xTuring
0.1.8


xTuring proporciona un ajuste rápido, eficiente y sencillo de LLM de código abierto, como Mistral, LLaMA, GPT-J y más. Al proporcionar una interfaz fácil de usar para ajustar los LLM a sus propios datos y aplicaciones, xTuring simplifica la creación, modificación y control de los LLM. Todo el proceso se puede realizar dentro de su computadora o en su nube privada, garantizando la privacidad y seguridad de los datos.
Con xTuring puedes,
pip install xturing from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
# Load the dataset
instruction_dataset = InstructionDataset ( "./examples/models/llama/alpaca_data" )
# Initialize the model
model = BaseModel . create ( "llama_lora" )
# Finetune the model
model . finetune ( dataset = instruction_dataset )
# Perform inference
output = model . generate ( texts = [ "Why LLM models are becoming so important?" ])
print ( "Generated output by the model: {}" . format ( output ))Puede encontrar la carpeta de datos aquí.
Nos complace anunciar las últimas mejoras en nuestra biblioteca xTuring :
LLaMA 2 : puede utilizar y ajustar el modelo LLaMA 2 en diferentes configuraciones: disponible en el mercado , disponible en el mercado con precisión INT8 , ajuste fino de LoRA , ajuste fino de LoRA con precisión INT8 y ajuste fino de LoRA. sintonizando con precisión INT4 usando el contenedor GenericModel y/o puede usar la clase Llama2 de xturing.models para probar y ajustar el modelo. from xturing . models import Llama2
model = Llama2 ()
## or
from xturing . models import BaseModel
model = BaseModel . create ( 'llama2' )Evaluation : ahora puede evaluar cualquier Causal Language Model en cualquier conjunto de datos. La métrica actualmente soportada es perplexity . # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model
model = BaseModel . create ( 'gpt2' )
# Run the Evaluation of the model on the dataset
result = model . evaluate ( dataset )
# Print the result
print ( f"Perplexity of the evalution: { result } " )INT4 Precision : ahora puede usar y ajustar cualquier LLM con INT4 Precision usando GenericLoraKbitModel . # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import GenericLoraKbitModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model for INT4 bit fine-tuning
model = GenericLoraKbitModel ( 'tiiuae/falcon-7b' )
# Run the fine-tuning
model . finetune ( dataset ) # Make the necessary imports
from xturing . models import BaseModel
# Initializes the model: quantize the model with weight-only algorithms
# and replace the linear with Itrex's qbits_linear kernel
model = BaseModel . create ( "llama2_int8" )
# Once the model has been quantized, do inferences directly
output = model . generate ( texts = [ "Why LLM models are becoming so important?" ])
print ( output ) # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import GenericLoraKbitModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model for INT4 bit fine-tuning
model = GenericLoraKbitModel ( 'tiiuae/falcon-7b' )
# Generate outputs on desired prompts
outputs = model . generate ( dataset = dataset , batch_size = 10 )Se recomienda una exploración del ejemplo de trabajo de Llama LoRA INT4 para comprender su aplicación.
Para obtener más información, considere examinar el ejemplo de trabajo de GenericModel disponible en el repositorio.

$ xturing chat -m " <path-to-model-folder> "
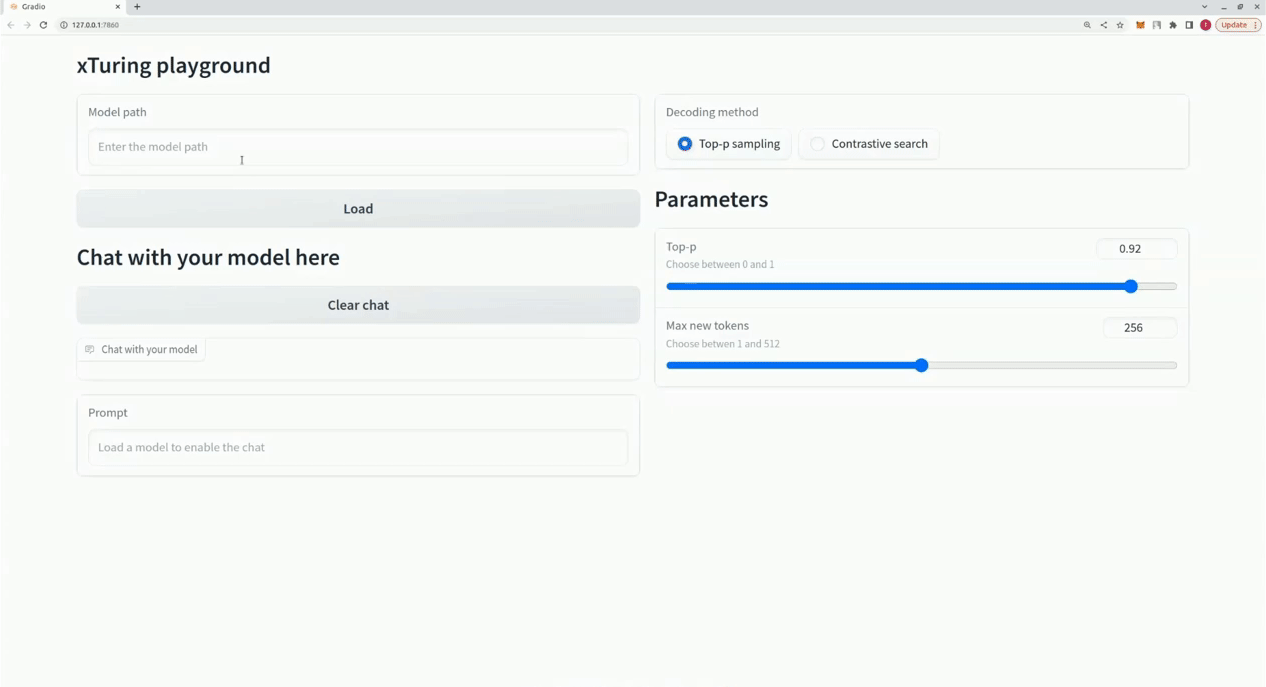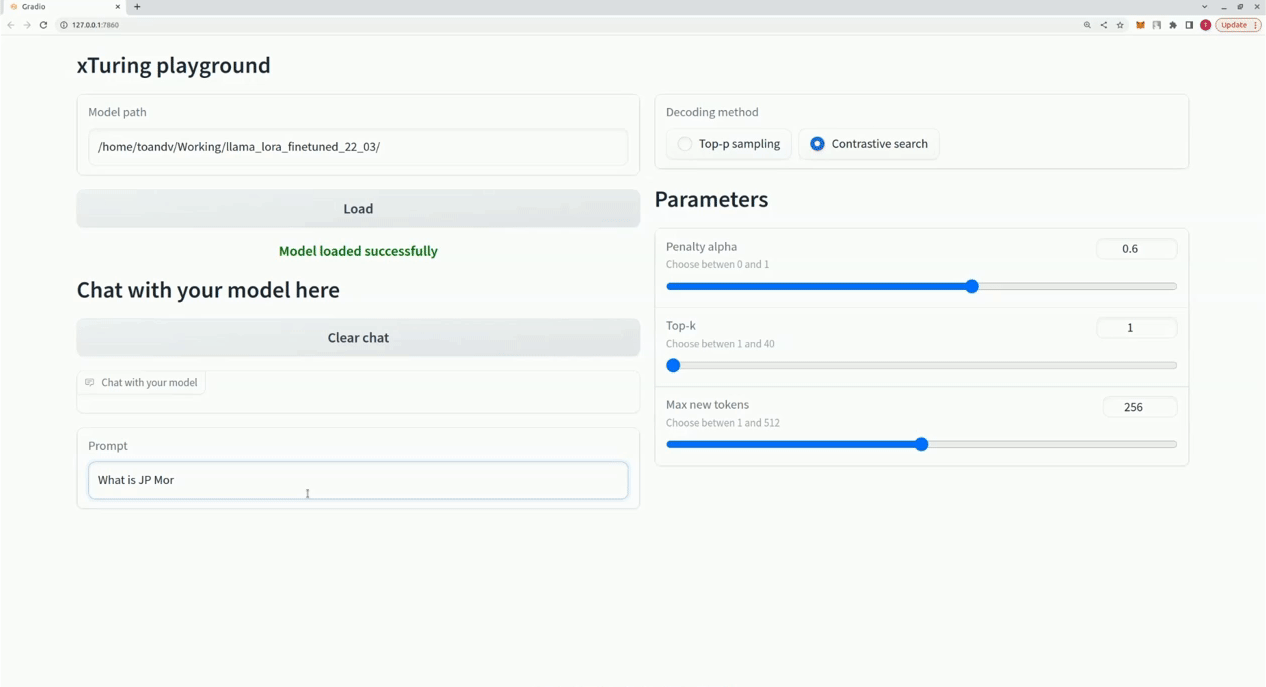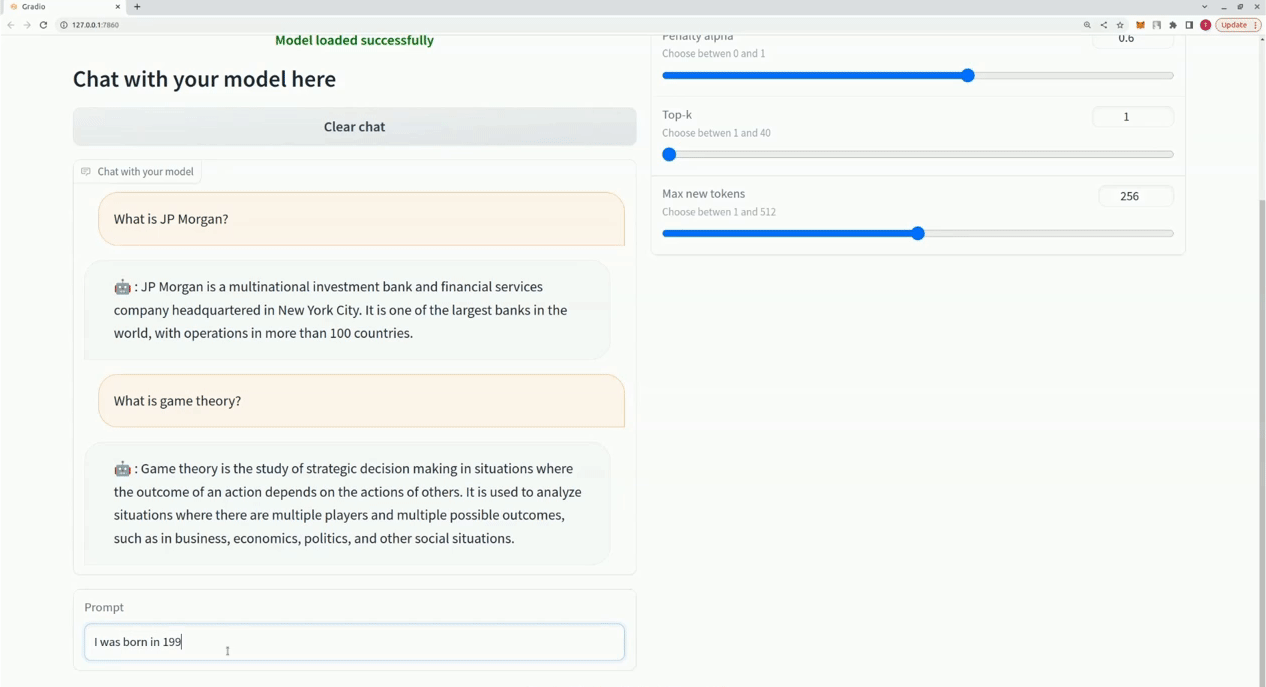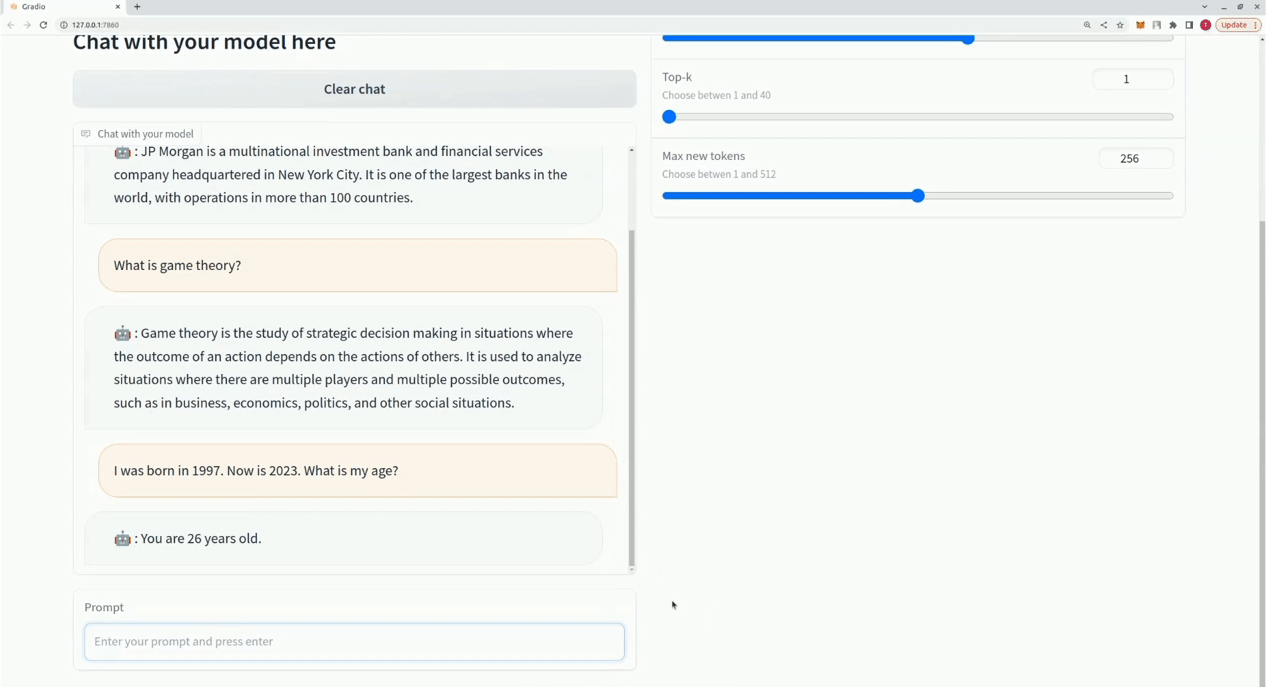
from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
from xturing . ui import Playground
dataset = InstructionDataset ( "./alpaca_data" )
model = BaseModel . create ( "<model_name>" )
model . finetune ( dataset = dataset )
model . save ( "llama_lora_finetuned" )
Playground (). launch () ## launches localhost UI A continuación se muestra una comparación del rendimiento de diferentes técnicas de ajuste fino en el modelo LLaMA 7B. Usamos el conjunto de datos de Alpaca para realizar ajustes. El conjunto de datos contiene 52K instrucciones.
Hardware:
4 GPU A100 de 40 GB, CPU de 335 GB de RAM
Parámetros de ajuste fino:
{
'maximum sequence length' : 512 ,
'batch size' : 1 ,
}| LLaMA-7B | Descarga de CPU DeepSpeed + | LoRA + Velocidad profunda | LoRA + DeepSpeed + Descarga de CPU |
|---|---|---|---|
| GPU | 33,5GB | 23,7GB | 21,9GB |
| UPC | 190GB | 10,2GB | 14,9GB |
| Tiempo/época | 21 horas | 20 minutos | 20 minutos |
Contribuya a esto enviando sus resultados de rendimiento en otras GPU creando un problema con sus especificaciones de hardware, consumo de memoria y tiempo por época.
Ya hemos perfeccionado algunos modelos que puedes usar como base o empezar a jugar. Así es como los cargarías:
from xturing . models import BaseModel
model = BaseModel . load ( "x/distilgpt2_lora_finetuned_alpaca" )| modelo | conjunto de datos | Camino |
|---|---|---|
| DistilGPT-2 LoRA | alpaca | x/distilgpt2_lora_finetuned_alpaca |
| LLAMA LORA | alpaca | x/llama_lora_finetuned_alpaca |
A continuación se muestra una lista de todos los modelos compatibles a través de la clase BaseModel de xTuring y sus claves correspondientes para cargarlos.
| Modelo | Llave |
|---|---|
| Floración | floración |
| Cerebras | cerebros |
| DestilarGPT-2 | distilgpt2 |
| Halcón-7B | halcón |
| Galáctica | galáctica |
| GPT-J | gptj |
| GPT-2 | gpt2 |
| Llama | llama |
| LlaMA2 | llama2 |
| OPT-1.3B | optar |
Las mencionadas anteriormente son las variantes básicas de los LLM. A continuación se muestran las plantillas para obtener sus versiones LoRA , INT8 , INT8 + LoRA e INT4 + LoRA .
| Versión | Plantilla |
|---|---|
| lora | <clave_modelo>_lora |
| INT8 | <clave_modelo>_int8 |
| INT8 + LoRA | <clave_modelo>_lora_int8 |
** Para cargar la versión INT4+LoRA de cualquier modelo, deberá utilizar la clase GenericLoraKbitModel de xturing.models . A continuación se muestra cómo usarlo:
model = GenericLoraKbitModel ( '<model_path>' ) model_path se puede reemplazar con su directorio local o cualquier modelo de biblioteca HuggingFace como facebook/opt-1.3b .
LLaMA , GPT-J , GPT-2 , OPT , Cerebras-GPT , Galactica y Bloom Generic model Falcon-7B Si tiene alguna pregunta, puede crear un problema en este repositorio.
También puedes unirte a nuestro servidor de Discord e iniciar una discusión en el canal #xturing .
Este proyecto tiene la licencia Apache 2.0; consulte el archivo de LICENCIA para obtener más detalles.
Como proyecto de código abierto en un campo en rápida evolución, agradecemos contribuciones de todo tipo, incluidas nuevas funciones y mejor documentación. Lea nuestra guía de contribución para saber cómo puede participar.


