hercules
v10.7.2
Análisis del historial de Git rápido, revelador y altamente personalizable.
Descripción general • Cómo utilizar • Instalación • Contribuciones • Licencia
Hercules es un motor de análisis de repositorios Git increíblemente rápido y altamente personalizable escrito en Go. Las pilas están incluidas. Desarrollado por go-git.
Aviso (noviembre de 2020): el autor principal ha vuelto del limbo y poco a poco está retomando el desarrollo. Ver la hoja de ruta.
Hay dos herramientas de línea de comandos: hercules y labours . El primero es un programa escrito en Go que toma un repositorio Git y ejecuta un gráfico acíclico dirigido (DAG) de tareas de análisis a lo largo del historial de confirmaciones completo. El segundo es un script de Python que muestra algunos gráficos predefinidos sobre los datos recopilados. Estas dos herramientas normalmente se utilizan juntas a través de una tubería. Es posible escribir análisis personalizados utilizando el sistema de complementos. También es posible combinar varios resultados de análisis, lo que es relevante para las organizaciones. El historial de confirmaciones analizado incluye ramas, fusiones, etc.
Hercules se ha utilizado con éxito en varios proyectos internos en el origen{d}. Hay publicaciones de blog: 1, 2 y una presentación. ¡Contribuya probando, corrigiendo errores, agregando nuevos análisis o codificando arrogancia!
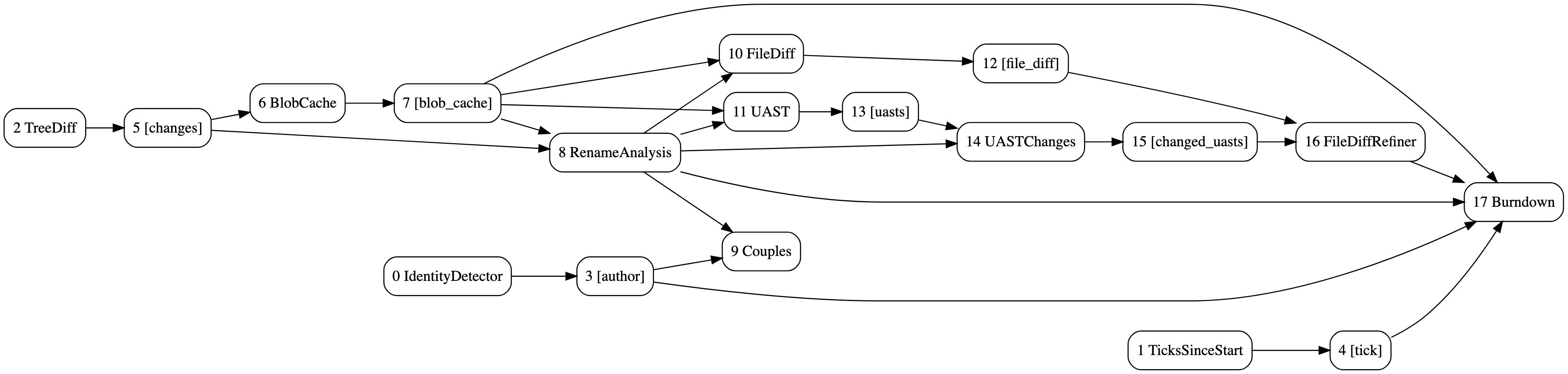
El DAG de burndown y análisis de parejas con refinamiento de diferencias UAST. Generado con hercules --burndown --burndown-people --couples --feature=uast --dry-run --dump-dag doc/dag.dot https://github.com/src-d/hercules
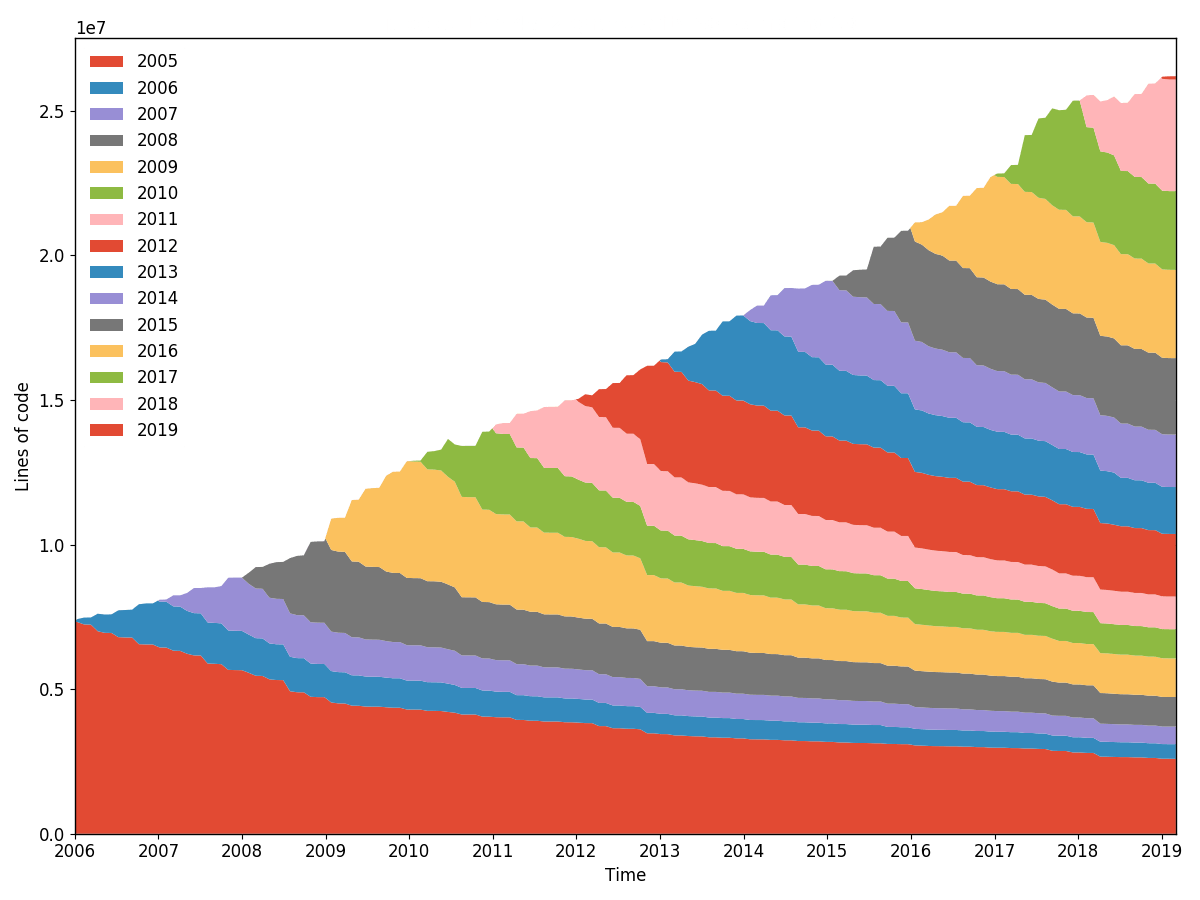
Burndown de línea torvalds/linux (granularidad 30, muestreo 30, remuestreado por año). Generado con hercules --burndown --first-parent --pb https://github.com/torvalds/linux | labours -f pb -m burndown-project en 1h 40min.
Toma el binario hercules de la página de Lanzamientos. labours se puede instalar desde PyPi:
pip3 install labours
pip3 es el administrador de paquetes de Python.
Numpy y Scipy se pueden instalar en Windows usando http://www.lfd.uci.edu/~gohlke/pythonlibs/
Necesitará Go (>= v1.11) y protoc .
git clone https://github.com/src-d/hercules && cd hercules
make
pip3 install -e ./python
Es posible ejecutar Hercules como una acción de GitHub: Hercules en GitHub Marketplace. Consulte el flujo de trabajo de muestra que muestra cómo realizar la configuración.
...¡son bienvenidos! Ver CONTRIBUCIÓN y código de conducta.
apache 2.0
La referencia de línea de comando más útil y confiablemente actualizada:
hercules --help
Algunos ejemplos:
# Use "memory" go-git backend and display the burndown plot. "memory" is the fastest but the repository's git data must fit into RAM.
hercules --burndown https://github.com/go-git/go-git | labours -m burndown-project --resample month
# Use "file system" go-git backend and print some basic information about the repository.
hercules /path/to/cloned/go-git
# Use "file system" go-git backend, cache the cloned repository to /tmp/repo-cache, use Protocol Buffers and display the burndown plot without resampling.
hercules --burndown --pb https://github.com/git/git /tmp/repo-cache | labours -m burndown-project -f pb --resample raw
# Now something fun
# Get the linear history from git rev-list, reverse it
# Pipe to hercules, produce burndown snapshots for every 30 days grouped by 30 days
# Save the raw data to cache.yaml, so that later is possible to labours -i cache.yaml
# Pipe the raw data to labours, set text font size to 16pt, use Agg matplotlib backend and save the plot to output.png
git rev-list HEAD | tac | hercules --commits - --burndown https://github.com/git/git | tee cache.yaml | labours -m burndown-project --font-size 16 --backend Agg --output git.png
labours -i /path/to/yaml permite leer la salida de hercules que se guardó en el disco.
Es posible almacenar el repositorio clonado en el disco. El análisis posterior se puede ejecutar en el directorio correspondiente en lugar de clonarlo desde cero:
# First time - cache
hercules https://github.com/git/git /tmp/repo-cache
# Second time - use the cache
hercules --some-analysis /tmp/repo-cache
La acción produce el artefacto llamado hercules_charts . Dado que actualmente es imposible empaquetar varios archivos en un solo artefacto, todos los gráficos y archivos del Proyector Tensorflow están empaquetados en el archivo tar interno. Para ver las incrustaciones, vaya a proyector.tensorflow.org, haga clic en "Cargar" y elija los dos TSV. Luego use UMAP o T-SNE.
docker run --rm srcd/hercules hercules --burndown --pb https://github.com/git/git | docker run --rm -i -v $(pwd):/io srcd/hercules labours -f pb -m burndown-project -o /io/git_git.png
hercules --burndown
labours -m burndown-project
Estadísticas de avance de líneas para todo el repositorio. Exactamente lo mismo que hace git-of-theseus pero mucho más rápido. La culpa se realiza de manera eficiente e incremental utilizando un algoritmo de seguimiento de árbol RB personalizado, y solo se registra la fecha de la última modificación mientras se ejecuta el análisis.
Todos los análisis de burndown dependen de los valores de granularidad y muestreo . La granularidad es la cantidad de días que componen cada banda de la pila. El muestreo es la frecuencia con la que se toma una instantánea del estado de agotamiento. Cuanto menor sea el valor, más fluida será la trama pero más trabajo se realizará.
Existe una opción para volver a muestrear las bandas dentro labours , para que puedas definir una distribución muy precisa y visualizarla de diferentes maneras. Además, el remuestreo alinea las bandas a través de límites periódicos, por ejemplo, meses o años. Las bandas no muestreadas aparentemente no están alineadas y comienzan desde la fecha de nacimiento del proyecto.
hercules --burndown --burndown-files
labours -m burndown-file
Estadísticas de burndown para cada archivo en el repositorio que esté activo en la última revisión.
Nota: generará un gráfico separado para cada archivo. No desea ejecutarlo en un repositorio con muchos archivos.
hercules --burndown --burndown-people [--people-dict=/path/to/identities]
labours -m burndown-person
Estadísticas de avance de los contribuyentes del repositorio. Si no se especifica --people-dict , las identidades se descubren mediante el siguiente algoritmo:
Si se especifica --people-dict , debería apuntar a un archivo de texto con las identidades personalizadas. El formato es: cada línea es un único desarrollador, contiene todos los correos electrónicos y nombres coincidentes separados por | . El caso es ignorado.
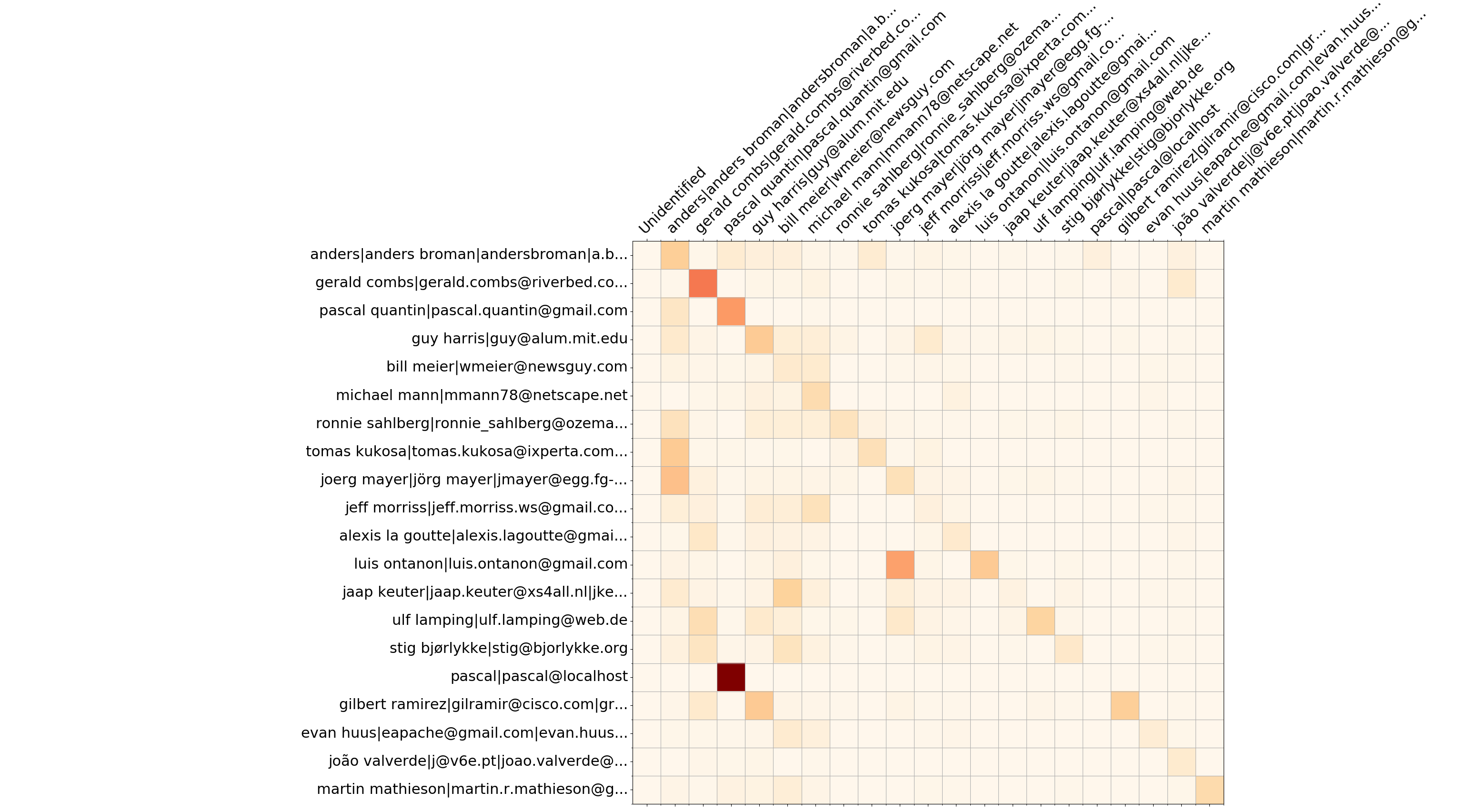
Wireshark top 20 desarrolladores: sobrescribe la matriz
hercules --burndown --burndown-people [--people-dict=/path/to/identities]
labours -m overwrites-matrix
Además de la información de avance, --burndown-people recopila las estadísticas de líneas agregadas y eliminadas por desarrollador. Por lo tanto, se puede visualizar cuántas líneas escritas por el desarrollador A son eliminadas por el desarrollador B. Esto indica colaboración entre personas y define equipos de expertos.
El formato es la matriz con N filas y (N+2) columnas, donde N es el número de desarrolladores.
--people-dict , siempre es 0). La secuencia de desarrolladores se almacena en el nodo YAML people_sequence .
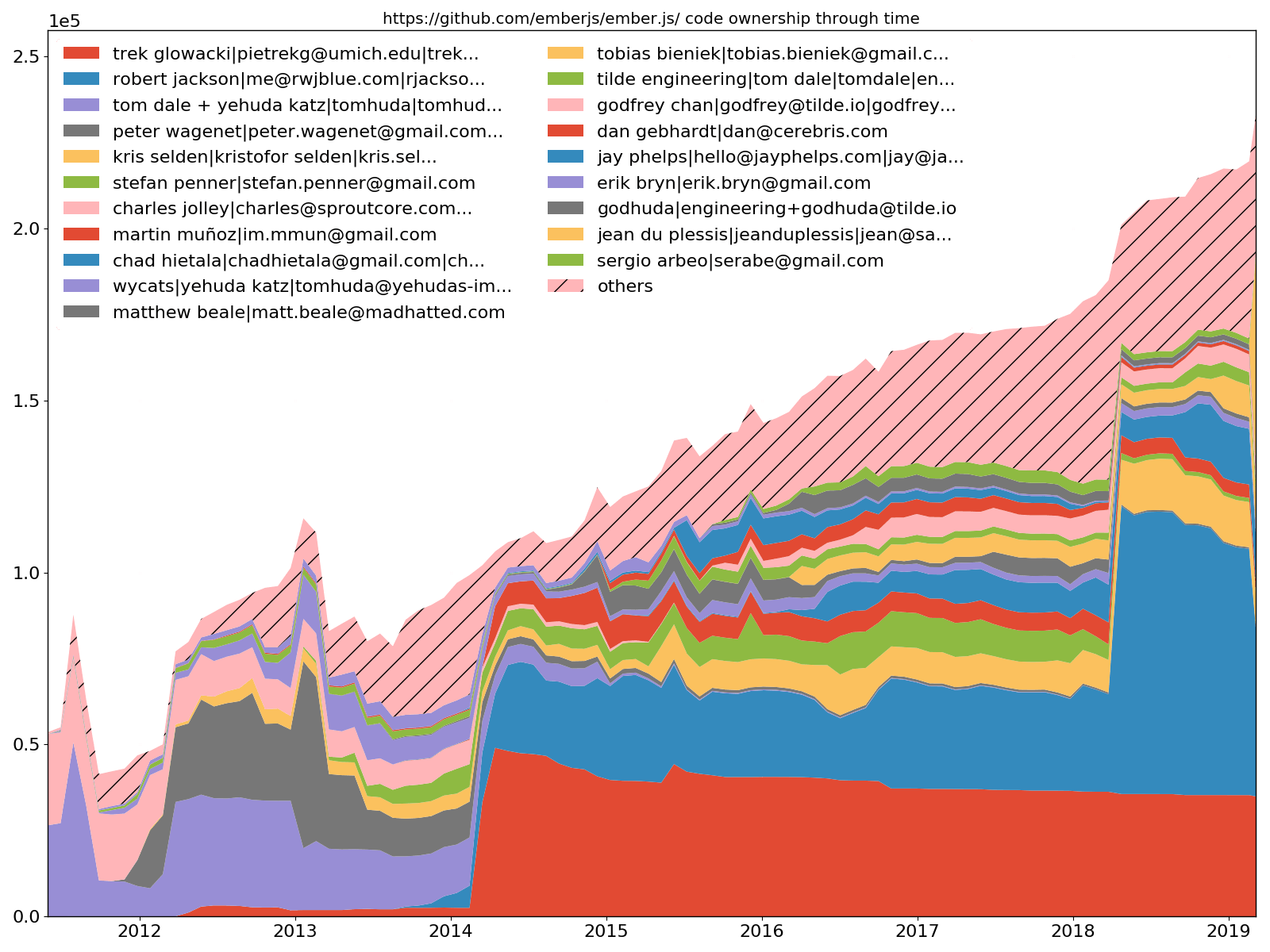
Ember.js 20 principales desarrolladores: propiedad del código
hercules --burndown --burndown-people [--people-dict=/path/to/identities]
labours -m ownership
--burndown-people también permite dibujar el código compartido a través de un gráfico de áreas apiladas en el tiempo. Es decir, cuántas líneas están activas en los momentos muestreados en el tiempo para cada desarrollador identificado.
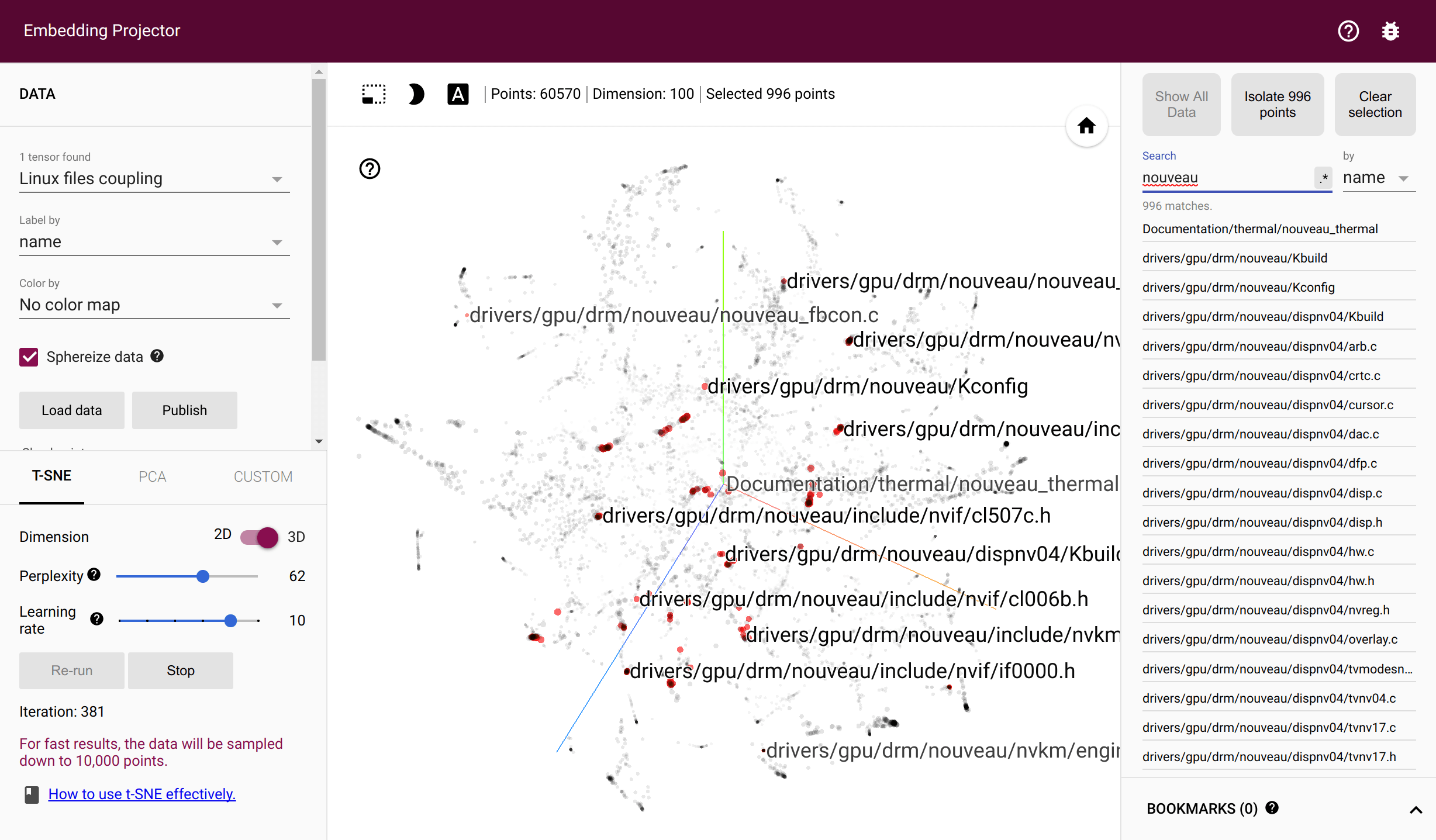
Acoplamiento de archivos torvalds/linux en Tensorflow Proyector
hercules --couples [--people-dict=/path/to/identities]
labours -m couples -o <name> [--couples-tmp-dir=/tmp]
Importante : requiere la instalación de Tensorflow, siga las instrucciones oficiales.
Los archivos se acoplan si se modifican en la misma confirmación. Los desarrolladores están emparejados si cambian el mismo archivo. hercules registra el número de parejas a lo largo de todo el historial de confirmaciones y genera las dos matrices de coocurrencia correspondientes. Luego, labours entrena incrustaciones giratorias: vectores densos que reflejan la probabilidad de coexistencia a través de la distancia euclidiana. La capacitación requiere una instalación de Tensorflow que funcione. Los archivos intermedios se almacenan en el directorio temporal del sistema o --couples-tmp-dir si se especifica. Las incrustaciones entrenadas se escriben en el directorio de trabajo actual con el nombre dependiendo de -o . El formato de salida es TSV y coincide con Tensorflow Proyector para que los archivos y las personas puedan visualizarse con t-SNE implementado en TF Proyector.
46 jinja2/compiler.py:visit_Template [FunctionDef]
42 jinja2/compiler.py:visit_For [FunctionDef]
34 jinja2/compiler.py:visit_Output [FunctionDef]
29 jinja2/environment.py:compile [FunctionDef]
27 jinja2/compiler.py:visit_Include [FunctionDef]
22 jinja2/compiler.py:visit_Macro [FunctionDef]
22 jinja2/compiler.py:visit_FromImport [FunctionDef]
21 jinja2/compiler.py:visit_Filter [FunctionDef]
21 jinja2/runtime.py:__call__ [FunctionDef]
20 jinja2/compiler.py:visit_Block [FunctionDef]
Gracias a Babelfish, Hércules es capaz de medir cuántas veces se ha modificado cada unidad estructural. De forma predeterminada, analiza las funciones; consulte el manual de Semantic UAST XPath para cambiar a otra cosa.
hercules --shotness [--shotness-xpath-*]
labours -m shotness
El análisis de parejas carga automáticamente datos de "disparo" si están disponibles.
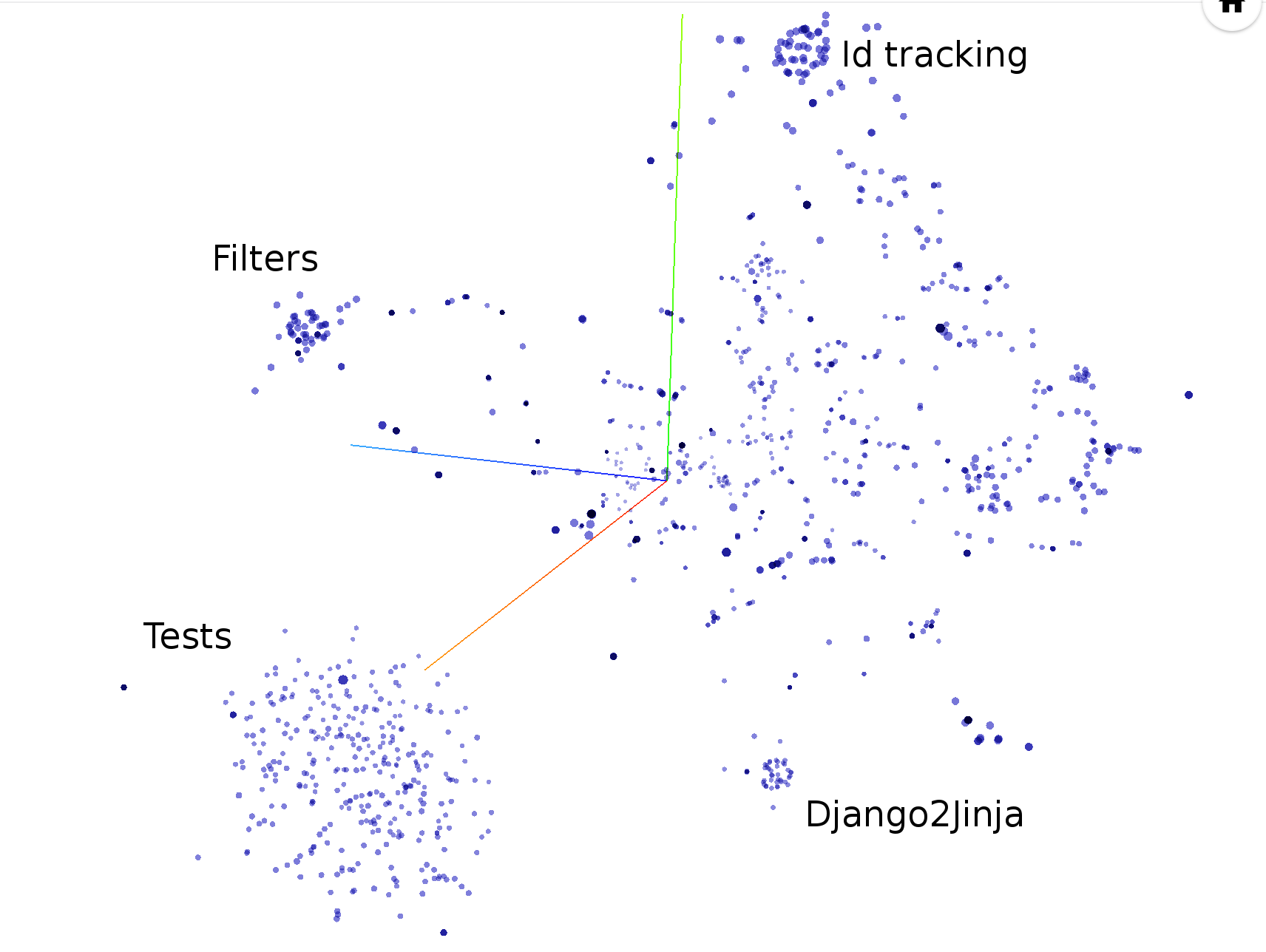
hercules --shotness --pb https://github.com/pallets/jinja | labours -m couples -f pb
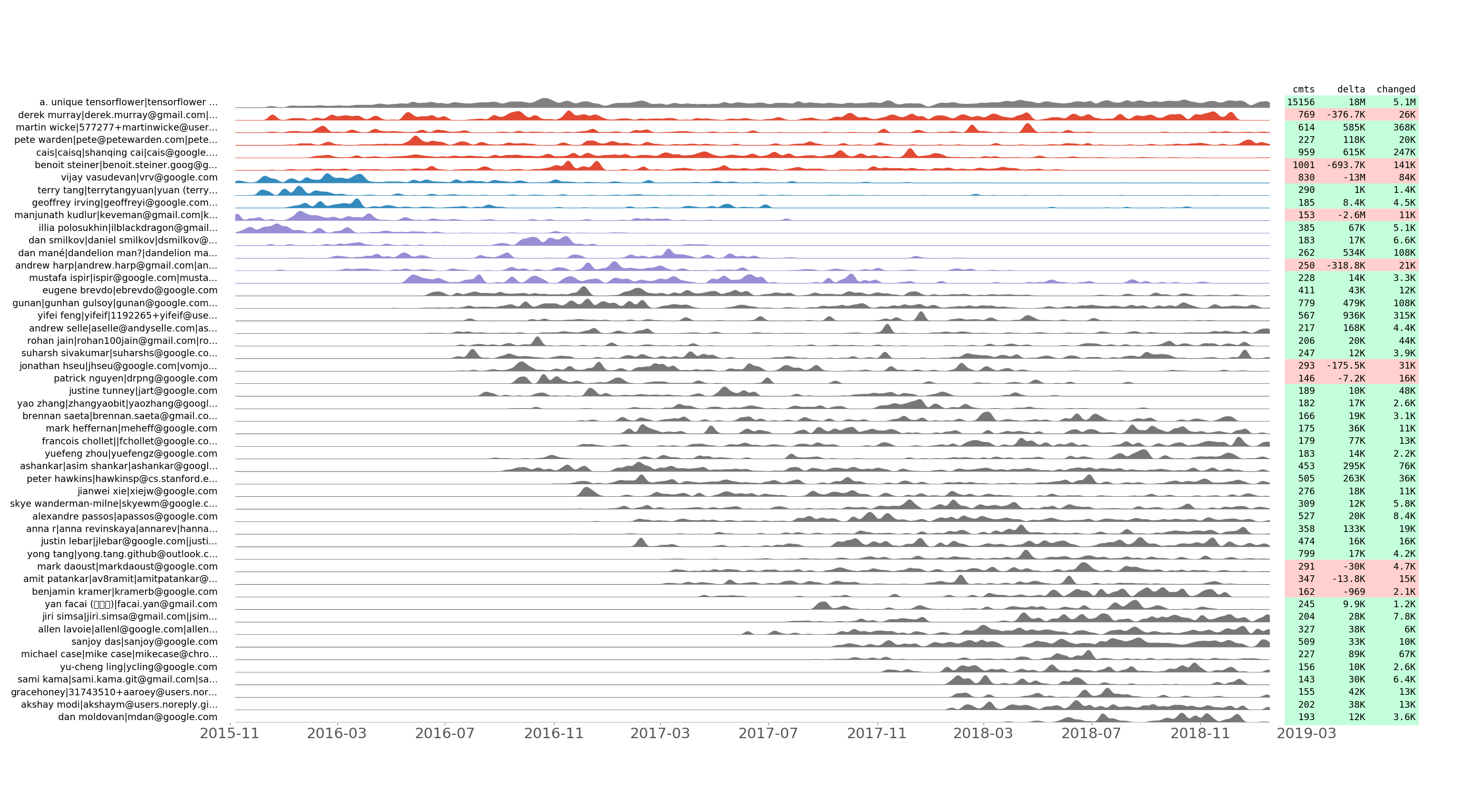
Serie de confirmaciones alineadas con tensorflow/tensorflow de los 50 principales desarrolladores por número de confirmación.
hercules --devs [--people-dict=/path/to/identities]
labours -m devs -o <name>
Registramos cuántas confirmaciones se realizan, así como las líneas agregadas, eliminadas y modificadas por día para cada desarrollador. Trazamos la serie temporal de confirmación resultante utilizando algunos trucos para mostrar la agrupación temporal. En otras palabras, dos series de confirmación adyacentes deberían verse similares después de la normalización.
Esta trama permite descubrir cómo evolucionó el equipo de desarrollo a través del tiempo. También muestra "cometer flashmobs" como Hacktoberfest. Por ejemplo, aquí están las ideas reveladas del gráfico tensorflow/tensorflow anterior:
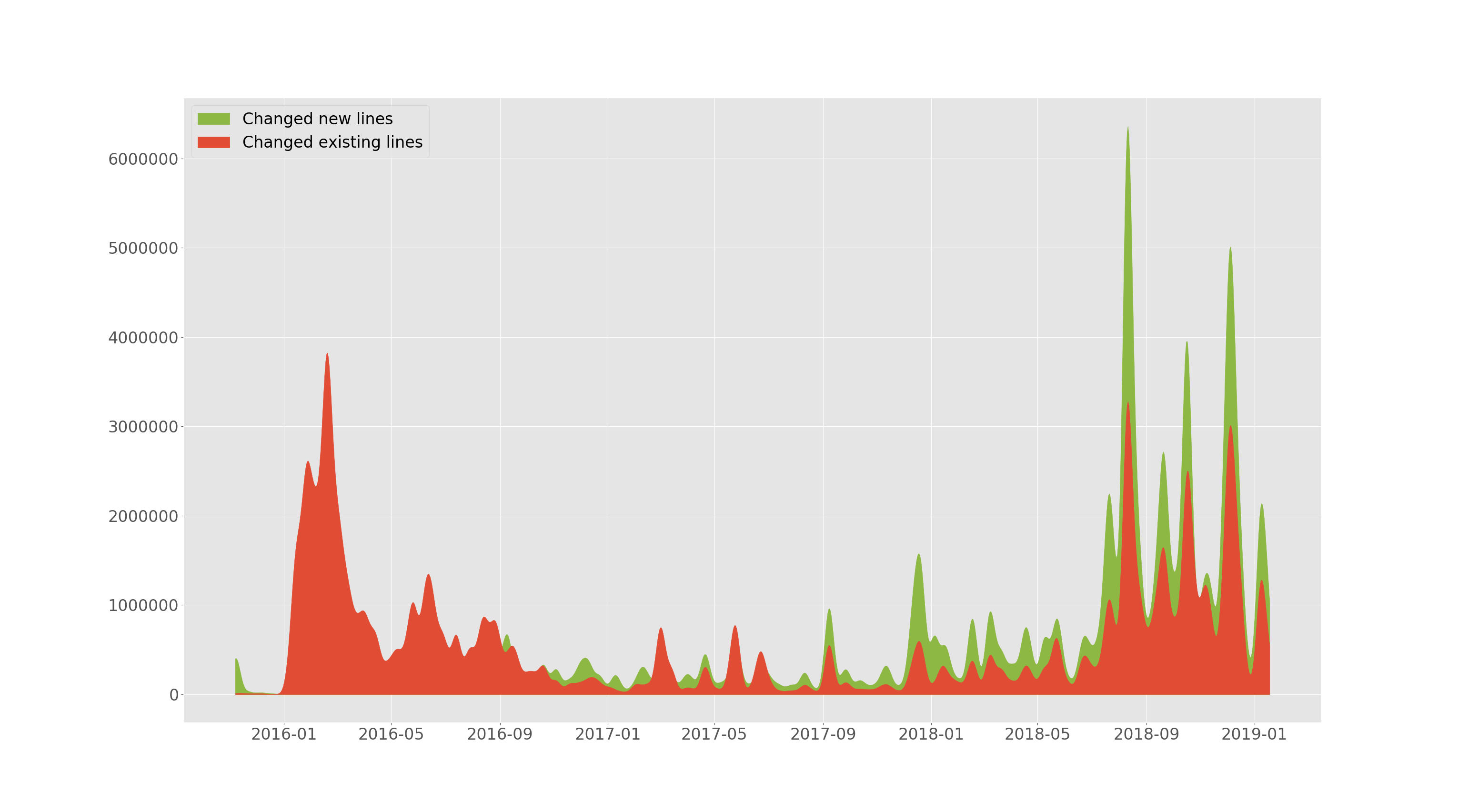
tensorflow/tensorflow agregó y cambió líneas a través del tiempo.
hercules --devs [--people-dict=/path/to/identities]
labours -m old-vs-new -o <name>
--devs de la sección anterior permite trazar cuántas líneas se agregaron y cuántas existentes cambiaron (eliminadas o reemplazadas) a lo largo del tiempo. Esta trama está suavizada.
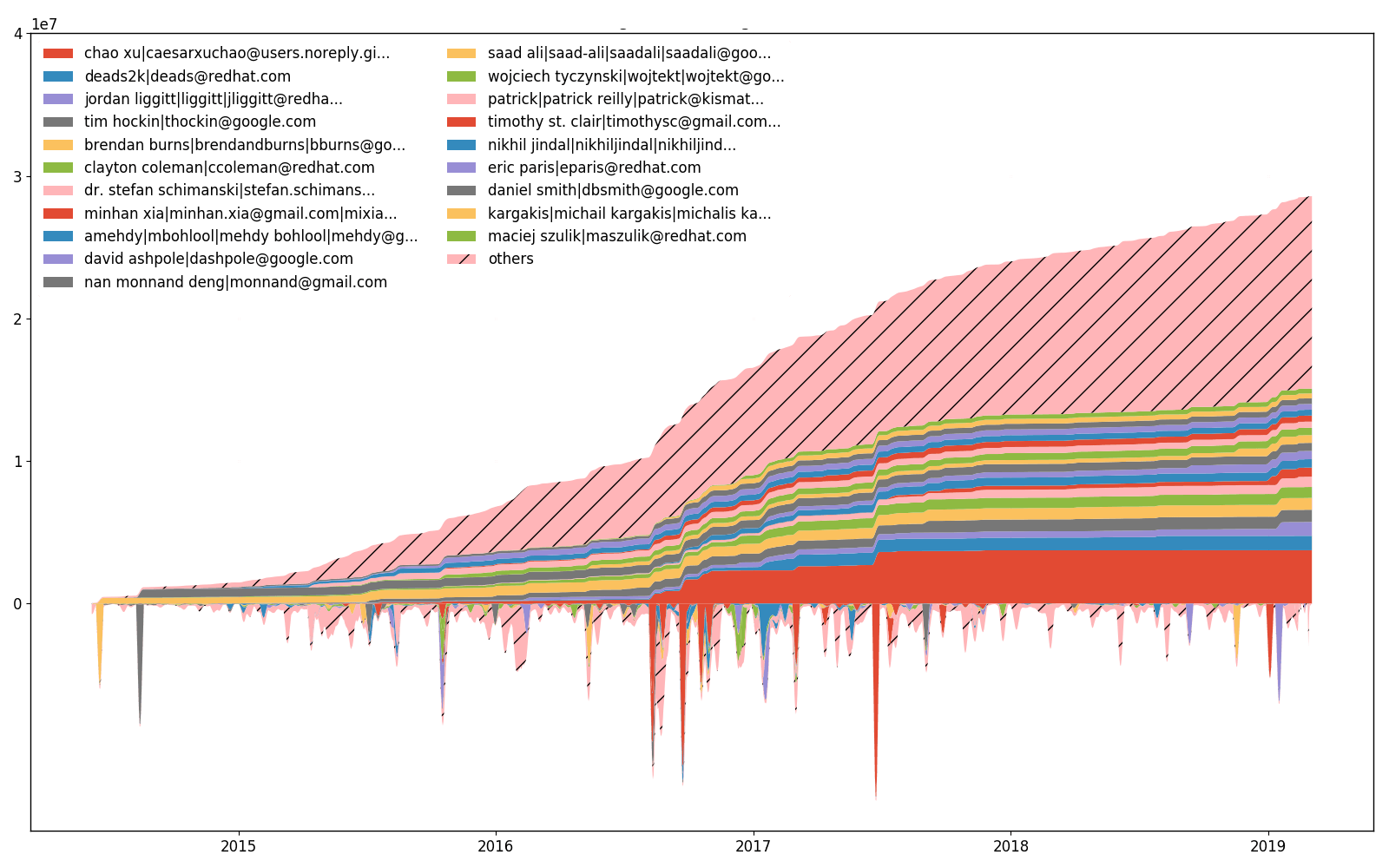
Esfuerzos de kubernetes/kubernetes a través del tiempo.
hercules --devs [--people-dict=/path/to/identities]
labours -m devs-efforts -o <name>
Además, --devs permite trazar cuántas líneas ha cambiado (agregado o eliminado) cada desarrollador. La parte superior de la parcela es una parte inferior acumulada (integrada). Es imposible tener la misma escala para ambas partes, por lo que los valores más bajos se escalan y, por lo tanto, no hay marcas inferiores del eje Y. Hay una diferencia entre la trama de esfuerzos y la trama de propiedad, aunque las líneas cambiantes se correlacionan con las líneas de propiedad.
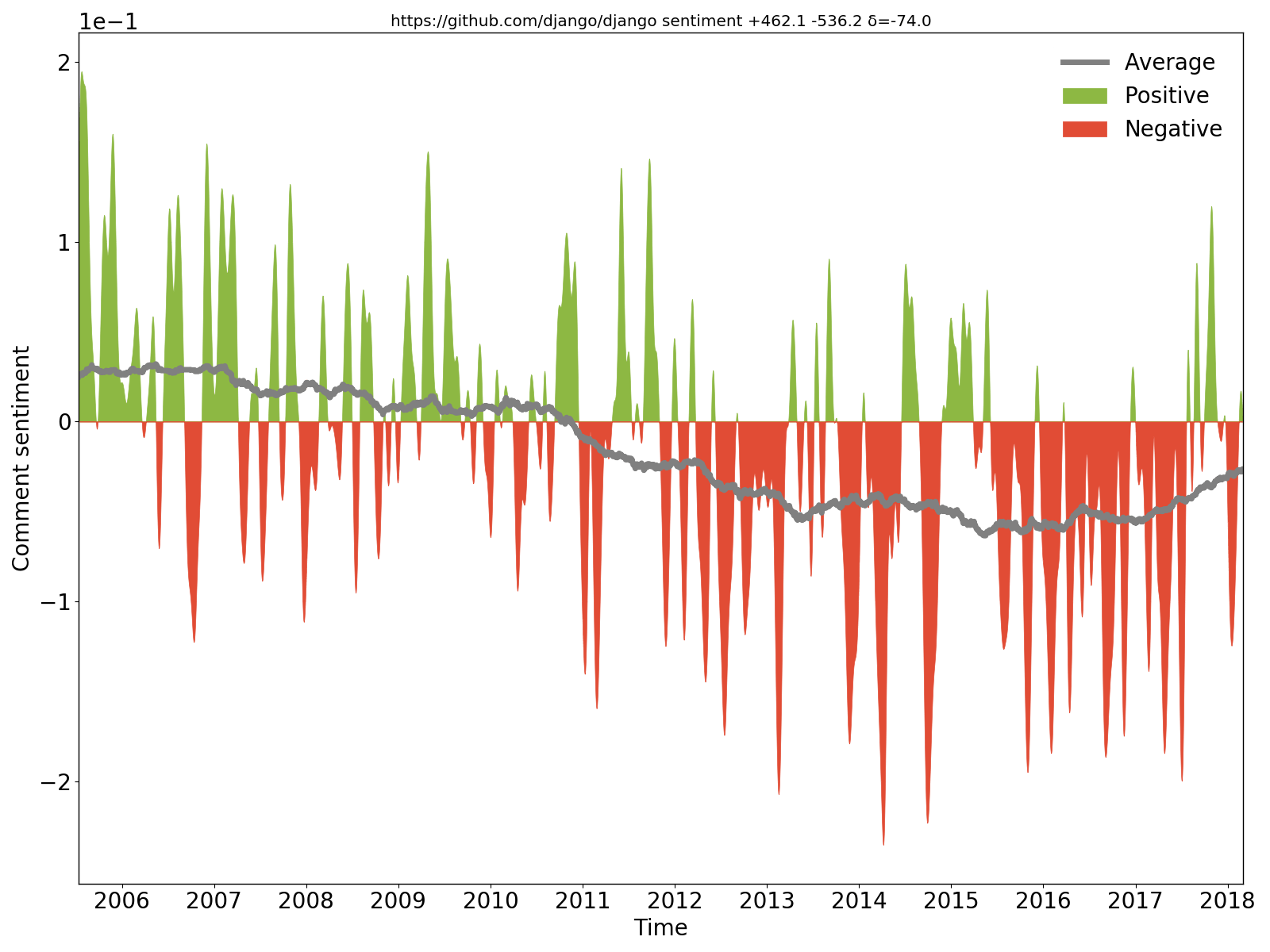
Se puede ver claramente que los comentarios de Django fueron positivos/optimistas al principio, pero luego se volvieron negativos/pesimistas.
hercules --sentiment --pb https://github.com/django/django | labours -m sentiment -f pb
Extraemos comentarios nuevos y modificados del código fuente en cada confirmación, aplicamos la red neuronal recurrente de sentimiento de propósito general BiDiSentiment y trazamos los resultados. Requiere libtensorflow. Por ejemplo sadly, we need to hide the rect from the documentation finder for now es negativo y Theano has a built-in optimization for logsumexp (...) so we can just write the expression directly como positiva. Sin embargo, no espere demasiado: tal como se escribió, el modelo de sentimiento es de propósito general y los comentarios del código tienen una naturaleza diferente, por lo que no hay magia (por ahora).
Hercules debe compilarse con la etiqueta "tensorflow"; no es la predeterminada:
make TAGS=tensorflow
Una compilación de este tipo requiere libtensorflow .
hercules --burndown --burndown-files --burndown-people --couples --shotness --devs [--people-dict=/path/to/identities]
labours -m all
Hercules tiene un sistema de complementos y permite ejecutar análisis personalizados. Consulte PLUGINS.md.
hercules combine es el comando que une varios resultados de análisis en formato Protocol Buffers.
hercules --burndown --pb https://github.com/go-git/go-git > go-git.pb
hercules --burndown --pb https://github.com/src-d/hercules > hercules.pb
hercules combine go-git.pb hercules.pb | labours -f pb -m burndown-project --resample M
YAML no admite toda la gama de caracteres Unicode y el analizador del lado labours puede generar excepciones. Filtre la salida de hercules a través de fix_yaml_unicode.py para descartar dichos caracteres ofensivos.
hercules --burndown --burndown-people https://github.com/... | python3 fix_yaml_unicode.py | labours -m people
Estas opciones afectan a todas las parcelas:
labours [--style=white|black] [--backend=] [--size=Y,X]
--style establece el estilo general de la trama (ver labours --help ). --background cambia el fondo de la trama para que sea blanco o negro. --backend elige el backend de Matplotlib. --size establece el tamaño de la figura en pulgadas. El valor predeterminado es 12,9 .
(requerido en macOS) puede anclar el backend predeterminado de Matplotlib con
echo "backend: TkAgg" > ~/.matplotlib/matplotlibrc
Estas opciones sólo son efectivas en gráficos de evolución:
labours [--text-size] [--relative]
--text-size cambia el tamaño de fuente, --relative activa el diseño de grabación ampliada.
Es posible generar toda la información necesaria para dibujar los gráficos en formato JSON. Simplemente agregue .json a la salida ( -o ) y listo. El formato de los datos no está completamente especificado y depende del código Python que lo genera. Cada archivo JSON debe contener "type" que refleja el tipo de trama.
--first-parent como solución alternativa.hercules para el kernel de Linux en modo "parejas" es de 1,5 GB y tarda más de una hora/180 GB de RAM en analizarse. Sin embargo, la mayoría de los repositorios se analizan en un minuto. Intente utilizar Protocol Buffers en su lugar ( hercules --pb y labours -f pb ). # Debian, Ubuntu
apt install libyaml-dev
# macOS
brew install yaml-cpp libyaml
# you might need to re-install pyyaml for changes to make effect
pip uninstall pyyaml
pip --no-cache-dir install pyyaml
Si el repositorio analizado es grande y utiliza muchas ramificaciones, la recopilación de estadísticas de burndown puede fallar con un OOM. Deberías probar lo siguiente:
--skip-blacklist para evitar analizar los archivos no deseados. También es posible restringir el --language .--hibernation-distance 10 --burndown-hibernation-threshold=1000 . Juega con esos dos números para comenzar a hibernar justo antes del OOM.--burndown-hibernation-disk --burndown-hibernation-dir /path .--first-parent , tú ganas. src-d/go-git a go-git/go-git . Actualice el código base para que sea compatible con la última versión de Go. 

