Facebook Messenger Bot
1.0.0
El chatbot de FB Messenger que entrené para hablar como yo. La publicación del blog asociada.
Para este proyecto, quería entrenar un modelo de secuencia a secuencia en mis registros de conversaciones anteriores de varios sitios de redes sociales. Puedes leer más sobre la motivación detrás de este enfoque, los detalles del modelo ML y el propósito de cada script de Python en la publicación del blog, pero quiero usar este README para explicar cómo puedes entrenar tu propio chatbot para que hable como tú. .
Para ejecutar estos scripts, necesitará las siguientes bibliotecas.
Descargue y descomprima este repositorio completo desde GitHub, ya sea de forma interactiva o ingresando lo siguiente en su Terminal.
git clone https://github.com/adeshpande3/Facebook-Messenger-Bot.gitNavegue hasta el directorio superior del repositorio en su máquina
cd Facebook-Messenger-BotNuestro primer trabajo es descargar todos los datos de su conversación desde varios sitios de redes sociales. Para mí, utilicé Facebook, Google Hangouts y LinkedIn. Si tiene otros sitios de los que obtiene datos, está bien. Sólo tendrás que crear un nuevo método en createDataset.py.
Datos de Facebook : Descarga tus datos desde aquí. Una vez descargado, debería tener un archivo bastante grande llamado mensajes.htm . Será un archivo bastante grande (más de 190 MB para mí). Necesitaremos analizar este archivo grande y extraer todas las conversaciones. Para hacer esto, usaremos esta herramienta que Dillon Dixon amablemente ha abierto. Continuará e instalará esa herramienta ejecutando
pip install fbchat-archive-parsery luego ejecutando:
fbcap ./messages.htm > fbMessages.txtEsto le brindará todas sus conversaciones de Facebook en un archivo de texto bastante unificado. Gracias Dillon! Continúe y luego almacene ese archivo en su carpeta Facebook-Messenger-Bot.
Datos de LinkedIn : Descarga tus datos desde aquí. Una vez descargado, debería ver un archivo inbox.csv . No necesitaremos realizar ningún otro paso aquí, solo queremos copiarlo a nuestra carpeta.
Datos de Google Hangouts : Descarga tu formulario de datos aquí. Una vez descargado, obtendrá un archivo JSON que tendremos que analizar. Para hacer esto, usaremos este analizador que se encuentra en esta excelente publicación de blog. Querremos guardar los datos en archivos de texto y luego copiar la carpeta a la nuestra.
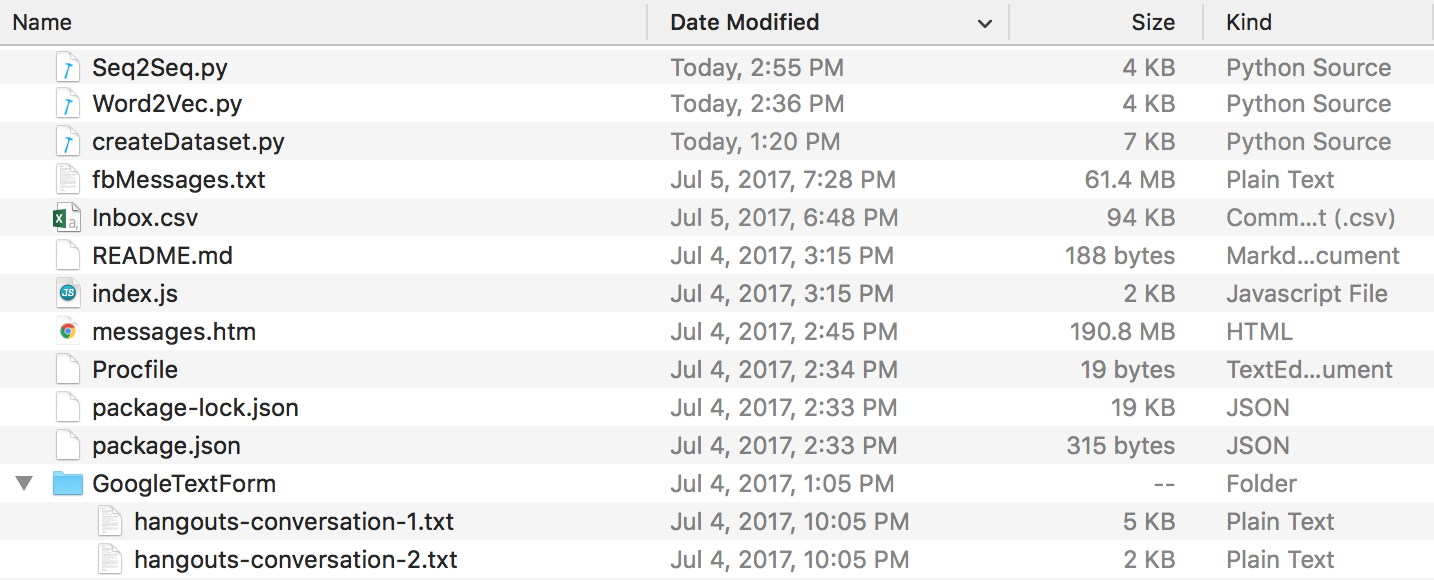
Al final de todo esto, debería tener una estructura de directorios similar a esta. Asegúrese de cambiar el nombre de las carpetas y los archivos si los suyos son diferentes.
Datos de Discord : puedes extraer tus registros de chat de Discord utilizando este increíble DiscordChatExporter creado por Tyrrrz. Siga su documentación para extraer los registros de chat singulares que desee en formato .txt (esto es importante). Luego puedes colocarlos todos en una carpeta llamada DiscordChatLogs en el directorio del repositorio.
Datos de WhatsApp : asegúrese de tener un teléfono celular y colóquelo en el formato de fecha de EE. UU. si aún no lo tiene (esto será importante más adelante cuando analice el archivo de registro en .csv). No se puede utilizar whatsApp web para este fin. Abra el chat que desea enviar, toque el botón de menú, toque más y luego haga clic en "Chat por correo electrónico". Envíate el correo electrónico a ti mismo y descárgalo a tu computadora. Esto le dará un archivo .txt; para analizarlo, lo convertiremos a .csv. Para hacer esto, vaya a este enlace e ingrese todo el texto en su archivo de registro. Haga clic en exportar, descargue el archivo csv y simplemente guárdelo en su carpeta Facebook-Messenger-Bot con el nombre "whatsapp_chats.csv".
NOTA : El analizador proporcionado en el enlace anterior parece haber sido eliminado. Si todavía tienes un archivo .csv en el formato correcto , aún puedes usarlo. De lo contrario, descargue sus registros de chat de WhatsApp como archivos .txt y colóquelos todos en una carpeta llamada WhatsAppChatLogs en el directorio del repositorio. createDataset.py funcionará con estos archivos si, y solo si, NO encuentra un archivo .csv llamado whatsapp_chats.csv .
En caso de que utilice registros de chat .txt , tenga en cuenta que el formato esperado es:
[20.06.19, 15:58:57] Loris: Welcome to the chat example
[20.06.19, 15:59:07] John: Thanks
(O)
12/28/19, 21:43 - Loris: Welcome to the chat example
12/28/19, 21:43 - John: Thanks
Ahora que tenemos todos nuestros registros de conversaciones en un formato limpio, podemos seguir adelante y crear nuestro conjunto de datos. En nuestro directorio, ejecutemos:
python createDataset.pyLuego se le pedirá que ingrese su nombre (para que el script sepa a quién buscar) y de qué sitios de redes sociales tiene datos. Este script creará un archivo llamado conversationDictionary.npy que es un objeto Numpy que contiene pares en forma de (FRIENDS_MESSAGE, YOUR RESPONSE). También se creará un archivo llamado conversaciónData.txt . Esto es simplemente un archivo de texto grande que contiene datos del diccionario en forma unificada.
Ahora que tenemos esos 2 archivos, podemos comenzar a crear nuestros vectores de palabras a través de un modelo Word2Vec. Este paso es un poco diferente a los demás. La función Tensorflow que veremos más adelante (en seq2seq.py) en realidad también maneja la parte de incrustación. Entonces puedes decidir entrenar tus propios vectores o hacer que la función seq2seq lo haga conjuntamente, que es lo que terminé haciendo. Si desea crear sus propios vectores de palabras a través de Word2Vec, responda sí cuando se le solicite (después de ejecutar lo siguiente). Si no lo hace, entonces está bien, responda n y esta función solo creará wordList.txt.
python Word2Vec.pySi ejecuta word2vec.py en su totalidad, se crearán 4 archivos diferentes. Word2VecXTrain.npy y Word2VecYTrain.npy son las matrices de entrenamiento que utilizará Word2Vec. Los guardamos en nuestra carpeta, en caso de que necesitemos entrenar nuestro modelo Word2Vec nuevamente con diferentes hiperparámetros. También guardamos wordList.txt , que simplemente contiene todas las palabras únicas de nuestro corpus. El último archivo guardado es embeddingMatrix.npy , que es una matriz Numpy que contiene todos los vectores de palabras generados.
Ahora podemos crear y entrenar nuestro modelo Seq2Seq.
python Seq2Seq.pyEsto creará 3 o más archivos diferentes. Seq2SeqXTrain.npy y Seq2SeqYTrain.npy son las matrices de entrenamiento que utilizará Seq2Seq. Nuevamente, los guardamos en caso de que queramos realizar cambios en la arquitectura de nuestro modelo y no queramos volver a calcular nuestro conjunto de entrenamiento. Los últimos archivos serán archivos .ckpt que contienen nuestro modelo Seq2Seq guardado. Los modelos se guardarán en diferentes períodos de tiempo en el ciclo de entrenamiento. Estos se utilizarán e implementarán una vez que hayamos creado nuestro chatbot.
Ahora que tenemos un modelo guardado, creemos nuestro chatbot de Facebook. Para hacerlo, recomiendo seguir este tutorial. No es necesario leer nada debajo de la sección "Personalizar lo que dice el bot". Nuestro modelo Seq2Seq se encargará de esa parte. IMPORTANTE: el tutorial le indicará que cree una nueva carpeta donde se ubicará el proyecto de Node. Tenga en cuenta que esta carpeta será diferente de nuestra carpeta. Puede pensar que esta carpeta es donde se encuentra nuestro preprocesamiento de datos y entrenamiento de modelos, mientras que la otra carpeta está estrictamente reservada para la aplicación Express (EDITAR: creo que puede seguir los pasos del tutorial dentro de nuestra carpeta y simplemente crear el proyecto Node. Procfile e index.js aquí si lo desea). El tutorial en sí debería ser suficiente, pero aquí hay un resumen de los pasos.
Después de seguir los pasos correctamente, debería poder enviar mensajes al chatbot y obtener respuestas.
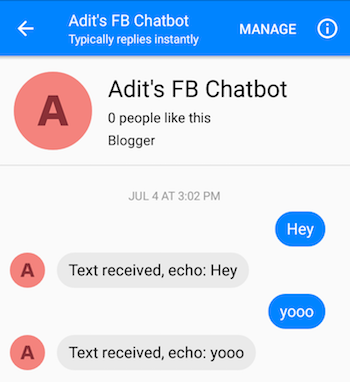
¡Ah, ya casi terminas! Ahora, tenemos que crear un servidor Flask donde podamos implementar nuestro modelo Seq2Seq guardado. Tengo el código para ese servidor aquí. Hablemos de la estructura general. Los servidores Flask normalmente tienen un archivo .py principal donde se definen todos los puntos finales. Este será app.py en nuestro caso. Aquí será donde cargaremos nuestro modelo. Debe crear una carpeta llamada 'modelos' y llenarla con 4 archivos (un archivo de punto de control, un archivo de datos, un archivo de índice y un metaarchivo). Estos son los archivos que se crean cuando guardas un modelo de Tensorflow.

En este archivo app.py, queremos crear una ruta (/prediction en mi caso) donde la entrada a la ruta se introducirá en nuestro modelo guardado y la salida del decodificador es la cadena que se devuelve. Continúe y eche un vistazo más de cerca a app.py si todavía le resulta un poco confuso. Ahora que tiene su app.py y sus modelos (y otros archivos auxiliares si los necesita), puede implementar su servidor. Usaremos Heroku nuevamente. Hay muchos tutoriales diferentes sobre cómo implementar servidores Flask en Heroku, pero me gusta este en particular (no necesito las secciones Foreman y Logging).
Ahí tienes. Deberías poder enviar mensajes al chatbot y ver algunas respuestas interesantes que (con suerte) se parezcan a ti de alguna manera.
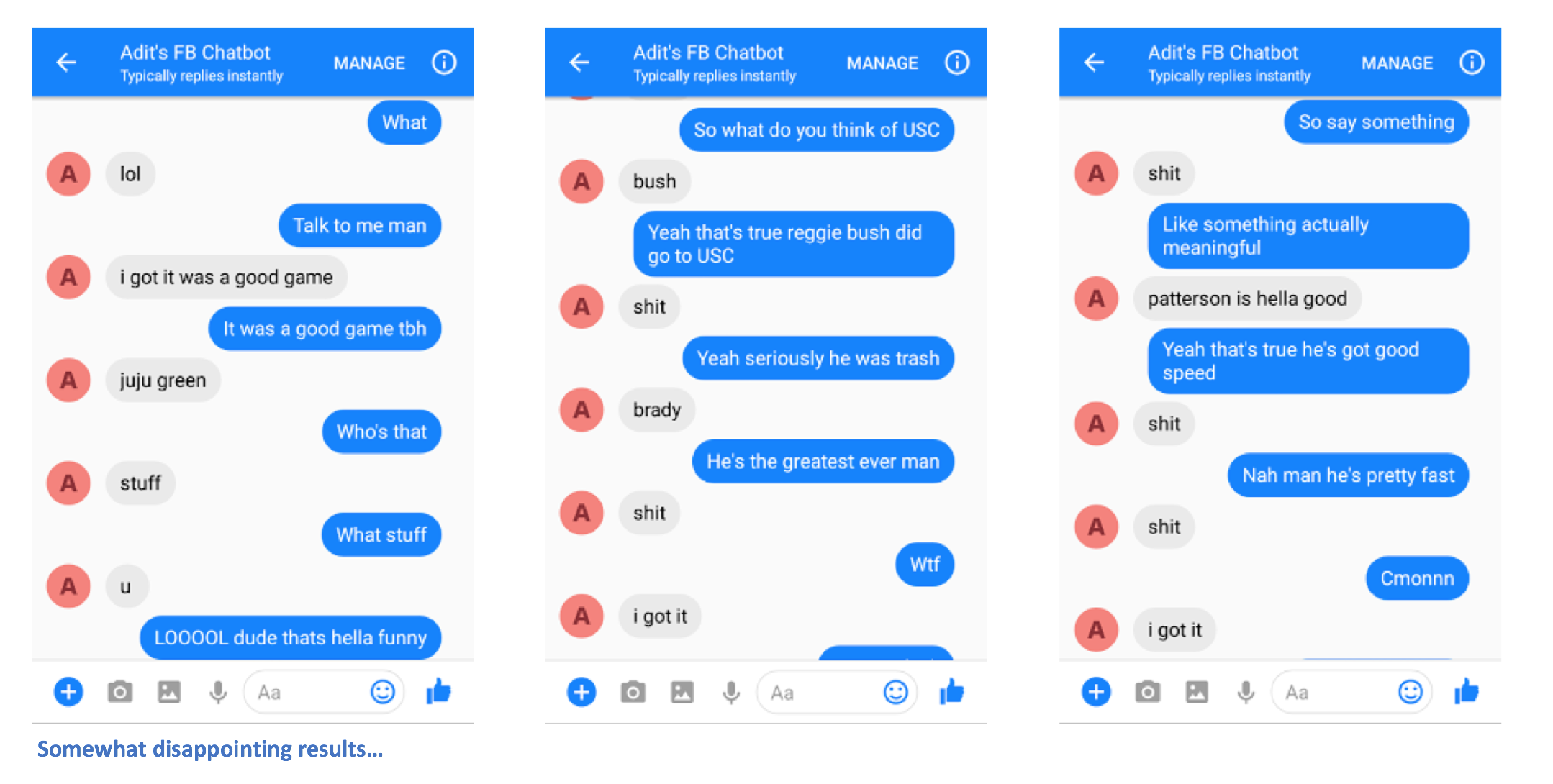
Avíseme si tiene algún problema o si tiene alguna sugerencia para mejorar este archivo README. Si pensaba que un determinado paso no estaba claro, hágamelo saber y haré todo lo posible para editar el archivo README y hacer cualquier aclaración.


