ssebowa
1.0.0
Ssebowa es una biblioteca Python de código abierto que proporciona modelos generativos de IA, que incluyen:
ssebowa-llm: un modelo de lenguaje grande (LLM) para generación de texto,ssebowa-vllm: un modelo de lenguaje visual (VLLM) para la comprensión visual,ssebowa-imagen: generación de imágenes y modelo de ajuste fino personalizado.Ssebowa-vigen: un modelo de generación de vídeo.Con Ssebowa, puede generar texto fácilmente, traducir idiomas, escribir diferentes tipos de contenido creativo, generar imágenes personalizadas y responder sus preguntas de manera informativa.
Para obtener información de uso más detallada, consulte: Documentación técnica de Ssebowa
Antes de ejecutar el script, asegúrese de que estén instaladas las bibliotecas necesarias. Puedes hacer esto ejecutando los siguientes comandos:
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .Luego instale Ssebowa
pip install ssebowaSi está ejecutando estos comandos en colab o jupyter notebook, utilice esto,
! git clone https://github.com/huggingface/diffusers
! cd diffusers
! pip install .
! pip install ssebowaAhora puedes acceder a los diferentes modelos importándolos desde la biblioteca:
Ssebowa-Imagen es un modelo de síntesis de imágenes de código abierto que utiliza una combinación de diffusion modeling y generative adversarial networks (GANs) para generar imágenes de alta calidad a partir de text descriptions y también permite convertir algunas fotos en custom model capaz de generar Impresionantes imágenes del chosen subject . Aprovecha un conjunto de 100 billion dataset de imágenes y descripciones de texto, lo que le permite capturar con precisión los matices de las imágenes del mundo real y traducir de manera efectiva descripciones de texto en representaciones visuales convincentes.
10-20 high-quality (jpg or png) como las suyas, de amigos, de productos o de mascotas, etc., y colóquelas en un directorio específico.16GB or more . (Si está ajustando SDXL, necesitará 24 GB de VRAM). from ssebowa.dataset import LocalDataset
from ssebowa.model import SdSsebowaModel
from ssebowa.trainer import LocalTrainer
from ssebowa.utils.image_helpers import display_images
from ssebowa.utils.prompt_helpers import make_promptDATA_DIR = " data " # The directory where you put your prepared photos
OUTPUT_DIR = " models " dataset = LocalDataset(DATA_DIR)
dataset = dataset.preprocess_images(detect_face=True)SUBJECT_NAME = " <YOUR-NAME> "
CLASS_NAME = " person " model = SdSsebowaModel(subject_name=SUBJECT_NAME, class_name=CLASS_NAME)
trainer = LocalTrainer(output_dir=OUTPUT_DIR)
predictor = trainer.fit(model, dataset)
# Use the prompt helper to create an awesome AI avatar!
prompt = next(make_prompt(SUBJECT_NAME, CLASS_NAME))
images = predictor.predict(
prompt, height=768, width=512, num_images_per_prompt=2,
)
display_images(images, fig_size=10)
from ssebowa import Ssebowa_imgen
model = Ssebowa_imgen ()Como generemos "Un gato sentado en una estantería"
image = model.generate_image( " A cat sitting on a bookshelf " )image.save( " cat_on_bookshelf.jpg " )

Ssebowa-vllm es un modelo de lenguaje visual grande (VLLM) de código abierto desarrollado por Ssebowa AI. Es una herramienta poderosa que se puede utilizar para comprender imágenes. Ssebowa-vllm tiene 11 mil millones de parámetros visuales y 7 mil millones de parámetros de lenguaje, lo que admite la comprensión de imágenes con una resolución de 1120*1120.
from ssebowa import ssebowa_vllm
model = ssebowa_vllm ()
response = model.understand(image_path, prompt)
print(response)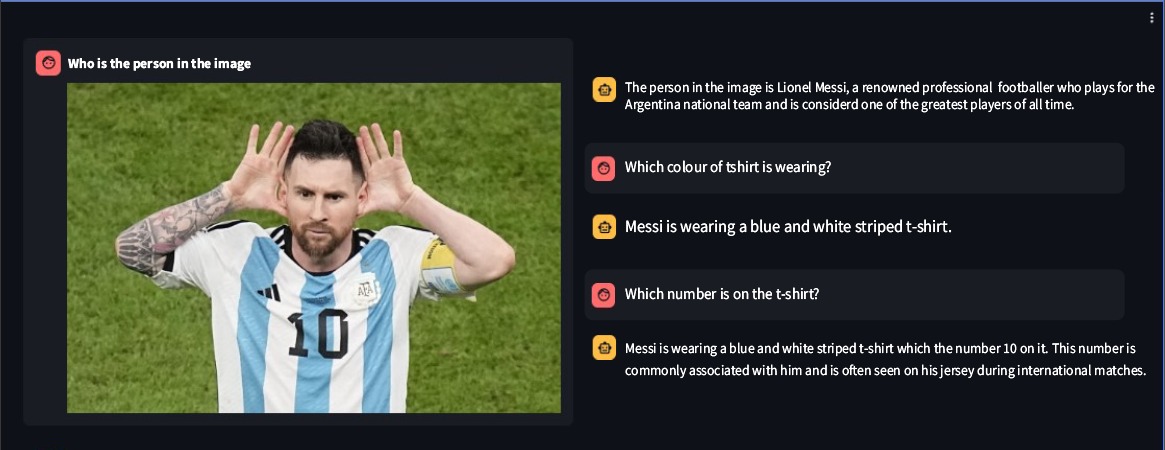
¡Ssebowa está abierto a contribuciones! Directrices en proceso..
Ssebowa se publica bajo la licencia Apache 2.0.
Si tiene alguna pregunta o sugerencia, no dude en abrir un problema en GitHub o contáctenos en [email protected].


