This template can be used for both Azure AI Studio and Azure Machine Learning.It can be used for both AZURE and LOCAL execution.It supports all types of flow - python Class flows, Function flows and YAML flows.It supports Github, Azure DevOps and Jenkins CI/CD orchestration.It supports pure python based Evaluation as well using promptflow-evals package.It should be used for INNER-LOOP Experimentation and Evaluation.It should be used for OUTER-LOOP Deployment and Inferencing. NOTE: A new FAQ section is added to help Engineers, Data Scientist and developers find answers to general questions on configuring and using this template.
PREGUNTAS FRECUENTES AQUÍ
Large Language Model Operations, o LLMOps, se ha convertido en la piedra angular de la ingeniería rápida eficiente y el desarrollo e implementación de aplicaciones inducidas por LLM. A medida que la demanda de aplicaciones inducidas por LLM continúa aumentando, las organizaciones necesitan un proceso coherente y optimizado para gestionar su ciclo de vida de un extremo a otro.
El auge de la IA y los grandes modelos de lenguaje (LLM) ha transformado varias industrias, permitiendo el desarrollo de aplicaciones innovadoras con capacidades de generación y comprensión de texto similares a las humanas. Esta revolución ha abierto nuevas posibilidades en campos como el servicio al cliente, la creación de contenido y el análisis de datos.
A medida que los LLM evolucionan rápidamente, la importancia de la ingeniería rápida se vuelve cada vez más evidente. Prompt Engineering desempeña un papel crucial a la hora de aprovechar todo el potencial de los LLM mediante la creación de indicaciones efectivas que se adaptan a escenarios comerciales específicos. Este proceso permite a los desarrolladores crear soluciones de IA personalizadas, haciendo que la IA sea más accesible y útil para una audiencia más amplia.
Es un marco de experimentación y evaluación para Prompt Flow. Simplemente no son canalizaciones de CI/CD para Prompt Flow, aunque lo admiten. Tiene un amplio conjunto de características para la experimentación, evaluación, implementación y monitoreo de Prompt Flow. Es una solución completa de extremo a extremo para la operacionalización de Prompt Flow.
La plantilla es compatible tanto con Azure AI Studio como con Azure Machine Learning. Según la configuración, la plantilla se puede usar tanto para Azure AI Studio como para Azure Machine Learning. Proporciona una experiencia de migración perfecta para la experimentación, evaluación e implementación de Prompt Flow en todos los servicios.
Esta plantilla admite diferentes tipos de flujos, lo que le permite definir y ejecutar flujos de trabajo según sus requisitos específicos. Los dos tipos de flujo principales admitidos son:
Flujos flexibles
Flujos de gráficos acíclicos dirigidos (DAG)
Una de las características poderosas de este proyecto es su capacidad para detectar automáticamente el tipo de flujo y ejecutarlo en consecuencia. Esto le permite experimentar con diferentes tipos de flujo y elegir el que mejor se adapte a sus necesidades.
Esta plantilla admite:
La gestión de flujos basados en lenguajes grandes, desde la experimentación local hasta la implementación de producción, no ha sido nada sencilla y no es una tarea única para todos.
Cada flujo tiene su ciclo de vida único, desde la experimentación inicial hasta el despliegue, y cada etapa presenta su propio conjunto de desafíos.
Las organizaciones suelen lidiar con múltiples flujos al mismo tiempo, cada uno con sus objetivos, requisitos y complejidades. Esto puede volverse abrumador rápidamente sin las herramientas de gestión adecuadas.
Implica manejar múltiples flujos, sus ciclos de vida únicos, experimentar con varias configuraciones y garantizar implementaciones sin problemas.
Ahí es donde entra en juego LLMOps con flujo rápido . LLMOps con flujo rápido es una "plantilla y guía de LLMOps" para ayudarlo a crear aplicaciones con LLM utilizando el flujo rápido. Proporciona las siguientes características:
Alojamiento de código centralizado: este repositorio admite código de alojamiento para múltiples flujos según el flujo de solicitud, lo que proporciona un repositorio único para todos sus flujos. Piense en esta plataforma como un repositorio único donde reside todo el código de flujo de mensajes. Es como una biblioteca para sus flujos, lo que facilita la búsqueda, el acceso y la colaboración en diferentes proyectos.
Gestión del ciclo de vida: cada flujo disfruta de su propio ciclo de vida, lo que permite transiciones fluidas desde la experimentación local hasta la implementación de producción.
Experimentación de variantes e hiperparámetros: experimente con múltiples variantes e hiperparámetros, evaluando variantes de flujo con facilidad. Las variantes y los hiperparámetros son como ingredientes de una receta. Esta plataforma le permite experimentar con diferentes combinaciones de variantes en múltiples nodos de un flujo.
Implementación A/B: implemente implementaciones A/B sin problemas, lo que le permitirá comparar diferentes versiones de flujo sin esfuerzo. Al igual que en las pruebas A/B tradicionales para sitios web, esta plataforma facilita la implementación A/B para flujos rápidos. Esto significa que puede comparar sin esfuerzo diferentes versiones de un flujo en un entorno del mundo real para determinar cuál funciona mejor.
Relaciones de flujo/conjunto de datos de muchos a muchos: acomode múltiples conjuntos de datos para cada estándar y flujo de evaluación, lo que garantiza versatilidad en las pruebas y evaluaciones de flujo. La plataforma está diseñada para acomodar múltiples conjuntos de datos para cada flujo.
Múltiples objetivos de implementación: el repositorio admite la implementación de flujos en computadoras administradas de Kubernetes y Azure impulsadas a través de la configuración, lo que garantiza que sus flujos puedan escalar según sea necesario.
Informes completos: genere informes detallados para cada configuración variante, lo que le permitirá tomar decisiones informadas. Proporciona una recopilación de métricas detallada para todos los experimentos y ejecuciones masivas de variantes, lo que permite tomar decisiones basadas en datos en archivos csv y HTML.
Ofrece BYOF (traiga sus propios flujos). Una plataforma completa para desarrollar múltiples casos de uso relacionados con aplicaciones de LLM.
Ofrece desarrollo basado en configuración . No es necesario escribir un código repetitivo extenso.
Proporciona ejecución de experimentación y evaluación rápidas localmente y en la nube.
Proporciona cuadernos para la evaluación local de las indicaciones. Proporciona una biblioteca de funciones para la experimentación local.
Pruebas de endpoints dentro del proceso después de la implementación para verificar su disponibilidad y preparación.
Proporciona Human-in-loop opcional para validar las métricas de aviso antes de la implementación.
LLMOps con flujo rápido proporciona capacidades para aplicaciones LLM tanto simples como complejas. Es completamente personalizable a las necesidades de la aplicación.
Cada caso de uso (conjunto de flujos estándar de flujo de aviso y flujos de evaluación) debe seguir la estructura de carpetas como se muestra aquí:
Además, hay un archivo experiment.yaml que configura el caso de uso (consulte la descripción del archivo y las especificaciones para obtener más detalles). También hay un archivo sample-request.json que contiene datos de prueba para probar los puntos finales después de la implementación.
La carpeta '.azure-pipelines' contiene las canalizaciones comunes de Azure DevOps para la plataforma y cualquier cambio en ellas afectará la ejecución de todos los flujos.
La carpeta '.github' contiene los flujos de trabajo de Github para la plataforma, así como los casos de uso. Esto es un poco diferente a Azure DevOps porque todos los flujos de trabajo de Github deben estar dentro de esta única carpeta para su ejecución.
La carpeta '.jenkins' contiene los canales declarativos de Jenkins para la plataforma, así como los casos de uso y trabajos individuales.
La carpeta 'docs' contiene documentación para guías paso a paso para la configuración relacionada con Azure DevOps, Github Workflow y Jenkins.
La carpeta 'llmops' contiene todo el código relacionado con la ejecución, evaluación e implementación del flujo.
La carpeta 'dataops' contiene todo el código relacionado con la implementación de la canalización de datos.
La carpeta 'local_execution' contiene scripts de Python para ejecutar localmente el flujo estándar y de evaluación.
El proyecto incluye 6 ejemplos que demuestran diferentes escenarios:
Ubicación: ./web_classification Importancia: demuestra el resumen del contenido del sitio web con múltiples variantes, mostrando la flexibilidad y las opciones de personalización disponibles en la plantilla.
Ubicación: ./named_entity_recognition Importancia: muestra la extracción de entidades nombradas del texto, lo cual es valioso para diversas tareas de procesamiento del lenguaje natural y extracción de información.
Ubicación: ./math_coding Importancia: muestra la capacidad de realizar cálculos matemáticos y generar fragmentos de código, destacando la versatilidad de la plantilla en el manejo de tareas computacionales.
Ubicación: ./chat_with_pdf Importancia: muestra una interfaz conversacional para interactuar con documentos PDF, aprovechando el poder de la generación aumentada de recuperación (RAG) para proporcionar respuestas precisas y relevantes.
Ubicación: ./function_flows Importancia: demuestra la generación de fragmentos de código basados en indicaciones del usuario, mostrando el potencial para automatizar las tareas de generación de código.
Ubicación: ./class_flows Importancia: muestra una aplicación de chat creada utilizando flujos basados en clases, que ilustra la estructuración y organización de interfaces conversacionales más complejas.
El repositorio ayuda a implementar en Kubernetes, Kubernetes ARC, Azure Web Apps y el proceso administrado de AzureML junto con la implementación A/B para el proceso administrado de AzureML.
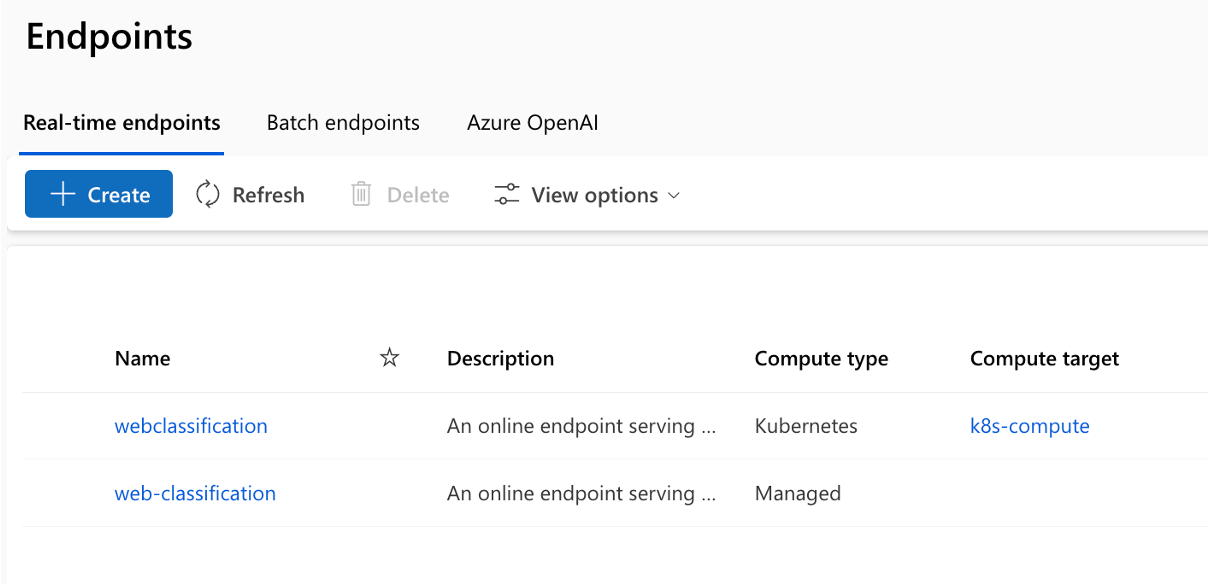
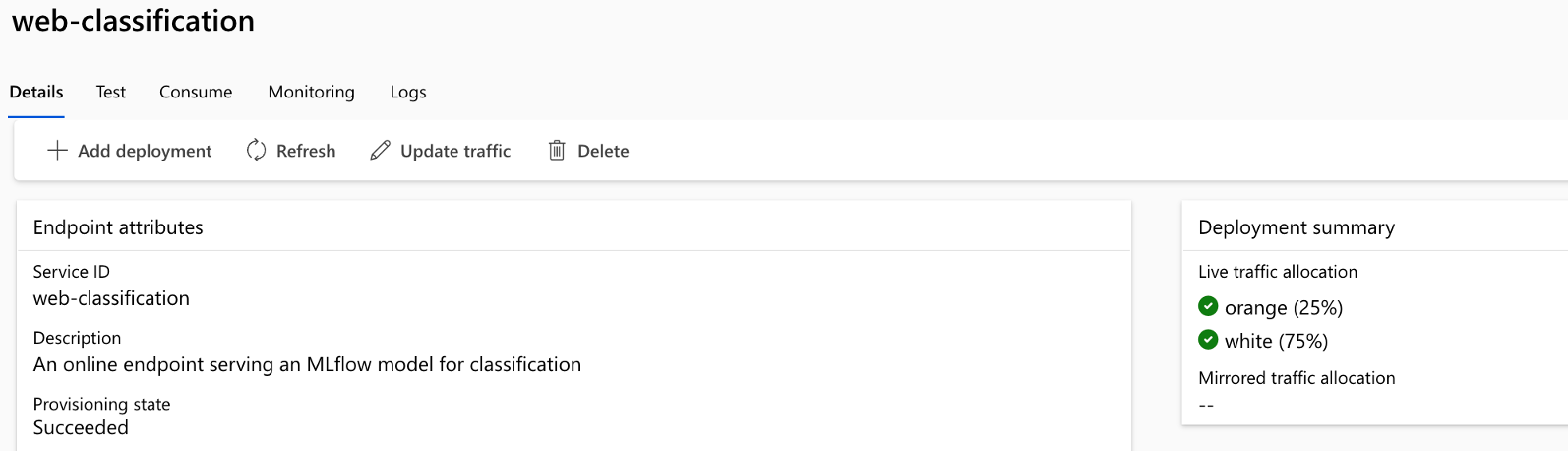
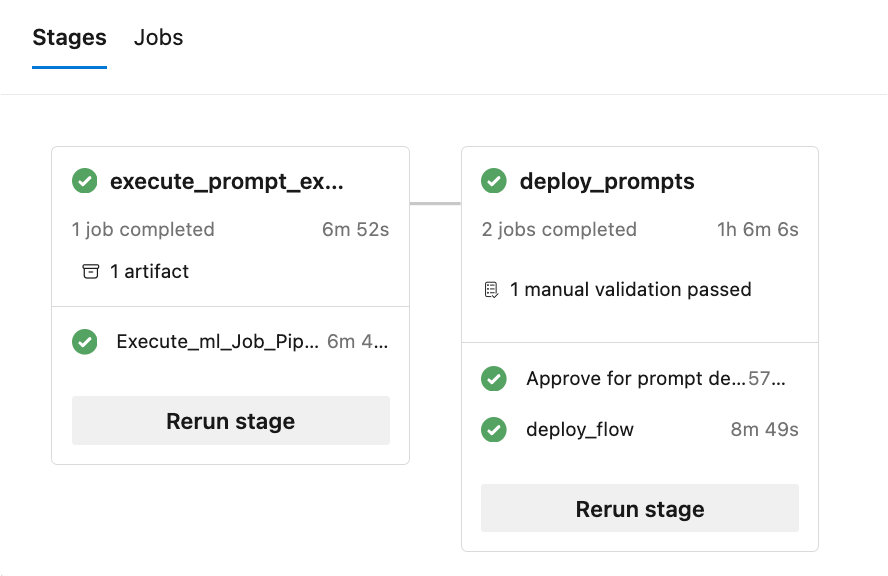
La ejecución del pipeline consta de múltiples etapas y trabajos en cada etapa:
El repositorio genera múltiples informes (se muestran ejemplos de ejecuciones de experimentos y métricas):


Para aprovechar las capacidades de la ejecución local , siga estos pasos de instalación:
git clone https://github.com/microsoft/llmops-promptflow-template.gitaoai . Agregue una línea aoai={"api_key": "","api_base": "","api_type": "azure","api_version": "2023-03-15-preview"} con valores actualizados para api_key y api_base. Si se utilizan conexiones adicionales con nombres diferentes en sus flujos, deben agregarse en consecuencia. Actualmente, fluya con AzureOpenAI como proveedor según sea compatible. experiment_name=
connection_name_1={ " api_key " : " " , " api_base " : " " , " api_type " : " azure " , " api_version " : " 2023-03-15-preview " }
connection_name_2={ " api_key " : " " , " api_base " : " " , " api_type " : " azure " , " api_version " : " 2023-03-15-preview " }python -m pip install promptflow promptflow-tools promptflow-sdk jinja2 promptflow[azure] openai promptflow-sdk[builtins] python-dotenv
Traiga o escriba sus flujos en la plantilla según la documentación aquí.
Escriba scripts de Python similares a los ejemplos proporcionados en la carpeta local_execution.
DataOps combina aspectos de DevOps, metodologías ágiles y prácticas de gestión de datos para agilizar el proceso de recopilación, procesamiento y análisis de datos. DataOps puede ayudar a aportar disciplina en la creación de conjuntos de datos (capacitación, experimentación, evaluación, etc.) necesarios para el desarrollo de aplicaciones LLM.
Las canalizaciones de datos se mantienen separadas de los flujos de ingeniería rápidos. Las canalizaciones de datos crean los conjuntos de datos y los conjuntos de datos se registran como activos de datos en Azure ML para que los consuman los flujos. Este enfoque ayuda a escalar y solucionar problemas de forma independiente en diferentes partes del sistema.
Para obtener detalles sobre cómo comenzar con DataOps, siga este documento: Cómo configurar DataOps.
Este proyecto agradece contribuciones y sugerencias. La mayoría de las contribuciones requieren que usted acepte un Acuerdo de licencia de colaborador (CLA) que declara que tiene derecho a otorgarnos, y de hecho lo hace, los derechos para usar su contribución. Para obtener más detalles, visite https://cla.opensource.microsoft.com.
Cuando envía una solicitud de extracción, un bot CLA determinará automáticamente si necesita proporcionar un CLA y decorar el PR de manera adecuada (por ejemplo, verificación de estado, comentario). Simplemente siga las instrucciones proporcionadas por el bot. Solo necesitarás hacer esto una vez en todos los repositorios que utilicen nuestro CLA.
Este proyecto ha adoptado el Código de conducta de código abierto de Microsoft. Para obtener más información, consulte las preguntas frecuentes sobre el Código de conducta o comuníquese con [email protected] si tiene alguna pregunta o comentario adicional.
Este proyecto puede contener marcas comerciales o logotipos de proyectos, productos o servicios. El uso autorizado de las marcas comerciales o logotipos de Microsoft está sujeto y debe seguir las Pautas de marcas y marcas comerciales de Microsoft. El uso de marcas comerciales o logotipos de Microsoft en versiones modificadas de este proyecto no debe causar confusión ni implicar patrocinio de Microsoft. Cualquier uso de marcas comerciales o logotipos de terceros está sujeto a las políticas de dichos terceros.
Este proyecto ha adoptado el Código de conducta de código abierto de Microsoft. Para obtener más información, consulte las preguntas frecuentes sobre el Código de conducta o comuníquese con [email protected] si tiene alguna pregunta o comentario adicional.
Copyright (c) Microsoft Corporation. Reservados todos los derechos.
Licenciado bajo la licencia MIT.


