WilmerAI
1.0.0
Este es un proyecto personal que se encuentra en pleno desarrollo. Podría contener, y probablemente contiene, errores, código incompleto u otros problemas no deseados. Como tal, el software se proporciona tal cual, sin garantía de ningún tipo.
WilmerAI refleja el trabajo de un único desarrollador y el esfuerzo de su tiempo y recursos personales; cualquier punto de vista, metodología, etc. que se encuentre dentro es suyo y no debe reflejarse en su empleador.
WilmerAI es un sofisticado sistema de middleware diseñado para recibir indicaciones entrantes y realizar diversas tareas antes de enviarlas a las API de LLM. Este trabajo incluye la utilización de un modelo de lenguaje grande (LLM) para categorizar el mensaje y enrutarlo al flujo de trabajo apropiado o procesar un contexto grande (más de 200 000 tokens) para generar un mensaje más pequeño y manejable adecuado para la mayoría de los modelos locales.
WilmerAI significa "¿Qué pasaría si los modelos de lenguaje enrutaran de manera experta todas las inferencias?"
Asistentes impulsados por varios LLM en tándem : las indicaciones entrantes se pueden enrutar a "categorías", y cada categoría está impulsada por un flujo de trabajo. Cada flujo de trabajo puede tener tantos nodos como desee, cada nodo impulsado por un LLM diferente. Por ejemplo, si le preguntas a tu asistente "¿Puedes escribirme un juego de Snake en Python?", eso podría clasificarse como CODIFICACIÓN y pasar a tu flujo de trabajo de codificación. El primer nodo de ese flujo de trabajo podría pedirle a Codestral-22b (o ChatGPT 4o si lo desea) que responda la pregunta. El segundo nodo podría pedirle a Deepseek V2 o Claude Sonnet que revisen el código. El siguiente nodo podría pedirle a Codestral que le dé un último vistazo y luego le responda. Ya sea que su flujo de trabajo sea solo un modelo único que responde porque es su mejor codificador, o si hay muchos nodos de diferentes LLM trabajando juntos para generar una respuesta, la elección es suya.
Soporte para la API de Wikipedia sin conexión : WilmerAI tiene un nodo que puede realizar llamadas a la API de Wikipedia sin conexión. Esto significa que puede tener una categoría, por ejemplo "HECHO", que analiza su mensaje entrante, genera una consulta a partir de él, consulta la API de Wikipedia para un artículo relacionado y usa ese artículo como inyección de contexto RAG para responder.
Resúmenes de chat generados continuamente para simular una "memoria" : el nodo Resumen de chat generará "recuerdos", fragmentando sus mensajes y luego resumiéndolos y guardándolos en un archivo. Luego tomará esos fragmentos resumidos y generará un resumen continuo y en constante actualización de toda la conversación, que se puede extraer y utilizar dentro del mensaje del LLM. Los resultados le permiten tomar más de 200.000 conversaciones de contexto y realizar un seguimiento relativo de lo que se ha dicho, incluso cuando se limitan las indicaciones del LLM a 5.000 contextos o menos.
Utilice varias computadoras para procesar memorias y respuestas en paralelo : si tiene 2 computadoras que pueden ejecutar LLM, puede designar una para que sea la "respondedora" y otra para que sea responsable de generar memorias/resúmenes. Este tipo de flujo de trabajo le permite seguir hablando con su LLM mientras se actualizan las memorias/resumen, sin dejar de utilizar las memorias existentes. Esto significa no tener que esperar nunca a que se actualice el resumen, incluso si asigna a un modelo grande y potente la tarea de encargarse de esa tarea para tener recuerdos de mayor calidad. (Ver ejemplo de usuario convo-role-dual-model )
Chats grupales de varios LLM en SillyTavern: es posible usar Wilmer para tener un chat grupal en ST donde cada personaje es un LLM diferente, si lo desea (el autor lo hace personalmente). Hay personajes de ejemplo disponibles en DocsSillyTavern . dividirse en dos grupos. Estos personajes/grupos de ejemplo son subconjuntos de grupos más grandes que utiliza el autor.
Funcionalidad de middleware: WilmerAI se encuentra entre la interfaz que utiliza para comunicarse con un LLM (como SillyTavern, OpenWebUI o incluso la terminal de un programa Python) y la API de backend que sirve a los LLM. Puede manejar múltiples LLM de backend simultáneamente.
Uso de varios LLM a la vez: configuración de ejemplo: SillyTavern -> WilmerAI -> varias instancias de KoboldCpp. Por ejemplo, Wilmer podría conectarse a Command-R 35b, Codestral 22b, Gemma-2-27b y usarlos todos en sus respuestas al usuario. Siempre que su LLM de elección esté expuesto a través de un punto final v1/Finalización o chat/Finalización, o el punto final Generar de KoboldCpp, puede usarlo.
Ajustes preestablecidos personalizables : los ajustes preestablecidos se guardan en un archivo json que puede personalizar fácilmente. Casi todos los ajustes preestablecidos se pueden administrar a través de json, incluidos los nombres de los parámetros. Esto significa que no es necesario esperar una actualización de Wilmer para utilizar algo nuevo. Por ejemplo, DRY apareció recientemente en KoboldCpp. Si eso no estaba en el json preestablecido para Wilmer, deberías poder simplemente agregarlo y comenzar a usarlo.
Puntos finales de API: proporciona puntos finales chat/Completions y v1/Completions compatibles con API OpenAI para conectarse a través de su interfaz, y puede conectarse a cualquier tipo en el back-end. Esto permite configuraciones complejas, como conectarse a Wilmer como una API v1/Completion y luego tener Wilmer conectado a chat/Completion, v1/Completion KoboldCpp Generar puntos finales, todo al mismo tiempo.
Plantillas de aviso: admite plantillas de aviso para puntos finales de API v1/Completions . WilmerAI también tiene su propia plantilla de avisos para conexiones desde una interfaz a través de v1/Completions . La plantilla se puede encontrar en la carpeta "Documentos" y está lista para cargarla en SillyTavern.
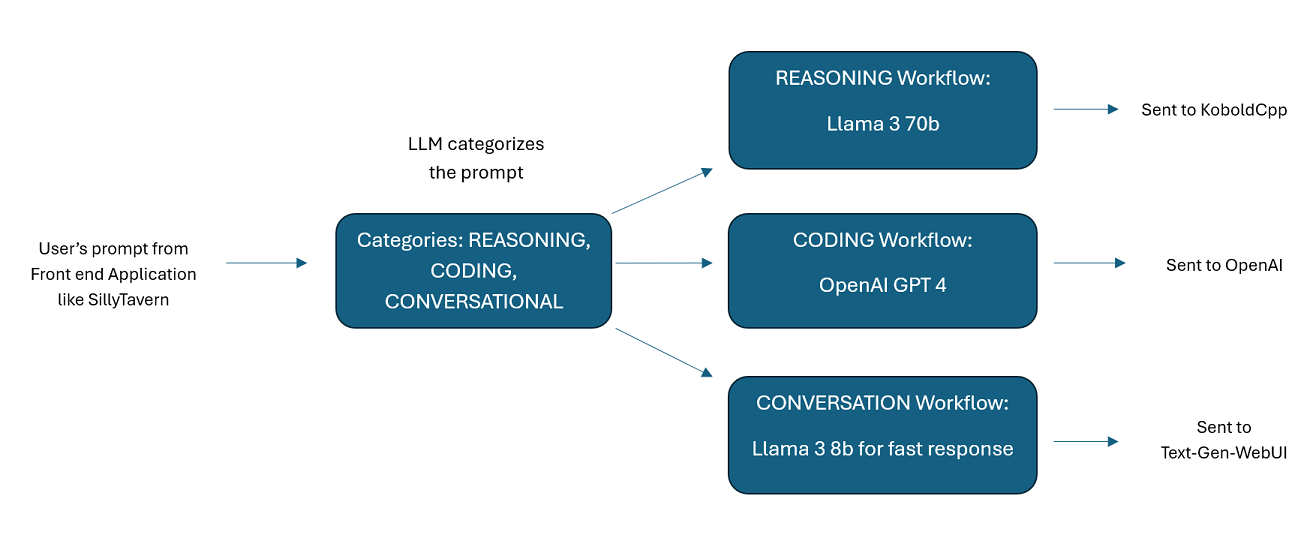
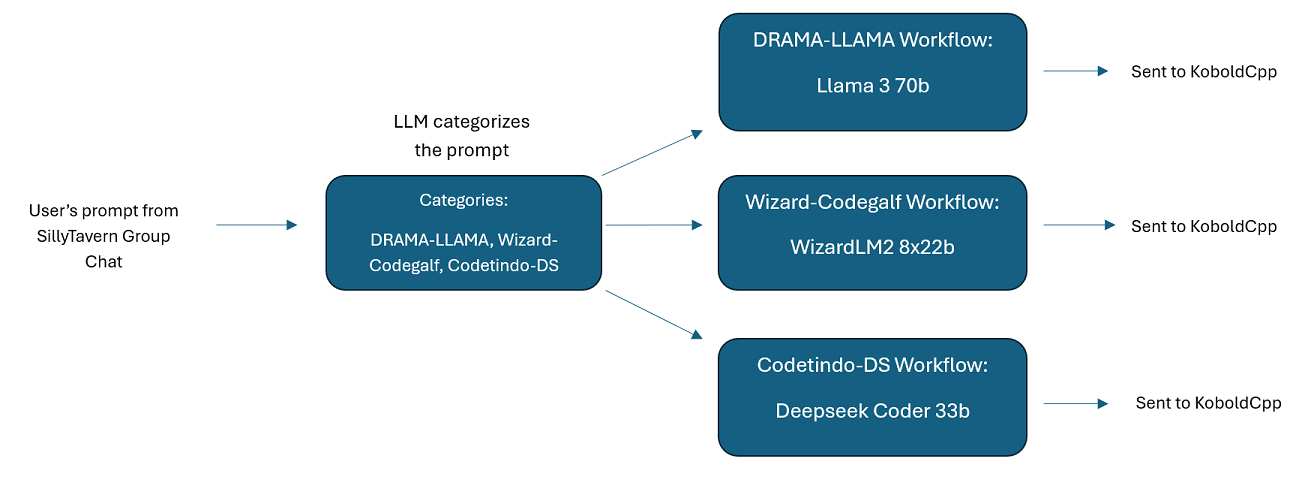
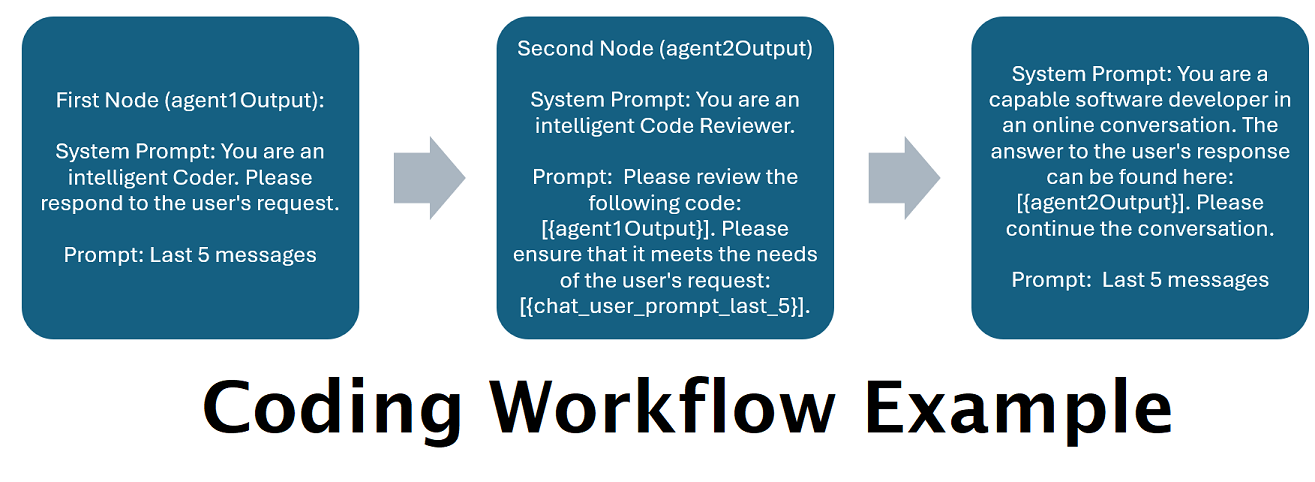
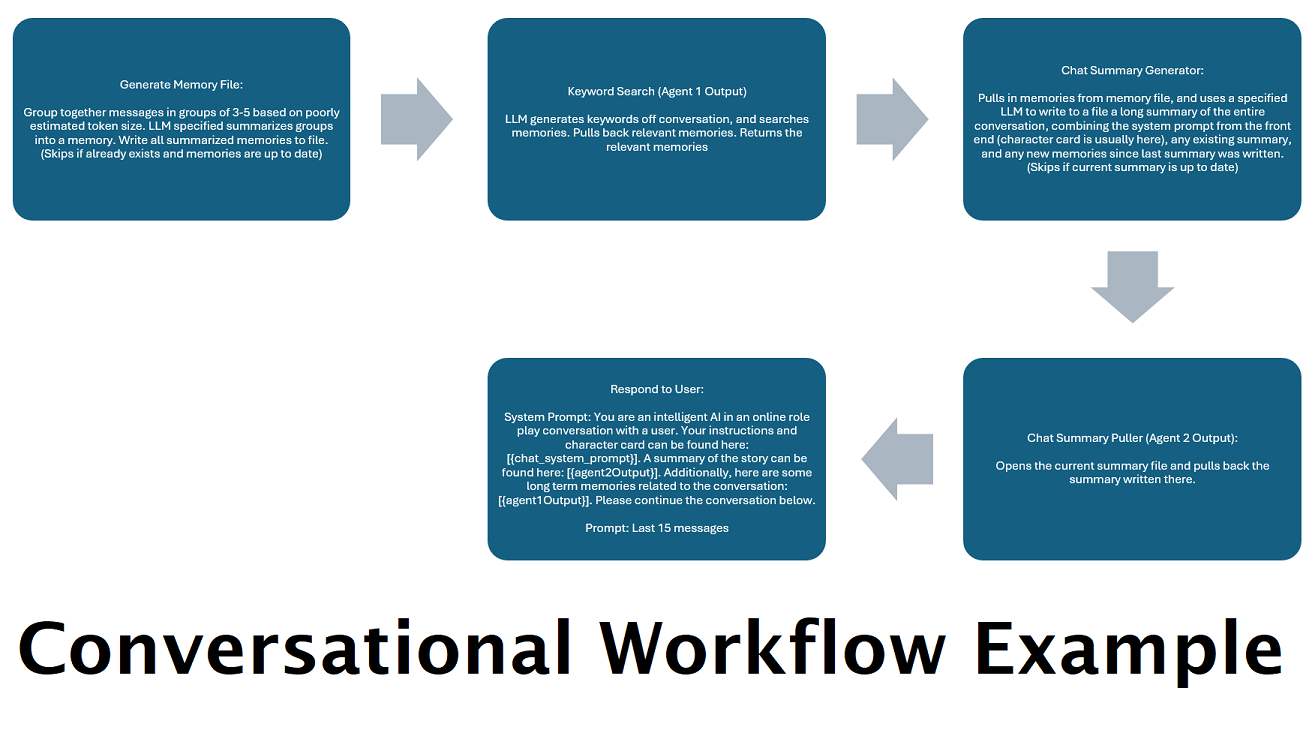

Tenga en cuenta que los flujos de trabajo, por su propia naturaleza, podrían realizar muchas llamadas a un punto final de API según cómo los configure. WilmerAI no rastrea el uso de tokens, no informa el uso preciso de tokens a través de su API ni ofrece ninguna forma viable de monitorear el uso de tokens. Entonces, si el seguimiento del uso de tokens es importante para usted por razones de costo, asegúrese de realizar un seguimiento de cuántos tokens está utilizando a través de cualquier panel que le proporcionen sus API de LLM, especialmente desde el principio, cuando se acostumbre a este software.
Su LLM afecta directamente la calidad de WilmerAI. Este es un proyecto impulsado por un LLM, donde los flujos y resultados dependen casi por completo de los LLM conectados y sus respuestas. Si conecta Wilmer a un modelo que produce resultados de menor calidad, o si sus ajustes preestablecidos o plantilla de mensajes tienen fallas, entonces la calidad general de Wilmer también será mucho menor. En ese sentido, no es muy diferente a los flujos de trabajo agentes.
Si bien el autor está haciendo todo lo posible para crear algo útil y de alta calidad, este es un proyecto en solitario ambicioso y seguramente tendrá sus problemas (especialmente porque el autor no es un desarrollador nativo de Python y dependió en gran medida de la IA para ayudarlo a lograrlo). lejos). Aunque poco a poco lo está descubriendo.
Wilmer expone un punto final OpenAI v1/Completions y chat/Completions, lo que lo hace compatible con la mayoría de las interfaces. Si bien he usado esto principalmente con SillyTavern, también podría funcionar con Open-WebUI.
Para conectarse como complemento de texto en SillyTavern, siga estos pasos (la siguiente captura de pantalla es de SillyTavern):
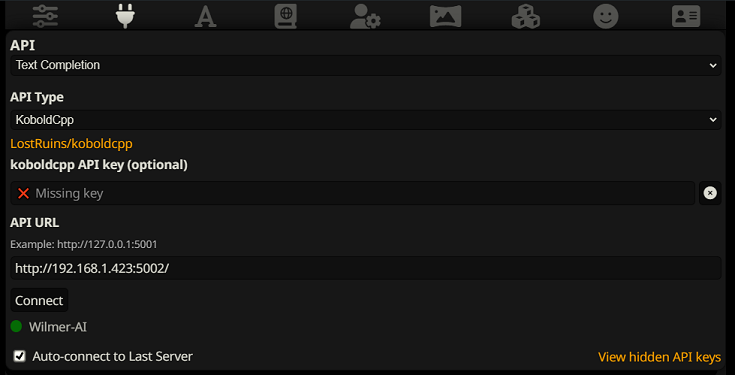
Cuando utilice completaciones de texto, debe utilizar un formato de plantilla de aviso específico de WilmerAI. Puede encontrar un archivo ST importable en Docs/SillyTavern/InstructTemplate . La plantilla de contexto también se incluye si desea utilizarla también.
La plantilla de instrucciones se ve así:
[Beg_Sys]You are an intelligent AI Assistant.[Beg_User]SomeOddCodeGuy: Hey there![Beg_Assistant]Wilmer: Hello![Beg_User]SomeOddCodeGuy: This is a test[Beg_Assistant]Wilmer: Nice.
De SillyTavern:
"input_sequence": "[Beg_User]",
"output_sequence": "[Beg_Assistant]",
"first_output_sequence": "[Beg_Assistant]",
"last_output_sequence": "",
"system_sequence_prefix": "[Beg_Sys]",
"system_sequence_suffix": "",
No se esperan nuevas líneas ni caracteres entre etiquetas.
Asegúrese de que la plantilla de contexto esté "habilitada" (casilla de verificación encima del menú desplegable)
Para conectarse como Finalizaciones de chat en SillyTavern, siga estos pasos (la siguiente captura de pantalla es de SillyTavern):
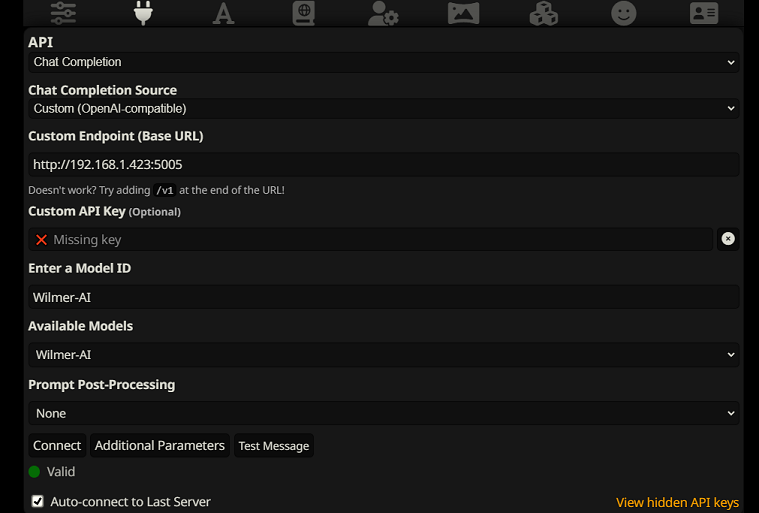
chatCompleteAddUserAssistant en verdadero. (No recomiendo establecer ambos en verdadero al mismo tiempo. Utilice nombres de personajes de SillyTavern o usuario/asistente de Wilmer. De lo contrario, la IA podría confundirse).Para cualquier tipo de conexión, recomiendo ir al ícono "A" en SillyTavern y seleccionar "Incluir nombres" y "Forzar grupos y personas" en el modo de instrucción, y luego ir al ícono del extremo izquierdo (donde están las muestras) y marcar " transmitir" en la parte superior izquierda, y luego en la parte superior derecha marcando "desbloquear" en contexto y arrastrándolo a 200,000+. Dejemos que Wilmer se preocupe por el contexto.
Wilmer actualmente no tiene interfaz de usuario; todo se controla a través de archivos de configuración JSON ubicados en la carpeta "Pública". Esta carpeta contiene todas las configuraciones esenciales. Al actualizar o descargar una nueva copia de WilmerAI, simplemente debe copiar su carpeta "Pública" a la nueva instalación para conservar su configuración.
Esta sección lo guiará a través de la configuración de Wilmer. He dividido las secciones en pasos; Podría recomendar copiar cada paso, 1 por 1, en un LLM y pedirle que le ayude a configurar la sección. Eso puede hacer que esto sea mucho más fácil.
NOTAS IMPORTANTES
Es importante tener en cuenta tres cosas sobre la configuración de Wilmer.
A) Los archivos preestablecidos son 100% personalizables. Lo que hay en ese archivo va a la API llm. Esto se debe a que las API de la nube no manejan algunos de los diversos ajustes preestablecidos que manejan las API de LLM locales. Como tal, si usa la API OpenAI u otros servicios en la nube, las llamadas probablemente fallarán si usa uno de los ajustes preestablecidos de IA locales habituales. Consulte la "OpenAI-API" preestablecida para ver un ejemplo de lo que acepta openAI.
B) Recientemente reemplacé todas las indicaciones en Wilmer para pasar de usar la segunda persona a la tercera persona. Esto ha tenido resultados bastante decentes para mí y espero que también los tenga para usted.
C) De forma predeterminada, todos los archivos de usuario están configurados para activar la transmisión de respuestas. Debe habilitar esto en su interfaz que llama a Wilmer para que ambos coincidan, o debe ingresar Usuarios/nombredeusuario.json y configurar Stream en "falso". Si tiene una discrepancia, donde la interfaz espera/no espera transmisión y su wilmer espera lo contrario, es probable que no se muestre nada en la interfaz.
Instalar Wilmer es sencillo. Asegúrese de tener Python instalado; El autor ha estado usando el programa con Python 3.10 y 3.12 y ambos funcionan bien.
Opción 1: utilizar los scripts proporcionados
Para mayor comodidad, Wilmer incluye un archivo BAT para Windows y un archivo .sh para macOS. Estos scripts crearán un entorno virtual, instalarán los paquetes necesarios desde requirements.txt y luego ejecutarán Wilmer. Puede utilizar estos scripts para iniciar Wilmer cada vez.
.bat proporcionado..sh proporcionado.IMPORTANTE: Nunca ejecute un archivo BAT o SH sin inspeccionarlo primero, ya que esto puede ser riesgoso. Si no está seguro de la seguridad de dicho archivo, ábralo en el Bloc de notas/TextEdit, copie el contenido y luego solicite a su LLM que lo revise para detectar posibles problemas.
Opción 2: Instalación manual
Alternativamente, puede instalar manualmente las dependencias y ejecutar Wilmer con los siguientes pasos:
Instale los paquetes necesarios:
pip install -r requirements.txtInicie el programa:
python server.pyLos scripts proporcionados están diseñados para agilizar el proceso mediante la configuración de un entorno virtual. Sin embargo, puedes ignorarlos con seguridad si prefieres la instalación manual.
NOTA : Al ejecutar el archivo bat, el archivo sh o el archivo python, los tres ahora aceptan los siguientes argumentos OPCIONALES:
Entonces, por ejemplo, considere las siguientes ejecuciones posibles:
bash run_macos.sh (utilizará el usuario especificado en _current-user.json, configuraciones en "Público", registros en "registros")bash run_macos.sh --User "single-model-assistant" (el valor predeterminado será público para las configuraciones y "registro" para los registros)bash run_macos.sh --ConfigDirectory "/users/socg/Public/configs" --User "single-model-assistant" (solo usará el valor predeterminado para "registros"bash run_macos.sh --ConfigDirectory "/users/socg/Public/configs" --User "single-model-assistant" --LoggingDirectory "/users/socg/wilmerlogs"Estos argumentos opcionales permiten a los usuarios activar múltiples instancias de WilmerAI, cada instancia usando un perfil de usuario diferente, iniciando sesión en un lugar diferente y especificando configuraciones en una ubicación diferente, si lo desean.
Dentro de Public/Configs encontrará una serie de carpetas que contienen archivos json. Las dos que más le interesan son la carpeta Endpoints y la carpeta Users .
NOTA: Los nodos de flujo de trabajo Factual de los usuarios de assistant-single-model , assistant-multi-model y group-chat-example intentarán utilizar el proyecto OfflineWikipediaTextApi para extraer artículos completos de Wikipedia en RAG. Si no tiene esta API, el flujo de trabajo no debería tener ningún problema, pero yo personalmente uso esta API para ayudar a mejorar las respuestas objetivas que recibo. Puede especificar la dirección IP de su API en el json de usuario de su elección.
Primero, elija qué usuario de plantilla le gustaría usar:
Assistant-single-model : esta plantilla es para un único modelo pequeño que se utiliza en todos los nodos. Esto también tiene rutas para muchos tipos de categorías diferentes y utiliza ajustes preestablecidos apropiados para cada nodo. Si te preguntas por qué hay rutas para diferentes categorías cuando solo hay 1 modelo: es para que puedas darle a cada categoría sus propios ajustes preestablecidos y también para que puedas crear flujos de trabajo personalizados para ellas. Tal vez desee que el codificador realice varias iteraciones para comprobarse a sí mismo o que el razonamiento le permita pensar las cosas en varios pasos.
asistente-multi-modelo : esta plantilla es para usar muchos modelos en conjunto. Al observar los puntos finales de este usuario, puede ver que cada categoría tiene su propio punto final. No hay absolutamente nada que le impida reutilizar la misma API para múltiples categorías. Por ejemplo, puede usar Llama 3.1 70b para codificación, matemáticas y razonamiento, y Command-R 35b 08-2024 para categorización, conversación y factual. No sientas que NECESITAS 10 modelos diferentes. Esto es simplemente para permitirle traer tantos si lo desea. Este usuario utiliza ajustes preestablecidos apropiados para cada nodo en los flujos de trabajo.
convo-roleplay-single-model : este usuario utiliza un modelo único con un flujo de trabajo personalizado que es bueno para las conversaciones y debería ser bueno para los juegos de roles (esperando comentarios para modificar si es necesario). Esto evita todas las rutas.
convo-roleplay-dual-model : este usuario utiliza dos modelos con un flujo de trabajo personalizado que es bueno para las conversaciones y debería ser bueno para los juegos de roles (a la espera de comentarios para modificarlos si es necesario). Esto evita todas las rutas. NOTA : Este flujo de trabajo funciona mejor si tiene 2 computadoras que pueden ejecutar LLM. Con la configuración actual para este usuario, cuando envíe un mensaje a Wilmer, el modelo de respuesta (computadora 1) le responderá. Luego, el flujo de trabajo aplicará un "bloqueo de flujo de trabajo" en ese punto. El modelo de resumen de memoria/chat (computadora 2) comenzará a actualizar los recuerdos y el resumen de la conversación hasta el momento, que se pasa al respondedor para ayudarlo a recordar cosas. Si enviara otro mensaje mientras se escriben los recuerdos, el respondedor (computadora 1) tomará cualquier resumen que exista y continuará respondiéndole. El bloqueo del flujo de trabajo le impedirá volver a ingresar a la sección de nuevos recuerdos. Lo que esto significa es que puedes seguir hablando con tu modelo de respuesta mientras se escriben nuevos recuerdos. Este es un ENORME aumento de rendimiento. Lo probé y para mí los tiempos de respuesta fueron increíbles. Sin esto, obtengo respuestas en 30 segundos de 3 a 5 veces y, de repente, tengo una espera de 2 minutos para generar recuerdos. Con esto, cada mensaje dura 30 segundos, cada vez, en Llama 3.1 70b en mi Mac Studio.
group-chat-example : este usuario es un ejemplo de mis propios chats grupales personales. Los personajes y los grupos incluidos son personajes y grupos reales que uso. Puedes encontrar los personajes de ejemplo en la carpeta Docs/SillyTavern . Estos son caracteres compatibles con SillyTavern que puedes importar directamente a ese programa o a cualquier programa que admita tipos de importación de caracteres .png. Los personajes del equipo de desarrollo tienen solo 1 nodo por flujo de trabajo: simplemente te responden. Los personajes del grupo de asesoramiento tienen 2 nodos por flujo de trabajo: el primer nodo genera una respuesta y el segundo nodo impone la "persona" del personaje (el punto final a cargo de esto es el punto final businessgroup-speaker ). Las personas del chat grupal ayudan mucho a variar las respuestas que obtienes, incluso si usas solo un modelo. Sin embargo, mi objetivo es usar diferentes modelos para cada personaje (pero reutilizar modelos entre grupos; así, por ejemplo, tengo un personaje modelo Llama 3.1 70b en cada grupo).
Una vez que haya seleccionado el usuario que desea utilizar, hay un par de pasos a seguir:
Actualice los puntos finales para su usuario en Público/Configuraciones/Puntos finales. Los personajes de ejemplo están ordenados en carpetas para cada uno. La carpeta del punto final del usuario se especifica en la parte inferior de su archivo user.json. Querrá completar cada punto final de manera adecuada para los LLM que está utilizando. Puede encontrar algunos puntos finales de ejemplo en la carpeta _example-endpoints .
Deberá configurar su usuario actual. Puede hacer esto cuando ejecuta el archivo bat/sh/py usando el argumento --User, o puede hacerlo en Public/Configs/Users/_current-user.json. Simplemente coloque el nombre del usuario como usuario actual y guárdelo.
Querrá abrir su archivo json de usuario y echar un vistazo a las opciones. Aquí puede establecer si desea transmitir o no, puede configurar la dirección IP de su API wiki fuera de línea (si la está usando), especificar dónde desea que vayan sus archivos de recuerdos/resumen durante los flujos de DiscussionId y también especificar dónde desea que la base de datos sqllite desaparezca si usa bloqueos de flujo de trabajo.
¡Eso es todo! Ejecute Wilmer, conéctese a él y estará listo para comenzar.
Primero, configuraremos los puntos finales y los modelos. Dentro de la carpeta Public/Configs debería ver las siguientes subcarpetas. Repasemos lo que necesita.
Estos archivos de configuración representan los puntos finales de la API de LLM a los que está conectado. Por ejemplo, el siguiente archivo JSON, SmallModelEndpoint.json , define un punto final:
{
"modelNameForDisplayOnly" : " Small model for all tasks " ,
"endpoint" : " http://127.0.0.1:5000 " ,
"apiTypeConfigFileName" : " KoboldCpp " ,
"maxContextTokenSize" : 8192 ,
"modelNameToSendToAPI" : " " ,
"promptTemplate" : " chatml " ,
"addGenerationPrompt" : true
}Estos archivos de configuración representan los diferentes tipos de API a los que podría acceder al utilizar Wilmer.
{
"nameForDisplayOnly" : " KoboldCpp Example " ,
"type" : " koboldCppGenerate " ,
"presetType" : " KoboldCpp " ,
"truncateLengthPropertyName" : " max_context_length " ,
"maxNewTokensPropertyName" : " max_length " ,
"streamPropertyName" : " stream "
} Estos archivos especifican la plantilla de solicitud para un modelo. Considere el siguiente ejemplo, llama3.json :
{
"promptTemplateAssistantPrefix" : " <|start_header_id|>assistant<|end_header_id|> nn " ,
"promptTemplateAssistantSuffix" : " <|eot_id|> " ,
"promptTemplateEndToken" : " " ,
"promptTemplateSystemPrefix" : " <|start_header_id|>system<|end_header_id|> nn " ,
"promptTemplateSystemSuffix" : " <|eot_id|> " ,
"promptTemplateUserPrefix" : " <|start_header_id|>user<|end_header_id|> nn " ,
"promptTemplateUserSuffix" : " <|eot_id|> "
} Estas plantillas se aplican a todas las llamadas de punto final v1/Finalización. Si prefiere no utilizar una plantilla, hay un archivo llamado _chatonly.json que divide los mensajes únicamente con nuevas líneas.
Crear y activar un usuario implica cuatro pasos principales. Siga las instrucciones a continuación para configurar un nuevo usuario.
Primero, dentro de la carpeta Users , cree un archivo JSON para el nuevo usuario. La forma más sencilla de hacerlo es copiar un archivo JSON de usuario existente, pegarlo como duplicado y luego cambiarle el nombre. A continuación se muestra un ejemplo de un archivo JSON de usuario:
{
"port" : 5006 ,
"stream" : true ,
"customWorkflowOverride" : false ,
"customWorkflow" : " CodingWorkflow-LargeModel-Centric " ,
"routingConfig" : " assistantSingleModelCategoriesConfig " ,
"categorizationWorkflow" : " CustomCategorizationWorkflow " ,
"defaultParallelProcessWorkflow" : " SlowButQualityRagParallelProcessor " ,
"fileMemoryToolWorkflow" : " MemoryFileToolWorkflow " ,
"chatSummaryToolWorkflow" : " GetChatSummaryToolWorkflow " ,
"conversationMemoryToolWorkflow" : " CustomConversationMemoryToolWorkflow " ,
"recentMemoryToolWorkflow" : " RecentMemoryToolWorkflow " ,
"discussionIdMemoryFileWorkflowSettings" : " _DiscussionId-MemoryFile-Workflow-Settings " ,
"discussionDirectory" : " D: \ Temp " ,
"sqlLiteDirectory" : " D: \ Temp " ,
"chatPromptTemplateName" : " _chatonly " ,
"verboseLogging" : true ,
"chatCompleteAddUserAssistant" : true ,
"chatCompletionAddMissingAssistantGenerator" : true ,
"useOfflineWikiApi" : true ,
"offlineWikiApiHost" : " 127.0.0.1 " ,
"offlineWikiApiPort" : 5728 ,
"endpointConfigsSubDirectory" : " assistant-single-model " ,
"useFileLogging" : false
}0.0.0.0 , lo que lo hace visible en su red si se ejecuta en otra computadora. Se admite la ejecución de varias instancias de Wilmer en diferentes puertos.true , el enrutador está deshabilitado y todos los mensajes van solo al flujo de trabajo especificado, lo que lo convierte en una única instancia de flujo de trabajo de Wilmer.customWorkflowOverride sea true .Routing , sin la extensión .json .DiscussionId .chatCompleteAddUserAssistant es true .DataFinder del grupo de ejemplo. A continuación, actualice el archivo _current-user.json para especificar qué usuario desea utilizar. Haga coincidir el nombre del archivo JSON del nuevo usuario, sin la extensión .json .
NOTA : Puede ignorar esto si desea utilizar el argumento --User cuando ejecute Wilmer.
Cree un archivo JSON de enrutamiento en la carpeta Routing . Este archivo puede tener el nombre que desee. Actualice la propiedad routingConfig en su archivo JSON de usuario con este nombre, menos la extensión .json . A continuación se muestra un ejemplo de un archivo de configuración de enrutamiento:
{
"CODING" : {
"description" : " Any request which requires a code snippet as a response " ,
"workflow" : " CodingWorkflow "
},
"FACTUAL" : {
"description" : " Requests that require factual information or data " ,
"workflow" : " ConversationalWorkflow "
},
"CONVERSATIONAL" : {
"description" : " Casual conversation or non-specific inquiries " ,
"workflow" : " FactualWorkflow "
}
}.json , que se activa si se elige la categoría. En la carpeta Workflow , cree una nueva carpeta que coincida con el nombre de usuario de la carpeta Users . La forma más rápida de hacerlo es copiar la carpeta de un usuario existente, duplicarla y cambiarle el nombre.
Si decide no realizar otros cambios, deberá revisar los flujos de trabajo y actualizar los puntos finales para que apunten al punto final que desee. Si está utilizando un flujo de trabajo de ejemplo agregado con Wilmer, entonces ya debería estar bien aquí.
Dentro de la carpeta "Pública" deberías tener:
Los flujos de trabajo en este proyecto se modifican y controlan en la carpeta Public/Workflows , dentro de la carpeta de flujos de trabajo específicos de su usuario. Por ejemplo, si su usuario se llama socg y tiene un archivo socg.json en la carpeta Users , dentro de los flujos de trabajo debería tener una carpeta Workflows/socg .
A continuación se muestra un ejemplo de cómo podría verse un JSON de flujo de trabajo:
[
{
"title" : " Coding Agent " ,
"agentName" : " Coder Agent One " ,
"systemPrompt" : " You are an exceptionally powerful and intelligent technical AI that is currently in a role play with a user in an online chat. n The instructions for the roleplay can be found below: n [ n {chat_system_prompt} n ] n Please continue the conversation below. Please be a good team player. This means working together towards a common goal, and does not always include being overly polite or agreeable. Disagreement when the other user is wrong can help foster growth in everyone, so please always speak your mind and critically review your peers. Failure to correct someone who is wrong could result in the team's work being a failure. " ,
"prompt" : " " ,
"lastMessagesToSendInsteadOfPrompt" : 6 ,
"endpointName" : " SocgMacStudioPort5002 " ,
"preset" : " Coding " ,
"maxResponseSizeInTokens" : 500 ,
"addUserTurnTemplate" : false
},
{
"title" : " Reviewing Agent " ,
"agentName" : " Code Review Agent Two " ,
"systemPrompt" : " You are an exceptionally powerful and intelligent technical AI that is currently in a role play with a user in an online chat. " ,
"prompt" : " You are in an online conversation with a user. The last five messages can be found here: n [ n {chat_user_prompt_last_five} n ] n You have already considered this request quietly to yourself within your own inner thoughts, and come up with a possible answer. The answer can be found here: n [ n {agent1Output} n ] n Please critically review the response, reconsidering your initial choices, and ensure that it is accurate, complete, and fulfills all requirements of the user's request. nn Once you have finished reconsidering your answer, please respond to the user with the correct and complete answer. nn IMPORTANT: Do not mention your inner thoughts or make any mention of reviewing a solution. The user cannot see the answer above, and any mention of it would confuse the user. Respond to the user with a complete answer as if it were the first time you were answering it. " ,
"endpointName" : " SocgMacStudioPort5002 " ,
"preset" : " Coding " ,
"maxResponseSizeInTokens" : 1000 ,
"addUserTurnTemplate" : true
}
]El flujo de trabajo anterior se compone de nodos de conversación. Ambos nodos hacen una cosa simple: enviar un mensaje al LLM especificado en el punto final.
title . Es útil nombrarlos que terminan en "Uno", "Dos", etc., para realizar un seguimiento de la salida del agente. La salida del primer nodo se guarda en {agent1Output} , la segunda en {agent2Output} , y así sucesivamente.Endpoints , sin la extensión .json .Presets , sin la extensión .json .false (consulte el primer nodo de ejemplo arriba). Si envía un mensaje, configúrelo como true (consulte el segundo nodo de ejemplo arriba). NOTE: The addDiscussionIdTimestampsForLLM feature was an experiment, and truthfully I am not happy with how the experiment went. Even the largest LLMs misread the timestamps, got confused by them, etc. I have other plans for this feature which should be far more useful, but I left it in and won't be removing it, even though I don't necessarily recommend using it. -Socg
Puede usar varias variables dentro de estas indicaciones. Estos serán reemplazados adecuadamente en tiempo de ejecución:
{chat_user_prompt_last_one} : el último mensaje en la conversación, sin etiquetas de plantilla de inmediato envolviendo el mensaje.{templated_user_prompt_last_one} : el último mensaje en la conversación, envuelto en las etiquetas de plantilla de solicitud de usuario/asistente apropiadas.{chat_system_prompt} : el mensaje del sistema enviado desde el extremo frontal. A menudo contiene una tarjeta de caracteres y otra información importante.{templated_system_prompt} : la solicitud del sistema desde el extremo frontal, envuelta en la etiqueta de plantilla de solicitud del sistema apropiada.{agent#Output} : # se reemplaza con el número que desea. Cada nodo genera una salida de agente. El primer nodo es siempre 1, y cada nodo posterior se incrementa en 1. Por ejemplo, {agent1Output} para el primer nodo, {agent2Output} para el segundo, etc.{category_colon_descriptions} : extrae las categorías y descripciones de su archivo JSON Routing .{categoriesSeparatedByOr} : extrae los nombres de categoría, separados por "o".[TextChunk] : una variable especial exclusiva del procesador paralelo, que probablemente no se usa con frecuencia.Nota: Para una comprensión más profunda de cómo funcionan los recuerdos, consulte la sección de Memorias de comprensión
Este nodo extraerá el número N de recuerdos (o mensajes más recientes si no hay discusión presente) y agregará un delimitador personalizado entre ellos. Entonces, si tiene un archivo de memoria con 3 recuerdos y elige un delimitador de " n ---------- n", entonces podría obtener lo siguiente:
This is the first memory
---------
This is the second memory
---------
This is the third memory
La combinación de este nodo con el resumen del chat puede permitir que la LLM reciba no solo el desglose resumido de toda la conversación en su conjunto, sino también una lista de todos los recuerdos que se construyó el resumen, que puede contener información más detallada y granular sobre él. Enviar ambos juntos, junto con los últimos 15-20 mensajes, puede crear la impresión de un recuerdo continuo y persistente de todo el chat hasta los mensajes más recientes. El cuidado especial para elaborar buenas indicaciones para la generación de los recuerdos puede ayudar a garantizar que se capturen los detalles que le importan, mientras que se ignoran los detalles menos pertinentes.
Este nodo no generará nuevos recuerdos; Esto es para que los bloqueos de flujo de trabajo puedan respetarse si los está utilizando en una configuración de múltiples computadoras. Actualmente, la mejor manera de generar recuerdos es el nodo FullChatsummary.


