clearml agent
v1.9.2

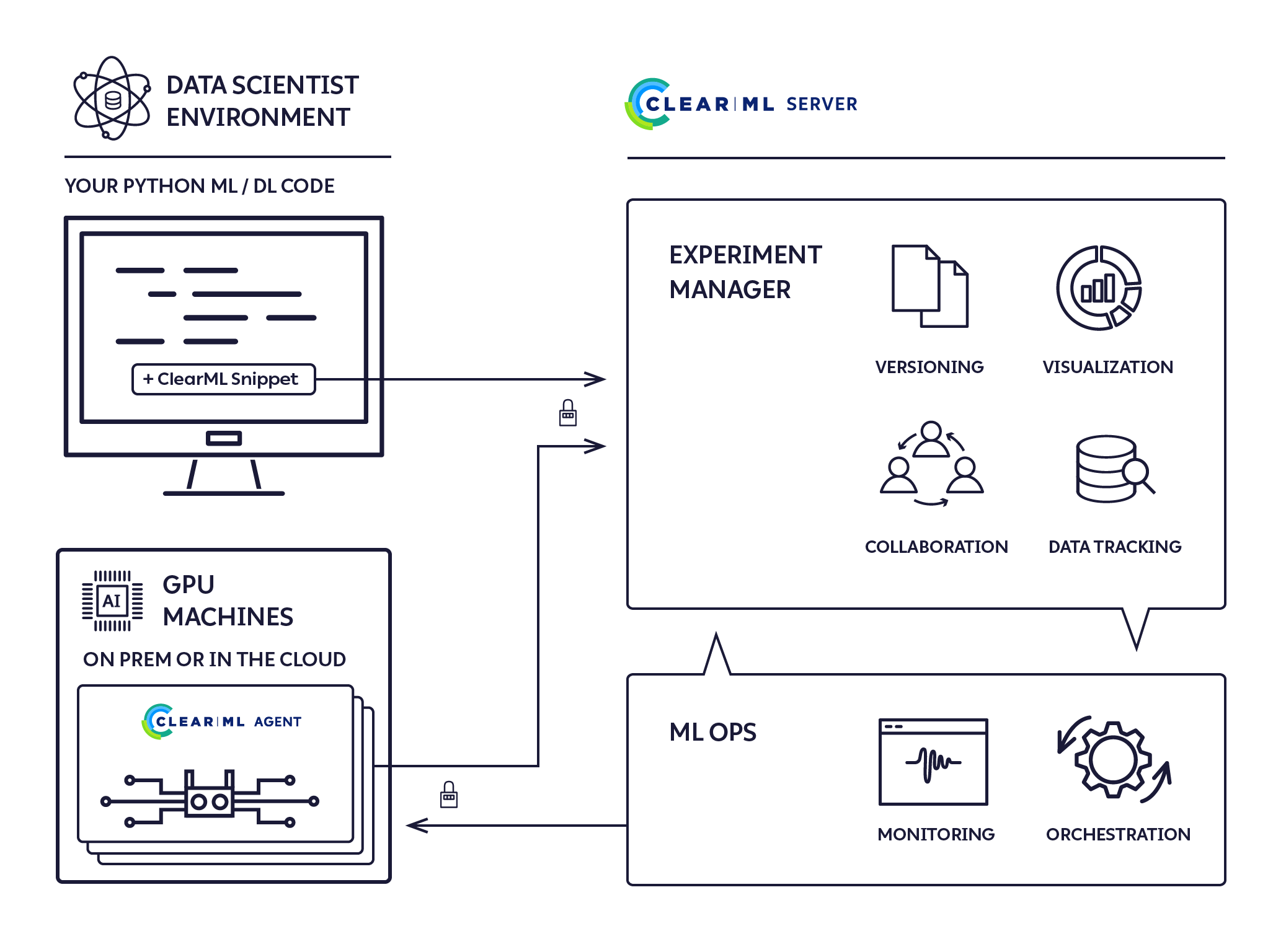
Agente ClearML: MLOps/LLMOps simplificados
Solución de programación y orquestación MLOps/LLMOps compatible con Linux, macOS y Windows
? ClearML is open-source - Leave a star to support the project! ?
Es un agente de ejecución de configuración cero que se activa y se olvida, y que proporciona una solución de clúster ML/DL completa.
Automatización completa en 5 pasos
pip install clearml-agent (instale el agente ClearML en cualquier máquina GPU: local/nube/...)"Todos los DevOps de aprendizaje profundo/máquina que tu investigación necesita, y algo más... Porque nadie tiene tiempo para eso"
Pruebe ClearML ahora con alojamiento propio o de nivel gratuito 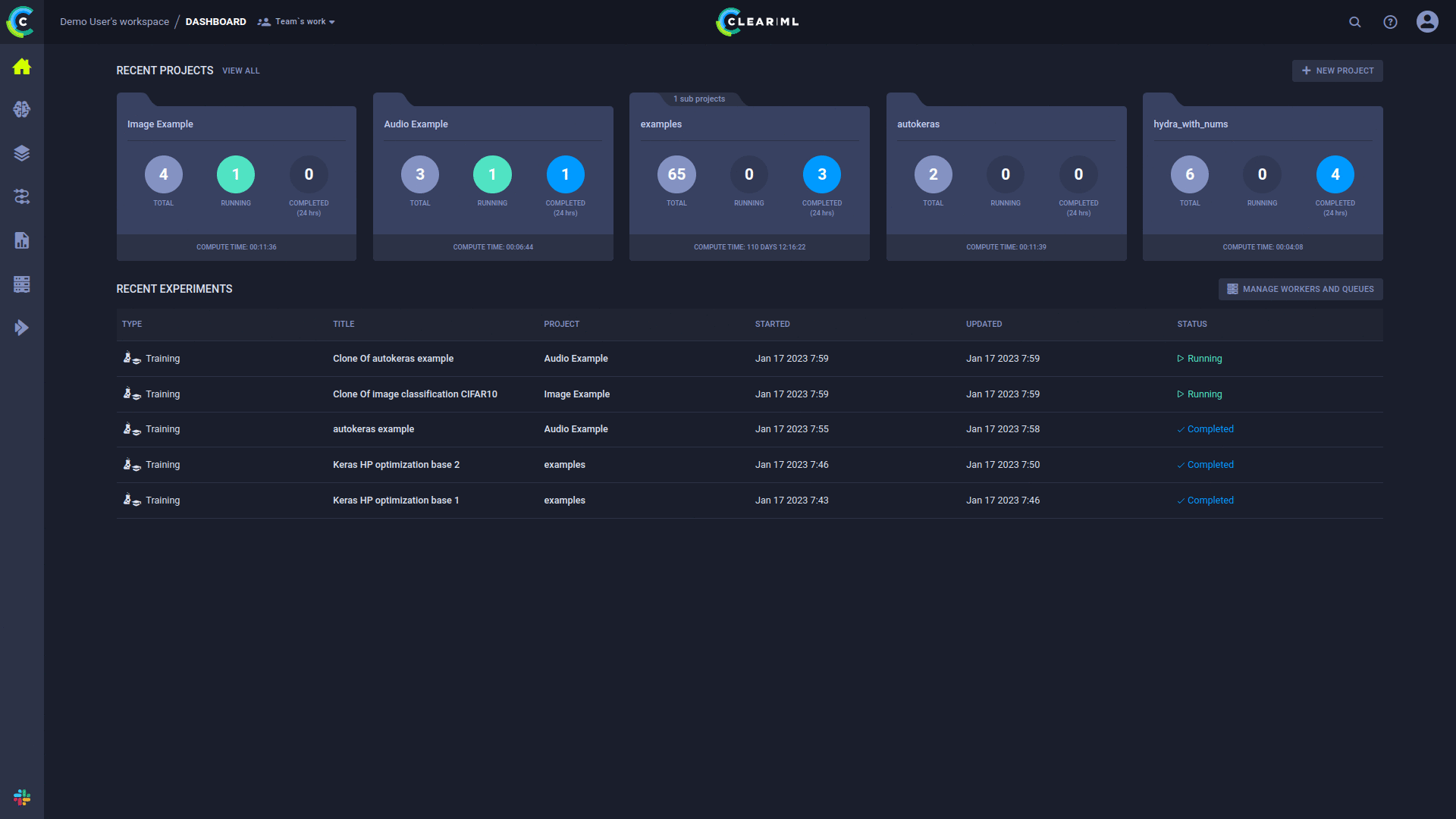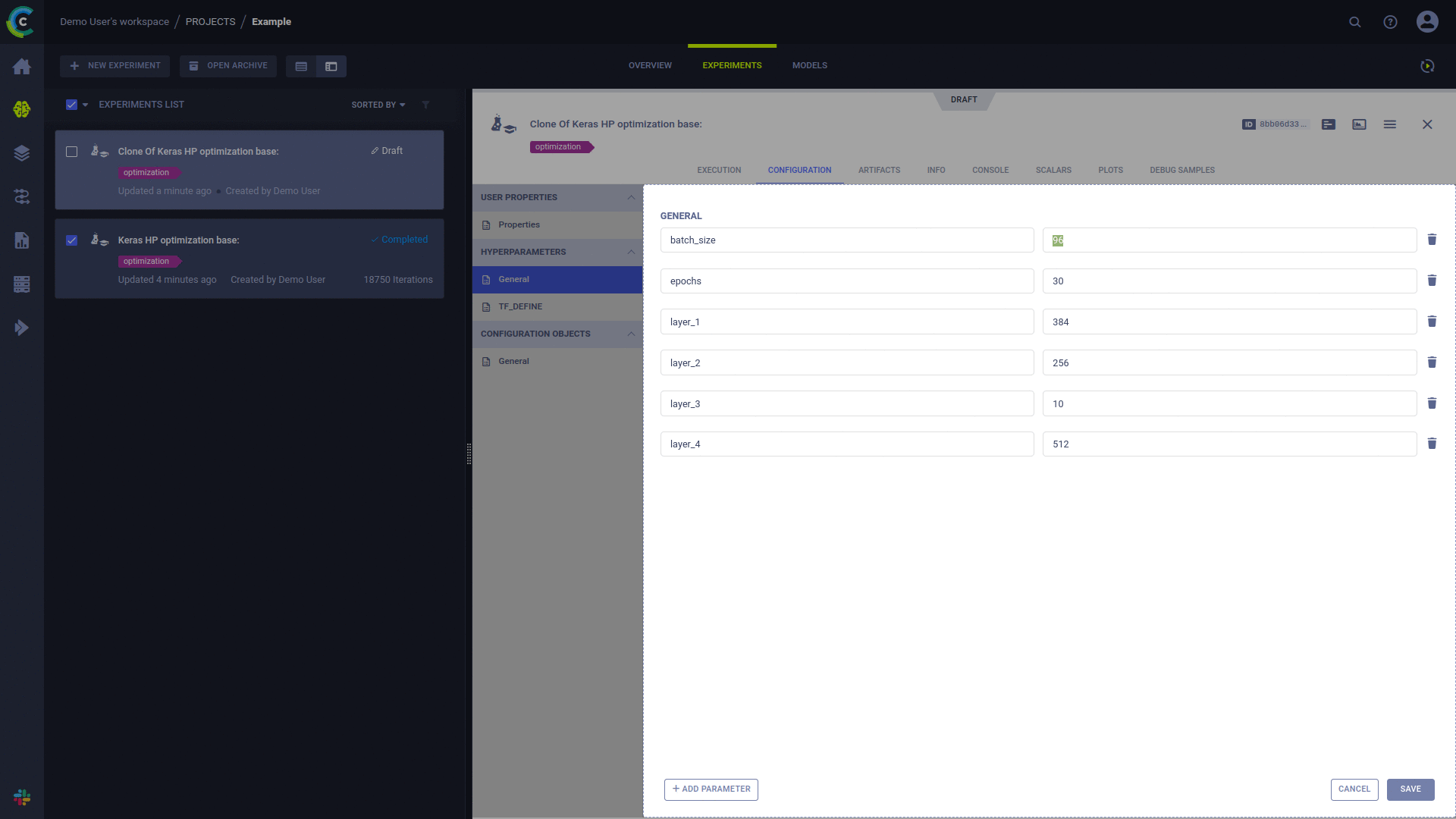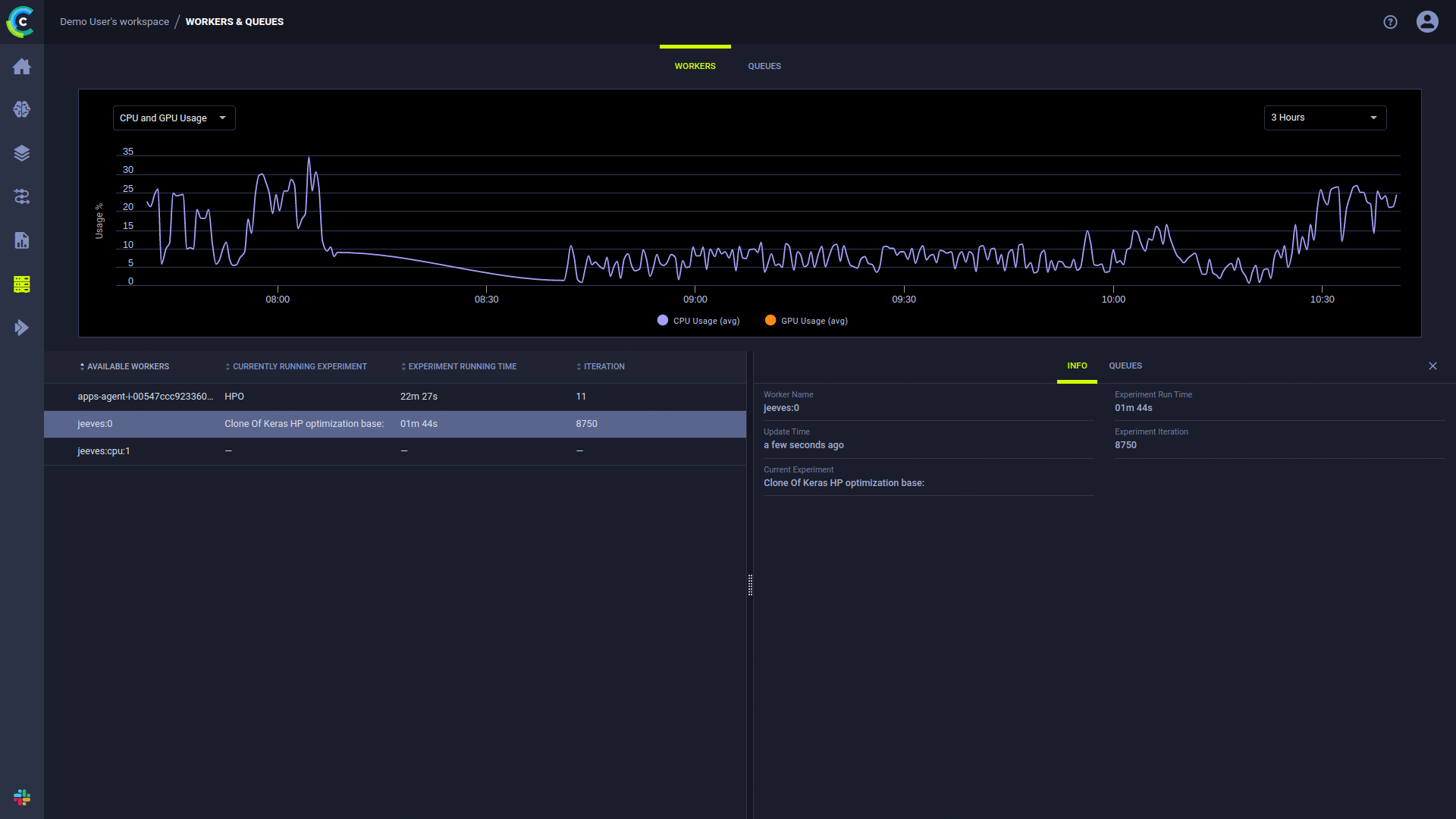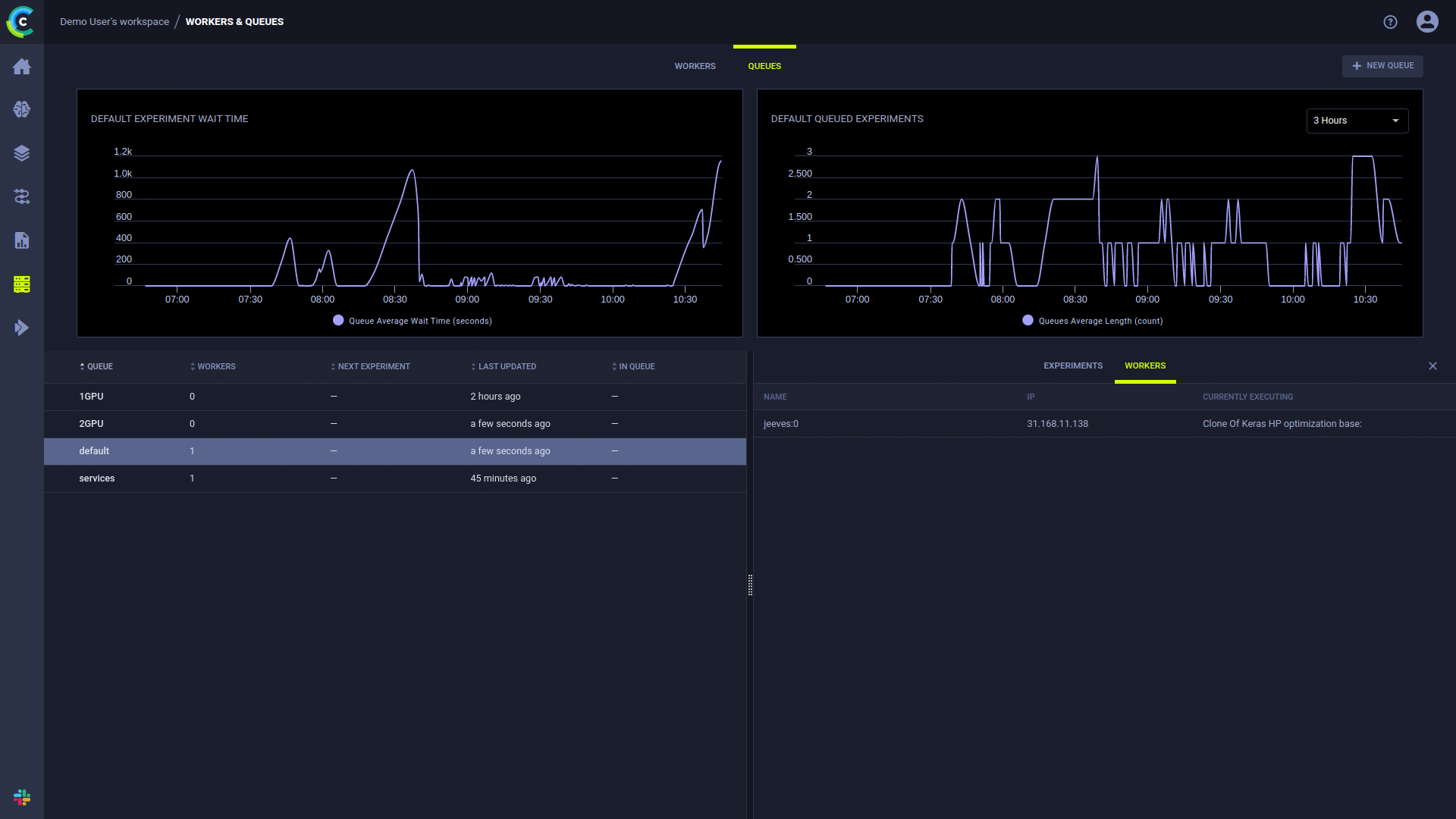
El agente ClearML se creó para abordar las necesidades de DevOps de investigación y desarrollo de DL/ML:
Con el agente ClearML, ahora puede configurar un clúster dinámico con *epsilon DevOps
*epsilon - ¿Porque lo somos? y nada es realmente trabajo cero
Creemos que Kubernetes es increíble, pero no es imprescindible para comenzar con agentes de ejecución remota y administración de clústeres. Diseñamos clearml-agent para que pueda ejecutarlo desde cero y sobre Kubernetes, en cualquier combinación que se adapte a su entorno.
Puede encontrar los Dockerfiles en la carpeta Docker y el gráfico de timón en https://github.com/allegroai/clearml-helm-charts
Ejecute el agente en modo Kubernetes Glue y asigne los trabajos de ClearML directamente a los trabajos de K8:
¡Sí! La integración de Slurm está disponible, consulte la documentación para obtener más detalles.
HPC a gran escala con solo hacer clic en un botón
El agente ClearML es un programador de trabajos que escucha colas de trabajos, extrae trabajos, configura los entornos de trabajo, ejecuta el trabajo y monitorea su progreso.
Cualquier experimento 'borrador' puede programarse para su ejecución por parte de un agente de ClearML.
Un experimento ejecutado previamente se puede poner en estado "Borrador" mediante cualquiera de dos métodos:
Se programa la ejecución de un experimento mediante la acción "Poner en cola" en el menú contextual del botón derecho del experimento en la interfaz de usuario de ClearML y seleccionando la cola de ejecución.
Consulte crear un experimento y ponerlo en cola para su ejecución.
Una vez que un experimento está en cola, un agente ClearML que monitorea esta cola lo recogerá y ejecutará.
La página ClearML UI Workers & Queues proporciona información de ejecución continua:
El agente ClearML ejecuta experimentos mediante el siguiente proceso:
pip install clearml-agentLa interfaz completa y las capacidades están disponibles con
clearml-agent --help
clearml-agent daemon --helpclearml-agent init Nota: El agente ClearML utiliza una carpeta de caché para almacenar en caché los paquetes pip, los paquetes apt y los repositorios clonados. La carpeta de caché predeterminada del Agente ClearML es ~/.clearml .
Vea todos los detalles en su archivo de configuración en ~/clearml.conf .
Nota: El agente ClearML amplía el archivo de configuración de ClearML ~/clearml.conf . Están diseñados para compartir el mismo archivo de configuración, vea el ejemplo aquí
Para depurar y experimentar, inicie el agente ClearML en modo foreground , donde toda la salida se imprime en la pantalla:
clearml-agent daemon --queue default --foreground Para el modo de servicio real, toda la salida estándar se almacenará automáticamente en un archivo temporal (no es necesario canalizar). Aviso: con el indicador --detached , el agente clearml se ejecutará en segundo plano
clearml-agent daemon --detached --queue default La asignación de GPU se controla a través del entorno del sistema operativo estándar NVIDIA_VISIBLE_DEVICES o el indicador --gpus (o se deshabilita con --cpu-only ).
Si no se establece ningún indicador y la variable NVIDIA_VISIBLE_DEVICES no existe, todas las GPU se asignarán para clearml-agent .
Si se establece el indicador --cpu-only , o NVIDIA_VISIBLE_DEVICES="none" , no se asignará ninguna gpu para clearml-agent .
Ejemplo: hacer girar dos agentes, uno por GPU en la misma máquina:
Aviso: con el indicador --detached , el agente clearml se ejecutará en segundo plano
clearml-agent daemon --detached --gpus 0 --queue default
clearml-agent daemon --detached --gpus 1 --queue default Ejemplo: girar dos agentes, extrayendo de la cola dual_gpu dedicada, dos GPU por agente
clearml-agent daemon --detached --gpus 0,1 --queue dual_gpu
clearml-agent daemon --detached --gpus 2,3 --queue dual_gpu Para depurar y experimentar, inicie el agente ClearML en modo foreground , donde toda la salida se imprime en la pantalla.
clearml-agent daemon --queue default --docker --foreground Para el modo de servicio real, toda la salida estándar se almacenará automáticamente en un archivo (no es necesario canalizar). Aviso: con el indicador --detached , el agente clearml se ejecutará en segundo plano
clearml-agent daemon --detached --queue default --docker Ejemplo: haga girar dos agentes, uno por gpu en la misma máquina, con la ventana acoplable nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 predeterminada:
clearml-agent daemon --detached --gpus 0 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
clearml-agent daemon --detached --gpus 1 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 Ejemplo: haga girar dos agentes, extrayendo de la cola dual_gpu dedicada, dos GPU por agente, con la ventana acoplable nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 predeterminada:
clearml-agent daemon --detached --gpus 0,1 --queue dual_gpu --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
clearml-agent daemon --detached --gpus 2,3 --queue dual_gpu --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04También se admiten colas prioritarias; caso de uso de ejemplo:
Cola de alta prioridad: important_jobs , cola de baja prioridad: default
clearml-agent daemon --queue important_jobs default El agente ClearML primero intentará extraer trabajos de la cola important_jobs y, solo si está vacía, el agente intentará extraer trabajos de la cola default .
Agregar colas, administrar el orden de los trabajos dentro de una cola y mover trabajos entre colas está disponible mediante la interfaz de usuario web; consulte el ejemplo en nuestro servidor gratuito.
Para detener la ejecución de un agente ClearML en segundo plano, ejecute la misma línea de comando utilizada para iniciar el agente con --stop agregado. Por ejemplo, para detener el primero de los agentes de una sola gpu de la misma máquina que se muestran arriba:
clearml-agent daemon --detached --gpus 0 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 --stopIntegre ClearML con su código
Ejecute el código en su máquina (Manualmente/PyCharm/Jupyter Notebook)
Mientras se ejecuta su código, ClearML crea un experimento que registra toda la información de ejecución necesaria:
Ahora tiene una "plantilla" de su experimento con todo lo necesario para la ejecución automatizada.
En la interfaz de usuario de ClearML, haga clic derecho en el experimento y seleccione "clonar". Se creará una copia de su experimento.
Ahora tiene un nuevo borrador de experimento clonado de su experimento original; no dude en editarlo.
Programe la ejecución del experimento recién creado: haga clic con el botón derecho en el experimento y seleccione "poner en cola".
ClearML-Agent Services es un modo especial de ClearML-Agent que brinda la capacidad de iniciar trabajos de larga duración que antes debían ejecutarse en máquinas locales/dedicadas. Permite que un solo agente inicie múltiples ventanas acoplables (tareas) para diferentes casos de uso:
El modo ClearML-Agent Services girará cualquier tarea puesta en cola en la cola especificada. Cada tarea iniciada por ClearML-Agent Services se registrará como un nuevo nodo en el sistema, proporcionando capacidades de seguimiento y transparencia. Actualmente, clearml-agent en modo de servicios admite la configuración solo de CPU. El modo de servicios ClearML-Agent se puede iniciar junto con los agentes GPU.
clearml-agent daemon --services-mode --detached --queue services --create-queue --docker ubuntu:18.04 --cpu-onlyNota : Es responsabilidad del usuario asegurarse de que las tareas adecuadas se envíen a la cola especificada.
El agente ClearML también se puede utilizar para implementar la orquestación de AutoML y los canales de experimentos junto con el paquete ClearML.
Se pueden encontrar ejemplos de AutoML y orquestación en la carpeta de ejemplo/automatización de ClearML.
Ejemplos de AutoML:
Ejemplos de canalización de experimentos:
Licencia Apache, Versión 2.0 (consulte la LICENCIA para obtener más información)


