[Papel] [Página del proyecto] [Modelo miniFLUX] [Modelo SD3 ⚡️] [¿demostración?]
Este es el repositorio oficial de Pyramid Flow, un método de generación de video autorregresivo eficiente para el entrenamiento basado en Flow Matching . Al entrenar solo en conjuntos de datos de código abierto , puede generar videos de 10 segundos de alta calidad con una resolución de 768p y 24 FPS y, naturalmente, admite la generación de imagen a video.
| 10s, 768p, 24fps | 5s, 768p, 24fps | Imagen a vídeo |
|---|---|---|
fuegos artificiales.mp4 | remolque.mp4 | domingo.mp4 |
2024.11.13 Estrenamos el punto de control miniFLUX 768p (hasta 10s).
Hemos cambiado la estructura del modelo de SD3 a un mini FLUX para solucionar problemas de estructura humana. Pruebe nuestro punto de control de imagen de 1024p, punto de control de video de 384p (hasta 5 segundos) y punto de control de video de 768p (hasta 10 segundos). El nuevo modelo miniflux muestra una gran mejora en la estructura humana y la estabilidad del movimiento.
2024.10.29 ⚡️⚡️⚡️ Lanzamos código de entrenamiento para VAE, código de ajuste para DiT y nuevos puntos de control modelo con estructura FLUX entrenados desde cero.
2024.10.13 Se admite la inferencia de múltiples GPU y la descarga de CPU. Úselo con menos de 8 GB de memoria GPU, con gran velocidad en múltiples GPU.
2024.10.11 ??? La demostración de Hugging Face está disponible. ¡Gracias @multimodalart por el compromiso!
2024.10.10 Publicamos el informe técnico, la página del proyecto y el punto de control del modelo de Pyramid Flow.
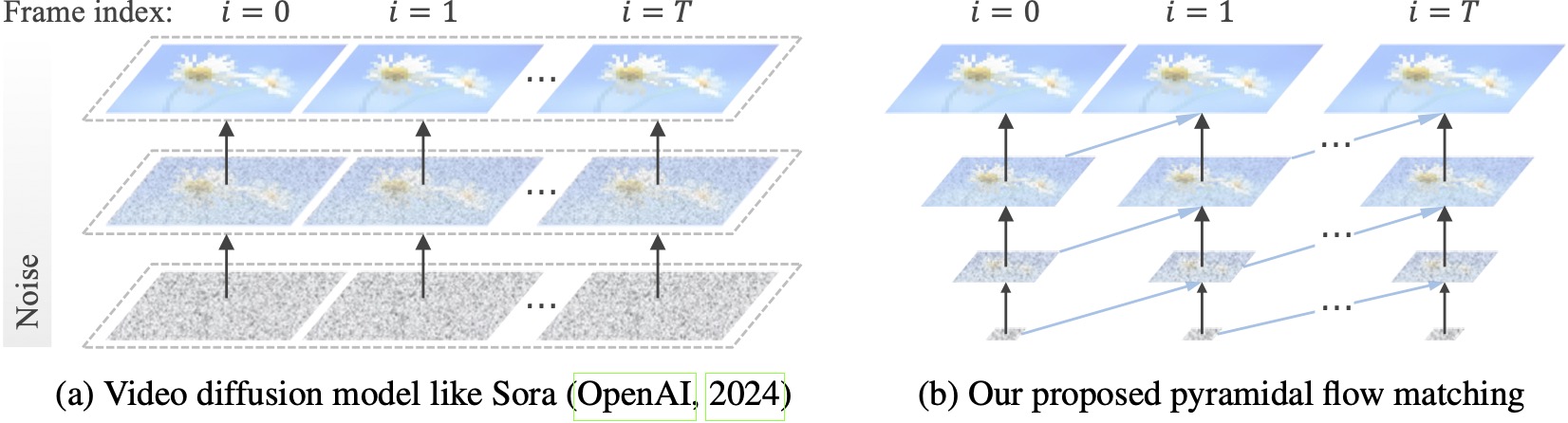
Los modelos de difusión de vídeo existentes funcionan a máxima resolución y gastan una gran cantidad de cálculo en latentes muy ruidosas. Por el contrario, nuestro método aprovecha la flexibilidad de la coincidencia de flujo (Lipman et al., 2023; Liu et al., 2023; Albergo & Vanden-Eijnden, 2023) para interpolar entre latentes de diferentes resoluciones y niveles de ruido, lo que permite la generación simultánea y descompresión de contenido visual con mejor eficiencia computacional. Todo el marco está optimizado de extremo a extremo con un único DiT (Peebles & Xie, 2023), generando vídeos de alta calidad de 10 segundos con una resolución de 768p y 24 FPS en 20,7k horas de entrenamiento de GPU A100.
Recomendamos configurar el entorno con conda. El código base actualmente utiliza Python 3.8.10 y PyTorch 2.1.2 (guía), y estamos trabajando activamente para admitir una gama más amplia de versiones.
git clone https://github.com/jy0205/Pyramid-Flow
cd Pyramid-Flow
# create env using conda
conda create -n pyramid python==3.8.10
conda activate pyramid
pip install -r requirements.txtLuego, descarga el modelo desde Huggingface (hay dos variantes: miniFLUX o SD3). Los modelos miniFLUX admiten generación de imágenes de 1024p y video de 384p y 768p, y los modelos basados en SD3 admiten generación de video de 768p y 384p. El punto de control de 384p genera video de 5 segundos a 24 FPS, mientras que el punto de control de 768p genera video de hasta 10 segundos a 24 FPS.
from huggingface_hub import snapshot_download
model_path = 'PATH' # The local directory to save downloaded checkpoint
snapshot_download ( "rain1011/pyramid-flow-miniflux" , local_dir = model_path , local_dir_use_symlinks = False , repo_type = 'model' )Para comenzar, primero instale Gradio, configure la ruta de su modelo en #L36 y luego ejecútelo en su máquina local:
python app.pyLa demostración de Gradio se abrirá en un navegador. Gracias a @tpc2233 por el compromiso; consulte el n.º 48 para obtener más detalles.
¿O probarlo sin esfuerzo en Hugging Face Space? creado por @multimodalart. Debido a los límites de la GPU, esta demostración en línea solo puede generar 25 fotogramas (exportar a 8 FPS o 24 FPS). Duplica el espacio para generar videos más largos.
Para probar rápidamente Pyramid Flow en Google Colab, ejecute el siguiente código:
# Setup
!git clone https://github.com/jy0205/Pyramid-Flow
%cd Pyramid-Flow
!pip install -r requirements.txt
!pip install gradio
# This code downloads miniFLUX
from huggingface_hub import snapshot_download
model_path = '/content/Pyramid-Flow'
snapshot_download("rain1011/pyramid-flow-miniflux", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')
# Start
!python app.py
Para utilizar nuestro modelo, siga el código de inferencia en video_generation_demo.ipynb en este enlace. Le recomendamos encarecidamente que pruebe el último Pyramid-miniflux publicado, que muestra una gran mejora en la estructura humana y la estabilidad del movimiento. Establezca el parámetro model_name en pyramid_flux para usar. Lo simplificamos aún más en el siguiente procedimiento de dos pasos. Primero, cargue el modelo descargado:
import torch
from PIL import Image
from pyramid_dit import PyramidDiTForVideoGeneration
from diffusers . utils import load_image , export_to_video
torch . cuda . set_device ( 0 )
model_dtype , torch_dtype = 'bf16' , torch . bfloat16 # Use bf16 (not support fp16 yet)
model = PyramidDiTForVideoGeneration (
'PATH' , # The downloaded checkpoint dir
model_name = "pyramid_flux" ,
model_dtype ,
model_variant = 'diffusion_transformer_768p' ,
)
model . vae . enable_tiling ()
# model.vae.to("cuda")
# model.dit.to("cuda")
# model.text_encoder.to("cuda")
# if you're not using sequential offloading bellow uncomment the lines above ^
model . enable_sequential_cpu_offload ()Luego, puede probar la generación de texto a video según sus propias indicaciones. Tenga en cuenta que la versión 384p ahora solo admite 5 (configure la temperatura en 16).
prompt = "A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors"
# used for 384p model variant
# width = 640
# height = 384
# used for 768p model variant
width = 1280
height = 768
with torch . no_grad (), torch . cuda . amp . autocast ( enabled = True , dtype = torch_dtype ):
frames = model . generate (
prompt = prompt ,
num_inference_steps = [ 20 , 20 , 20 ],
video_num_inference_steps = [ 10 , 10 , 10 ],
height = height ,
width = width ,
temp = 16 , # temp=16: 5s, temp=31: 10s
guidance_scale = 7.0 , # The guidance for the first frame, set it to 7 for 384p variant
video_guidance_scale = 5.0 , # The guidance for the other video latent
output_type = "pil" ,
save_memory = True , # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video ( frames , "./text_to_video_sample.mp4" , fps = 24 )Como modelo autorregresivo, nuestro modelo también admite la generación de imagen a video (condicionada por texto):
# used for 384p model variant
# width = 640
# height = 384
# used for 768p model variant
width = 1280
height = 768
image = Image . open ( 'assets/the_great_wall.jpg' ). convert ( "RGB" ). resize (( width , height ))
prompt = "FPV flying over the Great Wall"
with torch . no_grad (), torch . cuda . amp . autocast ( enabled = True , dtype = torch_dtype ):
frames = model . generate_i2v (
prompt = prompt ,
input_image = image ,
num_inference_steps = [ 10 , 10 , 10 ],
temp = 16 ,
video_guidance_scale = 4.0 ,
output_type = "pil" ,
save_memory = True , # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video ( frames , "./image_to_video_sample.mp4" , fps = 24 )También admitimos dos tipos de descarga de CPU para reducir los requisitos de memoria de GPU. Tenga en cuenta que pueden sacrificar la eficiencia.
cpu_offloading=True a la función de generación permite realizar inferencias con menos de 12 GB de memoria de GPU. Esta característica fue aportada por @Ednaordinary; consulte el n.° 23 para obtener más detalles.model.enable_sequential_cpu_offload() antes del procedimiento anterior permite realizar inferencias con menos de 8 GB de memoria de GPU. Esta característica fue aportada por @rodjjo; consulte el n.° 75 para obtener más detalles. Gracias a @niw, los usuarios de Apple Silicon (por ejemplo, MacBook Pro con M2 de 24 GB) también pueden probar nuestro modelo utilizando el backend MPS. Consulte el n.° 113 para obtener más detalles.
Para los usuarios con varias GPU, proporcionamos un script de inferencia que utiliza el paralelismo de secuencia para ahorrar memoria en cada GPU. Esto también aporta una gran aceleración, ya que solo toma 2,5 minutos generar un video de 5 s, 768p y 24 fps en 4 GPU A100 (frente a 5,5 minutos en una sola GPU A100). Ejecútelo en 2 GPU con el siguiente comando:
CUDA_VISIBLE_DEVICES=0,1 sh scripts/inference_multigpu.shActualmente admite 2 o 4 GPU (para la versión SD3), con más configuraciones disponibles en el script original. También puede iniciar una demostración de Gradio con múltiples GPU creada por @tpc2233; consulte el n.° 59 para obtener más detalles.
Spoiler: ni siquiera utilizamos el paralelismo de secuencias en el entrenamiento, gracias a nuestros eficientes diseños de flujo piramidal.
guidance_scale controla la calidad visual. Sugerimos utilizar una guía dentro de [7, 9] para el punto de control de 768p durante la generación de texto a video y 7 para el punto de control de 384p.video_guidance_scale controla el movimiento. Un valor mayor aumenta el grado dinámico y mitiga la degradación de la generación autorregresiva, mientras que un valor menor estabiliza el vídeo.Los requisitos de hardware para entrenar VAE son al menos 8 GPU A100. Consulte este documento. Este es un VAE 3D continuo tipo MAGVIT-v2, que debería ser bastante flexible. Siéntase libre de crear su propio modelo generativo de video en esta parte del código de capacitación de VAE.
Los requisitos de hardware para ajustar DiT son al menos 8 GPU A100. Consulte este documento. Proporcionamos instrucciones para las versiones autorregresivas y no autorregresivas de Pyramid Flow. El primero está más orientado a la investigación y el segundo es más estable (pero menos eficiente sin una pirámide temporal).
Los siguientes ejemplos de vídeo se generan a 5 s, 768p, 24 fps. Para obtener más resultados, visite nuestra página de proyecto.
tokio.mp4 | eiffel.mp4 |
ondas.mp4 | carril.mp4 |
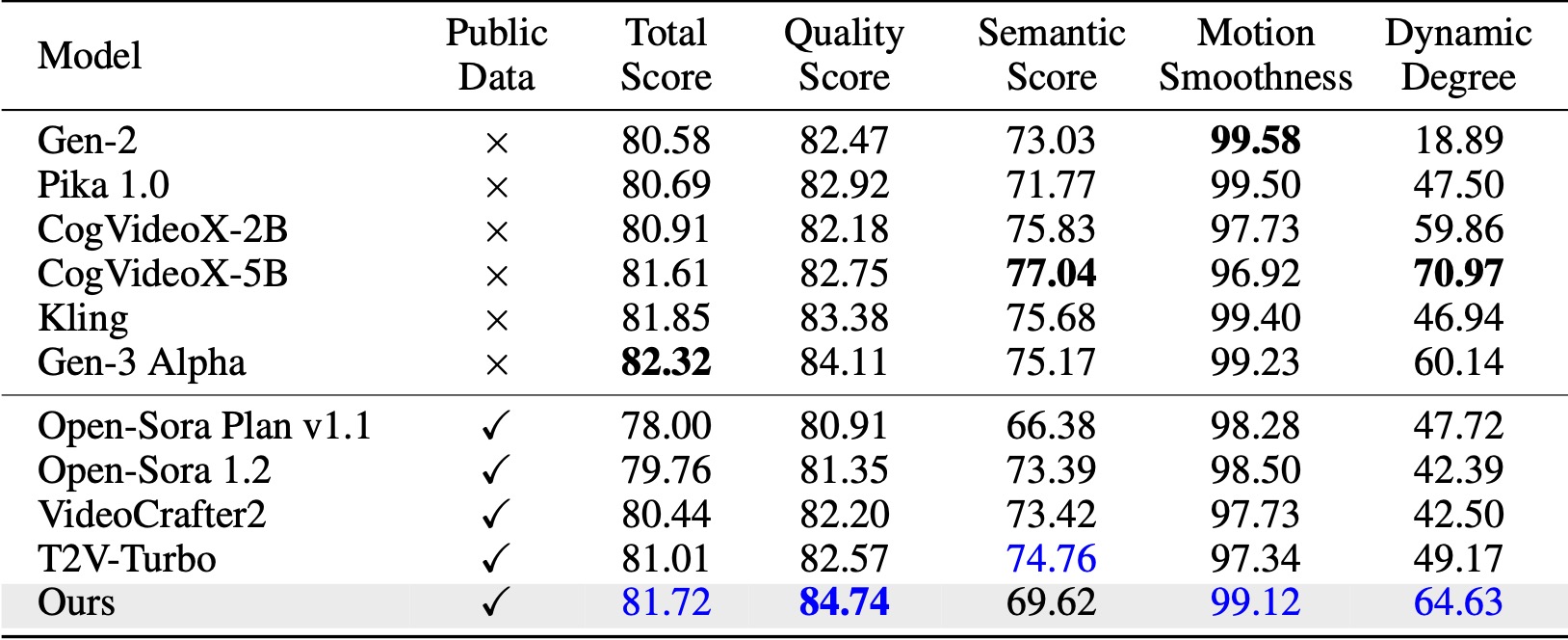
En VBench (Huang et al., 2024), nuestro método supera todas las líneas base de código abierto comparadas. Incluso con solo datos de vídeo públicos, logra un rendimiento comparable al de modelos comerciales como Kling (Kuaishou, 2024) y Gen-3 Alpha (Runway, 2024), especialmente en la puntuación de calidad (84,74 frente a 84,11 de Gen-3) y la suavidad del movimiento. .
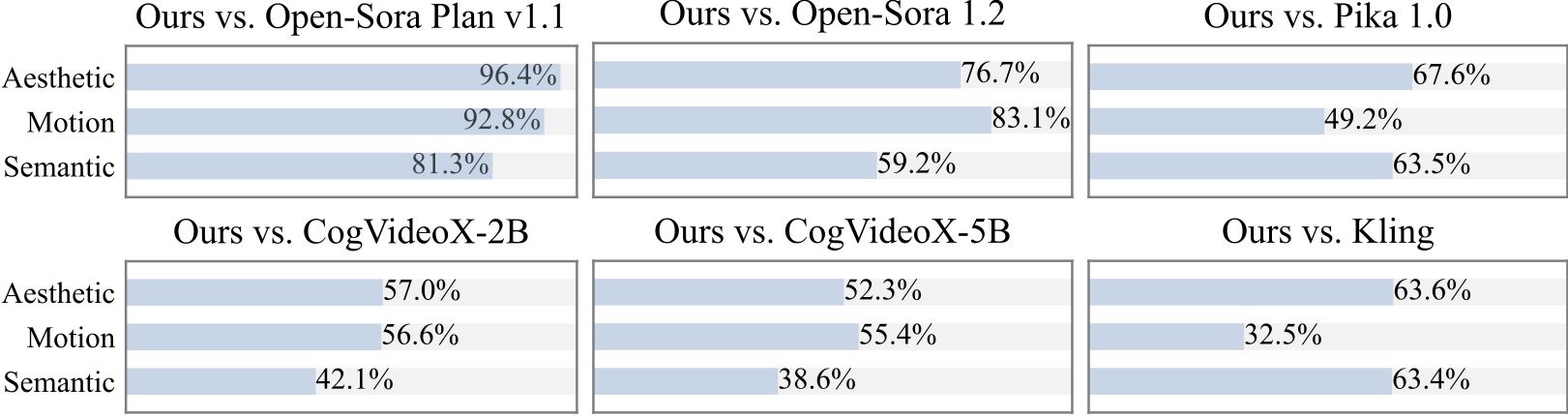
Realizamos un estudio de usuario adicional con más de 20 participantes. Como puede verse, nuestro método es preferido a los modelos de código abierto como Open-Sora y CogVideoX-2B, especialmente en términos de suavidad de movimiento.
Estamos agradecidos por los siguientes increíbles proyectos al implementar Pyramid Flow:
Considere darle una estrella a este repositorio y cite Pyramid Flow en sus publicaciones si le ayuda en su investigación.
@article{jin2024pyramidal,
title={Pyramidal Flow Matching for Efficient Video Generative Modeling},
author={Jin, Yang and Sun, Zhicheng and Li, Ningyuan and Xu, Kun and Xu, Kun and Jiang, Hao and Zhuang, Nan and Huang, Quzhe and Song, Yang and Mu, Yadong and Lin, Zhouchen},
jounal={arXiv preprint arXiv:2410.05954},
year={2024}
}


