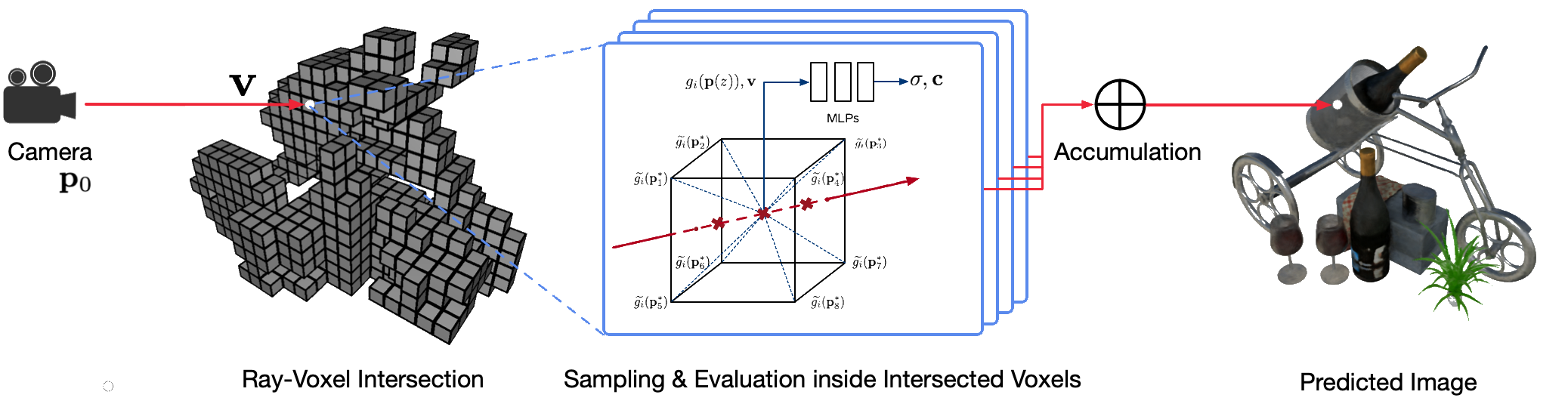
La representación fotorrealista y con punto de vista libre de escenas del mundo real utilizando técnicas clásicas de gráficos por computadora es un problema desafiante porque requiere el difícil paso de capturar modelos detallados de apariencia y geometría. La representación neuronal es un campo emergente que emplea redes neuronales profundas para aprender implícitamente representaciones de escenas que encapsulan tanto la geometría como la apariencia a partir de observaciones 2D con o sin una geometría aproximada. Sin embargo, los enfoques existentes en este campo a menudo muestran renderizados borrosos o sufren de un proceso de renderizado lento. Proponemos Neural Sparse Voxel Fields (NSVF), una nueva representación de escena neuronal para una representación de punto de vista libre rápida y de alta calidad.
Aquí está el repositorio oficial del artículo:
También proporcionamos nuestra implementación no oficial para:
Este código se implementa en PyTorch utilizando el marco fairseq.
El código ha sido probado en el siguiente sistema:
Solo se admite el aprendizaje y la renderización en GPU.
Para instalar, primero clone este repositorio e instale todas las dependencias:
pip install -r requirements.txtEntonces, corre
pip install --editable ./O si desea instalar el código localmente, ejecute:
python setup.py build_ext --inplacePuede descargar los conjuntos de datos reales y sintéticos preprocesados utilizados en nuestro artículo. Cite también los artículos originales si utiliza alguno de ellos en su trabajo.
| Conjunto de datos | Enlace de descarga | Notas sobre la división del conjunto de datos |
|---|---|---|
| NSVF sintético | descargar (.zip) | 0_* (formación) 1_* (validación) 2_* (pruebas) |
| NeRF sintético | descargar (.zip) | 0_* (formación) 1_* (validación) 2_* (pruebas) |
| MezcladoMVS | descargar (.zip) | 0_* (entrenamiento) 1_* (pruebas) |
| Tanques y templos | descargar (.zip) | 0_* (entrenamiento) 1_* (pruebas) |
Para preparar un nuevo conjunto de datos de una sola escena para entrenamiento y prueba, siga la estructura de datos:
< dataset_name >
| -- bbox.txt # bounding-box file
| -- intrinsics.txt # 4x4 camera intrinsics
| -- rgb
| -- 0.png # target image for each view
| -- 1.png
...
| -- pose
| -- 0.txt # camera pose for each view (4x4 matrices)
| -- 1.txt
...
[optional]
| -- test_traj.txt # camera pose for free-view rendering demonstration (4N x 4) donde el archivo bbox.txt contiene una línea que describe el cuadro delimitador inicial y el tamaño del vóxel:
x_min y_min z_min x_max y_max z_max initial_voxel_size Tenga en cuenta que no es necesario que los nombres de archivo de las imágenes de destino y los de los archivos de pose de cámara correspondientes sean exactamente iguales. Sin embargo, el orden de estos dos tipos de archivos (ordenados por cadena) debe coincidir. Los conjuntos de datos se dividen con índices de vista. Por ejemplo, " train (0..100) , valid (100..200) y test (200..400) " significa las primeras 100 vistas para entrenamiento, 100 a 199 vistas para validación y 200 a 399 vistas para pruebas. .
Dado el conjunto de datos de una sola escena ( {DATASET} ), utilizamos el siguiente comando para entrenar un modelo NSVF para sintetizar vistas novedosas a 800x800 píxeles, con un tamaño de lote de 4 imágenes por GPU y 2048 rayos por imagen. De forma predeterminada, el código detectará automáticamente todas las GPU disponibles.
En el siguiente ejemplo, utilizamos una arquitectura predefinida nsvf_base con argumentos específicos:
--no-sampling-at-reader , el modelo solo toma muestras de píxeles en la región de la imagen proyectada de vóxeles dispersos para el entrenamiento.1/8 (0.125) del tamaño del vóxel que normalmente se describe en el archivo bbox.txt .--use-octree . Construirá un octárbol de vóxeles disperso para acelerar la intersección rayo-vóxel, especialmente cuando el número de vóxeles es mayor que 10000 .--pruning-every-steps como 2500 , el modelo realiza una autopoda cada 2500 pasos.--half-voxel-size-at y --reduce-step-size-at como 5000,25000,75000 , el tamaño del vóxel y el tamaño del paso se reducen a la mitad en 5k , 25k y 75k , respectivamente.Tenga en cuenta que, aunque la configuración de los parámetros anteriores se utiliza para la mayoría de los experimentos del artículo, es posible ajustar estos parámetros para lograr una mejor calidad. Además de los parámetros anteriores, otros parámetros también pueden utilizar la configuración predeterminada.
Además de la arquitectura nsvf_base , puede consultar otras arquitecturas o definir sus propias arquitecturas en el archivo fairnr/models/nsvf.py .
python -u train.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--train-views " 0..100 " --view-resolution " 800x800 "
--max-sentences 1 --view-per-batch 4 --pixel-per-view 2048
--no-preload
--sampling-on-mask 1.0 --no-sampling-at-reader
--valid-views " 100..200 " --valid-view-resolution " 400x400 "
--valid-view-per-batch 1
--transparent-background " 1.0,1.0,1.0 " --background-stop-gradient
--arch nsvf_base
--initial-boundingbox ${DATASET} /bbox.txt
--use-octree
--raymarching-stepsize-ratio 0.125
--discrete-regularization
--color-weight 128.0 --alpha-weight 1.0
--optimizer " adam " --adam-betas " (0.9, 0.999) "
--lr 0.001 --lr-scheduler " polynomial_decay " --total-num-update 150000
--criterion " srn_loss " --clip-norm 0.0
--num-workers 0
--seed 2
--save-interval-updates 500 --max-update 150000
--virtual-epoch-steps 5000 --save-interval 1
--half-voxel-size-at " 5000,25000,75000 "
--reduce-step-size-at " 5000,25000,75000 "
--pruning-every-steps 2500
--keep-interval-updates 5 --keep-last-epochs 5
--log-format simple --log-interval 1
--save-dir ${SAVE}
--tensorboard-logdir ${SAVE} /tensorboard
| tee -a $SAVE /train.log Los puntos de control se guardan en {SAVE} . Puedes iniciar tensorboard para comprobar el progreso del entrenamiento:
tensorboard --logdir= ${SAVE} /tensorboard --port=10000Hay más ejemplos de guiones de entrenamiento para reproducir los resultados de nuestro artículo en los ejemplos.
Una vez que se entrena el modelo, se utiliza el siguiente comando para evaluar la calidad de representación en las vistas de prueba dada {MODEL_PATH} .
python validate.py ${DATASET}
--user-dir fairnr
--valid-views " 200..400 "
--valid-view-resolution " 800x800 "
--no-preload
--task single_object_rendering
--max-sentences 1
--valid-view-per-batch 1
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01,"tensorboard_logdir":"","eval_lpips":True} ' Tenga en cuenta que anulamos raymarching_tolerance a 0.01 para permitir la terminación anticipada y acelerar el procesamiento.
La representación con punto de vista libre se puede lograr una vez que se entrena un modelo y se especifica una trayectoria de representación. Por ejemplo, el siguiente comando es para renderizar con una trayectoria circular (velocidad angular de 3 grados/cuadro, 15 cuadros por GPU). Esto genera imágenes renderizadas por vista y combina las imágenes en un video .mp4 en ${SAVE}/output de la siguiente manera:

De forma predeterminada, el código puede detectar todas las GPU disponibles.
python render.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01} '
--render-beam 1 --render-angular-speed 3 --render-num-frames 15
--render-save-fps 24
--render-resolution " 800x800 "
--render-path-style " circle "
--render-path-args " {'radius': 3, 'h': 2, 'axis': 'z', 't0': -2, 'r':-1} "
--render-output ${SAVE} /output
--render-output-types " color " " depth " " voxel " " normal " --render-combine-output
--log-format " simple " Nuestro código también admite el renderizado para determinadas poses de la cámara. Por ejemplo, el siguiente comando es para renderizar con las poses de la cámara definidas en los archivos 200-399 en la carpeta ${DATASET}/pose :
python render.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01} '
--render-save-fps 24
--render-resolution " 800x800 "
--render-camera-poses ${DATASET} /pose
--render-views " 200..400 "
--render-output ${SAVE} /output
--render-output-types " color " " depth " " voxel " " normal " --render-combine-output
--log-format " simple " El código también admite renderizado con poses de cámara definidas en un archivo .txt . Consulte este ejemplo.
También admitimos la ejecución de cubos de marcha para extraer las superficies iso como mallas triangulares de un modelo NSVF entrenado y guardarlas como {SAVE}/{NAME}.ply .
python extract.py
--user-dir fairnr
--path ${MODEL_PATH}
--output ${SAVE}
--name ${NAME}
--format ' mc_mesh '
--mc-threshold 0.5
--mc-num-samples-per-halfvoxel 5 También es posible exportar los vóxeles dispersos aprendidos configurando --format 'voxel_mesh' . El archivo .ply de salida se puede abrir con cualquier visor 3D como MeshLab.

NSVF tiene licencia del MIT. La licencia también se aplica a los modelos previamente entrenados.
Por favor cite como
@article { liu2020neural ,
title = { Neural Sparse Voxel Fields } ,
author = { Liu, Lingjie and Gu, Jiatao and Lin, Kyaw Zaw and Chua, Tat-Seng and Theobalt, Christian } ,
journal = { NeurIPS } ,
year = { 2020 }
}

