EasyDetect
1.0.0

Un marco de detección de alucinaciones multimodal fácil de usar para MLLM
Reconocimiento • Punto de referencia • Demostración • Descripción general • ModelZoo • Instalación • Inicio rápido • Cita
Reconocimiento
Descripción general
Alucinación multimodal unificada
Conjunto de datos: estadística MHalluBench
Marco: Ilustración UniHD
modelozoo
Instalación
⏩Inicio rápido
Citación
2024-05-17 El artículo Detección unificada de alucinaciones para modelos multimodales de lenguaje grande es aceptado en la conferencia principal de ACL 2024.
2024-04-21 Reemplazamos todos los modelos base en la demostración con nuestros propios modelos entrenados, reduciendo significativamente el tiempo de inferencia.
2024-04-21 Lanzamos nuestro modelo de detección de alucinaciones de código abierto HalDet-LLAVA, que se puede descargar en huggingface, modelscope y Wisemodel.
2024-02-10 Lanzamos la demo de EasyDetect .
2024-02-05 Publicamos el artículo: "Detección unificada de alucinaciones para modelos multimodales de lenguaje grande" con un nuevo punto de referencia MHaluBench. Esperamos cualquier comentario o discusión sobre este tema :)
2023-10-20 El proyecto EasyDetect ha sido lanzado y está en desarrollo.
Parte de la implementación de este proyecto contó con la ayuda e inspiración de los kits de herramientas de alucinaciones relacionados, incluidos FactTool, Woodpecker y otros. Este repositorio también se beneficia del proyecto público de mPLUG-Owl, MiniGPT-4, LLaVA, GroundingDINO y MAERec. Seguimos la misma licencia para el código abierto y les agradecemos sus contribuciones a la comunidad.
EasyDetect es un paquete sistemático que se propone como un marco de detección de alucinaciones fácil de usar para modelos de lenguaje grande multimodal (MLLM) como GPT-4V, Gemini, LlaVA en sus experimentos de investigación.
Un requisito previo para la detección unificada es la categorización coherente de las principales categorías de alucinaciones dentro de los MLLM. Nuestro artículo examina superficialmente la siguiente taxonomía de alucinaciones desde una perspectiva unificada:


Figura 1: La detección de alucinaciones multimodal unificada tiene como objetivo identificar y detectar alucinaciones que entran en conflicto con modalidades en varios niveles, como objeto, atributo y escena-texto, así como alucinaciones que entran en conflicto con hechos tanto en imagen a texto como en texto a imagen. generación.
Alucinación de modalidad conflictiva. Los MLLM a veces generan resultados que entran en conflicto con las entradas de otras modalidades, lo que genera problemas como objetos, atributos o texto de escena incorrectos. Un ejemplo en la Figura (a) anterior incluye un MLLM que describe de manera inexacta el uniforme de un atleta, lo que muestra un conflicto a nivel de atributo debido a la capacidad limitada de los MLLM para lograr una alineación detallada de texto e imagen.
Alucinación que contradice hechos. Los resultados de los MLLM pueden contradecir el conocimiento fáctico establecido. Los modelos de imagen a texto pueden generar narrativas que se desvían del contenido real al incorporar hechos irrelevantes, mientras que los modelos de texto a imagen pueden producir imágenes que no reflejan el conocimiento fáctico contenido en las indicaciones del texto. Estas discrepancias subrayan la lucha de los MLLM por mantener la coherencia fáctica, lo que representa un desafío importante en el ámbito.
La detección unificada de alucinaciones multimodales requiere la verificación de cada par imagen-texto a={v, x} , donde v denota la entrada visual proporcionada a un MLLM o la salida visual sintetizada por este. En consecuencia, x significa la respuesta textual generada por MLLM basada en v o la consulta textual del usuario para sintetizar v . Dentro de esta tarea, cada x puede contener múltiples reclamos, denotados como a para determinar si es "alucinatoria" o "no alucinatoria", proporcionando una justificación de sus juicios basados en la definición de alucinación proporcionada. La detección de alucinaciones de texto en LLM denota un subcaso en esta configuración, donde v es nulo.
Para avanzar en esta trayectoria de investigación, presentamos el punto de referencia de metaevaluación MHaluBench, que abarca el contenido de la generación de imagen a texto y de texto a imagen, con el objetivo de evaluar rigurosamente los avances en los detectores de alucinaciones multimodales. En las siguientes figuras se proporcionan más detalles estadísticos sobre MHaluBench.
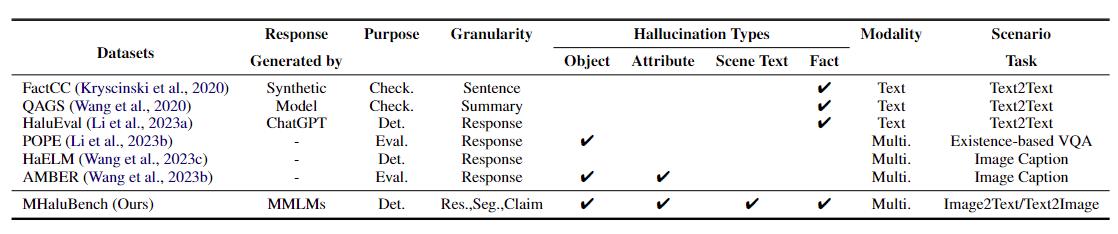
Tabla 1: Comparación de puntos de referencia con respecto a la verificación de hechos o la evaluación de alucinaciones existentes. "Controlar." indica verificar la coherencia fáctica, "Eval". denota evaluar alucinaciones generadas por diferentes LLM, y su respuesta se basa en diferentes LLM bajo prueba, mientras que "Det." encarna la evaluación de la capacidad de un detector para identificar alucinaciones.
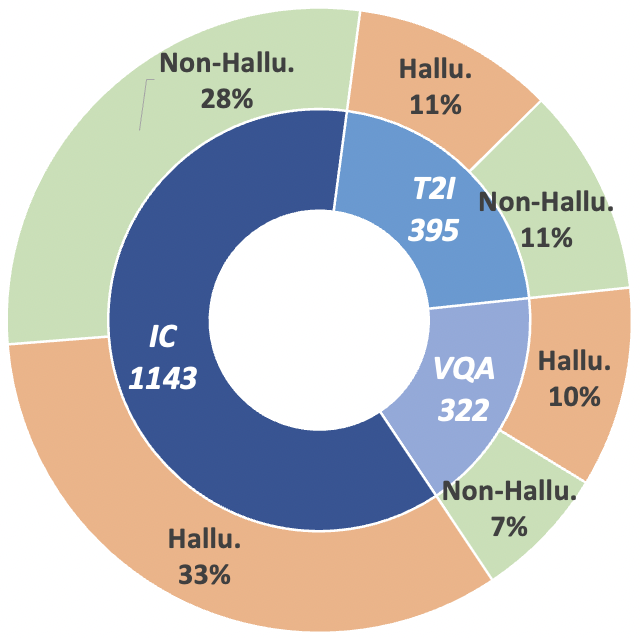
Figura 2: Estadísticas de datos a nivel de reclamo de MHaluBench. "IC" significa subtítulos de imágenes y "T2I" indica síntesis de texto a imagen, respectivamente.
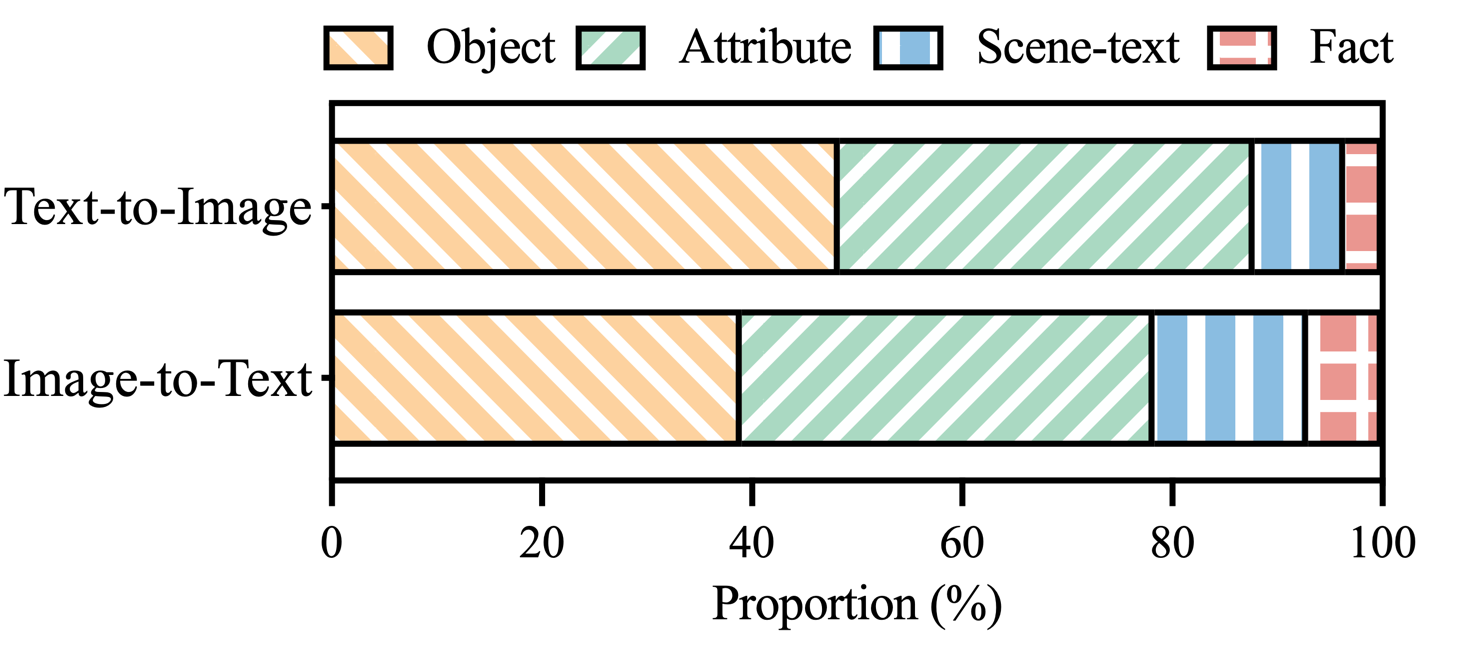
Figura 3: Distribución de categorías de alucinaciones dentro de las afirmaciones etiquetadas como alucinaciones de MHaluBench.
Para abordar los desafíos clave en la detección de alucinaciones, presentamos un marco unificado en la Figura 4 que aborda sistemáticamente la identificación de alucinaciones multimodal para tareas de imagen a texto y de texto a imagen. Nuestro marco aprovecha las fortalezas específicas de dominio de varias herramientas para recopilar de manera eficiente evidencia multimodal para confirmar alucinaciones.
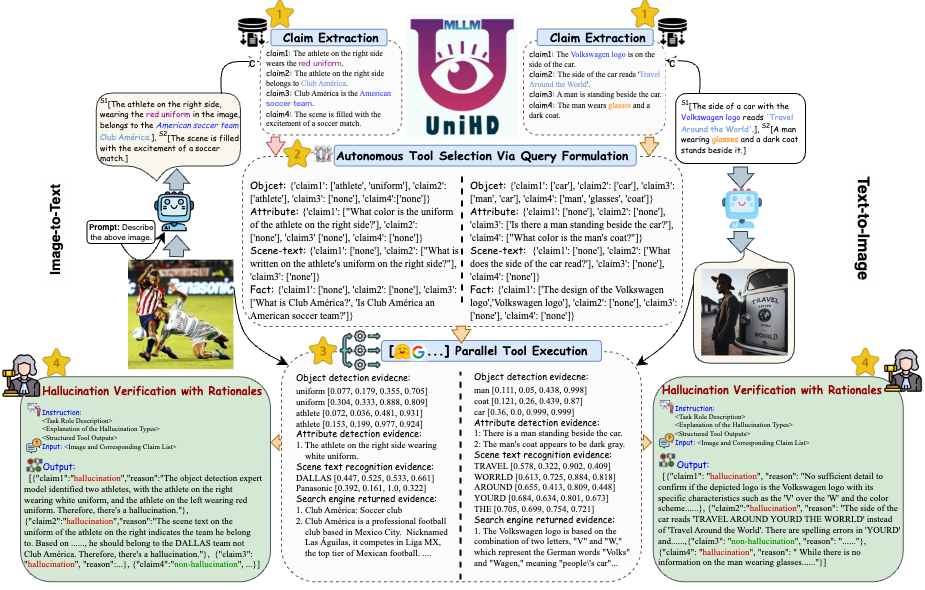
Figura 4: Ilustración específica de UniHD para la detección de alucinaciones multimodal unificada.
Puede descargar dos versiones de HalDet-LLaVA, 7b y 13b, en tres plataformas: HuggingFace, ModelScope y WiseModel.
| AbrazosCara | ModeloScope | Modelo sabio |
|---|---|---|
| HalDet-llava-7b | HalDet-llava-7b | HalDet-llava-7b |
| HalDet-llava-13b | HalDet-llava-13b | HalDet-llava-13b |
Los resultados del nivel de reclamación en el conjunto de datos de validación
Autocomprobación (GPT-4V) significa usar GPT-4V con 0 o 2 casos
UniHD (GPT-4V/GPT-4o) significa usar GPT-4V/GPT-4o con información de 2 disparos y herramientas
HalDet (LLAVA) significa usar LLAVA-v1.5 entrenado en nuestros conjuntos de datos de trenes
| tipo de tarea | modelo | Acc | promedio prec. | Recuperar promedio | Mac.F1 |
| imagen a texto | Autocomprobación 0disparo (GPV-4V) | 75.09 | 74,94 | 75,19 | 74,97 |
| Autocomprobación 2 disparos (GPV-4V) | 79,25 | 79.02 | 79,16 | 79.08 | |
| HalDet (LLAVA-7b) | 75.02 | 75.05 | 74,18 | 74,38 | |
| HalDet (LLAVA-13b) | 78,16 | 78,18 | 77,48 | 77,69 | |
| UniHD(GPT-4V) | 81,91 | 81,81 | 81,52 | 81,63 | |
| UniHD(GPT-4o) | 86.08 | 85,89 | 86.07 | 85,96 | |
| texto a imagen | Autocomprobación 0disparo (GPV-4V) | 76,20 | 79,31 | 75,99 | 75,45 |
| Autocomprobación 2 disparos (GPV-4V) | 80,76 | 81.16 | 80,69 | 80,67 | |
| HalDet (LLAVA-7b) | 67,35 | 69,31 | 67,50 | 66,62 | |
| HalDet (LLAVA-13b) | 74,74 | 76,68 | 74,88 | 74,34 | |
| UniHD(GPT-4V) | 85,82 | 85,83 | 85,83 | 85,82 | |
| UniHD(GPT-4o) | 89,29 | 89,28 | 89,28 | 89,28 |
Para ver información más detallada sobre HalDet-LLaVA y el conjunto de datos del tren, consulte el archivo Léame.
Instalación para el desarrollo local:
git clone https://github.com/zjunlp/EasyDetect.git cd EasyDetect pip install -r requirements.txt
Instalación de herramientas (GroundingDINO y MAERec):
# install GroundingDINO git clone https://github.com/IDEA-Research/GroundingDINO.git cp -r GroundingDINO pipeline/GroundingDINO cd pipeline/GroundingDINO/ pip install -e . cd .. # install MAERec git clone https://github.com/Mountchicken/Union14M.git cp -r Union14M/mmocr-dev-1.x pipeline/mmocr cd pipeline/mmocr/ pip install -U openmim mim install mmengine mim install mmcv mim install mmdet pip install timm pip install -r requirements/albu.txt pip install -r requirements.txt pip install -v -e . cd .. mkdir weights cd weights wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth wget https://download.openmmlab.com/mmocr/textdet/dbnetpp/dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015/dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015_20221101_124139-4ecb39ac.pth -O dbnetpp.pth wget https://github.com/Mountchicken/Union14M/releases/download/Checkpoint/maerec_b_union14m.pth -O maerec_b.pth cd ..
Proporcionamos código de ejemplo para que los usuarios comiencen rápidamente con EasyDetect.
Los usuarios pueden configurar fácilmente los parámetros de EasyDetect en un archivo yaml o simplemente usar rápidamente los parámetros predeterminados en el archivo de configuración que proporcionamos. La ruta del archivo de configuración es EasyDetect/pipeline/config/config.yaml
openai: api_key: Ingrese su clave de API de Openai
base_url: entrada base_url, el valor predeterminado es Ninguno
temperatura: 0,2
max_tokens: 1024herramienta:
detectar:groundingdino_config: la ruta de GroundingDINO_SwinT_OGC.pymodel_path: la ruta de groundingdino_swint_ogc.pthdevice: cuda:0BOX_TRESHOLD: 0.35TEXT_TRESHOLD: 0.25AREA_THRESHOLD: 0.001
ocr:dbnetpp_config: la ruta de dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015.pydbnetpp_path: la ruta de dbnetpp.pthmaerec_config: la ruta de maerec_b_union14m.pymaerec_path: la ruta de maerec_b.pthdevice: cuda:0content: word.numbercachefiles_path: la ruta de cache_files para guardar imágenes temporalesBOX_TRESHOLD: 0.2TEXT_TRESHOLD: 0.25
google_serper:serper_api_key: ingrese las claves de la API de Serpernippet_cnt: 10prompts: Claim_generate: pipeline/prompts/claim_generate.yaml
query_generate: canalización/prompts/query_generate.yaml
verificar: canalización/prompts/verify.yamlCódigo de ejemplo
from pipeline.run_pipeline import *pipeline = Pipeline()text = "El café en la imagen se llama "Hauptbahnhof""image_path = "./examples/058214af21a03013.jpg"type = "image-to-text"response, Claim_list = pipeline .run(texto=texto, ruta_imagen=ruta_imagen, tipo=tipo)imprimir(respuesta)imprimir(lista_reclamo)
Cite nuestro repositorio si utiliza EasyDetect en su trabajo.
@article{chen23factchd, autor = {Xiang Chen y Duanzheng Song y Honghao Gui y Chengxi Wang y Ningyu Zhang y Jiang Yong y Fei Huang y Chengfei Lv y Dan Zhang y Huajun Chen}, título = {FactCHD: Evaluación comparativa de detección de alucinaciones en conflicto con hechos }, revista = {CoRR}, volumen = {abs/2310.12086}, año = {2023}, url = {https://doi.org/10.48550/arXiv.2310.12086}, doi = {10.48550/ARXIV.2310.12086}, eprinttype = {arXiv}, eprint = {2310.12086}, biburl = {https://dblp.org/rec/journals/corr/abs-2310-12086.bib}, bibsource = {bibliografía informática de dblp, https://dblp.org}}@inproceedings{chen-etal-2024- unified-hallucination,title = "Detección unificada de alucinaciones para modelos multimodales de lenguaje grande",autor = "Chen, Xiang y Wang, Chenxi y Xue, Yida y Zhang, Ningyu y Yang, Xiaoyan y Li, Qiang y Shen, Yue y Liang, Lei y Gu, Jinjie y Chen, Huajun",editor = "Ku, Lun-Wei y Martins, Andre y Srikumar, Vivek",booktitle = " Actas de la 62ª Reunión Anual de la Asociación de Lingüística Computacional (Volumen 1: Artículos extensos)",mes = agosto,año = "2024", dirección = "Bangkok, Tailandia",publisher = "Asociación de Lingüística Computacional",url = "https://aclanthology.org/2024.acl-long.178",pages = "3235--3252",
}Ofreceremos mantenimiento a largo plazo para corregir errores, resolver problemas y satisfacer nuevas solicitudes. Entonces, si tiene algún problema, díganoslo.


