test arranger
v1.6.3
En TDD hay 3 fases: organizar, actuar y afirmar (dado, cuándo, luego en BDD). La fase de afirmación tiene un excelente soporte de herramientas; es posible que esté familiarizado con AssertJ, FEST-Assert o Hamcrest. Es en contraste con la fase de arreglo. Si bien organizar los datos de la prueba suele ser un desafío y una parte importante de la prueba generalmente se dedica a ello, es difícil señalar una herramienta que lo admita.
Test Arranger intenta llenar este vacío organizando instancias de clases requeridas para las pruebas. Las instancias están llenas de valores pseudoaleatorios que simplifican el proceso de creación de datos de prueba. El evaluador solo declara los tipos de objetos requeridos y obtiene instancias completamente nuevas. Cuando un valor pseudoaleatorio para un campo determinado no es lo suficientemente bueno, sólo se debe configurar este campo manualmente:
Product product = Arranger . some ( Product . class );
product . setBrand ( "Ocado" );< dependency >
< groupId >com.ocadotechnology.gembus</ groupId >
< artifactId >test-arranger</ artifactId >
< version >1.6.3</ version >
</ dependency >testImplementation ' com.ocadotechnology.gembus:test-arranger:1.6.3 ' La clase Arranger tiene varios métodos estáticos para generar valores pseudoaleatorios de tipos simples. Cada uno de ellos tiene una función de ajuste para simplificar las llamadas para Kotlin. Algunas de las posibles convocatorias se enumeran a continuación:
| Java | Kotlin | resultado |
|---|---|---|
Arranger.some(Product.class) | some<Product>() | una instancia de Producto con todos los campos llenos de valores |
Arranger.some(Product.class, "brand") | some<Product>("brand") | una instancia de Producto sin valor para el campo de marca |
Arranger.someSimplified(Category.class) | someSimplified<Category>() | una instancia de Categoría, los campos de la colección de tipos tienen un tamaño reducido a 1 y la profundidad del árbol de objetos está limitada a 3 |
Arranger.someObjects(Product.class, 7) | someObjects<Product>(7) | un flujo de tamaño 7 de instancias de Producto |
Arranger.someEmail() | someEmail() | una cadena que contiene la dirección de correo electrónico |
Arranger.someLong() | someLong() | un número pseudoaleatorio de tipo largo |
Arranger.someFrom(listOfCategories) | someFrom(listOfCategories) | una entrada de la lista de categorías |
Arranger.someText() | someText() | una cadena generada a partir de una Cadena de Markov; De forma predeterminada, es una cadena muy simple, pero se puede reconfigurar colocando otro archivo 'enMarkovChain' en el classpath de prueba con una definición alternativa; puede encontrar uno entrenado en un corpus en inglés aquí; consulte el archivo incluido en el proyecto 'enMarkovChain' para conocer el formato del archivo |
| - | some<Product> {name = "not so random"} | una instancia de Producto con todos los campos llenos de valores aleatorios excepto el name que está configurado como "no tan aleatorio", esta sintaxis se puede usar para configurar tantos campos del objeto como sea necesario, pero cada uno de los objetos debe ser mutable |
Es posible que los datos completamente aleatorios no sean adecuados para todos los casos de prueba. A menudo hay al menos un campo que es crucial para el objetivo de la prueba y necesita un valor determinado. Cuando la clase organizada es mutable, o es una clase de datos de Kotlin, o hay una manera de crear una copia alterada (por ejemplo, @Builder(toBuilder = true) de Lombok), simplemente use lo que esté disponible. Afortunadamente, incluso si no es ajustable, puedes usar Test Arranger. Existen versiones dedicadas de los métodos some() y someObjects() que aceptan un parámetro de tipo Map<String,Supplier> . Las claves en este mapa representan nombres de campos, mientras que los proveedores correspondientes entregan valores que Test Arranger establecerá para usted en esos campos, por ejemplo:
Product product = Arranger . some ( Product . class , Map . of ( "name" , () -> value ));De forma predeterminada, los valores aleatorios se generan según el tipo de campo. Los valores aleatorios no siempre se corresponden bien con las invariantes de clase. Cuando una entidad siempre necesita organizarse según algunas reglas relacionadas con los valores de los campos, puede proporcionar un organizador personalizado:
class ProductArranger extends CustomArranger < Product > {
@ Override
protected Product instance () {
Product product = enhancedRandom . nextObject ( Parent . class );
product . setPrice ( BigDecimal . valueOf ( Arranger . somePositiveLong ( 9_999L )));
return product ;
}
} Para tener control sobre el proceso de creación de instancias Product necesitamos anular el método instance() . Dentro del método podemos crear la instancia de Product como queramos. Específicamente, podemos generar algunos valores aleatorios. Para mayor comodidad, tenemos un campo enhancedRandom en la clase CustomArranger . En el ejemplo dado, generamos una instancia de Product con todos los campos con valores pseudoaleatorios, pero luego cambiamos el precio a algo aceptable en nuestro dominio. Eso no es negativo y es más pequeño que el número de 10k.
Arranger recoge automáticamente (mediante la reflexión) ProductArranger y lo utiliza cada vez que se solicita una nueva instancia de Product . No solo se refiere a llamadas directas como Arranger.some(Product.class) , sino también a las indirectas. Suponiendo que existe una clase Shop con products de campo de tipo List<Product> . Al llamar Arranger.some(Shop.class) , el arreglista utilizará ProductArranger para crear todos los productos almacenados en Shop.products .
El comportamiento del organizador de pruebas se puede configurar mediante propiedades. Si crea el archivo arranger.properties y lo guarda en la raíz del classpath (normalmente será el directorio src/test/resources/ ), se recogerá y se aplicarán las siguientes propiedades:
arranger.root Los arreglistas personalizados se seleccionan mediante reflexión. Todas las clases que amplían CustomArranger se consideran arreglistas personalizados. La reflexión se centra en un determinado paquete que por defecto es com.ocado . Eso no necesariamente es conveniente para usted. Sin embargo, con arranger.root=your_package se puede cambiar a your_package . Intente que el paquete sea lo más específico posible, ya que tener algo genérico (por ejemplo, solo com , que es el paquete raíz en muchas bibliotecas) resultará en escanear cientos de clases, lo que llevará un tiempo considerable.arranger.randomseed De forma predeterminada, siempre se utiliza la misma semilla para inicializar el generador de valores pseudoaleatorios subyacente. Como consecuencia, las ejecuciones posteriores generarán los mismos valores. Para lograr aleatoriedad entre ejecuciones, es decir, para comenzar siempre con otros valores aleatorios, es necesario configurar arranger.randomseed=true .arranger.cache.enable El proceso de organización de instancias aleatorias requiere algo de tiempo. Si crea una gran cantidad de instancias y no necesita que sean completamente aleatorias, habilitar el caché puede ser el camino a seguir. Cuando está habilitado, el caché almacena referencias a cada instancia aleatoria y, en algún momento, el organizador de pruebas deja de crear nuevas y, en su lugar, reutiliza las instancias almacenadas en caché. De forma predeterminada, el caché está deshabilitado.arranger.overridedefaults Test-arranger respeta la inicialización de campo predeterminada, es decir, cuando hay un campo inicializado con una cadena vacía, la instancia devuelta por test-arranger tiene la cadena vacía en este campo. No siempre es lo que necesitas en las pruebas, especialmente cuando existe una convención en el proyecto para inicializar campos con valores vacíos. Afortunadamente, puedes forzar a test-arranger a sobrescribir los valores predeterminados con valores aleatorios. Establezca arranger.overridedefaults en verdadero para anular la inicialización predeterminada.arranger.maxRandomizationDepth Algunas estructuras de datos de prueba pueden generar cadenas de objetos de cualquier longitud que hacen referencia entre sí. Sin embargo, para utilizarlas eficazmente en un caso de prueba, es fundamental controlar la longitud de estas cadenas. De forma predeterminada, Test-arranger deja de crear nuevos objetos en el cuarto nivel de profundidad de anidamiento. Si esta configuración predeterminada no se adapta a los casos de prueba de su proyecto, se puede ajustar utilizando este parámetro. Cuando tiene un registro Java que podría usarse como datos de prueba, pero necesita cambiar uno o dos de sus campos, la clase Data con su método de copia proporciona una solución. Esto es particularmente útil cuando se trata de registros inmutables que no tienen una forma obvia de modificar sus campos directamente.
El método Data.copy le permite crear una copia superficial de un registro mientras modifica selectivamente los campos deseados. Al proporcionar un mapa de anulaciones de campos, puede especificar los campos que deben modificarse y sus nuevos valores. El método de copia se encarga de crear una nueva instancia del registro con los valores de campo actualizados.
Este enfoque le evita crear manualmente un nuevo objeto de registro y configurar los campos individualmente, lo que proporciona una manera conveniente de generar datos de prueba con ligeras variaciones de los registros existentes.
En general, la clase Datos y su método de copia rescatan la situación al permitir la creación de copias superficiales de registros con campos seleccionados alterados, lo que brinda flexibilidad y conveniencia al trabajar con tipos de registros inmutables:
Data . copy ( myRecord , Map . of ( "recordFieldName" , () -> "altered value" ));Al realizar pruebas de un proyecto de software, rara vez uno tiene la impresión de que no se puede hacer mejor. En el ámbito de la organización de datos de prueba, hay dos áreas que estamos tratando de mejorar con Test Arranger.
Las pruebas son mucho más fáciles de entender cuando se conoce la intención del creador, es decir, por qué se escribió la prueba y qué tipo de problemas debería detectar. Desafortunadamente, no es extraordinario ver pruebas que tengan en la sección de organización (dada) declaraciones como la siguiente:
Product product = Product . builder ()
. withName ( "Some name" )
. withBrand ( "Some brand" )
. withPrice ( new BigDecimal ( "12.99" ))
. withCategory ( "Water, Juice & Drinks / Juice / Fresh" )
...
. build ();Al observar dicho código, es difícil decir qué valores son relevantes para la prueba y cuáles se proporcionan únicamente para satisfacer algunos requisitos no nulos. Si la prueba es sobre la marca, ¿por qué no escribirla así?
Product product = Arranger . some ( Product . class );
product . setBrand ( "Some brand" );Ahora es obvio que la marca es importante. Intentemos dar un paso más. Toda la prueba puede verse de la siguiente manera:
//arrange
Product product = Arranger . some ( Product . class );
product . setBrand ( "Some brand" );
//act
Report actualReport = sut . createBrandReport ( Collections . singletonList ( product ))
//assert
assertThat ( actualReport . getBrand ). isEqualTo ( "Some brand" ) Estamos probando ahora que el informe se creó para la marca "Algunas marcas". ¿Pero es ese el objetivo? Tiene más sentido esperar que el informe se genere para la misma marca a la que está asignado el producto determinado. Entonces lo que queremos probar es:
//arrange
Product product = Arranger . some ( Product . class );
//act
Report actualReport = sut . createBrandReport ( Collections . singletonList ( product ))
//assert
assertThat ( actualReport . getBrand ). isEqualTo ( product . getBrand ()) En caso de que el campo marca sea mutable y tengamos miedo de que sut pueda modificarlo, podemos almacenar su valor en una variable antes de pasar a la fase de acción y luego usarlo para la afirmación. La prueba será más larga, pero la intención sigue siendo clara.
Cabe destacar que lo que acabamos de hacer es una aplicación de los patrones de valor generado y, hasta cierto punto, del método de creación descritos en Patrones de prueba xUnit: código de prueba de refactorización de Gerard Meszaros.
¿Alguna vez has cambiado algo pequeño en el código de producción y terminaste con errores en docenas de pruebas? Algunos de ellos reportan afirmaciones fallidas, otros tal vez incluso se niegan a compilar. Este es un olor a código de cirugía de escopeta que acaba de disparar a tus pruebas inocentes. Bueno, tal vez no sean tan inocentes como para diseñarlos de manera diferente, para limitar el daño colateral causado por pequeños cambios. Analicémoslo con un ejemplo. Supongamos que tenemos en nuestro dominio la siguiente clase:
class TimeRange {
private LocalDateTime start ;
private long durationinMs ;
public TimeRange ( LocalDateTime start , long durationInMs ) {
... y que se utiliza en muchos lugares. Especialmente en las pruebas, sin Test Arranger, usando declaraciones como esta: new TimeRange(LocalDateTime.now(), 3600_000L); ¿Qué pasará si por algunas razones importantes nos vemos obligados a cambiar la clase a:
class TimeRange {
private LocalDateTime start ;
private LocalDateTime end ;
public TimeRange ( LocalDateTime start , LocalDateTime end ) {
... Es todo un desafío idear una serie de refactorizaciones que transformen la versión anterior en una nueva sin romper todas las pruebas dependientes. Lo más probable es un escenario en el que las pruebas se ajusten a la nueva API de la clase una por una. Esto significa mucho trabajo no exactamente emocionante con muchas preguntas sobre el valor deseado de duración (¿debería convertirlo cuidadosamente al end del tipo LocalDateTime o era simplemente un valor aleatorio conveniente)? La vida sería mucho más fácil con Test Arranger. Cuando en todos los lugares que requieren TimeRange simplemente no nulo tenemos Arranger.some(TimeRange.class) , es tan bueno para la nueva versión de TimeRange como lo fue para la anterior. Eso nos deja con esos pocos casos que no requieren TimeRange aleatorio, pero como ya usamos Test Arranger para revelar la intención de la prueba, en cada caso sabemos exactamente qué valor se debe usar para TimeRange .
Pero eso no es todo lo que podemos hacer para mejorar las pruebas. Presumiblemente, podemos identificar algunas categorías de la instancia TimeRange , por ejemplo, rangos del pasado, rangos del futuro y rangos actualmente activos. TimeRangeArranger es un excelente lugar para organizar eso:
class TimeRangeArranger extends CustomArranger < TimeRange > {
private final long MAX_DISTANCE = 999_999L ;
@ Override
protected TimeRange instance () {
LocalDateTime start = enhancedRandom . nextObject ( LocalDateTime . class );
LocalDateTime end = start . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( start , end );
}
public TimeRange fromPast () {
LocalDateTime now = LocalDateTime . now ();
LocalDateTime end = now . minusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( end . minusHours ( Arranger . somePositiveLong ( MAX_DISTANCE )), end );
}
public TimeRange fromFuture () {
LocalDateTime now = LocalDateTime . now ();
LocalDateTime start = now . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( start , start . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE )));
}
public TimeRange currentlyActive () {
LocalDateTime now = LocalDateTime . now ();
LocalDateTime start = now . minusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
LocalDateTime end = now . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( start , end );
}
} Un método de creación de este tipo no debe crearse por adelantado, sino corresponder con casos de prueba existentes. No obstante, existen posibilidades de que TimeRangeArranger cubra todos los casos en los que se crean instancias de TimeRange para pruebas. Como consecuencia, en lugar de llamadas al constructor con varios parámetros misteriosos, tenemos un arreglador con un método bien nombrado que explica el significado de dominio del objeto creado y ayuda a comprender la intención de la prueba.
Identificamos dos niveles de creadores de datos de prueba cuando analizamos los desafíos resueltos por Test Arranger. Para completar la imagen necesitamos mencionar al menos uno más, es decir, los Calendarios. Por el bien de esta discusión, podemos asumir que Fixtura es una clase diseñada para crear estructuras complejas de datos de prueba. El arreglador personalizado siempre se centra en una clase, pero a veces puedes observar en tus casos de prueba constelaciones recurrentes de dos o más clases. Puede ser el Usuario y su cuenta bancaria. Puede haber un CustomArranger para cada uno de ellos, pero ¿por qué ignorar el hecho de que a menudo se juntan? Aquí es cuando deberíamos empezar a pensar en un Accesorio. Será responsable de crear tanto el Usuario como la cuenta bancaria (presumiblemente utilizando organizadores personalizados dedicados) y vincularlos. Los accesorios se describen en detalle, incluidas varias variantes de implementación en xUnit Test Patterns: Refactoring Test Code de Gerard Meszaros.
Entonces tenemos tres tipos de bloques de construcción en las clases de prueba. Cada uno de ellos puede considerarse como la contraparte de un concepto (bloque de construcción de Domain Driven Design) del código de producción: 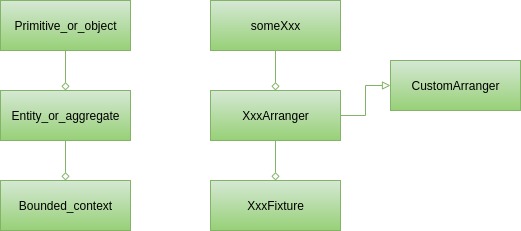
En la superficie hay objetos primitivos y simples. Eso es algo que aparece incluso en las pruebas unitarias más simples. Puede cubrir la organización de dichos datos de prueba con los métodos someXxx de la clase Arranger .
Por lo tanto, es posible que tenga servicios que requieran pruebas que funcionen únicamente en instancias User o tanto en User como en otras clases contenidas en la clase User , como una lista de direcciones. Para cubrir estos casos, normalmente se requiere un arreglador personalizado, es decir, UserArranger . Creará instancias de User respetando todas las restricciones e invariantes de clase. Además, seleccionará AddressArranger , cuando exista, para completar la lista de direcciones con datos válidos. Cuando varios casos de prueba requieren un determinado tipo de usuario, por ejemplo, usuarios sin hogar con una lista de direcciones vacía, se puede crear un método adicional en UserArranger. Como consecuencia, siempre que sea necesario crear una instancia User para las pruebas, será suficiente buscar en UserArranger y seleccionar un método de fábrica adecuado o simplemente llamar Arranger.some(User.class) .
El caso más desafiante se refiere a las pruebas que dependen de grandes estructuras de datos. En el comercio electrónico, podría ser una tienda que contenga muchos productos, pero también cuentas de usuario con historial de compras. Organizar datos para tales casos de prueba no suele ser trivial y repetir algo así no sería prudente. Es mucho mejor almacenarlo en una clase dedicada bajo un método bien nombrado, como shopWithNineProductsAndFourCustomers , y reutilizarlo en cada una de las pruebas. Recomendamos encarecidamente utilizar una convención de nomenclatura para dichas clases; para que sean fáciles de encontrar, nuestra sugerencia es utilizar Fixture postfix. Al final, podemos terminar con algo como esto:
class ShopFixture {
Repository repo ;
public void shopWithNineProductsAndFourCustomers () {
Arranger . someObjects ( Product . class , 9 )
. forEach ( p -> repo . save ( p ));
Arranger . someObjects ( Customer . class , 4 )
. forEach ( p -> repo . save ( p ));
}
}La versión más reciente del organizador de pruebas se compila con Java 17 y debe usarse en el tiempo de ejecución de Java 17+. Sin embargo, también existe una rama de Java 8 para compatibilidad con versiones anteriores, cubierta con las versiones 1.4.x.


