SDV
v1.17.2 - 2024-11-18
Este repositorio es parte del Proyecto Synthetic Data Vault, un proyecto de DataCebo.



Synthetic Data Vault (SDV) es una biblioteca de Python diseñada para ser su ventanilla única para crear datos sintéticos tabulares. El SDV utiliza una variedad de algoritmos de aprendizaje automático para aprender patrones a partir de datos reales y emularlos en datos sintéticos.
? Cree datos sintéticos mediante el aprendizaje automático. El SDV ofrece múltiples modelos, que van desde métodos estadísticos clásicos (GaussianCopula) hasta métodos de aprendizaje profundo (CTGAN). Genere datos para tablas individuales, múltiples tablas conectadas o tablas secuenciales.
Evaluar y visualizar datos. Compare los datos sintéticos con los datos reales frente a una variedad de medidas. Diagnostica problemas y genera un informe de calidad para obtener más información.
Preprocesar, anonimizar y definir restricciones. Controle el procesamiento de datos para mejorar la calidad de los datos sintéticos, elija entre diferentes tipos de anonimización y defina reglas de negocio en forma de restricciones lógicas.
| Enlaces importantes | |
|---|---|
 Tutoriales Tutoriales | Obtenga experiencia práctica con el SDV. Inicie los cuadernos de tutoriales y ejecute el código usted mismo. |
| Documentos | Aprenda a utilizar la biblioteca SDV con guías de usuario y referencias de API. |
| ? Blog | Obtenga más información sobre el uso de SDV, la implementación de modelos y nuestra comunidad de datos sintéticos. |
 Comunidad Comunidad | Únase a nuestro espacio de trabajo de Slack para recibir anuncios y debates. |
| Sitio web | Consulte el sitio web de SDV para obtener más información sobre el proyecto. |
El SDV está disponible públicamente bajo la Licencia de fuente comercial. Instale SDV usando pip o conda. Recomendamos utilizar un entorno virtual para evitar conflictos con otro software en su dispositivo.
pip install sdvconda install -c pytorch -c conda-forge sdvCargue un conjunto de datos de demostración para comenzar. Este conjunto de datos es una tabla única que describe a los huéspedes que se alojan en un hotel ficticio.
from sdv . datasets . demo import download_demo
real_data , metadata = download_demo (
modality = 'single_table' ,
dataset_name = 'fake_hotel_guests' )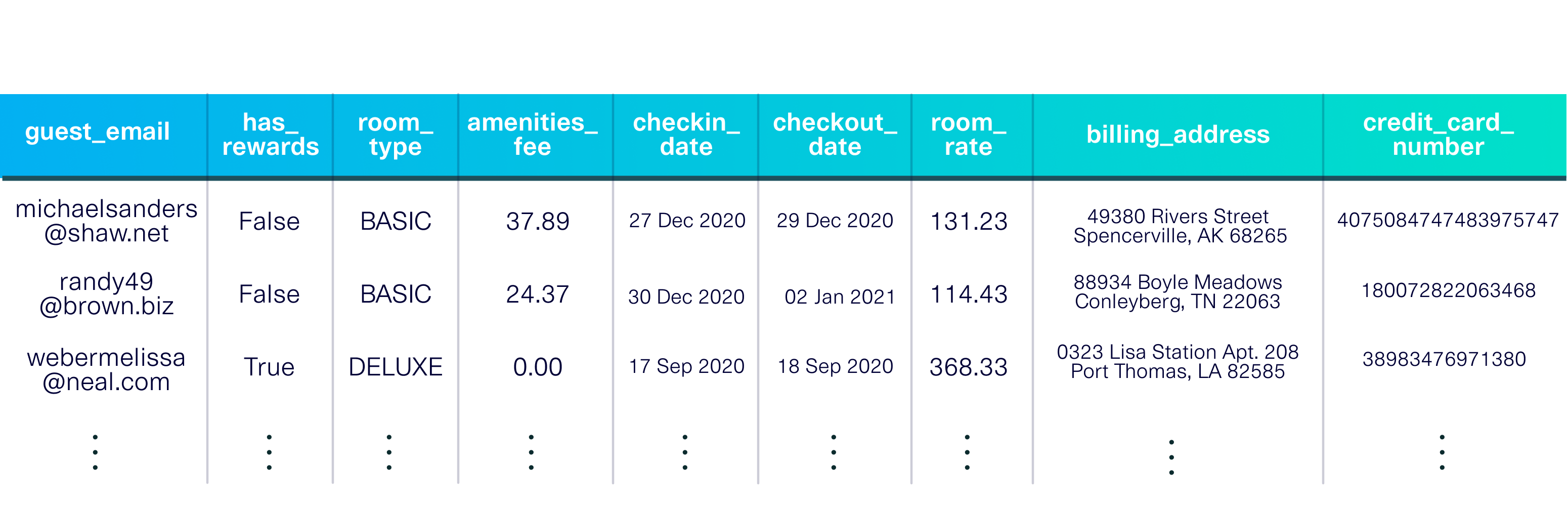
La demostración también incluye metadatos , una descripción del conjunto de datos, incluidos los tipos de datos en cada columna y la clave principal ( guest_email ).
A continuación, podemos crear un sintetizador SDV , un objeto que puedes usar para crear datos sintéticos. Aprende patrones a partir de datos reales y los replica para generar datos sintéticos. Utilicemos el sintetizador GaussianCopula.
from sdv . single_table import GaussianCopulaSynthesizer
synthesizer = GaussianCopulaSynthesizer ( metadata )
synthesizer . fit ( data = real_data )¡Y ahora el sintetizador está listo para crear datos sintéticos!
synthetic_data = synthesizer . sample ( num_rows = 500 )Los datos sintéticos tendrán las siguientes propiedades:
La biblioteca SDV le permite evaluar los datos sintéticos comparándolos con los datos reales. Comience generando un informe de calidad.
from sdv . evaluation . single_table import evaluate_quality
quality_report = evaluate_quality (
real_data ,
synthetic_data ,
metadata ) Generating report ...
(1/2) Evaluating Column Shapes: |████████████████| 9/9 [00:00<00:00, 1133.09it/s]|
Column Shapes Score: 89.11%
(2/2) Evaluating Column Pair Trends: |██████████████████████████████████████████| 36/36 [00:00<00:00, 502.88it/s]|
Column Pair Trends Score: 88.3%
Overall Score (Average): 88.7%
Este objeto calcula una puntuación de calidad general en una escala del 0 al 100% (siendo 100 el mejor), así como desgloses detallados. Para obtener más información, también puede visualizar los datos sintéticos frente a los reales.
from sdv . evaluation . single_table import get_column_plot
fig = get_column_plot (
real_data = real_data ,
synthetic_data = synthetic_data ,
column_name = 'amenities_fee' ,
metadata = metadata
)
fig . show ()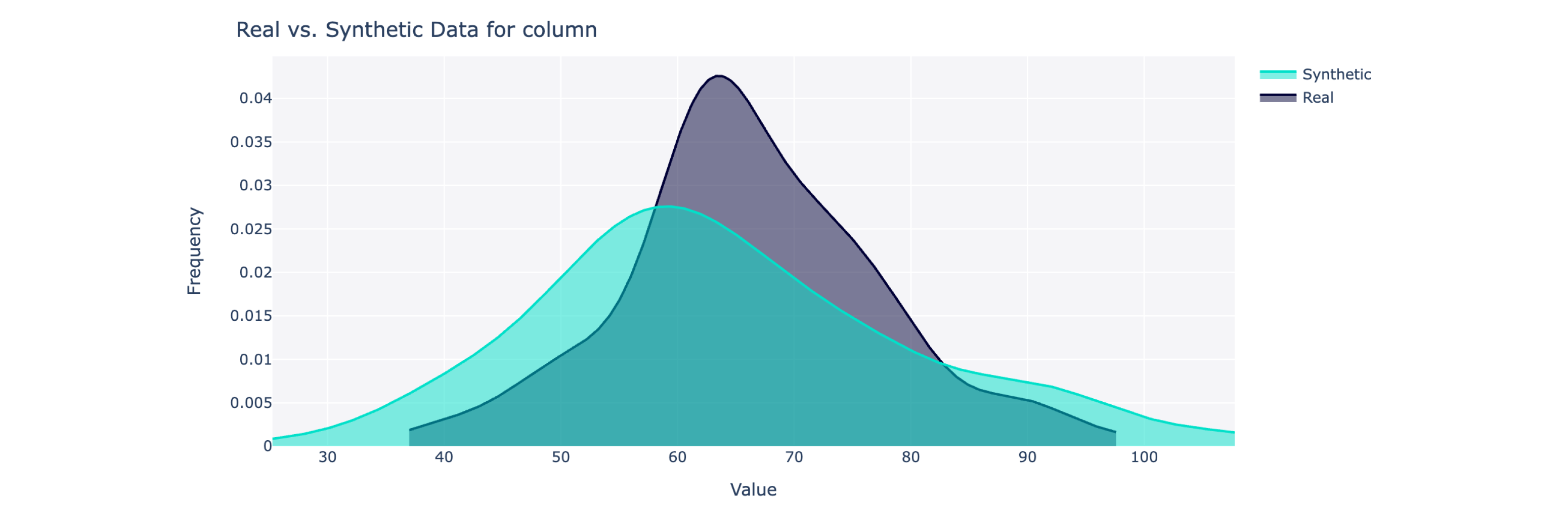
Con la biblioteca SDV, puede sintetizar datos de una sola tabla, de varias tablas y secuenciales. También puede personalizar todo el flujo de trabajo de datos sintéticos, incluido el preprocesamiento, la anonimización y la adición de restricciones.
Para obtener más información, visite la página de demostración de SDV.
¡Gracias a nuestro equipo de colaboradores que han construido y mantenido el ecosistema SDV a lo largo de los años!
Ver colaboradores
Si utiliza SDV para su investigación, cite el siguiente artículo:
Neha Patki, Roy Wedge, Kalyan Veeramachaneni . La bóveda de datos sintéticos. IEEE DSAA 2016.
@inproceedings{
SDV,
title={The Synthetic data vault},
author={Patki, Neha and Wedge, Roy and Veeramachaneni, Kalyan},
booktitle={IEEE International Conference on Data Science and Advanced Analytics (DSAA)},
year={2016},
pages={399-410},
doi={10.1109/DSAA.2016.49},
month={Oct}
}
El proyecto Synthetic Data Vault se creó por primera vez en el Data to AI Lab del MIT en 2016. Después de 4 años de investigación y tracción con la empresa, creamos DataCebo en 2020 con el objetivo de hacer crecer el proyecto. Hoy, DataCebo es el orgulloso desarrollador de SDV, el ecosistema más grande para la generación y evaluación de datos sintéticos. Es el hogar de múltiples bibliotecas que admiten datos sintéticos, que incluyen:
Comience a utilizar el paquete SDV: una solución totalmente integrada y su ventanilla única para datos sintéticos. O utilice las bibliotecas independientes para necesidades específicas.


