synthetic data generator
0.2.3
Cambiar idioma: 简体中文 | Últimos documentos API | Hoja de ruta | Únase al grupo Wechat
Ejemplos de colaboración: LLM: Síntesis de datos | LLM: Inferencia fuera de mesa | CTGAN compatible con datos de nivel de mil millones
El Generador de datos sintéticos (SDG) es un marco especializado diseñado para generar datos tabulares estructurados de alta calidad.
Los datos sintéticos no contienen información confidencial, pero conservan las características esenciales de los datos originales, lo que los exime de regulaciones de privacidad como GDPR y ADPPA.
Los datos sintéticos de alta calidad se pueden utilizar de forma segura en varios dominios, incluido el intercambio de datos, el entrenamiento y la depuración de modelos, el desarrollo y las pruebas de sistemas, etc.
Estamos emocionados de tenerlo aquí y esperamos sus contribuciones. ¡Comience con el proyecto a través de esta Guía general de contribuciones!
Nuestros principales logros y cronogramas actuales son los siguientes:
21 de noviembre de 2024: 1) Integración del modelo: hemos integrado el modelo GaussianCopula en nuestro sistema de procesamiento de datos. Consulte el ejemplo de código en este PR; 2) Calidad sintética: implementamos la detección automática de relaciones entre columnas de datos y permitimos la especificación de relaciones, mejoramos la calidad de los datos sintéticos (ejemplo de código); 3) Mejora del rendimiento: redujimos significativamente el uso de memoria de GaussianCopula al manejar datos discretos, lo que permitió entrenar en miles de entradas de datos categóricos con una configuración 2C4G .
30 de mayo de 2024: Se fusionó oficialmente el módulo Procesador de datos. Este módulo: 1) ayudará a SDG a convertir el formato de algunas columnas de datos (como las columnas de fecha y hora) antes de introducirlas en el modelo (para evitar ser tratados como tipos discretos) y a convertir de forma inversa los datos generados por el modelo al formato original. ; 2) realizar un preprocesamiento y posprocesamiento más personalizado en varios tipos de datos; 3) resolver fácilmente problemas como valores nulos en los datos originales; 4) admite el sistema enchufable.
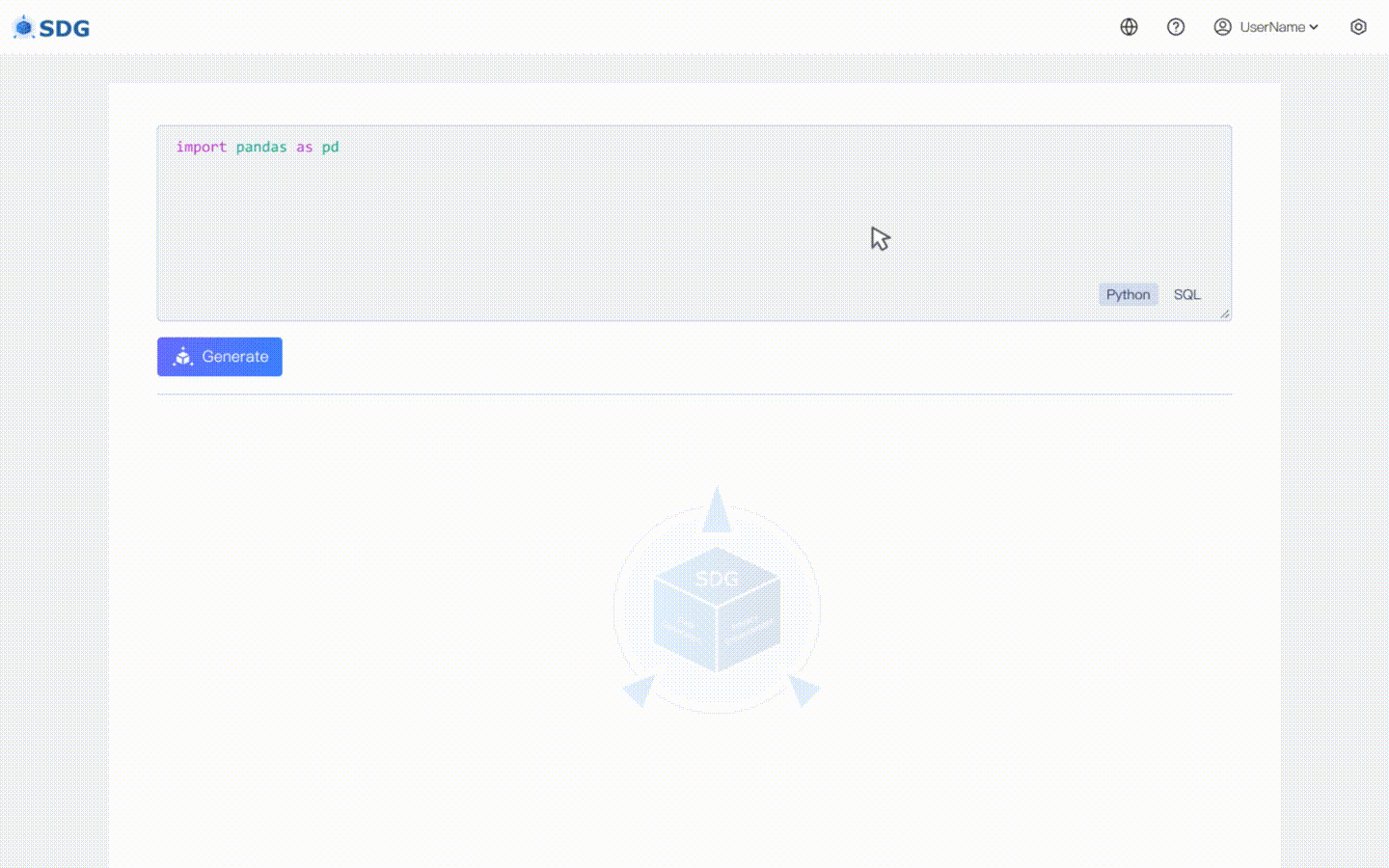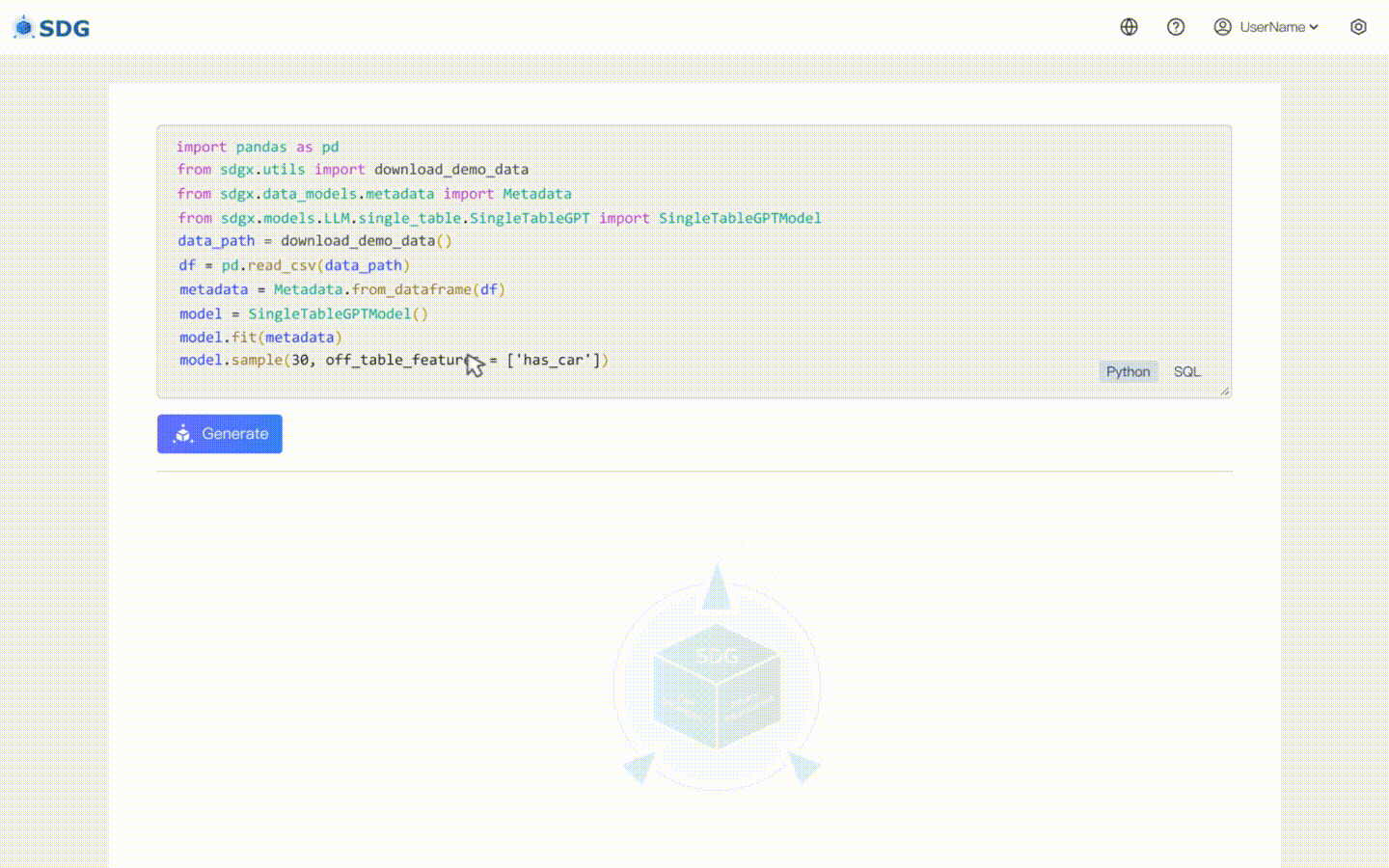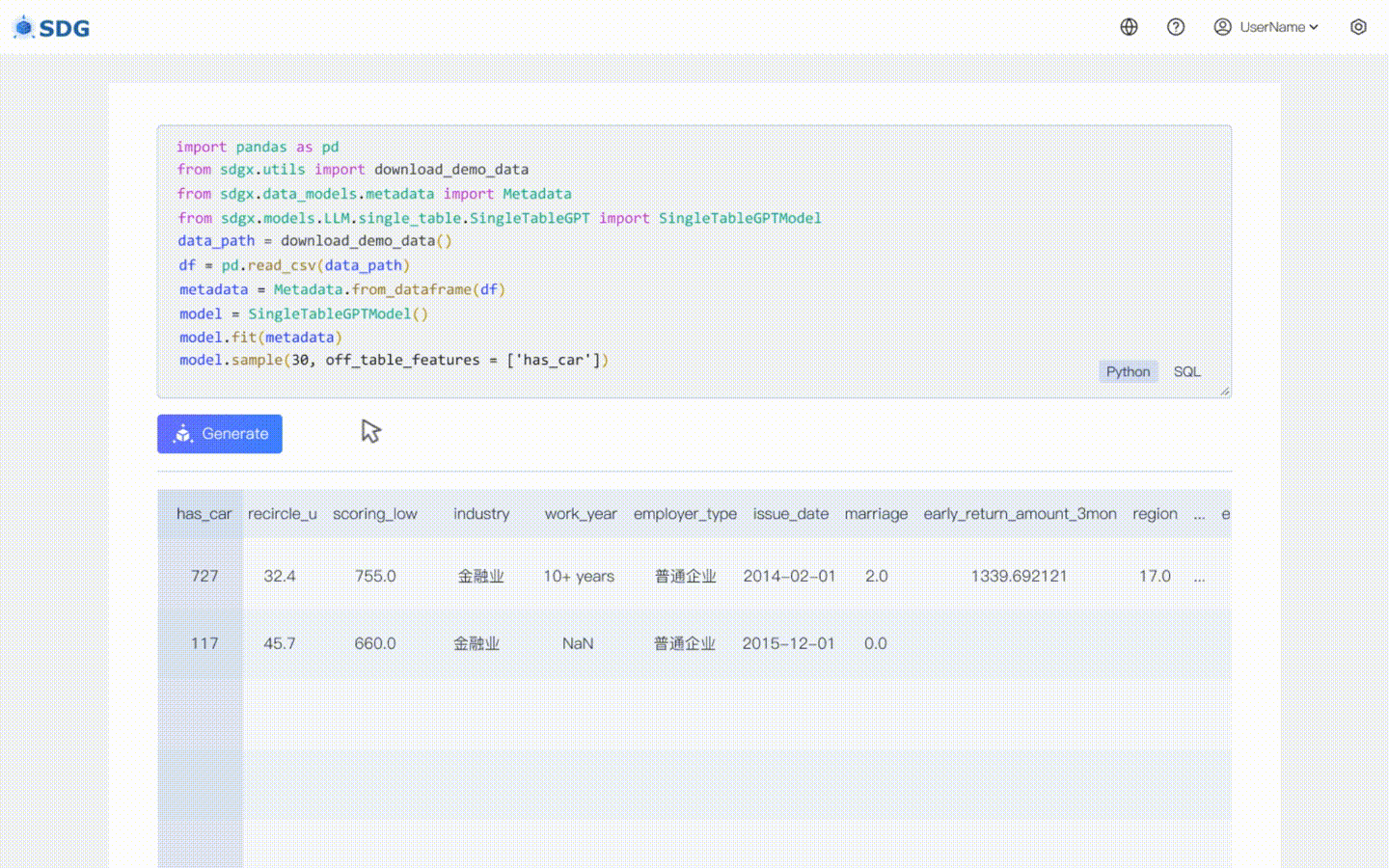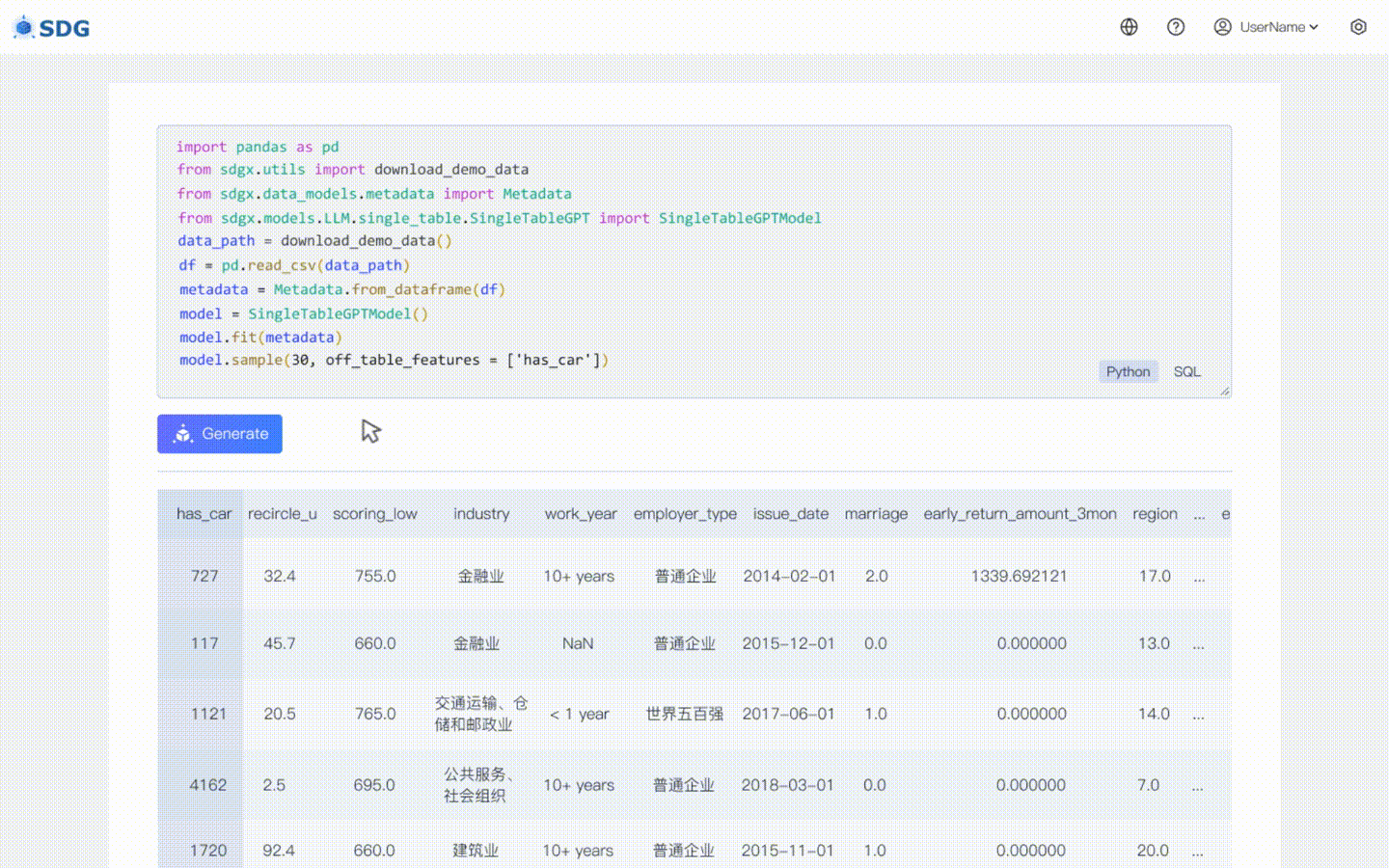
20 de febrero de 2024: se incluye un modelo de síntesis de datos de una sola tabla basado en LLM; vea el ejemplo de colaboración: LLM: Síntesis de datos y LLM: Inferencia de características fuera de la tabla.
7 de febrero de 2024: Mejoramos sdgx.data_models.metadata para admitir la descripción de información de metadatos para tablas individuales y tablas múltiples, admitir múltiples tipos de datos y admitir la inferencia automática de tipos de datos. ver ejemplo de colab: Metadatos de tabla única de los ODS。
20 de diciembre de 2023: lanzamiento de v0.1.0, se incluye un modelo CTGAN que admite miles de millones de capacidades de procesamiento de datos; vea nuestro punto de referencia frente a SDV, donde SDG logró un menor consumo de memoria y evitó fallas durante el entrenamiento. Para un uso específico, vea el ejemplo de colaboración: CTGAN compatible con mil millones de datos de nivel.
10 de agosto de 2023: Primera línea del código ODS confirmada.
Durante mucho tiempo, LLM se ha utilizado para comprender y generar diversos tipos de datos. De hecho, LLM también tiene ciertas capacidades en la generación de datos tabulares. Además, tiene algunas capacidades que no se pueden lograr con los métodos tradicionales (basados en métodos GAN o métodos estadísticos).
Nuestro sdgx.models.LLM.single_table.gpt.SingleTableGPTModel implementa dos características nuevas:
No se requieren datos de entrenamiento, se pueden generar datos sintéticos basados en datos de metadatos, vea nuestro ejemplo de colaboración.
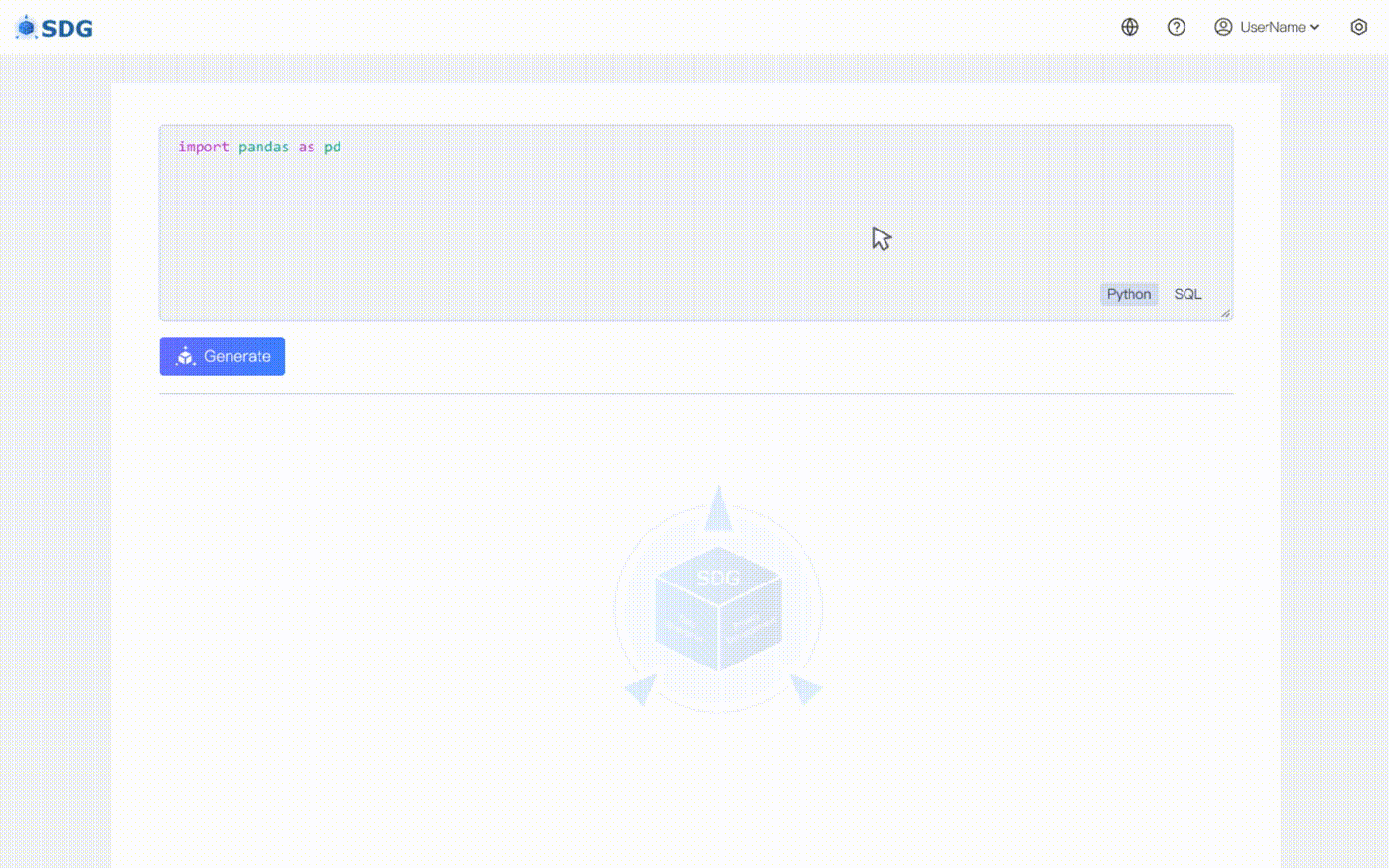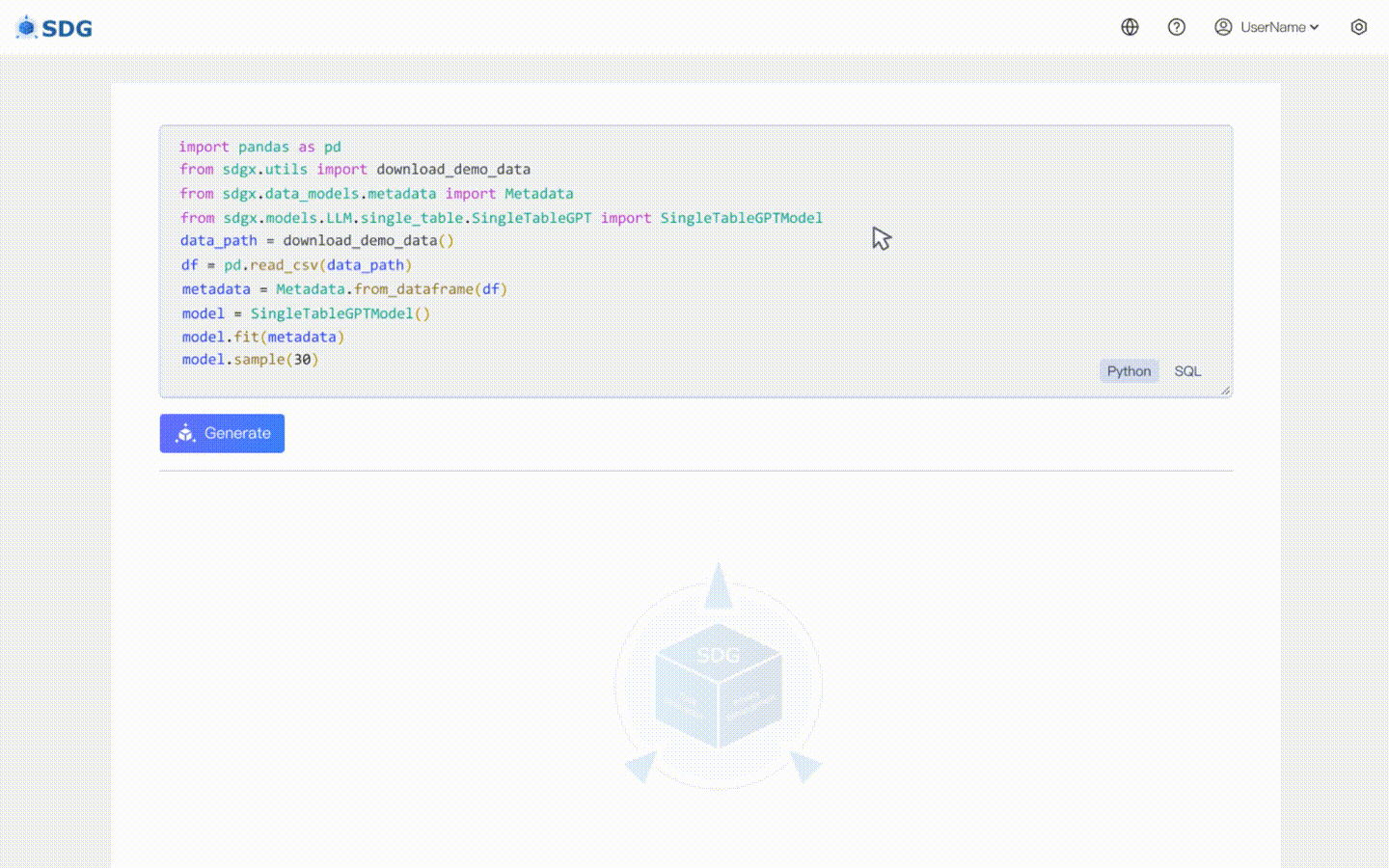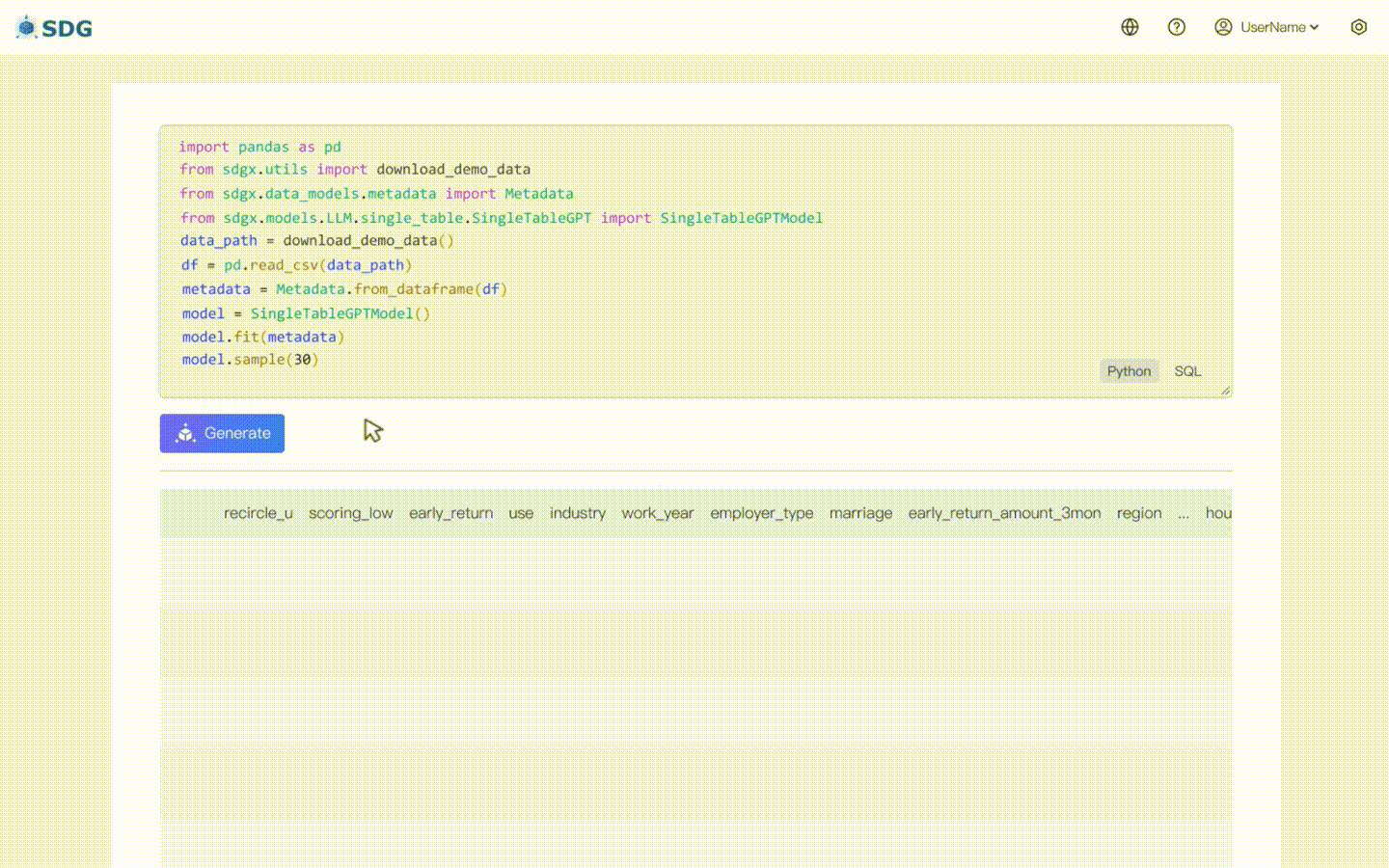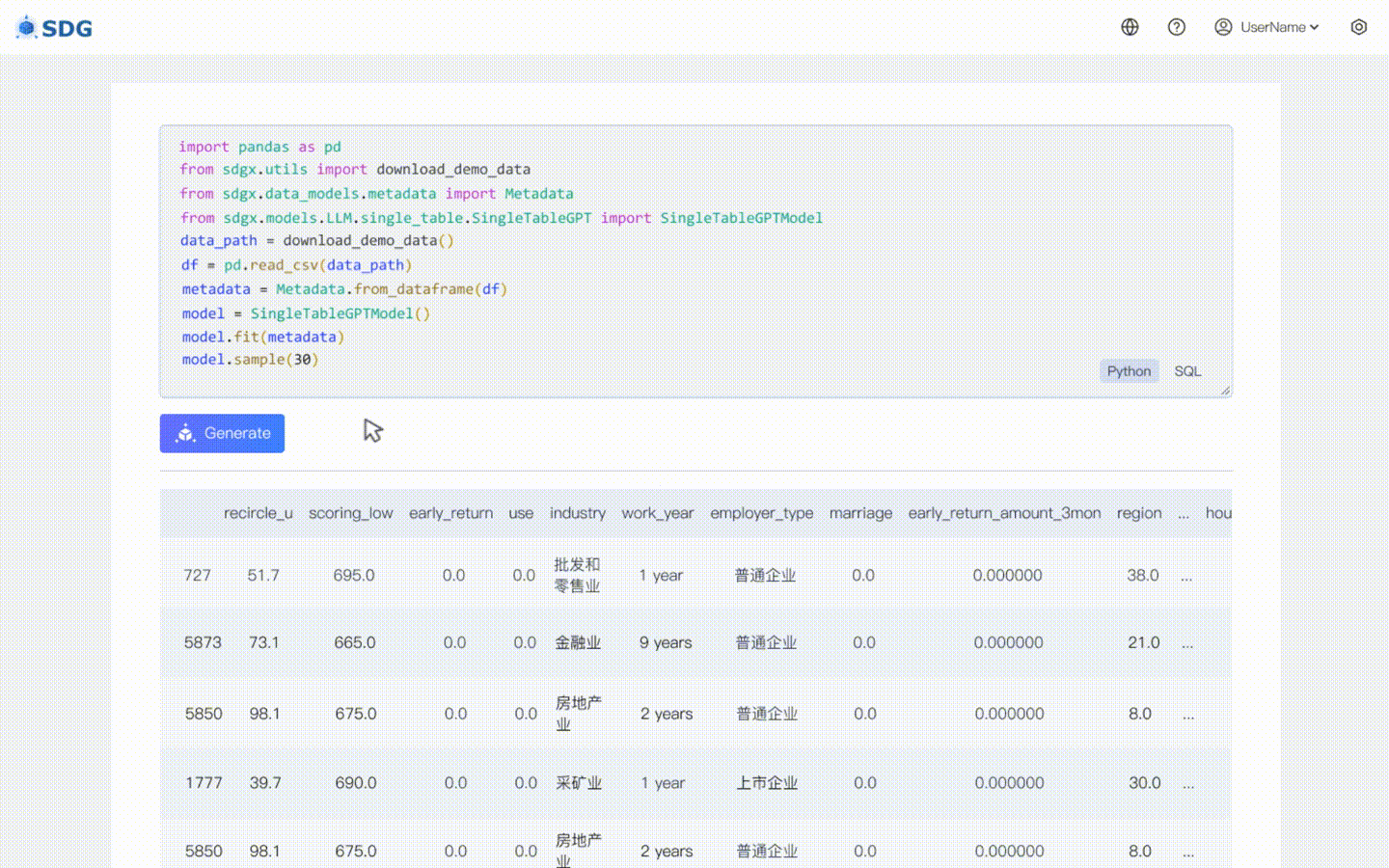
Infiera datos de nuevas columnas en función de los datos existentes en la tabla y el conocimiento dominado por LLM, vea nuestro ejemplo de colaboración.
Avances tecnológicos:
Admite una amplia gama de algoritmos de síntesis de datos estadísticos y también está integrado el modelo de generación de datos sintéticos basado en LLM;
Optimizado para big data, reduciendo efectivamente el consumo de memoria;
Seguimiento continuo de los últimos avances en el mundo académico y la industria, e introducción de soporte para algoritmos y modelos excelentes de manera oportuna.
Mejoras de privacidad:
SDG apoya la privacidad diferencial, la anonimización y otros métodos para mejorar la seguridad de los datos sintéticos.
Fácil de ampliar:
Admite la expansión de modelos, procesamiento de datos, conectores de datos, etc. en forma de paquetes de complementos.
Puede utilizar imágenes prediseñadas para experimentar rápidamente las funciones más recientes.
Docker extrae idsteam/sdgx: último
instalación de pip sdgx
Utilice SDG instalándolo a través del código fuente.
git clone [email protected]:hitsz-ids/synthetic-data-generator.git pip install .# O instalar desde gitpip install git+https://github.com/hitsz-ids/synthetic-data-generator.git
desde sdgx.data_connectors.csv_connector import CsvConnectorfrom sdgx.models.ml.single_table.ctgan import CTGANSynthesizerModelfrom sdgx.synthesizer import Synthesizerfrom sdgx.utils import download_demo_data# Esto descargará datos de demostración a ./datasetdataset_csv = download_demo_data()# Crear conector de datos para csv filedata_connector = CsvConnector(path=dataset_csv)# Inicialice el sintetizador, use CTGAN modelsynthesizer = Synthesizer(model=CTGANSynthesizerModel(epochs=1), # Para demodata_connector=data_connector rápido, )# Ajustar los modelosynthesizer.fit()# Samplesampled_data = synthesizer.sample(1000)print(sampled_data)
Los datos reales son los siguientes:
>>> data_connector.read() edad clase laboral fnlwgt educación ... pérdida de capital horas por semana clase del país natal0 2 State-gov 77516 Solteros ... 0 2 Estados Unidos <=50K1 3 Self-emp-not-inc 83311 Solteros .. 0 0 Estados Unidos <=50K2 2 Privado 215646 Graduado de secundaria ... 0 2 Estados Unidos. <=50K3 3 Privado 234721 11º... 0 2 Estados Unidos <=50K4 1 Privado 338409 Licenciatura... 0 2 Cuba <=50K... ... ... ... ... ... . .. ... ... ...48837 2 Privado 215419 Licenciatura ... 0 2 Estados Unidos <=50K48838 4 NaN 321403 Graduado de secundaria ... 0 2 Estados Unidos <=50K48839 2 Privado 374983 Licenciaturas ... 0 3 Estados Unidos <=50K48840 2 Privado 83891 Licenciaturas ... 0 2 Estados Unidos <=50K48841 1 Autoempleado 182148 Licenciaturas . .. 0 3 Estados Unidos >50K[48842 filas x 15 columnas]
Los datos sintéticos son los siguientes:
>>> sampled_data edad clase laboral fnlwgt educación ... pérdida de capital horas por semana clase de país natal0 1 NaN 28219 Alguna universidad ... 0 2 Puerto Rico <=50K1 2 Privado 250166 Graduado de secundaria ... 0 2 Estados Unidos >50K2 2 Privado 50304 HS-grad... 0 2 Estados Unidos <=50K3 4 Privado 89318 Licenciatura... 0 2 Puerto-Rico >50K4 1 Privada 172149 Licenciatura... 0 3 Estados Unidos <=50K.. ... ... ... ... ... ... ... ... ...995 2 NaN 208938 Licenciaturas ... 0 1 Estados Unidos <=50K996 2 Privada 166416 Licenciaturas ... 2 2 Estados Unidos <=50K997 2 NaN 336022 Graduado HS ... 0 1 Estados Unidos <=50K998 3 Privado 198051 Maestría ... 0 2 Estados Unidos >50K999 1 NaN 41973 Graduado HS ... 0 2 Estados Unidos <= 50K[1000 filas x 15 columnas]
CTGAN: Modelado de datos tabulares utilizando GAN condicional
C3-TGAN: C3-TGAN: síntesis de datos tabulares controlables con correlaciones explícitas y restricciones de propiedad
TVAE: modelado de datos tabulares utilizando GAN condicional
table-GAN: Síntesis de datos basada en redes generativas adversas
CTAB-GAN:CTAB-GAN: síntesis eficaz de datos de tablas
OCT-GAN: OCT-GAN: GAN tabulares condicionales basadas en ODE neuronales
El proyecto ODS fue iniciado por el Instituto de Seguridad de Datos del Instituto de Tecnología de Harbin . Si está interesado en nuestro proyecto, bienvenido a unirse a nuestra comunidad. Damos la bienvenida a organizaciones, equipos e individuos que comparten nuestro compromiso con la protección y seguridad de datos a través del código abierto:
Lea CONTRIBUCIÓN antes de redactar una solicitud de extracción.
Envíe un problema viendo Ver buen primer problema o envíe una solicitud de extracción.
Únase a nuestro grupo Wechat a través del código QR.


