LipGER
Initial Release
Esta es la implementación oficial de nuestro artículo LipGER: Corrección de errores generativos condicionados visualmente para un reconocimiento automático de voz robusto en InterSpeech 2024, que se selecciona para presentación oral .
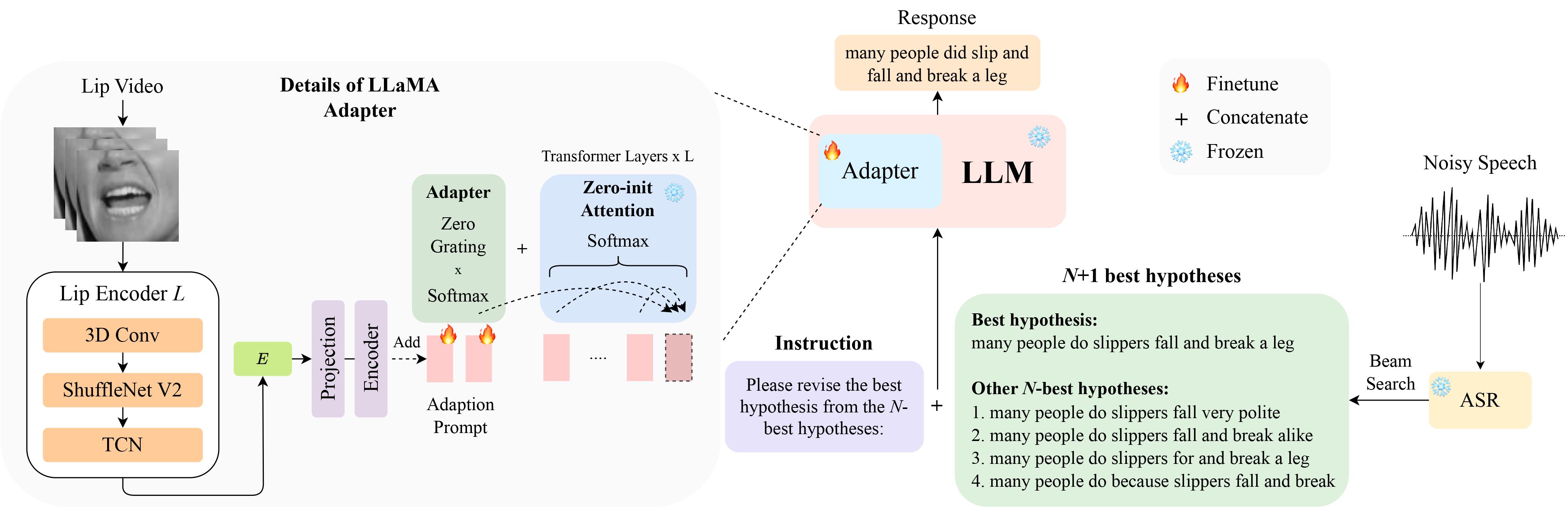
¡Puedes descargar los datos de LipHyp desde aquí!
pip install -r requirements.txt
Primero prepare los puntos de control usando:
pip install huggingface_hub
python scripts/download.py --repo_id meta-llama/Llama-2-7b-chat-hf --token your_hf_token
python scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/meta-llama/Llama-2-7b-chat-hfPara ver todos los puntos de control disponibles, ejecute:
python scripts/download.py | grep Llama-2Para más detalles, también puedes consultar este enlace, donde también puedes preparar otros puntos de control para otros modelos. Específicamente, utilizamos TinyLlama para nuestros experimentos.
El punto de control está disponible aquí. Después de la descarga, cambie la ruta del punto de control aquí.
LipGER espera que todos los archivos train, val y test estén en el formato sample_data.json. Una instancia en el archivo se parece a:
{
"Dataset": "dataset_name",
"Uid": "unique_id",
"Caption": "The ground truth transcription.",
"Noisy_Wav": "path_to_noisy_wav",
"Mouthroi": "path_to_mouth_roi_mp4",
"Video": "path_to_video_mp4",
"nhyps_base": [ list of N-best hypotheses ],
}
Debe pasar los archivos de voz a través de un modelo ASR entrenado capaz de generar N mejores hipótesis. En este repositorio ofrecemos dos formas de ayudarle a lograrlo. No dudes en utilizar otros métodos.
pip install whisper y luego ejecutas nhyps.py desde la carpeta data , ¡deberías estar bien! Tenga en cuenta que para ambos métodos, la primera de la lista es la mejor hipótesis y las otras son las N mejores hipótesis (se pasan como un campo de lista nhyps_base del JSON y se usan para construir un mensaje en los siguientes pasos).
Además, los métodos proporcionados utilizan únicamente voz como entrada. Para la generación de N-mejores hipótesis audiovisuales, utilizamos Auto-AVSR. Si necesita ayuda con el código, ¡plantee un problema!
Suponiendo que tiene los vídeos correspondientes para todos sus archivos de voz, siga estos pasos para recortar el retorno de la inversión (ROI) de los vídeos.
python crop_mouth_script.py
python covert_lip.py
Esto convertirá el ROI de mp4 a hdf5, el código cambiará la ruta del ROI de mp4 al ROI de hdf5 en el mismo archivo json. Puede elegir entre los detectores "mediapipe" y "retinaface" cambiando el "detector" en default.yaml
Una vez que tenga las N mejores hipótesis, cree el archivo JSON en el formato requerido. No proporcionamos un código específico para esta parte ya que la preparación de datos puede diferir para cada persona, pero el código debe ser simple. Nuevamente, plantee un problema si tiene alguna duda.
Los scripts de entrenamiento de LipGER no aceptan JSON para entrenamiento o evaluación. Debes convertirlos en un archivo pt. ¡Puedes ejecutar convert_to_pt.py para lograr esto! Cambie model_name según su deseo en la línea 27 y agregue la ruta a su JSON en la línea 58.
Para ajustar LipGER, simplemente ejecute:
sh finetune.sh
donde necesita configurar manualmente los valores de data (con el nombre del conjunto de datos), --train_path y --val_path (con rutas absolutas para entrenar y archivos .pt válidos).
Para inferir, primero cambie las rutas respectivas en lipger.py ( exp_path y checkpoint_dir ) y luego ejecute (con el argumento de ruta de datos de prueba apropiado):
sh infer.sh
El código para recortar el ROI de la boca está inspirado en Visual_Speech_Recognition_for_Multiple_Languages.
Nuestro código para LipGER está inspirado en RobustGER. Cite también su artículo si lo encuentra útil o nuestro código.
@inproceedings{ghosh23b_interspeech,
author={Sreyan Ghosh and Sonal Kumar and Ashish Seth and Purva Chiniya and Utkarsh Tyagi and Ramani Duraiswami and Dinesh Manocha},
title={{LipGER: Visually-Conditioned Generative Error Correction for Robust Automatic Speech Recognition}},
year=2024,
booktitle={Proc. INTERSPEECH 2024},
}


