RLAIF V
1.0.0

Alineación de MLLM a través de comentarios de IA de código abierto para lograr la confiabilidad de Super GPT-4V
中文 | Inglés
[2024.11.26] ¡Apoyamos la capacitación de LoRA ahora!
[2024.05.28] ¡Nuestro artículo ya está disponible en arXiv!
[2024.05.20] Nuestro conjunto de datos RLAIF-V se utiliza para entrenar MiniCPM-Llama3-V 2.5, que representa el primer MLLM de nivel GPT-4V del lado final.
[2024.05.20] ¡Abrimos el código, los pesos (7B, 12B) y los datos de RLAIF-V!
Presentamos RLAIF-V, un marco novedoso que alinea los MLLM en un paradigma de código totalmente abierto para una confiabilidad súper GPT-4V. RLAIF-V aprovecha al máximo los comentarios de código abierto desde dos perspectivas clave, incluidos los datos de comentarios de alta calidad y el algoritmo de aprendizaje de comentarios en línea. Las características notables de RLAIF-V incluyen:
"Confiabilidad del Super GPT-4V a través de comentarios de código abierto" . Al aprender de los comentarios de la IA de código abierto, RLAIF-V 12B logra una confiabilidad súper GPT-4V tanto en tareas generativas como discriminativas.
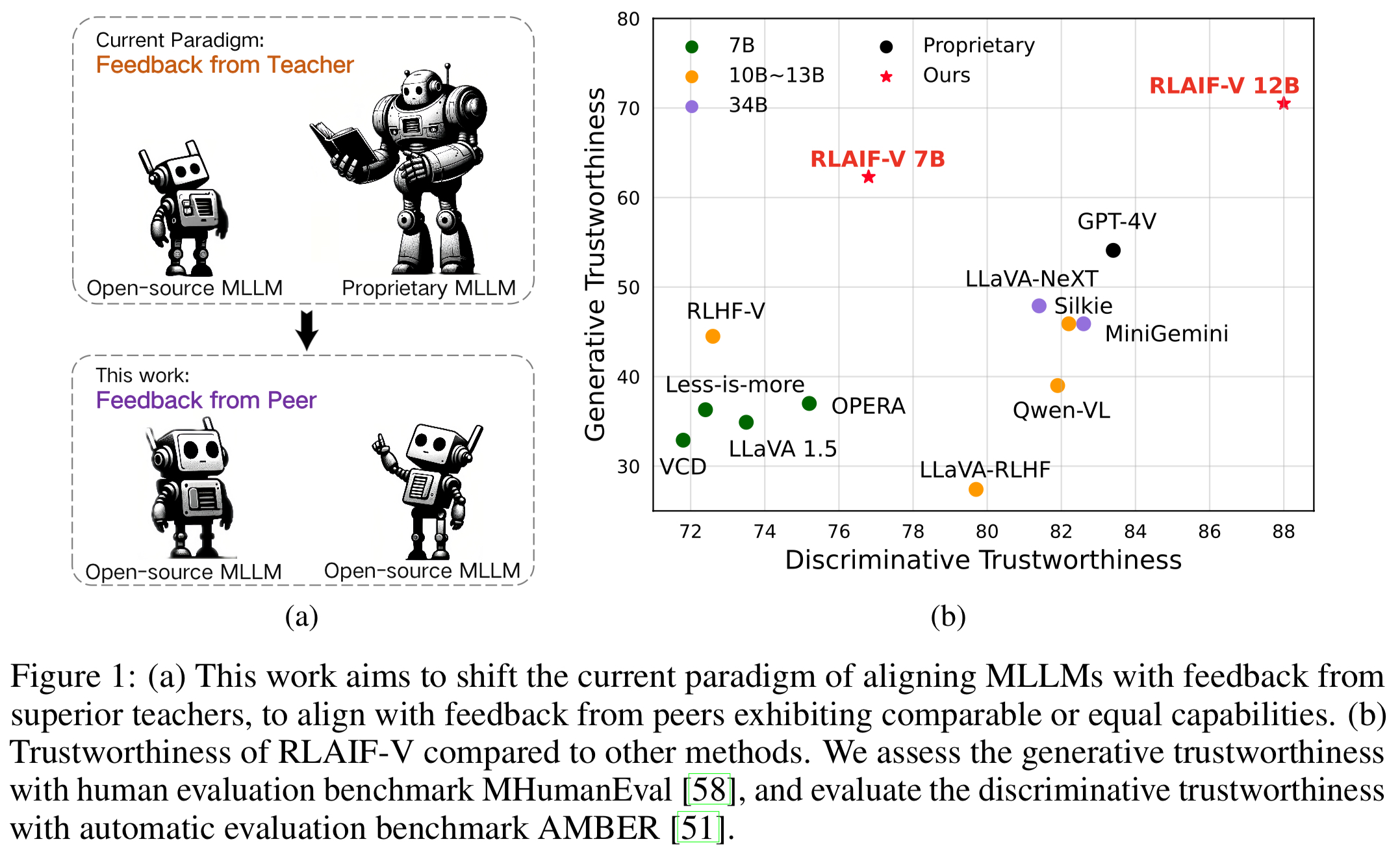
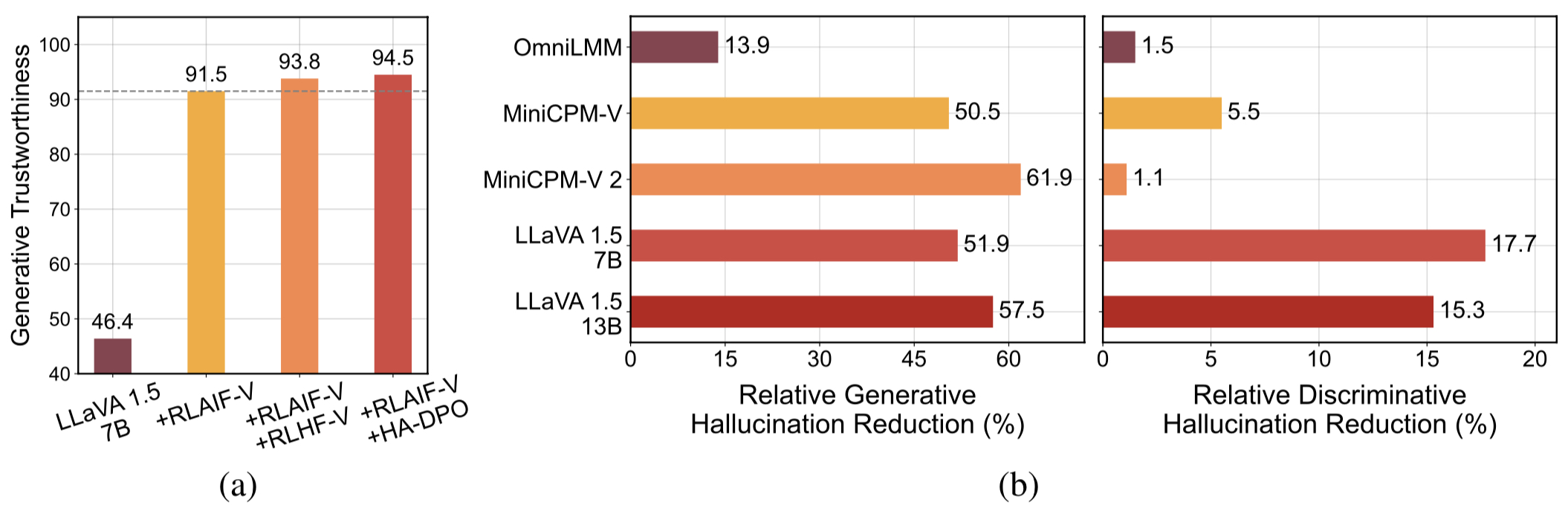
Datos de retroalimentación generalizables de alta calidad . Los datos de retroalimentación utilizados por RLAIF-V reducen efectivamente las alucinaciones de diferentes MLLM .
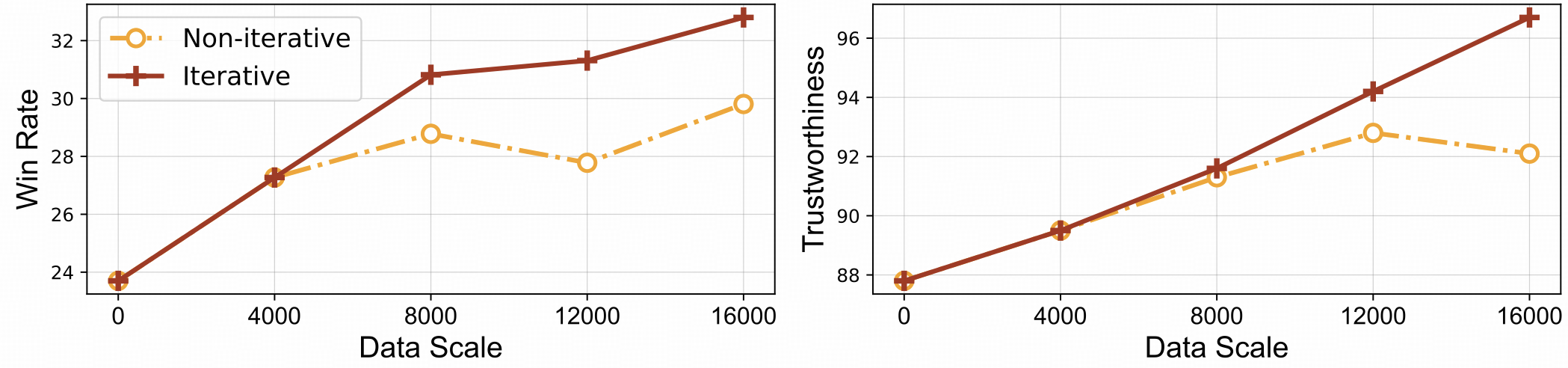
⚡️ Aprendizaje eficiente por retroalimentación con alineación iterativa. RLAIF-V muestra una mejor eficiencia de aprendizaje y un mayor rendimiento en comparación con el enfoque no iterativo.
Conjunto de datos
Instalar
Pesos del modelo
Inferencia
Generación de datos
Tren
Evaluación
Objeto HalBanco
Banco MMhal
REFOMB
Citación
Presentamos el conjunto de datos RLAIF-V, que es un conjunto de datos de preferencias generado por IA que cubre una amplia gama de tareas y dominios. Este conjunto de datos de preferencia multimodal de código abierto contiene 83,132 pares de comparación de alta calidad . El conjunto de datos contiene los pares de preferencias generados en cada iteración de entrenamiento de diferentes modelos, incluidos LLaVA 1.5 7B, OmniLMM 12B y MiniCPM-V.
Clona este repositorio y navega a la carpeta RLAIF-V
clon de git https://github.com/RLHF-V/RLAIF-V.gitcd RLAIF-V
Instalar paquete
conda crear -n rlaifv python=3.10 -y conda activar rlaifv instalación de pip -e.
Instale el modelo spaCy requerido
wget https://github.com/explosion/spacy-models/releases/download/en_core_web_trf-3.7.3/en_core_web_trf-3.7.3.tar.gz instalación de pip en_core_web_trf-3.7.3.tar.gz
| Modelo | Descripción | Descargar |
|---|---|---|
| RLAIF-V 7B | La variante más confiable de LLaVA 1.5 | ? |
| RLAIF-V 12B | Basado en OmniLMM-12B, logrando una confiabilidad súper GPT-4V. | ? |
Proporcionamos un ejemplo simple para mostrar cómo usar RLAIF-V.
from chat import RLAIFVChat, img2base64chat_model = RLAIFVChat('openBMB/RLAIF-V-7B') # or 'openBMB/RLAIF-V-12B'image_path="./examples/test.jpeg"msgs = "Describe en detalle las personas en la imagen."inputs = {"image": image_path, "question": msgs}respuesta = chat_model.chat(entradas)imprimir(respuesta)También puede ejecutar este ejemplo ejecutando el siguiente script:
chat de Python.py

Pregunta:
¿Por qué se detuvo el auto de la imagen?
Resultados esperados:
En la imagen, un automóvil se detuvo en la vía debido a la presencia de una oveja en la calzada. Es probable que el automóvil se detuviera para permitir que las ovejas se apartaran del camino de manera segura o evitar posibles accidentes con el animal. Esta situación pone de relieve la importancia de ser cautelosos y atentos al conducir, especialmente en zonas donde los animales pueden deambular cerca de las carreteras.
Configuración del entorno
Proporcionamos el modelo OmniLMM 12B y el modelo MiniCPM-Llama3-V 2.5 para generación de retroalimentación. Si desea utilizar MiniCPM-Llama3-V 2.5 para enviar comentarios, configure su entorno de inferencia de acuerdo con las instrucciones en el repositorio de MiniCPM-V GitHub.
Descargue nuestros modelos Llama3 8B optimizados: modelo dividido y modelo de transformación de preguntas, y guárdelos en las carpetas ./models/llama3_split y ./models/llama3_changeq respectivamente.
Comentarios sobre el modelo OmniLMM 12B
El siguiente script demuestra el uso del modelo LLaVA-v1.5-7b para generar respuestas de candidatos y el modelo OmniLMM 12B para proporcionar comentarios.
mkdir ./resultados bash ./script/data_gen/run_data_pipeline_llava15_omni.sh
Comentarios del modelo MiniCPM-Llama3-V 2.5
El siguiente script demuestra el uso del modelo LLaVA-v1.5-7b para generar respuestas de candidatos y el modelo MiniCPM-Llama3-V 2.5 para proporcionar comentarios. Primero, reemplace minicpmv_python en ./script/data_gen/run_data_pipeline_llava15_minicpmv.sh con la ruta de Python del entorno MiniCPM-V que creó.
mkdir ./resultados bash ./script/data_gen/run_data_pipeline_llava15_minicpmv.sh
Preparar datos (opcional)
Si puede acceder al conjunto de datos de Huggingface, puede omitir este paso; descargaremos automáticamente el conjunto de datos RLAIF-V.
Si ya descargó el conjunto de datos, puede reemplazar 'openbmb/RLAIF-V-Dataset' por la ruta de su conjunto de datos aquí en la Línea 38.
Capacitación
Aquí proporcionamos un script de entrenamiento para entrenar el modelo en 1 iteración . El parámetro max_step debe ajustarse según la cantidad de datos.
Ajuste completo
Ejecute el siguiente comando para comenzar a realizar un ajuste completo.
bash ./script/train/llava15_train.sh
lora
Ejecute el siguiente comando para iniciar el entrenamiento de lora.
instalación de pip bash ./script/train/llava15_train_lora.sh
Alineación iterativa
Para reproducir el proceso de capacitación iterativo en el documento, debe realizar los siguientes pasos 4 veces:
S1. Generación de datos.
Siga las instrucciones en generación de datos para generar pares de preferencias para el modelo base. Convierta el archivo jsonl generado en parquet huggingface.
S2. Cambiar la configuración de entrenamiento.
En el código del conjunto de datos, reemplace 'openbmb/RLAIF-V-Dataset' aquí por su ruta de datos.
En el script de entrenamiento, reemplace --data_dir con un nuevo directorio, reemplace --model_name_or_path con la ruta del modelo base, establezca --max_step en el número de pasos para 4 épocas, configure --save_steps en el número de pasos para 1/4 de época .
S3. Realizar formación DPO.
Ejecute el script de entrenamiento para entrenar el modelo base.
S4. Elija el modelo base para la próxima iteración.
Evalúe cada punto de control en Object HalBench y MMHal Bench, elija el punto de control mejor realizado como modelo base en la siguiente iteración.
Preparar anotaciones COCO2014
La evaluación de Object HalBench se basa en las anotaciones de título y segmentación del conjunto de datos COCO2014. Primero descargue el conjunto de datos COCO2014 del sitio web oficial del conjunto de datos COCO.
mkdir coco2014cd coco2014 wget http://images.cocodataset.org/annotations/annotations_trainval2014.zip descomprimir anotaciones_trainval2014.zip
Inferencia, evaluación y resumen.
Reemplace {YOUR_OPENAI_API_KEY} con una clave de API de OpenAI válida.
Nota: La evaluación se basa en gpt-3.5-turbo-0613 .
# cd RLAIF-Vbash ./script/eval/eval_rlaifv_objhal.sh ./RLAIF-V_weight ./results/RLAIF-V ./coco2014/annotations {YOUR_OPENAI_API_KEY}Preparar datos MMHal
Descargue los datos de evaluación de MMHal aquí y guarde el archivo en eval/data .
Ejecute el siguiente script para generar MMHal Bench:
Nota: La evaluación se basa en gpt-4-1106-preview .
# cd RLAIF-Vbash ./script/eval/eval_rlaifv_mmhal.sh ./RLAIF-V_weight ./results/RLAIF-V {TU_OPENAI_API_KEY}Preparación
Para utilizar la evaluación GPT-4, primero ejecute pip install openai==0.28 para instalar el paquete openai. A continuación, cambie openai.base y openai.api_key en eval/gpt4.py a su propia configuración.
Los datos de evaluación para el conjunto de desarrollo se pueden encontrar en eval/data/RefoMB_dev.jsonl . Debe descargar cada imagen desde la clave image_url en cada línea.
Evaluación para la puntuación general
Guarde la respuesta de su modelo en la clave answer del archivo de datos de entrada eval/data/RefoMB_dev.jsonl , por ejemplo:
{
"image_url": "https://thunlp.oss-cn-qingdao.aliyuncs.com/multimodal_openmme_test_20240319__20.jpg",
"question": "What is the background of the image?",
"type": "Coarse Perception",
"split": "dev",
"answer": "The background of the image features trees, suggesting that the scene takes place outdoors.",
"gt_description": "......"
}Ejecute el siguiente script para evaluar el resultado de su modelo:
save_dir="YOUR SAVING DIR" model_ans_path="YOUR MODEL ANSWER PATH" model_name="YOUR MODEL NAME" bash ./script/eval/run_refobm_overall.sh $save_dir $model_ans_path $model_name
Evaluación de la puntuación de alucinaciones.
Después de evaluar la puntuación general, se creará un archivo de resultados de la evaluación con el nombre A-GPT-4V_B-${model_name}.json . Utilice este archivo de resultados de evaluación para calcular la puntuación de alucinaciones de la siguiente manera:
eval_result="EVAL RESULT FILE PATH, e.g. 'A-GPT-4V_B-${model_name}'"
# Do not include ".json" in your file path!
bash ./script/eval/run_refomb_hall.sh $eval_resultNota: Para una mejor estabilidad, le recomendamos evaluar más de 3 veces y utilizar la puntuación promedio como puntuación final del modelo.
Avisos de uso y licencia : los datos, el código y el punto de control están destinados y autorizados para uso exclusivo en investigación. También están restringidos a usos que siguen el acuerdo de licencia de LLaMA, Vicuña y Chat GPT. El conjunto de datos es CC BY NC 4.0 (permite únicamente el uso no comercial) y los modelos entrenados con el conjunto de datos no deben usarse fuera de fines de investigación.
RLHF-V: el código base sobre el que construimos.
LLaVA: El modelo de instrucción y modelo de etiquetado de RLAIF-V-7B.
MiniCPM-V: el modelo de instrucción y el modelo de etiquetadora de RLAIF-V-12B.
Si encuentra útil nuestro modelo/código/datos/documento, considere citar nuestros documentos y destacarnos ️!
@article{yu2023rlhf, title={Rlhf-v: Hacia mllms confiables a través de la alineación del comportamiento a partir de comentarios humanos correccionales detallados}, autor={Yu, Tianyu y Yao, Yuan y Zhang, Haoye y He, Taiwen y Han, Yifeng y Cui, Ganqu y Hu, Jinyi y Liu, Zhiyuan y Zheng, Hai-Tao y Sun, Maosong y otros}, diario={arXiv preprint arXiv:2312.00849}, año={2023}}@article{yu2024rlaifv, title={RLAIF-V: Alineación de MLLM a través de comentarios de IA de código abierto para la confiabilidad de Super GPT-4V}, autor={Yu, Tianyu y Zhang, Haoye y Yao, Yuan y Dang, Yunkai y Chen, Da y Lu, Xiaoman y Cui, Ganqu y He, Taiwen y Liu, Zhiyuan y Chua, Tat-Seng y Sun, Maosong}, diario={arXiv preprint arXiv:2405.17220}, año={2024},
} 

