El diseño de tablas acumulativas es una herramienta de ingeniería de datos extremadamente poderosa que todos los ingenieros de datos deberían conocer.
Este diseño produce tablas que pueden proporcionar análisis eficientes en períodos de tiempo arbitrariamente grandes (hasta miles de días).
A continuación se muestra un diagrama del diseño de canalización de alto nivel para este patrón:
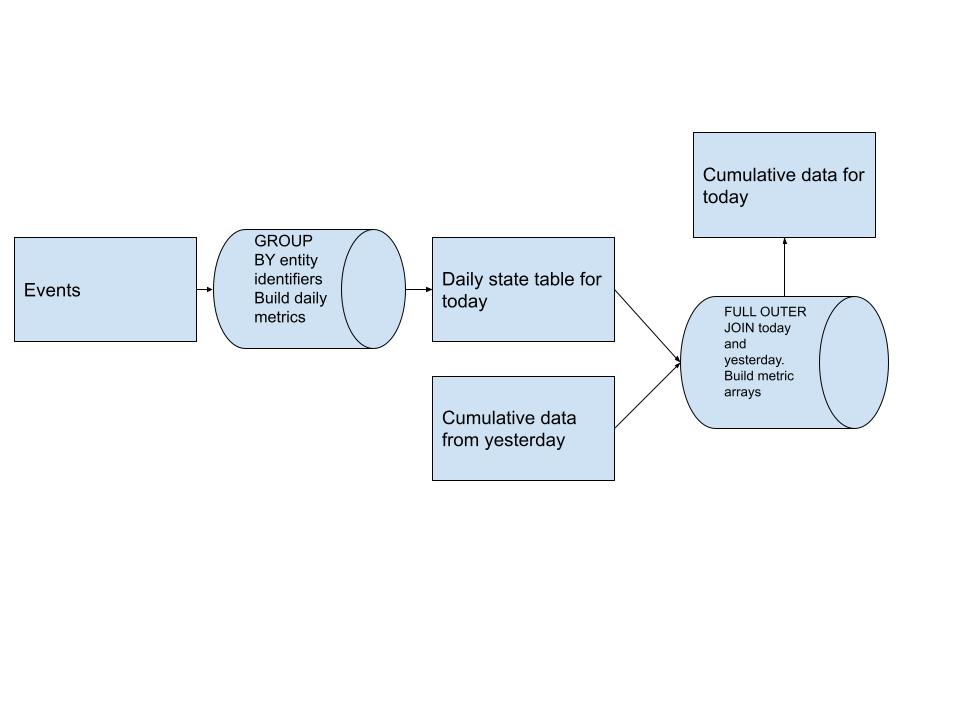
Inicialmente construimos nuestra tabla de métricas diarias que está en la esencia de cualquiera que sea nuestra entidad. Estos datos se derivan de cualquier fuente de eventos que tengamos en sentido ascendente.
Después de tener nuestras métricas diarias, FULL OUTER JOIN la tabla acumulativa de ayer con los datos diarios de hoy y creamos nuestras matrices de métricas para cada usuario. Esto nos permite incorporar el nuevo historial sin tener que escanearlo todo. (un gran aumento de rendimiento)
Estas matrices de métricas nos permiten responder fácilmente consultas sobre el historial de todos los usuarios usando cosas como ARRAY_SUM para calcular cualquier métrica que queramos en cualquier período de tiempo que permita la matriz.
¡¡Cuanto más largo sea el período de su análisis, más crítico se vuelve este patrón!!
Toda la sintaxis de consulta utiliza la sintaxis y funciones de Presto/Trino. ¡Este ejemplo debería modificarse para otras variantes de SQL!
Usaremos las fechas:
- 2022-01-01 como hoy en términos de flujo de aire, esto es
{{ ds }}- 2021-12-31 como ayer en términos de plantillas de Airflow, esto es
{{ yesterday_ds}}
En este ejemplo, veremos cómo crear este diseño para calcular los usuarios activos diarios, semanales y mensuales, así como los me gusta, los comentarios y las acciones de los usuarios.
Nuestra tabla fuente en este caso es events .
event_type que es like , comment , share o viewEs tentador pensar que la solución a esto es ejecutar una canalización similar a
SELECT
COUNT(DISTINCT user_id) as num_monthly_active_users,
COUNT(CASE WHEN event_type = 'like' THEN 1 END) as num_likes_30d,
COUNT(CASE WHEN event_type = 'comment' THEN 1 END) as num_comments_30d,
COUNT(CASE WHEN event_type = 'share' THEN 1 END) as num_shares_30d,
...
FROM events
WHERE event_date BETWEEN DATE_SUB('2022-01-01', 30), AND '2022-01-01'
El problema con esto es que estamos escaneando 30 días de datos de eventos todos los días para producir estos números. Una tubería bastante derrochadora, pero simple. Debería haber una manera en la que solo tengamos que escanear los datos del evento una vez y combinarlos con los resultados de los 29 días anteriores, ¿verdad? ¿Podemos crear una estructura de datos donde un científico de datos pueda consultar nuestros datos y saber fácilmente la cantidad de acciones que realizó un usuario en los últimos N días?
Este diseño es bastante simple con solo 3 pasos:
GROUP BY user_id y luego cuéntelos como activos diarios si tienen algún eventoCOUNT(CASE WHEN event_type = 'like' THEN 1 END) para calcular también la cantidad de me gusta, comentarios y acciones compartidas diarias.FULL OUTER JOIN estos dos conjuntos de datos en today.user_id = yesterday.user_idCOALESCE(today.user_id, yesterday.user_id) as user_id para realizar un seguimiento de todos los usuarios.activity_array . Solo queremos que activity_array almacene los datos de los últimos 30 días.CARDINALITY(activity_array) < 30 para entender si podemos simplemente agregar el valor de hoy al frente de la matriz o si necesitamos cortar un elemento del final de la matriz antes de agregar el valor de hoy al frente.COALESCE(t.is_active_today, 0) para poner valores cero en la matriz cuando un usuario no está activoactivity_array ¡pero también para Me gusta, comentarios y recursos compartidos!CASE WHEN ARRAY_SUM(activity_array) > 0 THEN 1 ELSE 0 END nos da activos mensuales ya que limitamos el tamaño de la matriz a 30CASE WHEN ARRAY_SUM(SLICE(activity_array, 1, 7)) > 0 THEN 1 ELSE 0 END nos da actividad semanal ya que solo verificamos los primeros 7 elementos de la matriz (es decir, los últimos 7 días)ARRAY_SUM(SLICE(like_array, 1, 7)) as num_likes_7d nos da la cantidad de Me gusta que hizo este usuario en los últimos 7 díasARRAY_SUM(like_array) as num_likes_30d nos da la cantidad de Me gusta que hizo este usuario en los últimos 30 días desde que la matriz se fijó en ese tamaño.depends_on_past: True

