AttackVLM
1.0.0
[Página del proyecto] | [Diapositivas] | [arXiv] | [Repositorio de datos]
In this research, we evaluate the adversarial robustness of recent large vision-language (generative) models (VLMs), under the most realistic and challenging setting with threat model of black-box access and targeted goal.
Our proposed method aims for the targeted response generation over large VLMs such as MiniGPT-4, LLaVA, Unidiffuser, BLIP/2, Img2Prompt, etc.
In other words, we mislead and let the VLMs say what you want, regardless of the content of the input image query.

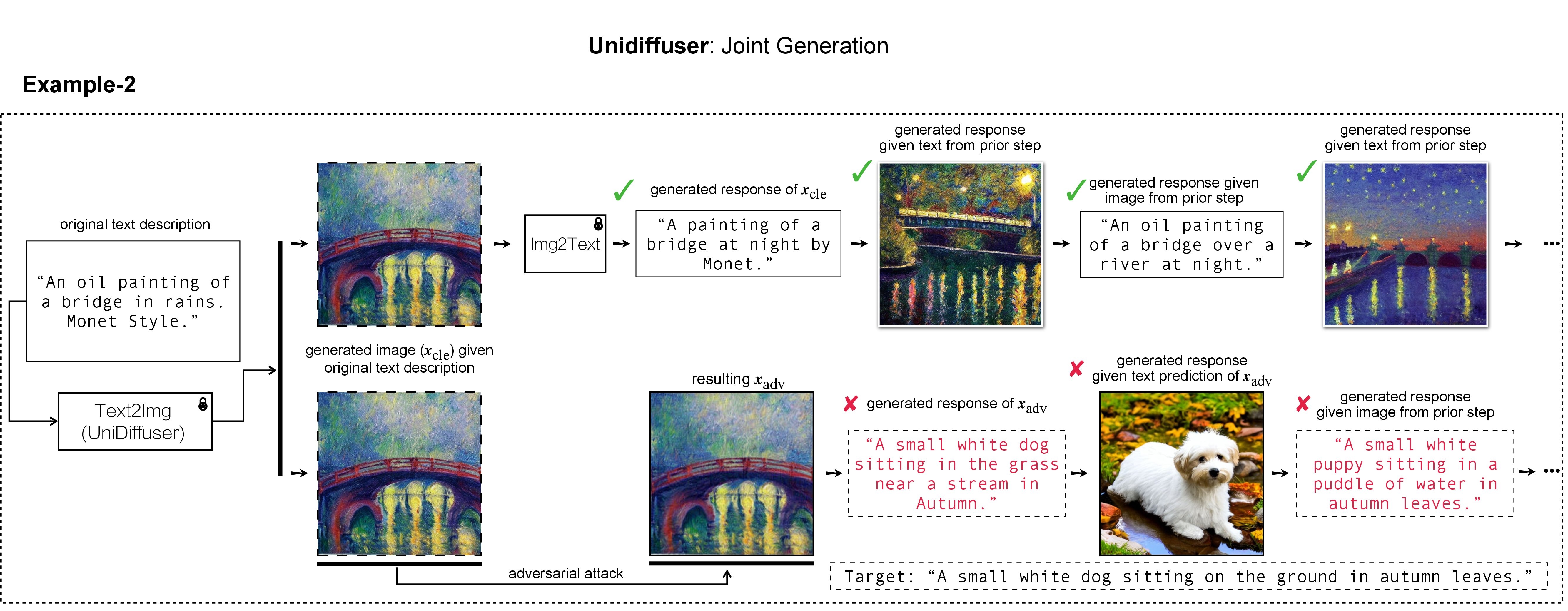
En nuestro trabajo, utilizamos DALL-E, Midjourney y Stable Diffusion para la generación y demostración de la imagen de destino. Para los experimentos a gran escala, aplicamos Difusión estable para la generación de imágenes de destino. Para instalar Stable Diffusion, iniciamos nuestro entorno conda siguiendo los modelos de difusión latente. Se puede crear y activar un entorno conda base adecuado llamado ldm con:
conda env create -f environment.yaml
conda activate ldm
Tenga en cuenta que para diferentes modelos de víctimas, seguiremos sus implementaciones oficiales y entornos conda.
 Como se analiza en nuestro artículo, para lograr un ataque dirigido flexible, aprovechamos un modelo de texto a imagen previamente entrenado para generar una imagen objetivo con un único título como texto objetivo. En consecuencia, de esta manera usted mismo puede especificar el título objetivo para el ataque.
Como se analiza en nuestro artículo, para lograr un ataque dirigido flexible, aprovechamos un modelo de texto a imagen previamente entrenado para generar una imagen objetivo con un único título como texto objetivo. En consecuencia, de esta manera usted mismo puede especificar el título objetivo para el ataque.
Utilizamos Stable Diffusion, DALL-E o Midjourney como generadores de texto a imagen en nuestros experimentos. Aquí utilizamos Stable Diffusion para demostración (¡gracias por el código abierto!).
git clone https://github.com/CompVis/stable-diffusion.git
cd stable-diffusion
luego, prepare los subtítulos específicos completos de MS-COCO o descargue nuestra versión procesada y limpia:
https://drive.google.com/file/d/19tT036LBvqYonzI7PfU9qVi3jVGApKrg/view?usp=sharing
y muévalo a ./stable-diffusion/ . En los experimentos, se puede muestrear aleatoriamente un subconjunto de subtítulos COCO (por ejemplo, 10 , 100 , 1K , 10K , 50K ) para el ataque adversario. Por ejemplo, supongamos que hemos muestreado aleatoriamente 10K subtítulos de COCO como nuestro texto objetivo c_tar y los hemos almacenado en el siguiente archivo:
https://drive.google.com/file/d/1e5W3Yim7ZJRw3_C64yqVZg_Na7dOawaF/view?usp=sharing
Las imágenes objetivo h_ξ(c_tar) se pueden obtener a través de Difusión estable leyendo el mensaje de texto de los subtítulos de COCO de muestra, con el script a continuación y txt2img_coco.py (mueva txt2img_coco.py a ./stable-diffusion/ , tenga en cuenta que los hiperparámetros se pueden ajustado según su preferencia):
python txt2img_coco.py
--ddim_eta 0.0
--n_samples 10
--n_iter 1
--scale 7.5
--ddim_steps 50
--plms
--skip_grid
--ckpt ./_model_pool/sd-v1-4-full-ema.ckpt
--from-file './name_of_your_coco_captions_file.txt'
--outdir './path_of_your_targeted_images'
donde el ckpt lo proporciona Stable Diffusion v1 y se puede descargar aquí: sd-v1-4-full-ema.ckpt.
Se pueden encontrar detalles adicionales de implementación de la generación de texto a imagen mediante Stable Diffusion AQUÍ.
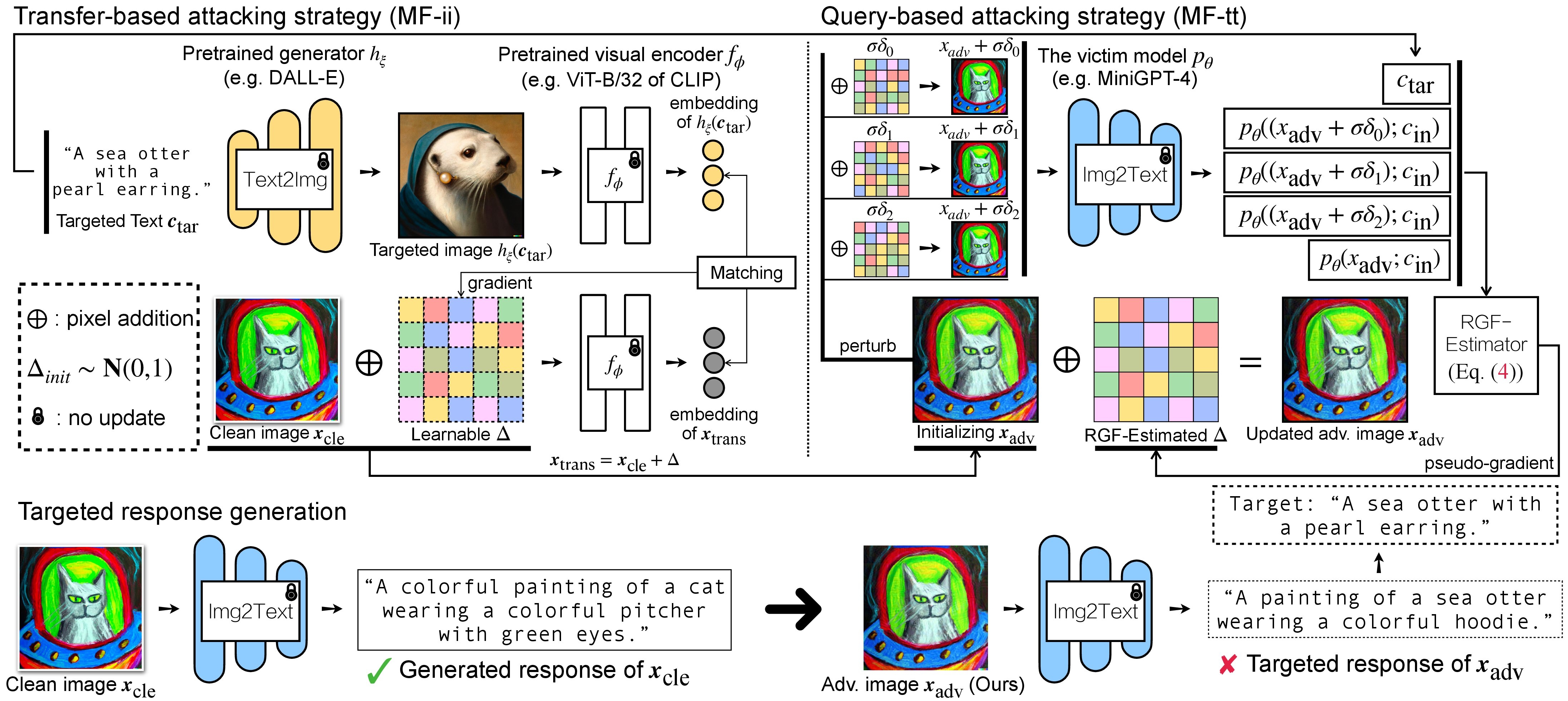
Hay dos pasos de ataque adversario para VLM: (1) estrategia de ataque basada en transferencias y (2) estrategia de ataque basada en consultas utilizando (1) como inicialización. Para los modelos BLIP/BLIP-2/Img2Prompt, consulte ./LAVIS_tool . Aquí usamos Unidiffuser como ejemplo.
git clone https://github.com/thu-ml/unidiffuser.git
cd unidiffuser
cp ../unidff_tool/* ./
luego, cree un entorno conda adecuado llamado unidiffuser siguiendo los pasos AQUÍ y prepare los pesos del modelo correspondientes (usamos uvit_v1.pth como el peso de U-ViT).
conda activate unidiffuser
bash _train_adv_img_trans.sh
las imágenes adv creadas x_trans se almacenarán en dir of white-box transfer images especificadas en --output . Luego, realizamos la conversión de imagen a texto y almacenamos la respuesta generada de x_trans. Esto se puede lograr mediante:
python _eval_i2t_dataset.py
--batch_size 100
--mode i2t
--img_path 'dir of white-box transfer images'
--output 'dir of white-box transfer captions'
donde las respuestas generadas se almacenarán en dir of white-box transfer captions en formato .txt . Los usaremos para la estimación de pseudogradiente mediante el estimador RGF.
MF-ii + MF-tt (por ejemplo, 8 px) bash _train_trans_and_query_fixed_budget.sh
Por otro lado, si desea realizar un ataque basado en transferencia+consulta con un presupuesto de perturbación separado , también proporcionamos un script:
bash _train_trans_and_query_more_budget.sh
Aquí, utilizamos wandb para monitorear dinámicamente el promedio móvil de la puntuación CLIP (por ejemplo, RN50, ViT-B/32, ViT-L/14, etc.) para evaluar la similitud entre (a) la respuesta generada (de trans/ consultar imágenes) y (b) el texto objetivo predefinido c_tar .
A continuación se muestra un ejemplo, donde la línea de puntos indica el promedio móvil de la puntuación CLIP (de los títulos de las imágenes) después de la consulta: 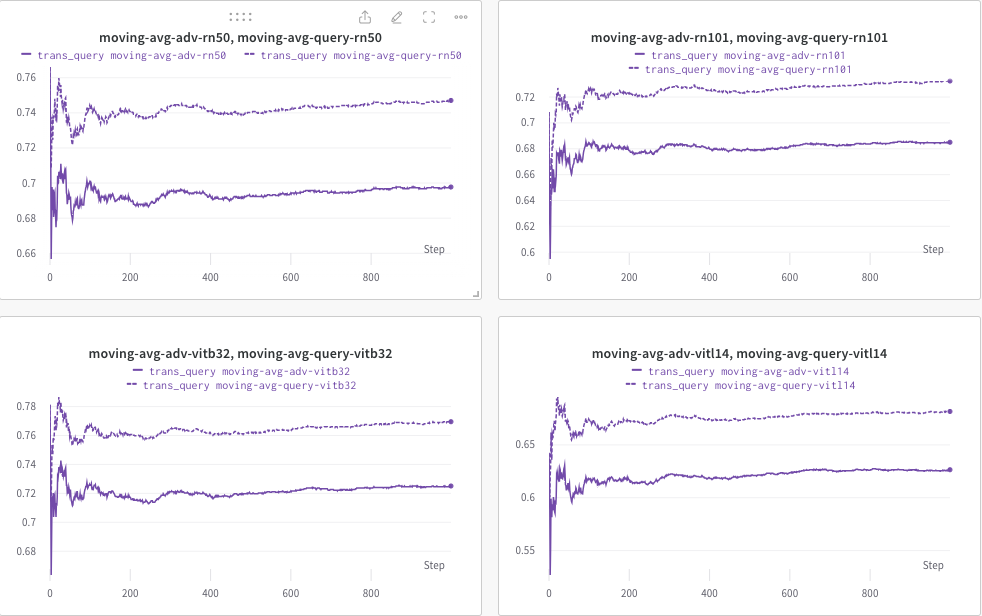
Mientras tanto, el título de la imagen después de la consulta se almacenará y el directorio se puede especificar mediante --output .
Si encuentra útil este proyecto en su investigación, considere citar nuestro artículo:
@inproceedings{zhao2023evaluate,
title={On Evaluating Adversarial Robustness of Large Vision-Language Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Li, Chongxuan and Cheung, Ngai-Man and Lin, Min},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023}
}
Mientras tanto, una investigación relevante que tiene como objetivo incorporar una marca de agua a modelos de difusión (multimodales):
@article{zhao2023recipe,
title={A Recipe for Watermarking Diffusion Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Cheung, Ngai-Man and Lin, Min},
journal={arXiv preprint arXiv:2303.10137},
year={2023}
}
Apreciamos la maravillosa implementación básica de MiniGPT-4, LLaVA, Unidiffuser, LAVIS y CLIP. También agradecemos a @MetaAI por abrir sus puntos de control LLaMA. Agradecemos a SiSi por proporcionar algunas imágenes agradables y visualmente agradables generadas por @Midjourney en nuestra investigación.


