nmt
1.0.0
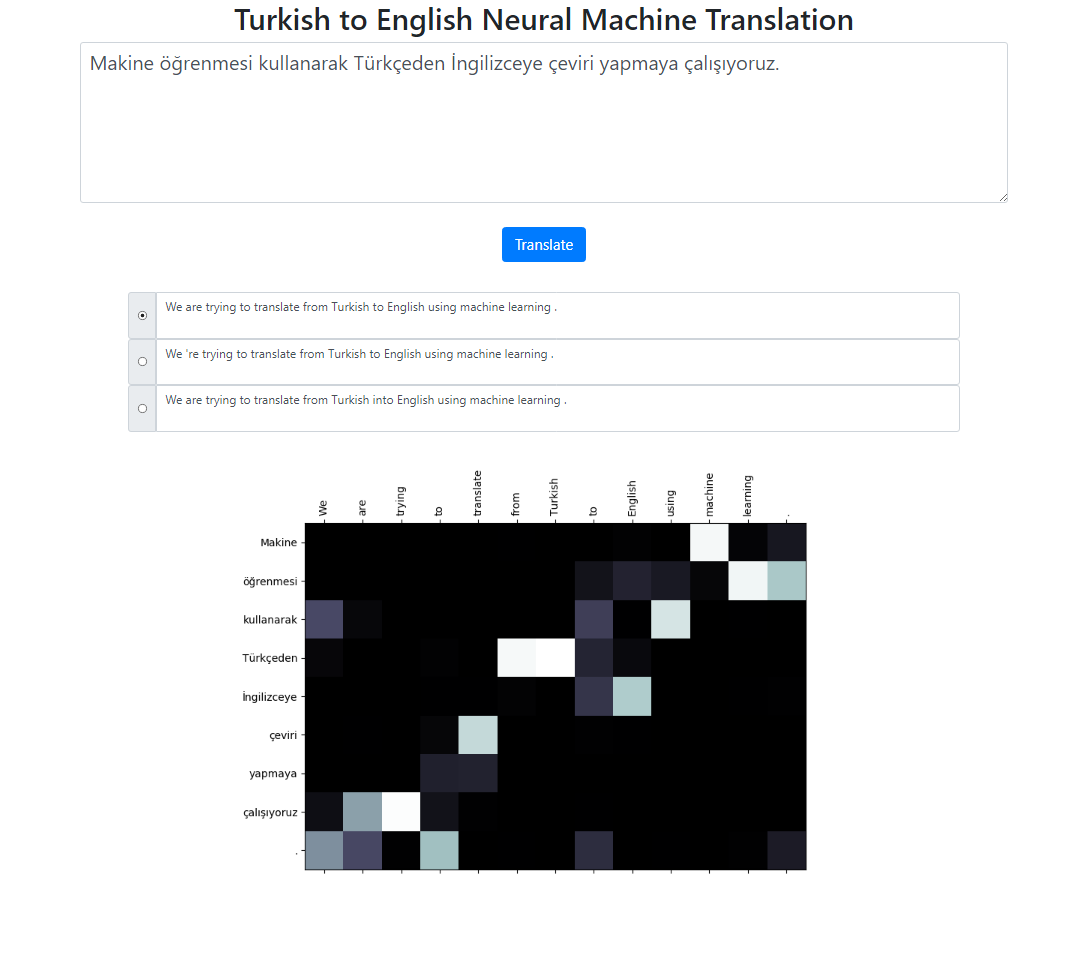
Este repositorio implementa un sistema de traducción automática neuronal del turco al inglés utilizando el modelo Seq2Seq + Global Attention. También hay una aplicación Flask que puedes ejecutar localmente. Puede ingresar el texto, traducir e inspeccionar los resultados, así como la visualización de la atención. Ejecutamos una búsqueda de haz con un tamaño de haz 3 en segundo plano y devolvemos las secuencias más probables ordenadas por su puntuación relativa.
El conjunto de datos para este proyecto se toma de aquí. He utilizado el corpus de Tatoeba. He eliminado algunos de los duplicados encontrados en los datos. También pretokenicé el conjunto de datos. La versión finalizada se puede encontrar en la carpeta de datos.
Para tokenizar las oraciones turcas, he usado RegexpTokenizer de nltk.
puncts_except_apostrophe = '!"#$%&()*+,-./:;<=>?@[]^_`{|}~'TOKENIZE_PATTERN = fr"[{puncts_except_apostrophe}]|w+|['w ]+"regex_tokenizer = RegexpTokenizer(pattern=TOKENIZE_PATTERN)text = "Titanic 15 Nisan pazartesi saat 02:20'de battı."tokenized_text = regex_tokenizer.tokenize(text)print(" ".join(tokenized_text))# Salida: Titanic 15 Nisan pazartesi saat 02: 20 'de battı .# Esta propiedad de división en "02: 20 " es diferente del tokenizador inglés.# Podríamos manejar esas situaciones. Pero quería mantenerlo simple y ver si # la distribución de la atención en esas palabras se alinea con los tokens en inglés.# Hay casos similares principalmente en fechas, como en este ejemplo: 09/02/2019Para tokenizar las oraciones en inglés, he usado el modelo en inglés de spacy.
en_nlp = spacy.load('en_core_web_sm')text = "El Titanic se hundió a las 02:20 del lunes 15 de abril."tokenized_text = en_nlp.tokenizer(text)print(" ".join([tok.text para tok en tokenized_text ]))# Salida: El Titanic se hundió a las 02:20 del lunes 15 de abril.Se espera que las oraciones en turco e inglés estén en dos archivos diferentes.
file: train.tr tr_sent_1 tr_sent_2 tr_sent_3 ... file: train.en en_sent_1 en_sent_2 en_sent_3 ...
Ejecute python train.py -h para obtener la lista completa de argumentos.
Sample usage: python train.py --train_data train.tr train.en --valid_data valid.tr valid.en --n_epochs 30 --batch_size 32 --embedding_dim 256 --hidden_size 256 --num_layers 2 --bidirectional --dropout_p 0.3 --device cuda
Calcular la puntuación azul del nivel de corpus.
usage: test.py [-h] --model_file MODEL_FILE --valid_data VALID_DATA [VALID_DATA ...] Neural Machine Translation Testing optional arguments: -h, --help show this help message and exit --model_file MODEL_FILE Model File --valid_data VALID_DATA [VALID_DATA ...] Validation_data Sample Usage: python test.py --model_file model.bin --validation_data valid.tr valid.en
Para ejecutar la aplicación localmente, ejecute:
python app.py
Asegúrese de que las rutas de su modelo en el archivo config.py estén definidas correctamente.
Archivo de modelo
archivo de vocabulario
Usar unidades de subpalabras (tanto para turco como para inglés)
Diferentes mecanismos de atención (aprendizaje de diferentes parámetros de atención)
El código esqueleto para este proyecto está tomado del curso de PNL de Stanford: CS224n


