardará en capas. Asegúrese de que haya suficiente espacio en disco en el directorio de caché de Huggingface.
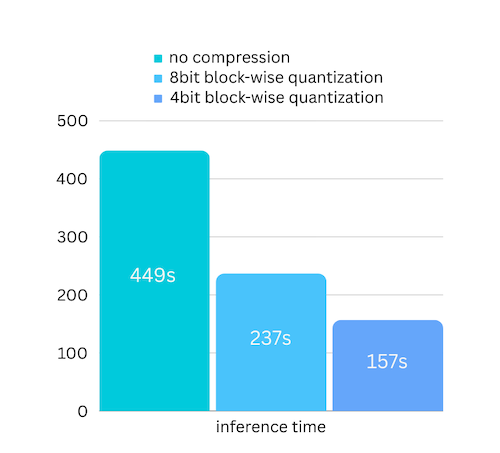
Acabamos de agregar compresión de modelo basada en la compresión de modelo basada en cuantificación por bloques. Lo que puede acelerar aún más la velocidad de inferencia hasta 3 veces , ¡con una pérdida de precisión casi ignorable! (consulte más evaluaciones de rendimiento y por qué utilizamos la cuantificación por bloques en este documento)
pip install -U bitsandbytespip install -U airllm model = AutoModel . from_pretrained ( "garage-bAInd/Platypus2-70B-instruct" ,
compression = '4bit' # specify '8bit' for 8-bit block-wise quantization
)La cuantificación normalmente necesita cuantificar tanto los pesos como las activaciones para acelerar realmente las cosas. Lo que hace que sea más difícil mantener la precisión y evitar el impacto de valores atípicos en todo tipo de entradas.
Si bien en nuestro caso el cuello de botella se encuentra principalmente en la carga del disco, solo necesitamos reducir el tamaño de carga del modelo. Por lo tanto, solo podemos cuantificar la parte de los pesos, lo que es más fácil de garantizar la precisión.
Al inicializar el modelo, admitimos las siguientes configuraciones:
Simplemente instale airllm y ejecute el código igual que en Linux. Vea más en Inicio rápido.
Ejemplo [cuaderno de Python] (https://github.com/lyogavin/airllm/blob/main/air_llm/examples/run_on_macos.ipynb)
Colaboraciones de ejemplo aquí:
from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "THUDM/chatglm3-6b-base" )
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = True )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ]) from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "Qwen/Qwen-7B" )
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ]) from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "baichuan-inc/Baichuan2-7B-Base" )
#model = AutoModel.from_pretrained("internlm/internlm-20b")
#model = AutoModel.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ])Gran parte del código se basa en el gran trabajo de SimJeg en la competencia de exámenes de Kaggle. Un gran agradecimiento a SimJeg:
Cuenta de GitHub @SimJeg, el código en Kaggle, la discusión asociada.
safetensors_rust.SafetensorError: Error al deserializar el encabezado: MetadataIncompleteBuffer
Si se encuentra con este error, la causa más posible es que se haya quedado sin espacio en el disco. El proceso de división del modelo consume mucho disco. Mira esto. Es posible que necesite ampliar su espacio en disco, borrar el archivo .cache de huggingface y volver a ejecutarlo.
Lo más probable es que esté cargando el modelo QWen o ChatGLM con la clase Llama2. Pruebe lo siguiente:
Para el modelo QWen:
from airllm import AutoModel #<----- instead of AirLLMLlama2
AutoModel . from_pretrained (...)Para el modelo ChatGLM:
from airllm import AutoModel #<----- instead of AirLLMLlama2
AutoModel . from_pretrained (...)Algunos modelos son modelos cerrados, necesitan el token API de Huggingface. Puedes proporcionar hf_token:
model = AutoModel . from_pretrained ( "meta-llama/Llama-2-7b-hf" , #hf_token='HF_API_TOKEN')El tokenizador de algunos modelos no tiene un token de relleno, por lo que puedes configurar un token de relleno o simplemente desactivar la configuración de relleno:
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = False #<----------- turn off padding
)Si encuentra útil AirLLM en su investigación y desea citarlo, utilice la siguiente entrada de BibTex:
@software{airllm2023,
author = {Gavin Li},
title = {AirLLM: scaling large language models on low-end commodity computers},
url = {https://github.com/lyogavin/airllm/},
version = {0.0},
year = {2023},
}
¡Bienvenidas contribuciones, ideas y debates!
Si te resulta útil, ¡por favor o invítame un café!


