Ainur
1.0.0
Ainur es un modelo innovador de aprendizaje profundo para la generación de música multimodal condicional. Está diseñado para generar muestras de música estéreo de alta calidad a 48 kHz condicionadas a una variedad de entradas, como letras, descriptores de texto y otro tipo de audio. La arquitectura de difusión jerárquica de Ainur, combinada con las incrustaciones CLASP, le permite producir composiciones musicales coherentes y expresivas en una amplia gama de géneros y estilos. 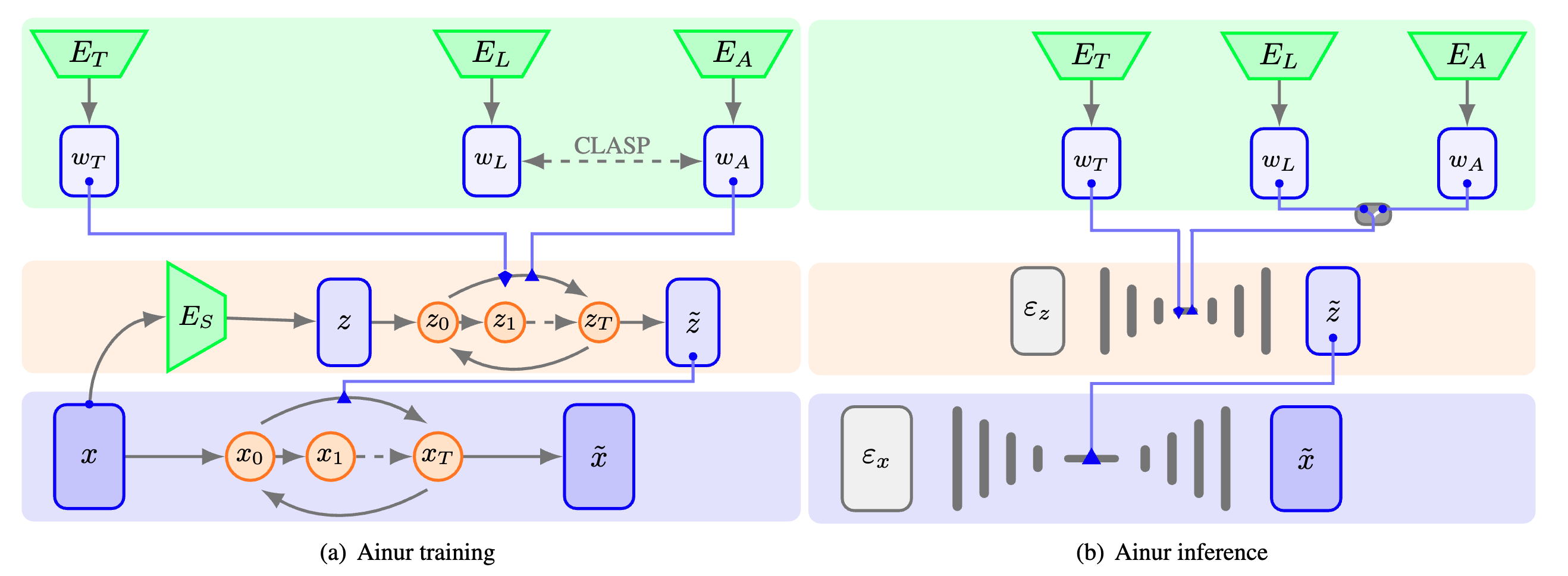

Generación condicional: Ainur permite la generación de música condicionada a letras, descriptores de texto u otro audio, ofreciendo un enfoque flexible y creativo para la composición musical.
Salida de alta calidad: el modelo es capaz de producir muestras de música estéreo de 22 segundos a 48 kHz, lo que garantiza alta fidelidad y realismo.
Aprendizaje multimodal: Ainur emplea incrustaciones CLASP, que son representaciones multimodales de letras y audio, para facilitar la alineación de las letras textuales con los fragmentos de audio correspondientes.
Evaluación objetiva: proporcionamos métricas de evaluación integrales, que incluyen la distancia de audio Frechet (FAD) y la consistencia del ciclo CLASP (C3), para evaluar la calidad y coherencia de la música generada.
Para ejecutar Ainur, asegúrese de tener instaladas las siguientes dependencias:
Pitón 3.8+
PyTorch 1.13.1
PyTorch Rayo 2.0.0
Puede instalar los paquetes de Python necesarios ejecutando:
instalación de pip -r requisitos.txt
Clona este repositorio:
clon de git https://github.com/ainur-music/ainur.gitcd ainur
Instale las dependencias (como se mencionó anteriormente).
Ejecute Ainur con la entrada que desee. Consulte los cuadernos de ejemplo en la carpeta de examples para obtener orientación sobre el uso de Ainur para la generación de música. ( muy pronto )
Ainur guía la generación de música y mejora la calidad de las voces a través de información textual y letras sincronizadas. Aquí te dejamos un ejemplo de insumos para entrenar y generar música con Ainur:
«Red Hot Chili Peppers, Alternative Rock, 7 of 19»
«[00:45.18] I got your hey oh, now listen what I say oh [...]»
Comparamos el desempeño de Ainur con otro modelo de última generación para la generación de texto a música. Basamos la evaluación en métricas objetivas como FAD y utilizamos diferentes modelos de integración como referencia: VGGish, YAMNet y Trill.
| Modelo | Velocidad [kHz] | Longitud [s] | Parámetros [M] | Pasos de inferencia | Tiempo de inferencia [s] ↓ | FAD VGGish ↓ | FAD YAMNet ↓ | Trino FAD ↓ |
|---|---|---|---|---|---|---|---|---|
| ainur | 48@2 | 22 | 910 | 50 | 14.5 | 8.38 | 20,70 | 0,66 |
| Ainur (sin CLASP) | 48@2 | 22 | 910 | 50 | 14.7 | 8.40 | 20,86 | 0,64 |
| AudioLDM | 16@1 | 22 | 181 | 200 | 2.20 | 15.5 | 784.2 | 0,52 |
| AudioLDM 2 | 16@1 | 22 | 1100 | 100 | 20.8 | 8.67 | 23,92 | 0,52 |
| MúsicaGen | 16@1 | 22 | 300 | 1500 | 81.3 | 14.4 | 53.04 | 0,66 |
| Tocadiscos tragamonedas | 16@1 | 1 | 1000 | - | 538 | 20.4 | 178.1 | 1,59 |
| MúsicaLM | 16@1 | 5 | 1890 | 125 | 153 | 15.0 | 61,58 | 0,47 |
| Rifusión | 44.1@1 | 5 | 890 | 50 | 6.90 | 5.24 | 15,96 | 0,67 |
Explora y escucha música generada por Ainur aquí.
Puede descargar puntos de control Ainur y CLASP previamente entrenados desde Drive:
Mejor punto de control de Ainur (modelo con menor pérdida durante el entrenamiento)
Último punto de control de Ainur (modelo con mayor número de pasos de entrenamiento)
Punto de control de CLASP
Este proyecto tiene la licencia MIT; consulte el archivo de LICENCIA para obtener más detalles.
© 2023 Giuseppe Concialdi


