./imagesDockerfile para incluir sus binariosf()TUPLE_CODECS
docker build -t image_compression_comparison .
docker run -it -v $(pwd):/image_compression_comparison image_compression_comparison
python3 script_compress_parallel.py
Se realizan codificaciones dirigidas a ciertos valores métricos y los resultados se almacenan en los respectivos archivos de bases de datos, por ejemplo:
main(metric='ssim', target_arr=[0.92, 0.95, 0.97, 0.99], target_tol=0.005, db_file_name='encoding_results_ssim.db')main(metric='vmaf', target_arr=[75, 80, 85, 90, 95], target_tol=0.5, db_file_name='encoding_results_vmaf.db')
compression_results_[PID]_[TIMESTAMP].txtcompression_results_worker_[PID]_[TIMESTAMP].txt En archivos de base de datos sqlite3, por ejemplo encoding_results_vmaf.db y encoding_results_ssim.db .
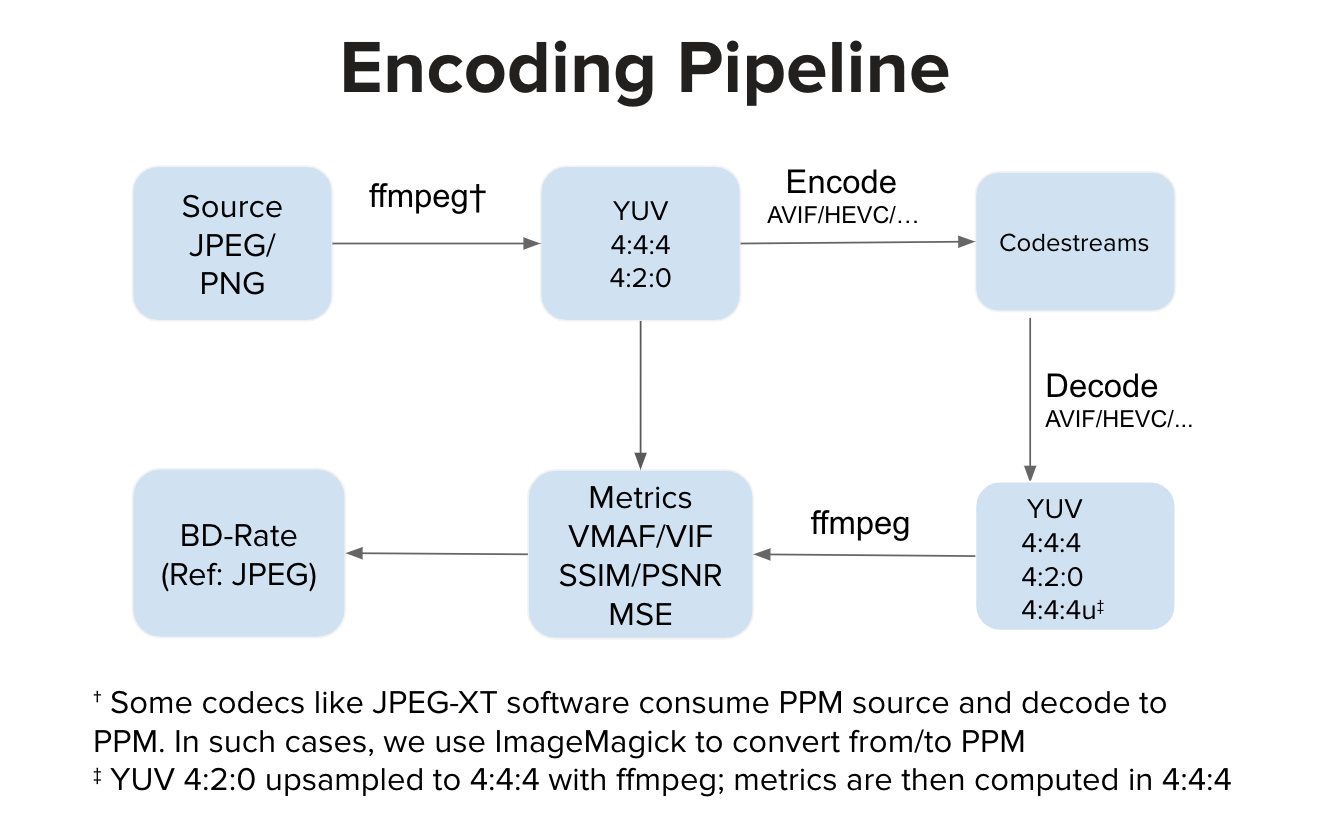
Las tasas porcentuales de BD se pueden calcular utilizando un script llamado compute_BD_rates.py . El guión toma un argumento:
python3 compute_BD_rates.py [db file name]
e imprime valores para BD Rate VMAF , BD Rate SSIM , BDRate MS_SSIM , BDRate VIF , BDRate PSNR_Y y BDRate PSNR_AVG para cada imagen de origen, así como la media del conjunto de datos de origen. Las tasas de BD se imprimen tanto para el submuestreo 420 como para 444 . PSNR_AVG se deriva de MSE_AVG , que es MSE ponderado en todos los componentes de color, ponderado según el número de muestras en los componentes de color respectivos.
También se incluye un script llamado analyze_encoding_results.py que
El guión toma dos argumentos:
python3 analyze_encoding_results.py [metric_name like vmaf OR ssim] [db file name]
Cabe señalar que la tasa de BD proporciona un número agregado sobre toda la gama de cualidades objetivo. Si se analiza únicamente la tasa de BD, es posible que se pierdan ciertos conocimientos, por ejemplo, ¿cómo se compara la eficiencia de la compresión, por ejemplo, específicamente para el punto operativo VMAF=95?
Otro ejemplo es, digamos que la tasa de BD es cero. Es muy posible que las curvas de velocidad-calidad se crucen y un códec sea significativamente mejor que el otro en, digamos, el punto operativo VMAF=95, y peor en la región de menor tasa de bits.
Idealmente, cuando los recursos de imagen se codifican para su uso en la interfaz de usuario, sería deseable tener una calidad operativa bien definida, como VMAF=95. Y podría decirse que los resultados de la región de menor calidad podrían ser irrelevantes. Los conocimientos descritos en (b) aumentan así el conocimiento "general" que ofrece la tasa de BD.
El número de procesos de trabajo simultáneos se puede especificar en
pool = multiprocessing.Pool(processes=4, initializer=initialize_worker)
Dado el sistema en el que se está ejecutando, la simultaneidad razonable podría estar limitada por la cantidad de núcleos de procesador o la cantidad de RAM disponible versus la memoria consumida por el proceso codificador más exigente en el conjunto de códecs que se están probando. Por ejemplo, si una instancia de encoder_A normalmente consume 5 GB de RAM y tiene 32 GB de RAM en total, entonces la simultaneidad razonable podría limitarse a 6 (32/5) incluso si tiene 24 (o más de 6) núcleos de procesador.
Idealmente, una implementación de codificador consume entrada YUV y genera un flujo codificado. Idealmente, una implementación de decodificador consume el flujo codificado y lo decodifica en salida YUV. Luego calculamos métricas en el espacio YUV. Sin embargo, existen implementaciones como el software JPEG-XT que consumen entradas PPM y producen salidas PPM. En tales casos, puede haber una conversión de PPM a YUV de origen y también una conversión de PPM a YUV decodificada antes del cálculo de calidad en el espacio YUV. Los pasos de conversión adicionales, en comparación con el proceso normal, pueden introducir una ligera distorsión, pero en nuestros experimentos esos pasos no hacen ninguna mella notable en la puntuación VMAF.