nim anywhere
1.0.0

Únase al canal flojo #cdd-nim-anywhere si es un usuario interno, abra un problema si es externo para cualquier pregunta o comentario.
Uno de los principales beneficios del uso de la IA para las empresas es su capacidad para trabajar con sus datos internos y aprender de ellos. La generación aumentada de recuperación (RAG) es una de las mejores formas de hacerlo. NVIDIA ha desarrollado un conjunto de microservicios llamado microservicio NIM para ayudar a nuestros socios y clientes a crear un canal RAG eficaz con facilidad.
NIM Anywhere contiene todas las herramientas necesarias para comenzar a integrar NIM para RAG. Se escala de forma nativa a laboratorios de tamaño completo y hasta entornos de producción. Esta es una gran noticia para crear una arquitectura RAG y agregar fácilmente NIM según sea necesario. Si no está familiarizado con RAG, recupera dinámicamente información externa relevante durante la inferencia sin modificar el modelo en sí. Imagine que es el líder tecnológico de una empresa con una base de datos local que contiene información confidencial y actualizada. No desea que OpenAI acceda a sus datos, pero necesita que el modelo los comprenda para responder las preguntas con precisión. La solución es conectar su modelo de lenguaje a la base de datos y alimentarlos con la información.
Para obtener más información sobre por qué RAG es una excelente solución para aumentar la precisión y confiabilidad de sus modelos de IA generativa, lea este blog.
¡Comience a utilizar NIM Anywhere ahora con las instrucciones de inicio rápido y cree su primera aplicación RAG utilizando NIM!
Para permitir que AI Workbench acceda a los recursos de la nube de NVIDIA, deberá proporcionarle una clave personal. Estas claves comienzan con nvapi- .
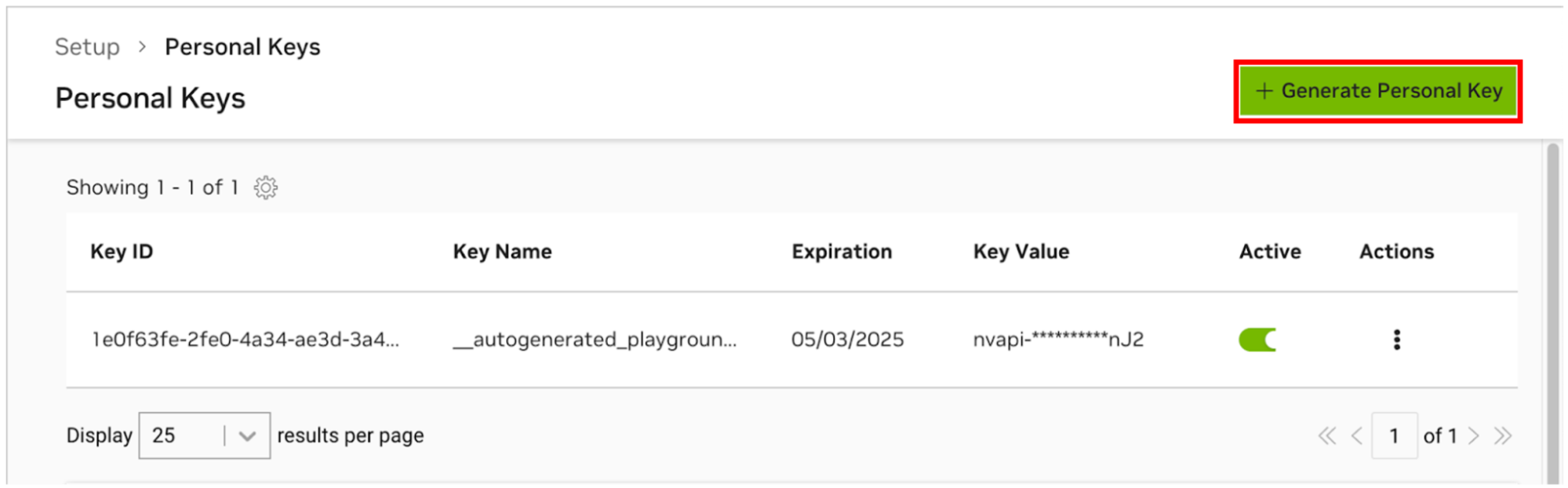
Vaya al Administrador de claves personales de NGC. Si se le solicita, regístrese para obtener una nueva cuenta e inicie sesión.
SUGERENCIA Puede encontrar esta herramienta iniciando sesión en ngc.nvidia.com, expandiendo el menú de su perfil en la parte superior derecha, seleccionando Configuración y luego seleccionando Generar clave personal .
Seleccione Generar clave personal .
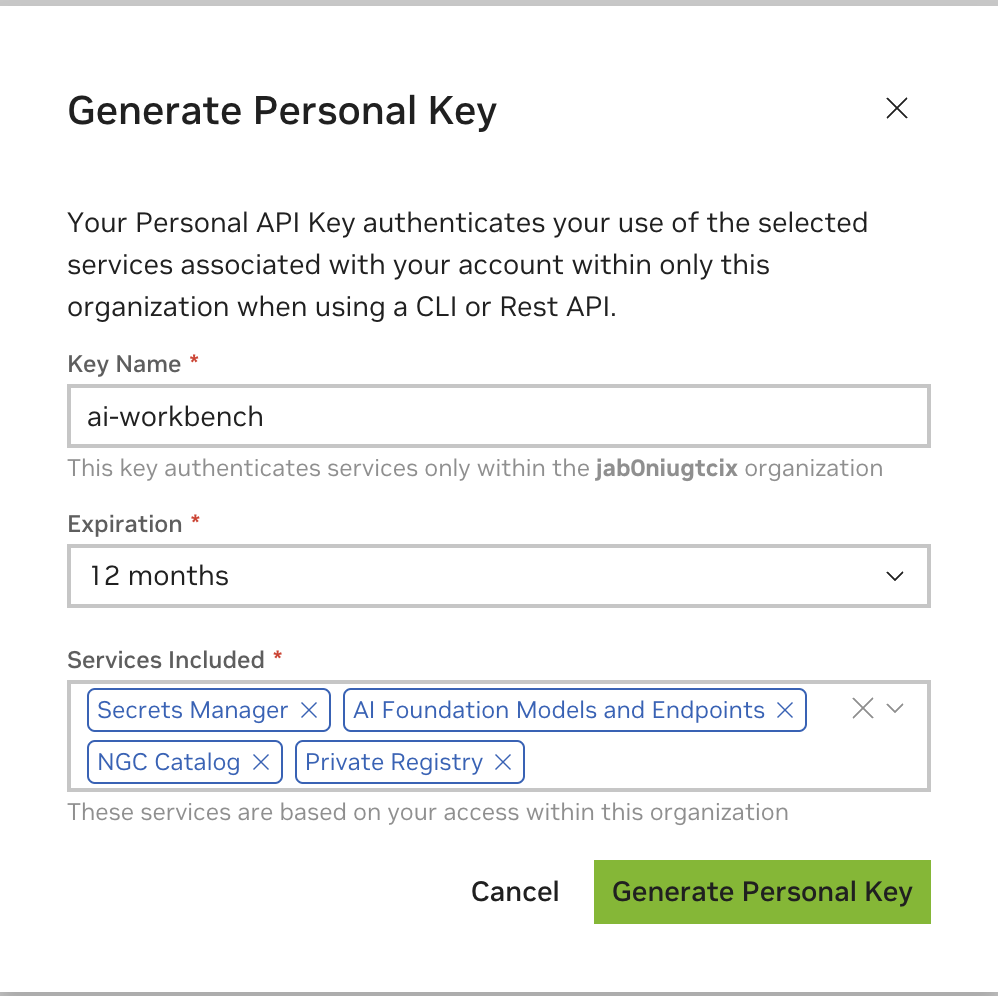
Ingrese cualquier valor como nombre de clave, un vencimiento de 12 meses está bien y seleccione todos los servicios. Presione Generar clave personal cuando haya terminado.
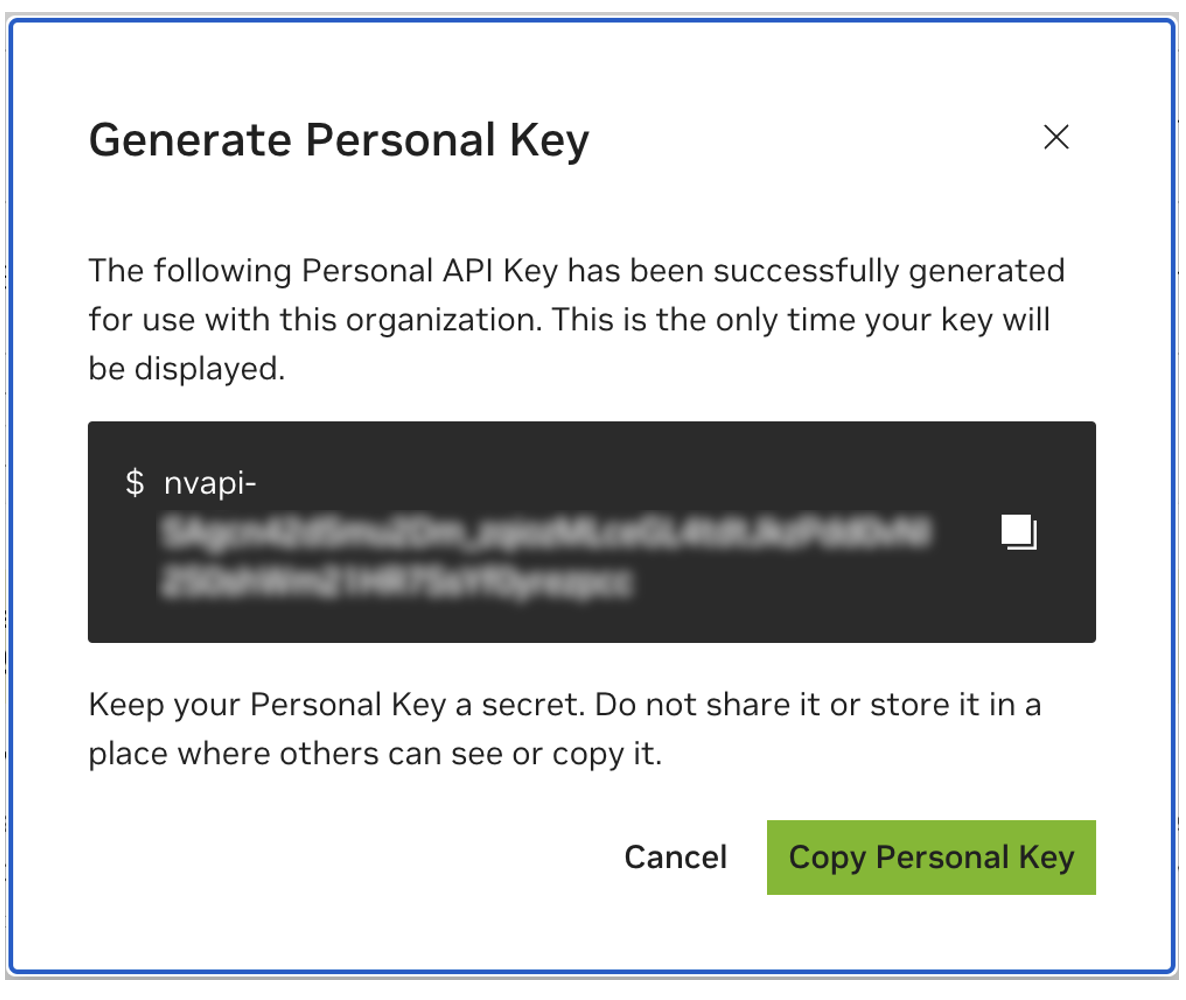
Guarde su clave personal para más tarde. Workbench lo necesitará y no hay forma de recuperarlo más adelante. Si se pierde la clave, se debe crear una nueva. Protege esta clave como si fuera una contraseña.
Este proyecto está diseñado para usarse con NVIDIA AI Workbench. Si bien esto no es un requisito, ejecutar esta demostración sin AI Workbench requerirá trabajo manual, ya que es posible que la automatización y las integraciones preconfiguradas no estén disponibles.
Esta guía de inicio rápido asumirá que se está utilizando una máquina de laboratorio remota para el desarrollo y que la máquina local es un cliente ligero para acceder de forma remota a la máquina de desarrollo. Esto permite que los recursos informáticos permanezcan ubicados de forma centralizada y que los desarrolladores sean más portátiles. Tenga en cuenta que la máquina del laboratorio remoto debe ejecutar Ubuntu, pero el cliente local puede ejecutar Windows, MacOS o Ubuntu. Para instalar este proyecto solo localmente, simplemente omita la instalación remota.
diagrama de flujo LR
local
entorno de laboratorio de subgrafos
maquina-de-laboratorio-remoto
fin
local <-.ssh.-> máquina-de-laboratorio-remoto
Se requiere Ubuntu si el cliente local también se utilizará para el desarrollo. Cuando se utiliza una máquina de laboratorio remota, puede ser Windows, MacOS o Ubuntu.
Para obtener instrucciones completas, consulte la Guía del usuario de NVIDIA AI Workbench.
Instalar el software requerido previamente
Descargue el instalador de NVIDIA AI Workbench y ejecútelo. Autorice a Windows para permitir que el instalador realice cambios.
Siga las instrucciones del asistente de instalación. Si necesita instalar WSL2, autorice a Windows a realizar los cambios y reinicie la máquina local cuando se le solicite. Cuando el sistema se reinicie, el instalador de NVIDIA AI Workbench debería reanudarse automáticamente.
Seleccione Docker como tiempo de ejecución de su contenedor.
Inicie sesión en su cuenta de GitHub utilizando la opción Iniciar sesión a través de GitHub.com .
Ingrese su información de autor de git si se le solicita.
Para obtener instrucciones completas, consulte la Guía del usuario de NVIDIA AI Workbench.
Instalar el software requerido previamente
Descargue la imagen del disco NVIDIA AI Workbench (archivo .dmg ) y ábrala.
Arrastre AI Workbench a la carpeta Aplicaciones y ejecute NVIDIA AI Workbench desde el iniciador de aplicaciones. 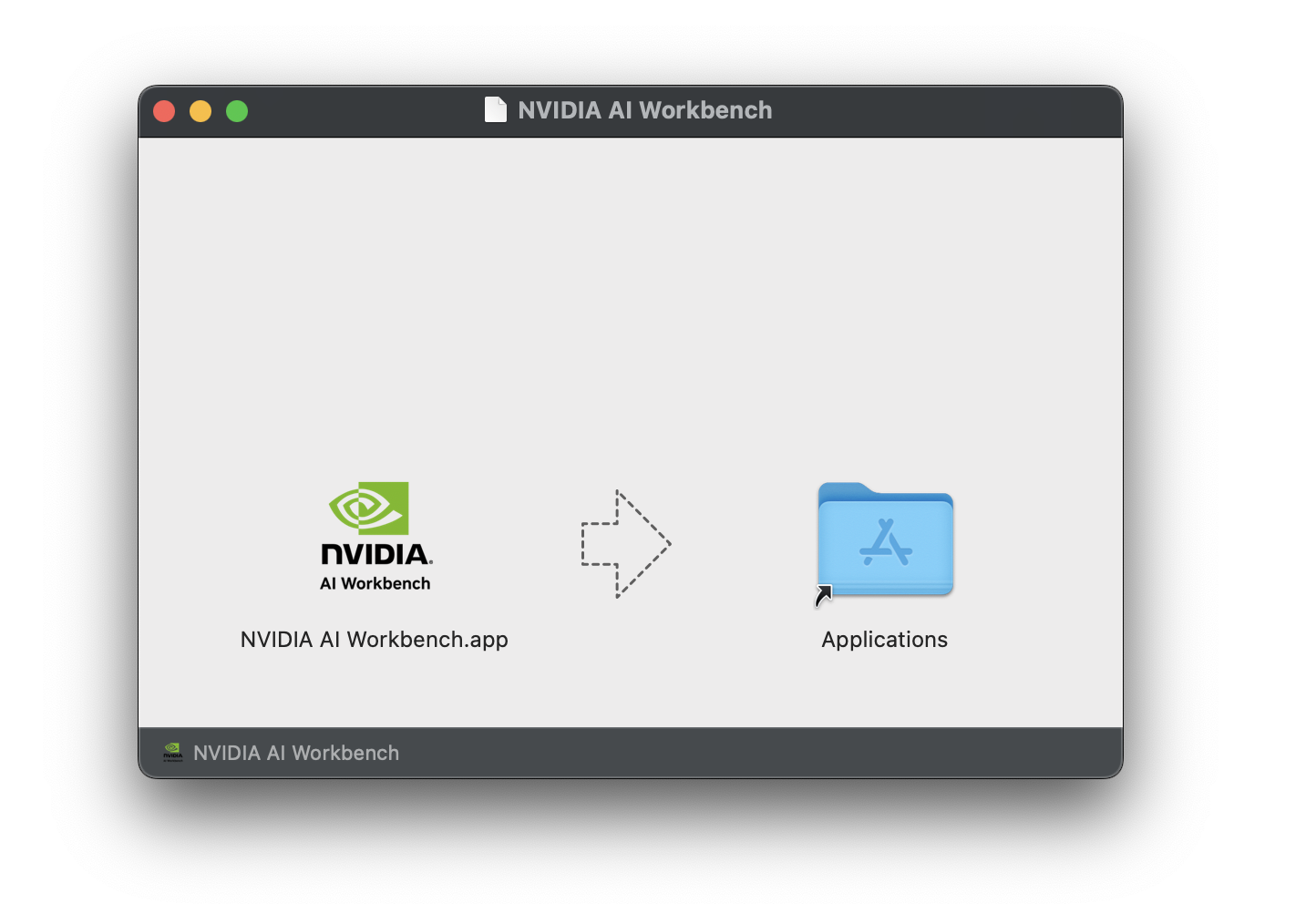
Seleccione Docker como tiempo de ejecución de su contenedor.
Inicie sesión en su cuenta de GitHub utilizando la opción Iniciar sesión a través de GitHub.com .
Ingrese su información de autor de git si se le solicita.
Para obtener instrucciones completas, consulte la Guía del usuario de NVIDIA AI Workbench. Ejecute esta instalación como el usuario que será el usuario de Workbench. No ejecute estos pasos como root .
Instalar el software requerido previamente
Descargue el instalador de NVIDIA AI Workbench, hágalo ejecutable y luego ejecútelo. Puede hacer que el archivo sea ejecutable con el siguiente comando:
chmod +x NVIDIA-AI-Workbench- * .AppImageAI Workbench instalará los controladores NVIDIA por usted (si es necesario). Deberá reiniciar su máquina local después de instalar los controladores y luego reiniciar la instalación de AI Workbench haciendo doble clic en el icono de NVIDIA AI Workbench en su escritorio.
Seleccione Docker como tiempo de ejecución de su contenedor.
Inicie sesión en su cuenta de GitHub utilizando la opción Iniciar sesión a través de GitHub.com .
Ingrese su información de autor de git si se le solicita.
Sólo Ubuntu es compatible con máquinas remotas.
Para obtener instrucciones completas, consulte la Guía del usuario de NVIDIA AI Workbench. Ejecute esta instalación como el usuario que utilizará Workbench. No ejecute estos pasos como root .
Asegúrese de que la autenticación basada en clave SSH esté habilitada desde la máquina local a la máquina remota. Si esto no está habilitado actualmente, los siguientes comandos lo habilitarán en la mayoría de las situaciones. Cambie REMOTE_USER y REMOTE-MACHINE para reflejar su dirección remota.
ssh - keygen -f " C:Userslocal-user.sshid_rsa " - t rsa - N ' "" '
type $ env: USERPROFILE .sshid_rsa.pub | ssh REMOTE_USER @REMOTE - MACHINE " cat >> .ssh/authorized_keys " if [ ! -e ~ /.ssh/id_rsa ] ; then ssh-keygen -f ~ /.ssh/id_rsa -t rsa -N " " ; fi
ssh-copy-id REMOTE_USER@REMOTE-MACHINESSH en el host remoto. Luego, use los siguientes comandos para descargar y ejecutar el instalador de NVIDIA AI Workbench.
mkdir -p $HOME /.nvwb/bin &&
curl -L https://workbench.download.nvidia.com/stable/workbench-cli/ $( curl -L -s https://workbench.download.nvidia.com/stable/workbench-cli/LATEST ) /nvwb-cli- $( uname ) - $( uname -m ) --output $HOME /.nvwb/bin/nvwb-cli &&
chmod +x $HOME /.nvwb/bin/nvwb-cli &&
sudo -E $HOME /.nvwb/bin/nvwb-cli installAI Workbench instalará los controladores NVIDIA por usted (si es necesario). Deberá reiniciar su máquina remota después de instalar los controladores y luego reiniciar la instalación de AI Workbench volviendo a ejecutar los comandos del paso anterior.
Seleccione Docker como tiempo de ejecución de su contenedor.
Inicie sesión en su cuenta de GitHub utilizando la opción Iniciar sesión a través de GitHub.com .
Ingrese su información de autor de git si se le solicita.
Una vez que se completa la instalación remota, la ubicación remota se puede agregar a la instancia local de AI Workbench. Abra la aplicación AI Workbench, haga clic en Agregar ubicación remota y luego ingrese la información requerida. Cuando termine, haga clic en Agregar ubicación .
REMOTE-MACHINE .REMOTE_USER ./home/USER/.ssh/id_rsa .Hay dos formas de descargar este proyecto para uso local: clonación y bifurcación.
Clonar este repositorio es la forma recomendada de comenzar. Esto no permitirá modificaciones locales, pero es el inicio más rápido. Esto también permite la forma más sencilla de obtener actualizaciones.
Se recomienda bifurcar este repositorio para el desarrollo, ya que los cambios se podrán guardar. Sin embargo, para obtener actualizaciones, el mantenedor de la bifurcación tendrá que extraerlas periódicamente del repositorio ascendente. Para trabajar desde una bifurcación, siga las instrucciones de GitHub y luego haga referencia a la URL de su bifurcación personal en el resto de esta sección.
Abra la ventana local de NVIDIA AI Workbench. De la lista de ubicaciones que se muestran, seleccione la remota que acaba de configurar o la local si va a trabajar localmente.
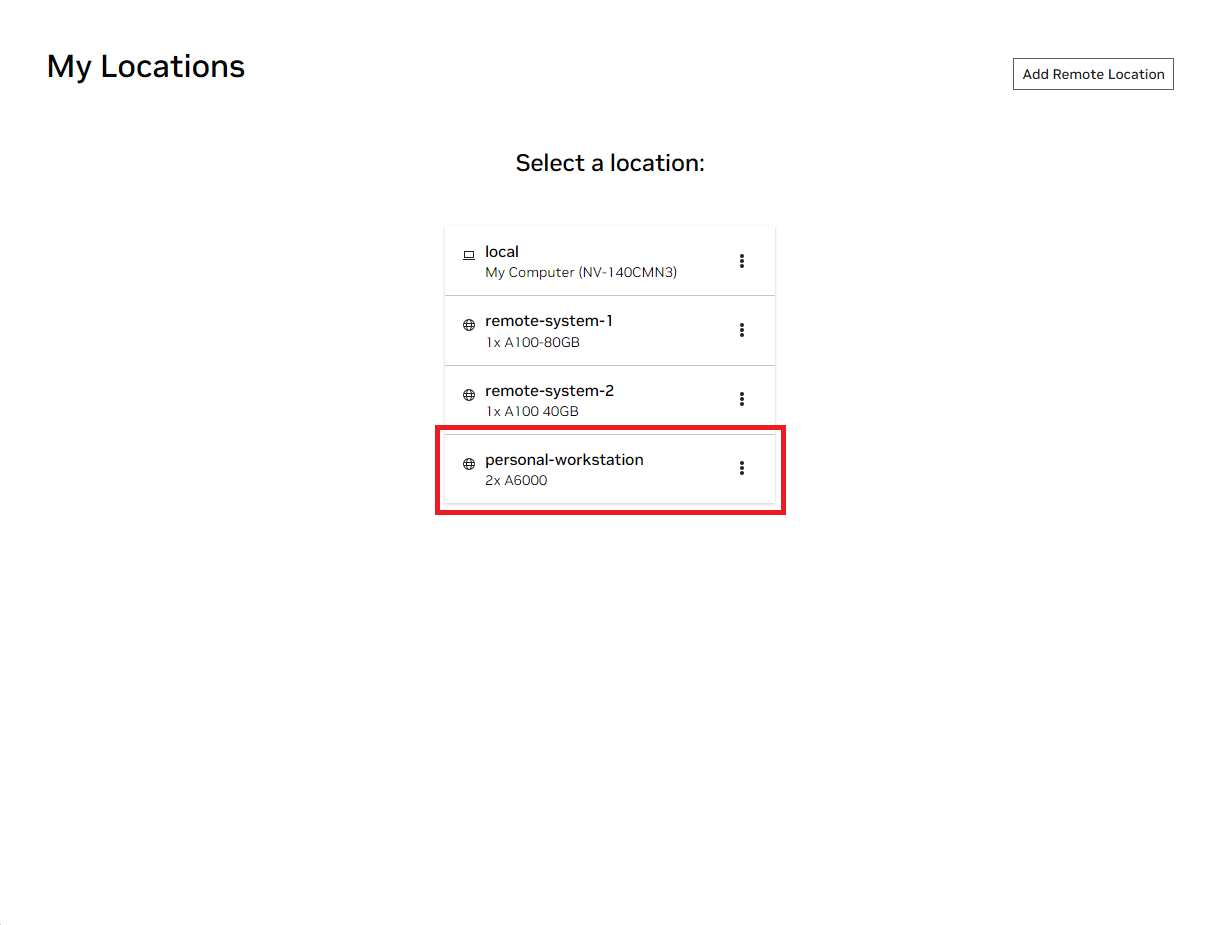
Una vez dentro de la ubicación, seleccione Clonar Proyecto .
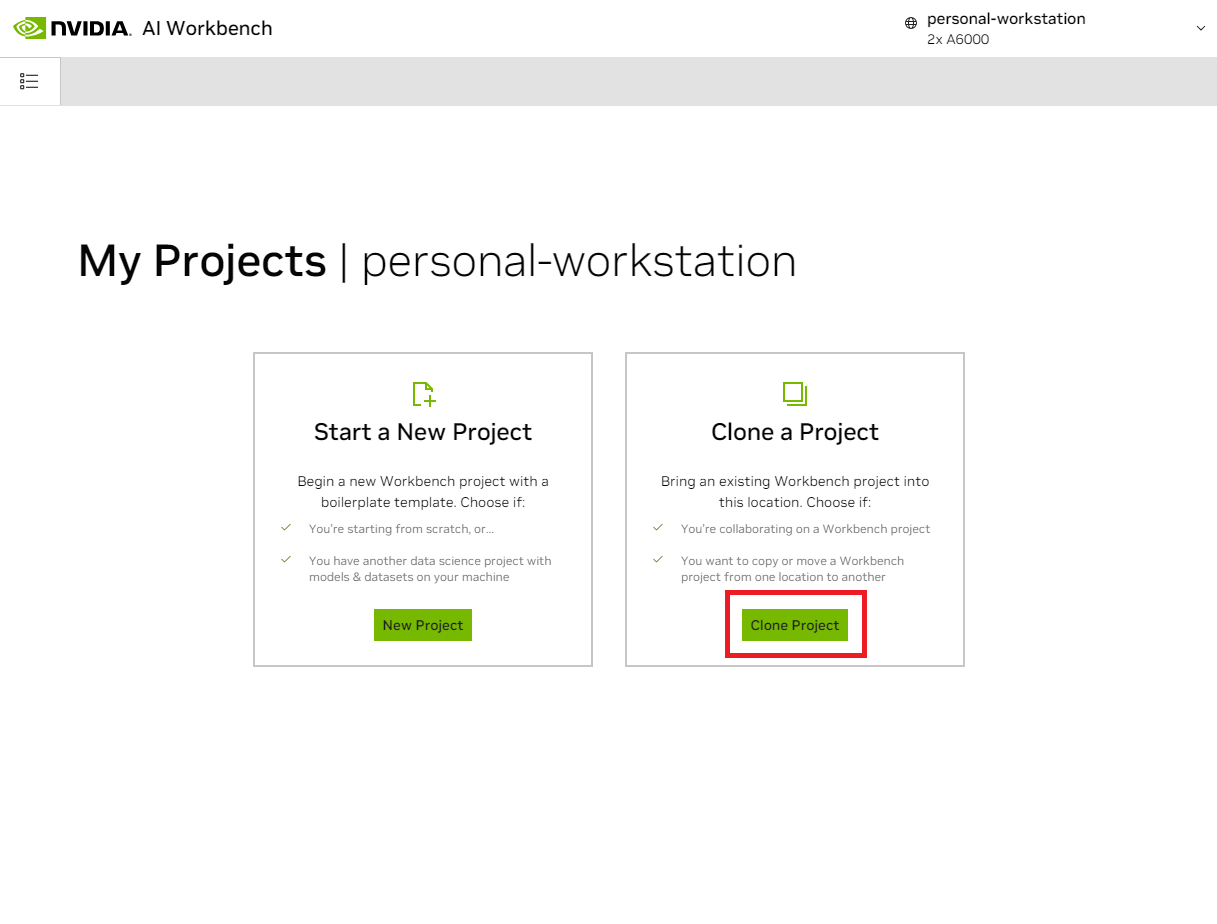
En la ventana emergente 'Clonar proyecto', configure la URL del repositorio en https://github.com/NVIDIA/nim-anywhere.git . Puede dejar la Ruta como predeterminada /home/REMOTE_USER/nvidia-workbench/nim-anywhere.git . Haga clic en Clonar.`
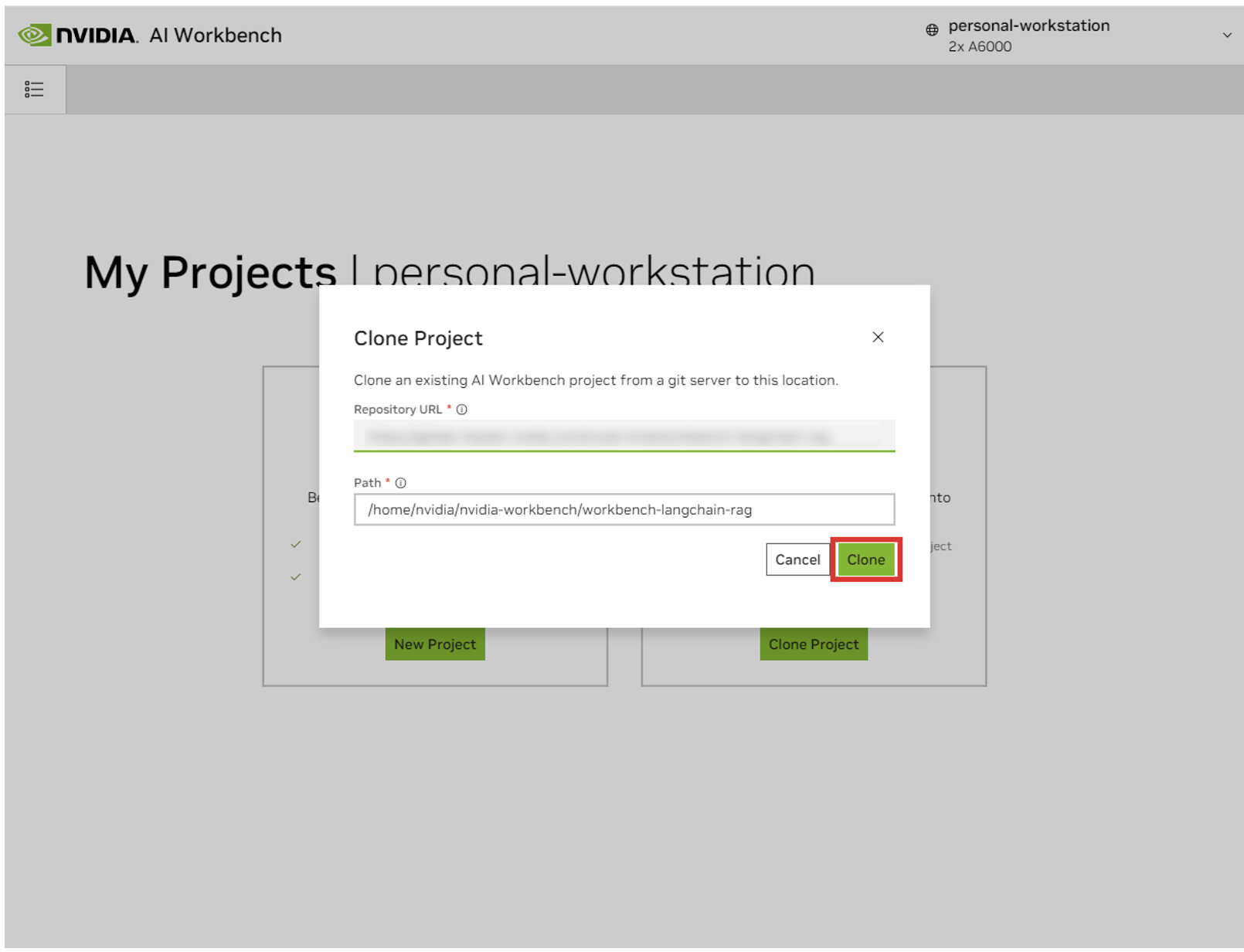
Serás redirigido a la página del nuevo proyecto. Workbench iniciará automáticamente el entorno de desarrollo. Puede ver el progreso en tiempo real expandiendo la Salida en la parte inferior de la ventana.
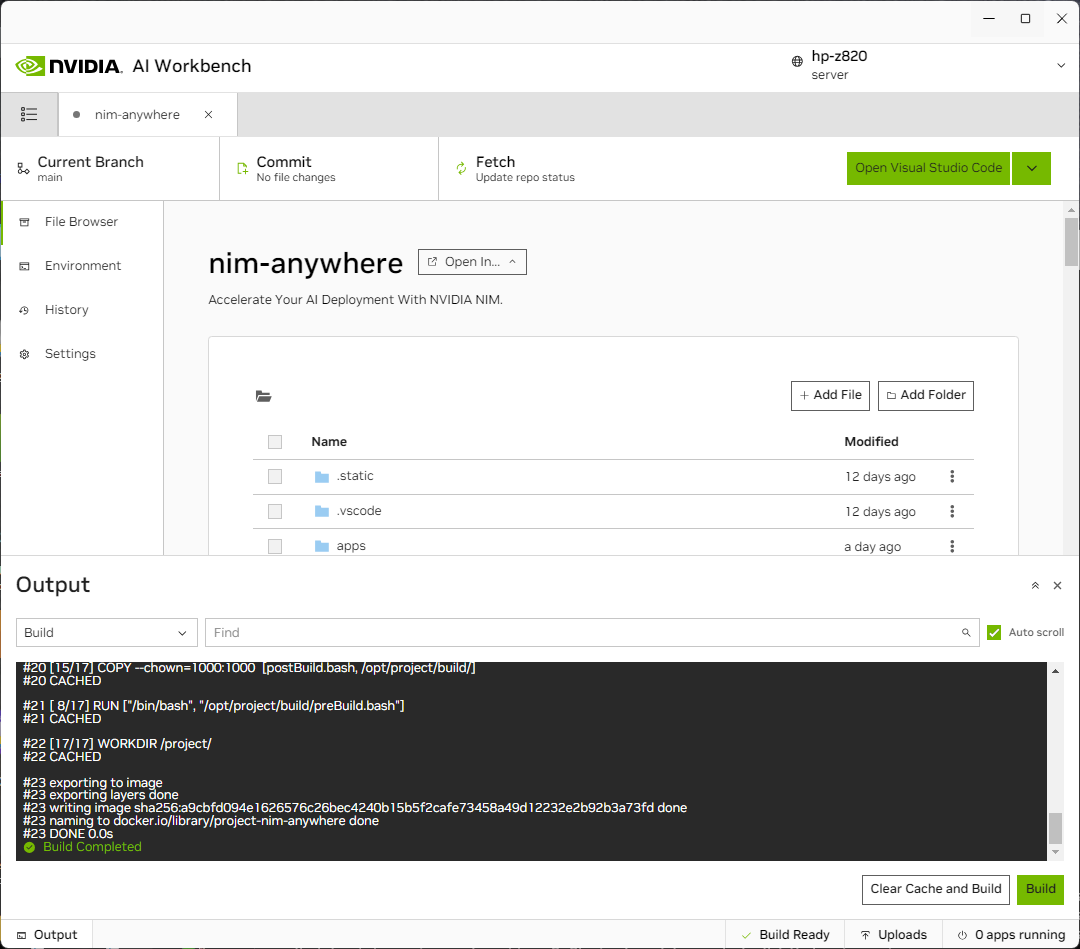
El proyecto debe configurarse para funcionar con recursos de la máquina local.
Antes de ejecutarlo por primera vez, se debe proporcionar la configuración específica del proyecto. La configuración del proyecto se realiza utilizando la pestaña Entorno del panel izquierdo.
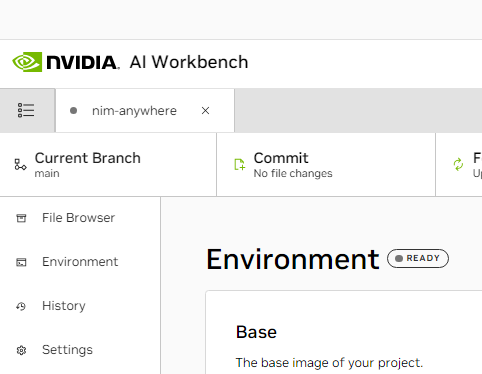
Desplácese hacia abajo hasta la sección Variables y busque la entrada NGC_HOME . Debería configurarse en algo como ~/.cache/nvidia-nims . El valor aquí lo utiliza el banco de trabajo. Esta misma ubicación también aparece en la sección Montajes que monta este directorio en el contenedor.
Desplácese hacia abajo hasta la sección Secretos y busque la entrada NGC_API_KEY . Presione Configurar y proporcione la clave personal para NGC que se generó anteriormente.
Desplácese hacia abajo hasta la sección Monturas . Aquí hay dos soportes para configurar.
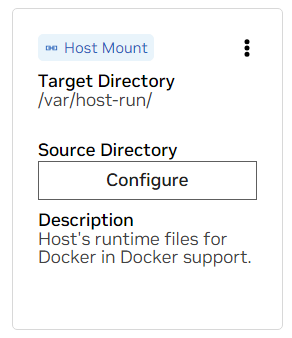
a. Busque el soporte para /var/host-run. Esto se utiliza para permitir que el entorno de desarrollo acceda al demonio Docker del host en un patrón llamado Docker fuera de Docker. Presione Configurar y proporcione el directorio /var/run .
b. Busque el soporte para /home/workbench/.cache/nvidia-nims. Este montaje se utiliza como caché de tiempo de ejecución para NIM donde pueden almacenar en caché archivos de modelo. Compartir este caché con el host reduce el uso del disco y el ancho de banda de la red.
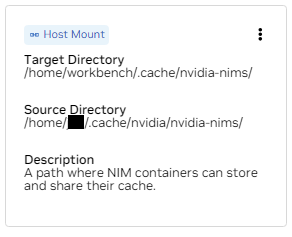
Si aún no tiene un caché nim, o no está seguro, use los siguientes comandos para crear uno en /home/USER/.cache/nvidia-nims .
mkdir -p ~ /.cache/nvidia-nims
chmod 2777 ~ /.cache/nvidia-nimsSe producirá una reconstrucción después de que se hayan cambiado estas configuraciones.
Una vez que la compilación se complete con un mensaje Build Ready , todas las aplicaciones estarán disponibles para usted.
Incluso las cadenas LLM más básicas dependen de algunos microservicios adicionales. Estos pueden ignorarse durante el desarrollo de alternativas en memoria, pero luego se requieren cambios de código para pasar a producción. Afortunadamente, Workbench gestiona esos microservicios adicionales para entornos de desarrollo.
SUGERENCIA: Para cada aplicación, la salida de depuración se puede monitorear en la interfaz de usuario haciendo clic en el enlace Salida en la esquina inferior izquierda, seleccionando el menú desplegable y eligiendo la aplicación de interés.
Todas las aplicaciones incluidas en este espacio de trabajo se pueden controlar navegando a Entorno > Aplicaciones .
Primero, active Milvus Vector DB y Redis . Milvus se utiliza como base de conocimientos no estructurada y Redis se utiliza para almacenar historiales de conversaciones.
Una vez que se hayan iniciado estos servicios, se puede iniciar Chain Server de forma segura. Contiene el código LangChain personalizado para realizar nuestra cadena de razonamiento. De forma predeterminada, utilizará Milvus y Redis locales, pero utilizará ai.nvidia.com para la inferencia de modelos LLM e incrustación.
[OPCIONAL]: A continuación, inicie LLM NIM . La primera vez que se inicia LLM NIM, llevará algún tiempo descargar la imagen y los modelos optimizados.
a. Durante un inicio prolongado, para confirmar que LLM NIM se está iniciando, se puede observar el progreso viendo los registros mediante el panel Salida en la parte inferior izquierda de la interfaz de usuario.
b. Si los registros indican un error de autenticación, eso significa que la NGC_API_KEY proporcionada no tiene acceso a los NIM. Verifique que se haya generado correctamente y en una organización NGC que tenga soporte o prueba de NVIDIA AI Enterprise.
do. Si los registros parecen estar atascados en ..........: Pull complete . ..........: Verifying complete , o ..........: Download complete ; Todo esto es un resultado normal de Docker de que se han descargado las distintas capas de la imagen del contenedor.
d. Es necesario abordar cualquier otro fallo aquí.
Una vez que el servidor de cadena esté activo, se puede iniciar la interfaz de chat . Al iniciar la interfaz, se abrirá automáticamente en una ventana del navegador.
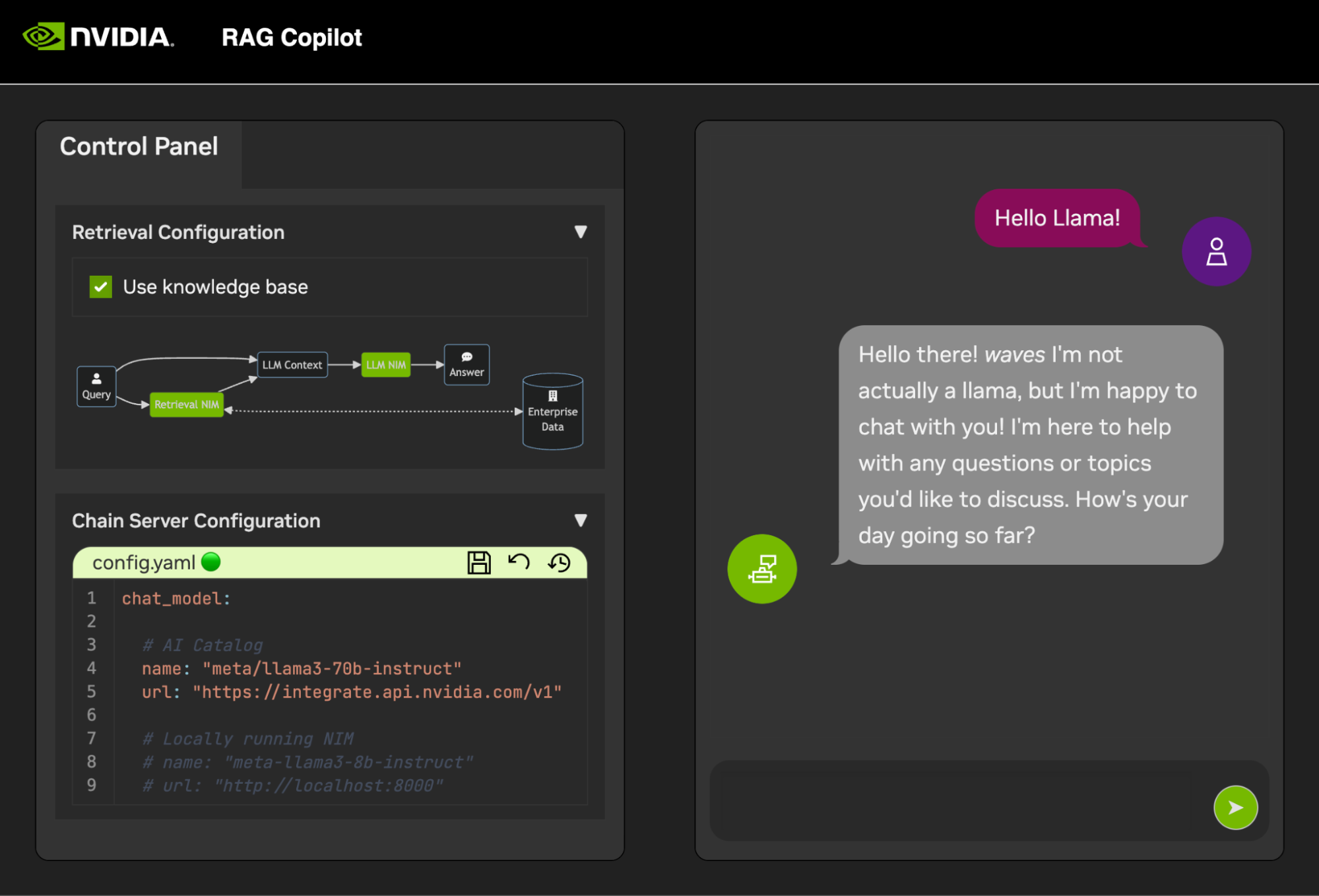
Para comenzar a desarrollar demostraciones, se proporciona un conjunto de datos de muestra junto con un Jupyter Notebook que muestra cómo se incorporan los datos a una base de datos vectorial.
Para importar documentación PDF a la base de datos vectorial, abra Jupyter usando el iniciador de aplicaciones en AI Workbench.
Utilice Jupyter Notebook en code/upload-pdfs.ipynb para ingerir el conjunto de datos predeterminado. Si utiliza el conjunto de datos predeterminado, no es necesario realizar cambios.
Si utiliza un conjunto de datos personalizado, cárguelo en el directorio data/ en Jupyter y modifique el cuaderno proporcionado según sea necesario.
Este proyecto contiene aplicaciones para algunos servicios de demostración, así como integraciones con servicios externos. Todo esto está orquestado por NVIDIA AI Workbench.
Todos los servicios de demostración están en la carpeta code . El nivel raíz de la carpeta de códigos tiene algunos cuadernos interactivos destinados a inmersiones técnicas profundas. Chain Server es una aplicación de muestra que utiliza NIM con LangChain. (Tenga en cuenta que el servidor de cadena aquí le ofrece la opción de experimentar con y sin RAG). La carpeta Chat Frontend contiene un servidor de interfaz de usuario interactivo para ejercitar el servidor de cadena. Finalmente, se proporcionan cuadernos de muestra en el directorio de Evaluación para demostrar la puntuación y validación de la recuperación.
mapa mental
root((Banco de trabajo AI))
Servicios de demostración
Servidor de cadena<br />LangChain + NIM
Frontend<br />UI de demostración interactiva
Evaluación<br />Validar los resultados
Cuadernos<br />Uso avanzado
Integraciones
Redis</br>Historial de conversaciones
Milvus</br>Base de datos vectorial
LLM NIM</br>LLM optimizados
El Chain Server se puede configurar con un archivo de configuración o variables de entorno.
De forma predeterminada, la aplicación buscará un archivo de configuración en todas las ubicaciones siguientes. Si se encuentran varios archivos de configuración, los valores de los archivos inferiores en la lista tendrán prioridad.
Se puede especificar una ruta de archivo de configuración adicional a través de una variable de entorno denominada APP_CONFIG . El valor de este archivo tendrá prioridad sobre todas las ubicaciones de archivos predeterminadas.
export APP_CONFIG=/etc/my_config.yaml La configuración también se puede establecer mediante variables de entorno. Los nombres de las variables tendrán el formato: APP_FIELD__SUB_FIELD Los valores especificados como variables de entorno tendrán prioridad sobre todos los valores de los archivos.
# Your API key for authentication to AI Foundation.
# ENV Variables: NGC_API_KEY, NVIDIA_API_KEY, APP_NVIDIA_API_KEY
# Type: string, null
nvidia_api_key : ~
# The Data Source Name for your Redis DB.
# ENV Variables: APP_REDIS_DSN
# Type: string
redis_dsn : redis://localhost:6379/0
llm_model :
# The name of the model to request.
# ENV Variables: APP_LLM_MODEL__NAME
# Type: string
name : meta/llama3-8b-instruct
# The URL to the model API.
# ENV Variables: APP_LLM_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
embedding_model :
# The name of the model to request.
# ENV Variables: APP_EMBEDDING_MODEL__NAME
# Type: string
name : nvidia/nv-embedqa-e5-v5
# The URL to the model API.
# ENV Variables: APP_EMBEDDING_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
reranking_model :
# The name of the model to request.
# ENV Variables: APP_RERANKING_MODEL__NAME
# Type: string
name : nv-rerank-qa-mistral-4b:1
# The URL to the model API.
# ENV Variables: APP_RERANKING_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
milvus :
# The host machine running Milvus vector DB.
# ENV Variables: APP_MILVUS__URL
# Type: string
url : http://localhost:19530
# The name of the Milvus collection.
# ENV Variables: APP_MILVUS__COLLECTION_NAME
# Type: string
collection_name : collection_1
log_level :
La interfaz de chat también tiene algunas opciones de configuración. Se pueden configurar de la misma manera que el servidor de cadena.
# The URL to the chain on the chain server.
# ENV Variables: APP_CHAIN_URL
# Type: string
chain_url : http://localhost:3030/
# The url prefix when this is running behind a proxy.
# ENV Variables: PROXY_PREFIX, APP_PROXY_PREFIX
# Type: string
proxy_prefix : /
# Path to the chain server's config.
# ENV Variables: APP_CHAIN_CONFIG_FILE
# Type: string
chain_config_file : ./config.yaml
log_level :
Todos los comentarios y contribuciones a este proyecto son bienvenidos. Al realizar cambios en este proyecto, ya sea para uso personal o para contribuir, se recomienda trabajar en una bifurcación de este proyecto. Una vez que se hayan completado los cambios en la bifurcación, se debe abrir una Solicitud de fusión.
Este proyecto se configuró con Linters que se ajustaron para ayudar a que el código permanezca consistente sin ser demasiado engorroso. Usamos los siguientes Linters:
El entorno VSCode integrado está configurado para ejecutar linting y verificación en tiempo real.
Para ejecutar manualmente el linting realizado por las canalizaciones de CI, ejecute /project/code/tools/lint.sh . Se pueden ejecutar pruebas individuales especificándolas por nombre: /project code/tools/lint.sh [deps|pylint|mypy|black|docs|fix] . Ejecutar la herramienta lint en modo de reparación corregirá automáticamente lo que pueda ejecutando Black, actualizando el archivo README y borrando la salida de la celda en todos los Jupyter Notebooks.
La interfaz ha sido diseñada en un esfuerzo por minimizar el desarrollo requerido de HTML y Javascript. Se proporciona un Shell de aplicación con marca y estilo que se ha creado con HTML básico, Javascript y CSS. Está diseñado para que sea fácil de personalizar, pero nunca debería ser obligatorio. Todos los componentes interactivos de la interfaz se crean en Gradio y se montan en el shell de la aplicación mediante iframes.
En la parte superior del shell de la aplicación hay un menú que enumera las vistas disponibles. Cada vista puede tener su propio diseño que consta de una o varias páginas.
Las páginas contienen los componentes interactivos para una demostración. El código de las páginas está en el directorio code/frontend/pages . Para crear una nueva página:
__init__.py en el nuevo directorio que usa Gradio para definir la interfaz de usuario. El diseño de Gradio Blocks debe definirse en una variable llamada page .chat para ver un ejemplo.code/frontend/pages/__init__.py , importe la nueva página y agregue la nueva página a la lista __all__ .NOTA: Crear una nueva página no la agregará a la interfaz. Debe agregarse a una vista para que aparezca en el Frontend.
La vista consta de una o varias páginas y debe funcionar de forma independiente una de otra. Todas las vistas están definidas en el módulo code/frontend/server.py . Todas las vistas declaradas se agregarán automáticamente a la barra de menú del Frontend y estarán disponibles en la interfaz de usuario.
Para definir una nueva vista, modifique la lista denominada views . Esta es una lista de objetos View . El orden de los objetos definirá su orden en el menú Frontend. La primera vista definida será la predeterminada.
Los objetos de vista describen el nombre y el diseño de la vista. Se pueden declarar de la siguiente manera:
my_view = frontend . view . View (
name = "My New View" , # the name in the menu
left = frontend . pages . sample_page , # the page to show on the left
right = frontend . pages . another_page , # the page to show on the right
) Todas las declaraciones de página, View.left o View.right , son opcionales. Si no se declaran, los iframes asociados en el diseño web se ocultarán. Los otros iframes se expandirán para llenar los huecos. Los siguientes diagramas muestran los distintos diseños.
bloque-beta
columnas 1
menú["barra de menú"]
bloquear
columnas 2
izquierda derecha
fin
bloque-beta
columnas 1
menú["barra de menú"]
bloquear
columnas 1
izquierda: 1
fin
La interfaz contiene algunos activos de marca que se pueden personalizar para diferentes casos de uso.
La interfaz contiene un logotipo en la parte superior izquierda de la página. Para modificar el logo, se requiere un SVG del logo deseado. Luego, el shell de la aplicación se puede modificar fácilmente para usar el nuevo SVG modificando el archivo code/frontend/_assets/index.html . Hay un único div con un ID de logo . Este cuadro contiene un único SVG. Actualice esto a la definición SVG deseada.
< div id =" logo " class =" logo " >
< svg viewBox =" 0 0 164 30 " > ... </ svg >
</ div > El estilo de App Shell se define en code/frontend/_static/css/style.css . Los colores de este archivo se pueden modificar de forma segura.
El estilo de las distintas páginas se define en code/frontend/pages/*/*.css . Es posible que estos archivos también requieran modificaciones para esquemas de color personalizados.
El tema Gradio está definido en el archivo code/frontend/_assets/theme.json . Los colores de este archivo se pueden modificar de forma segura según la marca deseada. También se pueden cambiar otros estilos en este archivo, pero pueden provocar cambios importantes en la interfaz. La documentación de Gradio contiene más información sobre la tematización de Gradio.
NOTA: Este es un tema avanzado que la mayoría de los desarrolladores nunca necesitarán.
En ocasiones, puede ser necesario tener varias páginas en una vista que se comuniquen entre sí. Para ello, se utiliza el marco de mensajería postMessage de Javascript. Cualquier mensaje confiable publicado en el shell de la aplicación se reenviará a cada iframe donde las páginas pueden manejar el mensaje como se desee. La página control utiliza esta función para modificar la configuración de la página chat .
Lo siguiente publicará un mensaje en el shell de la aplicación ( window.top ). El mensaje contendrá un diccionario con la clave use_kb y un valor verdadero. Usando Gradio, este Javascript puede ser ejecutado por cualquier evento de Gradio.
window . top . postMessage ( { "use_kb" : true } , '*' ) ; El shell de la aplicación enviará automáticamente este mensaje a todas las páginas. El siguiente código de muestra consumirá el mensaje en otra página. Este código se ejecutará de forma asíncrona cuando se reciba un evento message . Si el mensaje es confiable, un componente de Gradio con elem_id de use_kb se actualizará al valor especificado en el mensaje. De esta manera, el valor de un componente de Gradio se puede duplicar en todas las páginas.
window . addEventListener (
"message" ,
( event ) => {
if ( event . isTrusted ) {
use_kb = gradio_config . components . find ( ( element ) => element . props . elem_id == "use_kb" ) ;
use_kb . props . value = event . data [ "use_kb" ] ;
} ;
} ,
false ) ; El archivo README se procesa automáticamente; Las ediciones directas se sobrescribirán. Para modificar el archivo README, deberá editar los archivos de cada sección por separado. Todos estos archivos se combinarán y el archivo README se generará automáticamente. Puede encontrar todos los archivos relacionados en la carpeta docs .
La documentación se escribe en Github Flavored Markdown y luego Pandoc la procesa en un archivo Markdown final. Los detalles de este proceso se definen en el Makefile. El orden de los archivos generados se define en docs/_TOC.md . La documentación se puede obtener una vista previa en la ventana del explorador de archivos de Workbench.
El archivo de encabezado es el primer archivo utilizado para compilar la documentación. Este archivo se puede encontrar en docs/_HEADER.md . El contenido de este archivo se escribirá palabra por palabra, sin ninguna manipulación, en el README antes que nada.
El archivo de resumen contiene una descripción rápida y un gráfico que describe este proyecto. El contenido de este archivo se agregará al archivo README inmediatamente después del encabezado y justo antes de la tabla de contenido. Pandoc procesa este archivo para incrustar imágenes antes de escribirlo en el README.
El archivo más importante para la documentación es el archivo de tabla de contenido en docs/_TOC.md . Este archivo define una lista de archivos que deben concatenarse para generar el manual README final. Los archivos deben estar en esta lista para ser incluidos.
Guarde todo el contenido estático, incluidas las imágenes, en la carpeta _static . Esto ayudará con la organización.
Puede resultar útil tener documentos que se actualicen y escriban solos. Para crear un documento dinámico, simplemente cree un archivo ejecutable que escriba el documento formateado Markdown en la salida estándar. Durante el tiempo de compilación, si una entrada en el archivo de tabla de contenido es ejecutable, se ejecutará y se utilizará su salida estándar en su lugar.
Cuando se envía una confirmación relacionada con la documentación, una acción de GitHub representará la documentación. Cualquier cambio en el README se confirmará automáticamente.
La mayor parte de la configuración del entorno de desarrollo se realiza con variables de entorno. Para realizar cambios permanentes en las variables de entorno, modifique variables.env o utilice la interfaz de usuario de Workbench.
Este proyecto utiliza un entorno Python en /usr/bin/python3 y las dependencias se administran con pip . Debido a que todo el desarrollo se realiza dentro de un contenedor, cualquier cambio en el entorno de Python será efímero. Para instalar permanentemente un paquete de Python, agréguelo al archivo requirements.txt o use la interfaz de usuario de Workbench.
El entorno de desarrollo está basado en Ubuntu 22.04. El usuario principal tiene acceso sudo sin contraseña, pero todos los cambios en el sistema serán efímeros. Para realizar cambios permanentes en los paquetes instalados, agréguelos al archivo [ apt.txt ]. Para realizar otros cambios en el sistema operativo como manipular archivos, agregar variables de entorno, etc; utilice los archivos postBuild.bash y preBuild.bash .
Por lo general, es una buena práctica actualizar las dependencias mensualmente para garantizar que ningún CVE quede expuesto a través de dependencias mal utilizadas. El siguiente proceso se puede utilizar para parchear este proyecto. Se recomienda ejecutar la prueba de regresión después del parche para asegurarse de que no se haya roto nada en la actualización.
/project/code/tools/bump.sh ./project/code/tools/audit.sh . Este script imprimirá un informe de todos los paquetes de Python en estado de advertencia y todos los paquetes en estado de error. Cualquier cosa que se encuentre en un estado de error debe resolverse, ya que tendrá CVE activos y vulnerabilidades conocidas.

