ChatLM mini Chinese
1.0.0
chino | inglés
Los grandes modelos de lenguaje actuales tienden a tener parámetros grandes, y las computadoras de consumo tardan en hacer inferencias simples, y mucho menos entrenar un modelo desde cero. El objetivo de este proyecto es entrenar un modelo de lenguaje generativo desde cero, incluida la limpieza de datos, el entrenamiento con tokenizadores, el entrenamiento previo del modelo, el ajuste fino de las instrucciones SFT, la optimización RLHF, etc.
ChatLM-mini-Chinese es un pequeño modelo de diálogo chino con solo 0,2 mil millones de parámetros de modelo (aproximadamente 210 millones, incluidos los pesos compartidos). Puede entrenarse previamente en una máquina con un mínimo de 4 GB de memoria de video ( batch_size=1 , fp16 o bf16 . ), y la carga e inferencia float16 requieren al menos 512 MB de memoria de video.
Huggingface , incluidos transformers , accelerate , trl , peft , etc.trainer autoimplementado admite el entrenamiento previo y el ajuste fino de SFT en una sola máquina con una sola tarjeta o con varias tarjetas en una sola máquina. Admite detenerse en cualquier posición durante el entrenamiento y continuar el entrenamiento en cualquier posición.Text-to-Text extremo a extremo y en el preentrenamiento de predicción sin mask .huggingface tokenizers de sentencepiece y caras abrazadas;batch_size=1, max_len=320 , se admite el entrenamiento previo en una máquina con al menos 16 GB de memoria + 4 GB de memoria de video;trainer autoimplementado admite el ajuste rápido de comandos y admite cualquier punto de interrupción para continuar con el entrenamiento;sequence to sequence del Huggingface trainer ;peft lora para optimizar las preferencias;Lora adapter se puede fusionar con el modelo original.Si necesita realizar una recuperación de generación mejorada (RAG) basada en modelos pequeños, puede consultar mi otro proyecto Phi2-mini-Chinese. Para obtener el código, consulte rag_with_langchain.ipynb.
? Últimas actualizaciones
Todos los conjuntos de datos provienen de conjuntos de datos de conversaciones de una sola ronda publicados en Internet. Después de la limpieza y el formateo de los datos, se guardan como archivos parquet. Para conocer el proceso de procesamiento de datos, consulte utils/raw_data_process.py . Los principales conjuntos de datos incluyen:
Belle_open_source_1M , train_2M_CN y train_3.5M_CN que tengan respuestas cortas, no contengan estructuras de tablas complejas ni tareas de traducción (sin lista de vocabulario en inglés), un total de 3,7 millones de filas y quedan 3,38 millones de filas después de la limpieza.N palabras de la enciclopedia son las respuestas. Utilizando datos de la enciclopedia 202309 , quedan 1,19 millones de mensajes de entrada y respuestas después de la limpieza. Descarga de wiki: zhwiki, convierta el archivo bz2 descargado a referencia wiki.txt: WikiExtractor. El número total de conjuntos de datos es 10,23 millones: conjunto de preentrenamiento de texto a texto: 9,3 millones, conjunto de evaluación: 25.000 (debido a que la decodificación es lenta, el conjunto de evaluación no es demasiado grande). Conjunto de prueba: 900.000. A continuación se muestran los conjuntos de datos de optimización de SFT y optimización de DPO.
Modelo T5 (Transformador de transferencia de texto a texto), consulte el documento para obtener más detalles: Exploración de los límites del aprendizaje por transferencia con un transformador unificado de texto a texto.
El código fuente del modelo proviene de huggingface, consulte: T5ForConditionalGeneration.
Consulte model_config.json para la configuración del modelo. La T5-base oficial: encoder layer y decoder layer son 12 capas. En este proyecto, estos dos parámetros se modifican a 10 capas.
Parámetros del modelo: 0.2B. Tamaño de la lista de palabras: 29298, incluyendo solo chino y una pequeña cantidad de inglés.
hardware:
# 预训练阶段:
CPU: 28 vCPU Intel(R) Xeon(R) Gold 6330 CPU @ 2.00GHz
内存:60 GB
显卡:RTX A5000(24GB) * 2
# sft及dpo阶段:
CPU: Intel(R) i5-13600k @ 5.1GHz
内存:32 GB
显卡:NVIDIA GeForce RTX 4060 Ti 16GB * 1 Entrenamiento de tokenizador : la biblioteca de entrenamiento tokenizer existente tiene problemas OOM cuando encuentra corpus grandes. Por lo tanto, el corpus completo se fusiona y construye en función de la frecuencia de palabras de acuerdo con un método similar a BPE , que tarda medio día en ejecutarse.
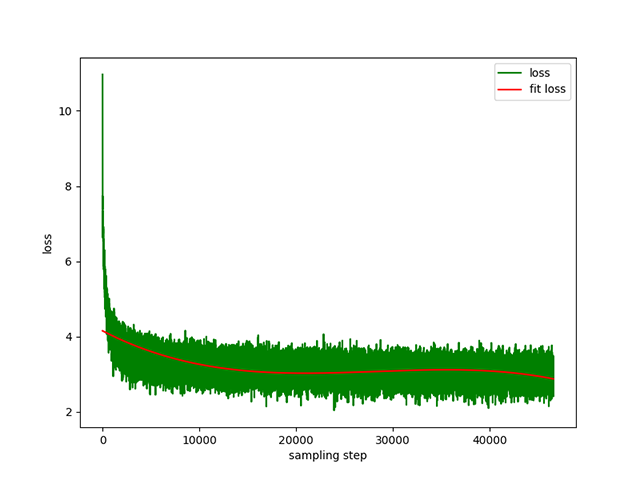
Preentrenamiento de texto a texto : una tasa de aprendizaje dinámico de 1e-4 a 5e-3 y un tiempo de preentrenamiento de 8 días. Pérdida de entrenamiento:
belle (la longitud de las instrucciones y las respuestas es inferior a 512), la tasa de aprendizaje es una tasa de aprendizaje dinámica de 1e-7 a 5e-5 , y el tiempo de ajuste fino son 2 dias. Pérdida de ajuste: 
chosen . En el paso 2 , el lote del modelo SFT generate las indicaciones en el conjunto de datos y obtiene el texto rejected . Para optimizar la preferencia completa de dpo y aprender, la velocidad es le-5 , media precisión fp16 , un total de 2 epoch y lleva 3 horas. pérdida de dpo: 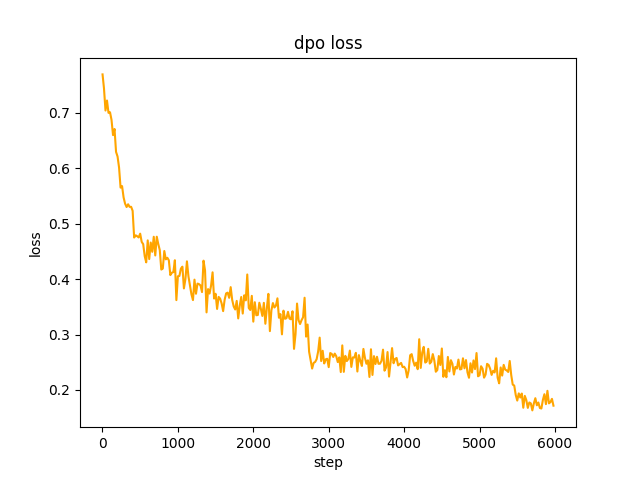
De forma predeterminada, TextIteratorStreamer de huggingface transformers se usa para implementar el diálogo de transmisión, que solo admite greedy search . Si necesita otros métodos de generación, como beam sample , cambie el parámetro stream_chat de cli_demo.py a False . 

Hay problemas: el conjunto de datos previo al entrenamiento solo tiene más de 9 millones y los parámetros del modelo son solo 0.2B. No puede cubrir todos los aspectos y habrá situaciones en las que la respuesta será incorrecta y el generador no tendrá sentido.
Si no se puede conectar huggingface, use modelscope.snapshot_download para descargar el archivo del modelo desde modelscope.
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
import torch
model_id = 'charent/ChatLM-mini-Chinese'
# 如果无法连接huggingface,打开以下两行代码的注释,将从modelscope下载模型文件,模型文件保存到'./model_save'目录
# from modelscope import snapshot_download
# model_id = snapshot_download(model_id, cache_dir='./model_save')
device = torch . device ( 'cuda' if torch . cuda . is_available () else 'cpu' )
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForSeq2SeqLM . from_pretrained ( model_id , trust_remote_code = True ). to ( device )
txt = '如何评价Apple这家公司?'
encode_ids = tokenizer ([ txt ])
input_ids , attention_mask = torch . LongTensor ( encode_ids [ 'input_ids' ]), torch . LongTensor ( encode_ids [ 'attention_mask' ])
outs = model . my_generate (
input_ids = input_ids . to ( device ),
attention_mask = attention_mask . to ( device ),
max_seq_len = 256 ,
search_type = 'beam' ,
)
outs_txt = tokenizer . batch_decode ( outs . cpu (). numpy (), skip_special_tokens = True , clean_up_tokenization_spaces = True )
print ( outs_txt [ 0 ])Apple是一家专注于设计和用户体验的公司,其产品在设计上注重简约、流畅和功能性,而在用户体验方面则注重用户的反馈和使用体验。作为一家领先的科技公司,苹果公司一直致力于为用户提供最优质的产品和服务,不断推陈出新,不断创新和改进,以满足不断变化的市场需求。
在iPhone、iPad和Mac等产品上,苹果公司一直保持着创新的态度,不断推出新的功能和设计,为用户提供更好的使用体验。在iPad上推出的iPad Pro和iPod touch等产品,也一直保持着优秀的用户体验。
此外,苹果公司还致力于开发和销售软件和服务,例如iTunes、iCloud和App Store等,这些产品在市场上也获得了广泛的认可和好评。
总的来说,苹果公司在设计、用户体验和产品创新方面都做得非常出色,为用户带来了许多便利和惊喜。
Precaución
El modelo de este proyecto es un modelo TextToText En el prompt , response y otros campos en las etapas de preentrenamiento, SFT y RLFH, asegúrese de agregar la marca de final de secuencia [EOS] .
git clone --depth 1 https://github.com/charent/ChatLM-mini-Chinese.git
cd ChatLM-mini-Chinese Este proyecto recomienda el uso de python 3.10 . Es posible que las versiones anteriores de Python no sean compatibles con las bibliotecas de terceros de las que depende.
instalación de tubería:
pip install -r ./requirements.txtSi pip instaló la versión de CPU de pytorch, puede instalar la versión CUDA de pytorch con el siguiente comando:
# pip 安装torch + cu118
pip3 install torch --index-url https://download.pytorch.org/whl/cu118instalación de conda:
conda install --yes --file ./requirements.txt Utilice el comando git para descargar los pesos del modelo y los archivos de configuración de Hugging Face Hub . Primero debe instalar Git LFS y luego ejecutar:
# 使用git命令下载huggingface模型,先安装[Git LFS],否则下载的模型文件不可用
git clone --depth 1 https://huggingface.co/charent/ChatLM-mini-Chinese
# 如果无法连接huggingface,请从modelscope下载
git clone --depth 1 https://www.modelscope.cn/charent/ChatLM-mini-Chinese.git
mv ChatLM-mini-Chinese model_save También puede descargarlo manualmente directamente desde el almacén ChatLM-Chinese-0.2B Hugging Face Hub y mover el archivo descargado al directorio model_save .
Los requisitos del corpus deben ser lo más completos posible. Se recomienda agregar múltiples corpus, como enciclopedias, códigos, artículos, blogs, conversaciones, etc.
Este proyecto se basa principalmente en la enciclopedia china wiki. Cómo obtener el corpus wiki chino: Dirección de descarga del wiki chino: zhwiki, descargue zhwiki-[存档日期]-pages-articles-multistream.xml.bz2 , aproximadamente 2,7 GB, convierta el archivo bz2 descargado en referencia wiki.txt: WikiExtractor Luego use la biblioteca OpenCC de Python para convertirlo al chino simplificado y finalmente coloque el wiki.simple.txt obtenido en el directorio data del directorio raíz del proyecto. Combine varios corpus en un archivo txt usted mismo.
Dado que el tokenizador de entrenamiento consume mucha memoria, si su corpus es muy grande (el archivo txt fusionado excede 2G), se recomienda muestrear el corpus según categorías y proporciones para reducir el tiempo de entrenamiento y el consumo de memoria. Entrenar un archivo txt de 1,7 GB requiere aproximadamente 48 GB de memoria (estimado, solo tengo 32 GB, lo que activa el intercambio con frecuencia, la computadora se atasca durante mucho tiempo T_T), la CPU de 13600k demora aproximadamente 1 hora.
La diferencia entre char level y byte level es la siguiente (busque información usted mismo para conocer las diferencias de uso específicas). El tokenizador entrena char level de forma predeterminada. Si se requiere byte level , simplemente configure token_type='byte' en train_tokenizer.py .
# 原始文本
txt = '这是一段中英混输的句子, (chinese and English, here are words.)'
tokens = charlevel_tokenizer . tokenize ( txt )
print ( tokens )
# char level tokens输出
# ['▁这是', '一段', '中英', '混', '输', '的', '句子', '▁,', '▁(', '▁ch', 'inese', '▁and', '▁Eng', 'lish', '▁,', '▁h', 'ere', '▁', 'are', '▁w', 'ord', 's', '▁.', '▁)']
tokens = bytelevel_tokenizer . tokenize ( txt )
print ( tokens )
# byte level tokens输出
# ['Ġè¿Ļæĺ¯', 'ä¸Ģ段', 'ä¸Ńèĭ±', 'æ··', 'è¾ĵ', 'çļĦ', 'åı¥åŃIJ', 'Ġ,', 'Ġ(', 'Ġch', 'inese', 'Ġand', 'ĠEng', 'lish', 'Ġ,', 'Ġh', 'ere', 'Ġare', 'Ġw', 'ord', 's', 'Ġ.', 'Ġ)']Empezar a entrenar:
# 确保你的训练语料`txt`文件已经data目录下
python train_tokenizer . py {
"prompt" : "对于花园街,你有什么了解或看法吗? " ,
"response" : "花园街(是香港油尖旺区的一条富有特色的街道,位于九龙旺角东部,北至界限街,南至登打士街,与通菜街及洗衣街等街道平行。现时这条街道是香港著名的购物区之一。位于亚皆老街以南的一段花园街,也就是"波鞋街"整条街约150米长,有50多间售卖运动鞋和运动用品的店舖。旺角道至太子道西一段则为排档区,售卖成衣、蔬菜和水果等。花园街一共分成三段。明清时代,花园街是芒角村栽种花卉的地方。此外,根据历史专家郑宝鸿的考证:花园街曾是1910年代东方殷琴拿烟厂的花园。纵火案。自2005年起,花园街一带最少发生5宗纵火案,当中4宗涉及排档起火。2010年。2010年12月6日,花园街222号一个卖鞋的排档于凌晨5时许首先起火,浓烟涌往旁边住宅大厦,消防接报4 "
}jupyter-lab o cuaderno jupyter:
Consulte el archivo train.ipynb . Se recomienda utilizar jupyter-lab para evitar considerar la situación en la que el proceso del terminal finaliza después de desconectarse del servidor.
Consola:
La capacitación de la consola debe considerar que el proceso finalizará después de que se desconecte la conexión. Se recomienda utilizar la herramienta del demonio de proceso Supervisor o screen para establecer una sesión de conexión.
Primero, configure accelerate , ejecute el siguiente comando y seleccione de acuerdo con las indicaciones. Consulte accelerate.yaml Nota: DeepSpeed es más problemático de instalar en Windows .
accelerate config Inicie el entrenamiento si desea utilizar la configuración proporcionada por el proyecto, agregue el parámetro --config_file ./accelerate.yaml después del siguiente comando accelerate launch . La configuración se basa en la configuración de 2xGPU de una sola máquina.
Hay dos scripts para el entrenamiento previo. El entrenador implementado en este proyecto corresponde a train.py y el entrenador implementado por huggingface corresponde a pre_train.py . Puede usar cualquiera de ellos y el efecto será el mismo. El entrenador implementado en este proyecto muestra información de capacitación más hermosa y facilita la modificación de los detalles de la capacitación (como funciones de pérdida, registros, etc.). Todos los puntos de interrupción compatibles para continuar con la capacitación. punto de interrupción en cualquier posición. Presione ctrl+c para guardar la información del punto de interrupción al salir del script.
Máquina única y tarjeta única:
# 本项目实现的trainer
accelerate launch ./train.py train
# 或者使用 huggingface trainer
python pre_train.py Máquina única con varias tarjetas: 2 es el número de tarjetas gráficas, modifíquelo según su situación real.
# 本项目实现的trainer
accelerate launch --multi_gpu --num_processes 2 ./train.py train
# 或者使用 huggingface trainer
accelerate launch --multi_gpu --num_processes 2 pre_train.pyContinuar entrenando desde el punto de interrupción:
# 本项目实现的trainer
accelerate launch --multi_gpu --num_processes 2 ./train.py train --is_keep_training=True
# 或者使用 huggingface trainer
# 需要在`pre_train.py`中的`train`函数添加`resume_from_checkpoint=True`
accelerate launch --multi_gpu --num_processes 2 pre_train.pyTodo el conjunto de datos SFT proviene de la contribución de BELLE boss, gracias. Los conjuntos de datos SFT son: generate_chat_0.4M, train_0.5M_CN y train_2M_CN, quedando aproximadamente 1,37 millones de filas después de la limpieza. Ejemplo de ajuste de un conjunto de datos con el comando sft:
{
"prompt" : "解释什么是欧洲启示录" ,
"response" : "欧洲启示录(The Book of Revelation)是新约圣经的最后一卷书,也被称为《启示录》、《默示录》或《约翰默示录》。这本书从宗教的角度描述了世界末日的来临,以及上帝对世界的审判和拯救。 书中的主题包括来临的基督的荣耀,上帝对人性的惩罚和拯救,以及魔鬼和邪恶力量的存在。欧洲启示录是一个充满象征和暗示的文本,对于解读和理解有许多不同的方法和观点。 "
} Cree su propio conjunto de datos consultando el archivo parquet de muestra en el directorio data . El formato del conjunto de datos es: parquet se divide en dos columnas, una columna de texto prompt , que representa la solicitud, y una columna de texto response . que representa el resultado esperado del modelo. Para obtener detalles sobre el ajuste, consulte el método train en model/trainer.py . Cuando is_finetune está configurado en True , el ajuste se congelará de forma predeterminada y solo entrenará el decodificador. capa. Si necesita congelar otros parámetros, ajuste el código usted mismo.
Ejecute el ajuste fino de SFT:
# 本项目实现的trainer, 添加参数`--is_finetune=True`即可, 参数`--is_keep_training=True`可从任意断点处继续训练
accelerate launch --multi_gpu --num_processes 2 ./train.py --is_finetune=True
# 或者使用 huggingface trainer, 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 sft_train.py
python sft_train.pyAquí hay dos métodos preferidos comunes: PPO y DPO. Busque artículos y blogs para implementaciones específicas.
Método PPO (optimización de preferencias aproximadas, optimización de políticas próximas)
Paso 1: utilice el conjunto de datos de ajuste fino para realizar un ajuste fino supervisado (SFT, Supervised Finetuning).
Paso 2: Utilice el conjunto de datos de preferencias (un mensaje contiene al menos 2 respuestas, una respuesta deseada y una respuesta no deseada. Se pueden ordenar varias respuestas por puntuación, y la más buscada tiene la puntuación más alta) para entrenar el modelo de recompensa (RM , Modelo de recompensa). Puede utilizar la biblioteca peft para crear rápidamente el modelo de recompensa de Lora.
Paso 3: Utilice RM para realizar capacitación PPO supervisada en el modelo SFT para que el modelo cumpla con las preferencias.
Utilice el ajuste fino de DPO (optimización de preferencia directa) ( este proyecto utiliza el método de ajuste fino de DPO, que ahorra memoria de video . Sobre la base de obtener el modelo SFT, no es necesario entrenar el modelo de recompensa para obtener respuestas positivas (). elegido) y respuestas negativas (rechazadas) para comenzar a afinar. El texto chosen ajustado proviene del conjunto de datos original alpaca-gpt4-data-zh, y el texto rejected proviene de la salida del modelo después del ajuste fino de SFT durante 1 época. Los otros dos conjuntos de datos: huozi_rlhf_data_json y rlhf-reward-. single-round-trans_chinese, después de fusionar Un total de 80.000 datos dpo.
Para conocer el proceso de procesamiento del conjunto de datos de dpo, consulte utils/dpo_data_process.py .
Ejemplo de conjunto de datos de optimización de preferencias de DPO:
{
"prompt" : "为给定的产品创建一个创意标语。,输入:可重复使用的水瓶。 " ,
"chosen" : " "保护地球,从拥有可重复使用的水瓶开始! " " ,
"rejected" : " "让你的水瓶成为你的生活伴侣,使用可重复使用的水瓶,让你的水瓶成为你的伙伴" "
}Ejecute la optimización de preferencias:
# 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 dpo_train.py
python dpo_train.py Asegúrese de que existan los siguientes archivos en el directorio model_save . Estos archivos se pueden encontrar en el almacén ChatLM-Chinese-0.2B Hugging Face Hub :
ChatLM-mini-Chinese
├─model_save
| ├─config.json
| ├─configuration_chat_model.py
| ├─generation_config.json
| ├─model.safetensors
| ├─modeling_chat_model.py
| ├─special_tokens_map.json
| ├─tokenizer.json
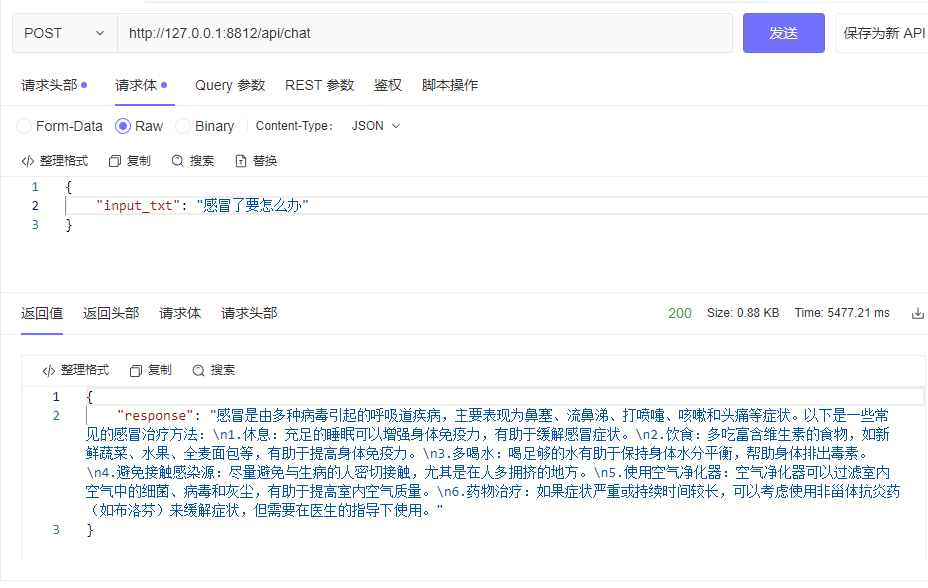
| └─tokenizer_config.jsonpython cli_demo.pypython api_demo.pyEjemplo de llamada API:
curl --location ' 127.0.0.1:8812/api/chat '
--header ' Content-Type: application/json '
--header ' Authorization: Bearer Bearer '
--data ' {
"input_txt": "感冒了要怎么办"
} ' 
Aquí tomamos la información del triplete en el texto como ejemplo para realizar un ajuste posterior. Para conocer el método tradicional de extracción de aprendizaje profundo para esta tarea, consulte el almacén pytorch_IE_model. Extraiga todos los triples en un fragmento de texto, como la oración 《写生随笔》是冶金工业2006年出版的图书,作者是张来亮, extraiga los triples (写生随笔,作者,张来亮) y (写生随笔,出版社,冶金工业) .
El conjunto de datos original es: conjunto de datos de triple extracción de Baidu. Ejemplo del formato del conjunto de datos ajustado procesado:
{
"prompt" : "请抽取出给定句子中的所有三元组。给定句子:《家乡的月亮》是宋雪莱演唱的一首歌曲,所属专辑是《久违的哥们》 " ,
"response" : " [(家乡的月亮,歌手,宋雪莱),(家乡的月亮,所属专辑,久违的哥们)] "
} Puede utilizar directamente el script sft_train.py para realizar ajustes finos. El script finetune_IE_task.ipynb contiene el proceso de decodificación detallado. El conjunto de datos de entrenamiento tiene alrededor de 17000 elementos, la tasa de aprendizaje 5e-5 y la época de entrenamiento 5 . Las capacidades de diálogo de otras tareas no han desaparecido después del ajuste.

Efecto de ajuste fino: utilice el conjunto de datos dev publicado百度三元组抽取数据集como conjunto de prueba para comparar con el método tradicional pytorch_IE_model.
| Modelo | puntuación F1 | Precisión P | Recordar R |
|---|---|---|---|
| ChatLM-Chinese-0.2B ajuste fino | 0,74 | 0,75 | 0,73 |
| ChatLM-Chinese-0.2B sin entrenamiento previo | 0,51 | 0,53 | 0,49 |
| Métodos tradicionales de aprendizaje profundo. | 0,80 | 0,79 | 80.1 |
Nota: ChatLM-Chinese-0.2B无预训练significa inicializar directamente parámetros aleatorios y comenzar el entrenamiento con una tasa de aprendizaje de 1e-4 . Otros parámetros son consistentes con el ajuste fino.
El modelo en sí no se entrena utilizando un conjunto de datos más grande, ni está ajustado para las instrucciones para responder preguntas de opción múltiple. La puntuación C-Eval es básicamente un nivel de referencia y puede usarse como referencia si es necesario. Código de evaluación C-Eval ver: eval/c_eavl.ipynb
| categoría | correcto | cuenta_pregunta | exactitud |
|---|---|---|---|
| Humanidades | 63 | 257 | 24,51% |
| Otro | 89 | 384 | 23,18% |
| PROVENIR | 89 | 430 | 20,70% |
| Ciencia social | 72 | 275 | 26,18% |
Si cree que este proyecto le resulta útil, cítelo.
@misc{Charent2023,
author={Charent Chen},
title={A small chinese chat language model with 0.2B parameters base on T5},
year={2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/charent/ChatLM-mini-Chinese}},
}
Este proyecto no asume ningún riesgo ni responsabilidad que surja de los riesgos para la seguridad de los datos y la opinión pública causados por modelos y códigos de fuente abierta, o cualquier modelo que sea engañado, abusado, difundido o explotado indebidamente.


