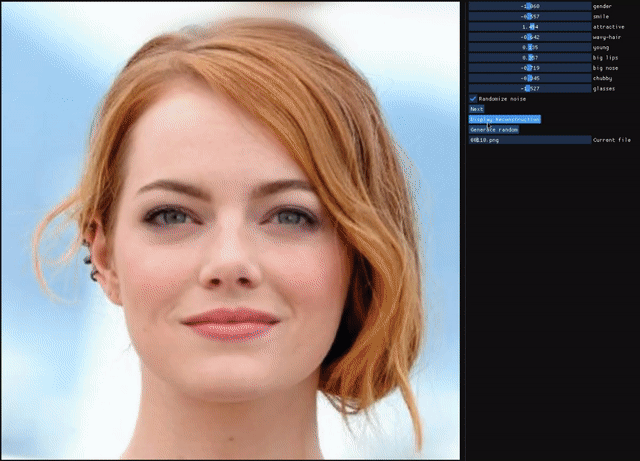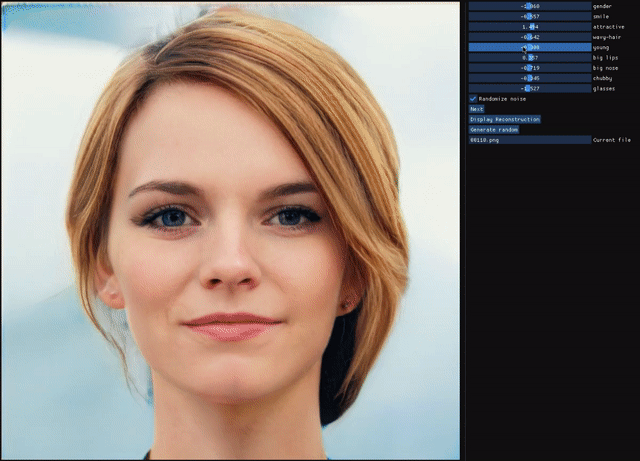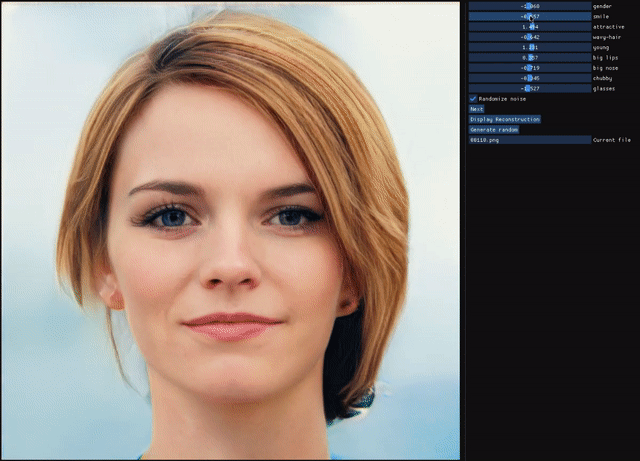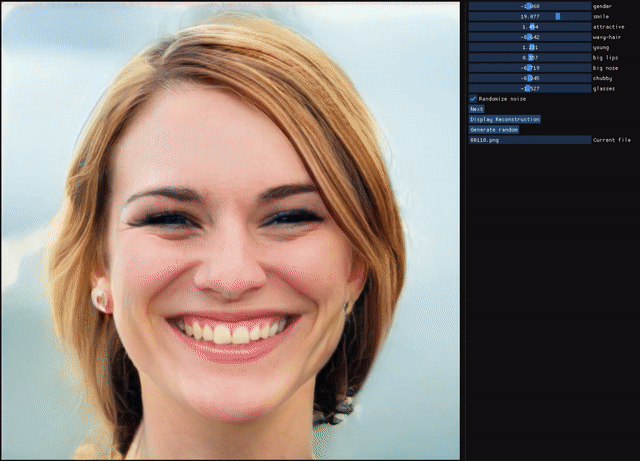
ALAE
1.0.0
Stanislav Pidhorskyi • Donald A. Adjeroh • Gianfranco Doretto
 |  |
Carpeta de Google Drive con modelos y resultados cualitativos.
Autocodificadores latentes adversarios
Stanislav Pidhorskyi, Donald Adjeroh, Gianfranco DorettoResumen: Las redes de codificadores automáticos son enfoques no supervisados que tienen como objetivo combinar propiedades generativas y representacionales aprendiendo simultáneamente un mapa codificador-generador. Aunque se han estudiado exhaustivamente, la cuestión de si tienen el mismo poder generativo que las GAN o si aprenden representaciones desenredadas no se ha abordado por completo. Presentamos un codificador automático que aborda estos problemas de forma conjunta, al que llamamos codificador automático latente adversario (ALAE). Es una arquitectura general que puede aprovechar las mejoras recientes en los procedimientos de capacitación de GAN. Diseñamos dos codificadores automáticos: uno basado en un codificador MLP y otro basado en un generador StyleGAN, al que llamamos StyleALAE. Verificamos las propiedades de desenredo de ambas arquitecturas. Mostramos que StyleALAE no solo puede generar imágenes faciales de 1024x1024 con una calidad comparable a StyleGAN, sino que también puede producir reconstrucciones y manipulaciones faciales basadas en imágenes reales con la misma resolución. Esto convierte a ALAE en el primer codificador automático capaz de compararse e ir más allá de las capacidades de un tipo de arquitectura de solo generador.
@InProceedings{pidhorskyi2020adversarial,
author = {Pidhorskyi, Stanislav and Adjeroh, Donald A and Doretto, Gianfranco},
booktitle = {Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR)},
title = {Adversarial Latent Autoencoders},
year = {2020},
note = {[to appear]},
}
Para ejecutar la demostración, necesitará tener una GPU compatible con CUDA, PyTorch >= v1.3.1 y controladores cuda/cuDNN instalados. Instale los paquetes necesarios:
pip install -r requirements.txt
Descargue modelos previamente entrenados:
python training_artifacts/download_all.py
Ejecute la demostración:
python interactive_demo.py
Puede especificar la configuración de yaml para usar. Las configuraciones se encuentran aquí: https://github.com/podgorskiy/ALAE/tree/master/configs. De forma predeterminada, utiliza uno para el conjunto de datos FFHQ. Puede cambiar la configuración usando el parámetro -c . Para ejecutar en celeb-hq con una resolución de 256x256, ejecute:
python interactive_demo.py -c celeba-hq256
Sin embargo, para configuraciones distintas a FFHQ, es necesario obtener nuevos vectores de dirección principales para los atributos.
El código del repositorio está organizado de tal manera que todos los scripts deben ejecutarse desde la raíz del repositorio. Si utiliza un IDE (por ejemplo, PyCharm o Visual Studio Code), simplemente configure el Directorio de trabajo para que apunte a la raíz del repositorio.
Si desea ejecutar desde la línea de comando, también debe configurar la variable PYTHONPATH para que apunte a la raíz del repositorio.
Por ejemplo, digamos que hemos clonado el repositorio en el directorio ~/ALAE , luego hagamos:
$ cd ~/ALAE
$ export PYTHONPATH=$PYTHONPATH:$(pwd)
Ahora puede ejecutar scripts de la siguiente manera:
$ python style_mixing/stylemix.py
| Camino | Descripción |
|---|---|
| ALAE | Carpeta raíz del repositorio |
| ├ configuraciones | Carpeta con archivos de configuración yaml. |
| │ ├ dormitorio.yaml | Archivo de configuración para el conjunto de datos del dormitorio LSUN con una resolución de 256x256. |
| │ ├ celeba.yaml | Archivo de configuración para el conjunto de datos CelebA con una resolución de 128x128. |
| │ ├ celeba-hq256.yaml | Archivo de configuración para el conjunto de datos CelebA-HQ con una resolución de 256x256. |
| │ ├ celeba_ablation_nostyle.yaml | Archivo de configuración para el conjunto de datos CelebA 128x128 para estudio de ablación (sin estilos). |
| │ ├ celeba_ablation_separate.yaml | Archivo de configuración para el conjunto de datos CelebA 128x128 para estudio de ablación (codificador y discriminador separados). |
| │ ├ celeba_ablation_z_reg.yaml | Archivo de configuración para el conjunto de datos CelebA 128x128 para estudio de ablación (regresión en el espacio Z, no en W). |
| │ ├ ffhq.yaml | Archivo de configuración para el conjunto de datos FFHQ con una resolución de 1024x1024. |
| │ ├ mnist.yaml | Archivo de configuración para el conjunto de datos MNIST utilizando la arquitectura Style. |
| │ └ mnist_fc.yaml | Archivo de configuración para el conjunto de datos MNIST que utiliza solo capas completamente conectadas (MNIST invariante de permutación). |
| ├ preparación_del_conjunto de datos | Carpeta con scripts para la preparación de conjuntos de datos. |
| │ ├ prepare_celeba_hq_tfrec.py | Para preparar TFRecords para el conjunto de datos CelebA-HQ con una resolución de 256x256. |
| │ ├ prepara_celeba_tfrec.py | Para preparar TFRecords para el conjunto de datos CelebA con una resolución de 128x128. |
| │ ├ prepare_mnist_tfrec.py | Para preparar TFRecords para el conjunto de datos MNIST. |
| │ ├ split_tfrecords_dormitorio.py | Para dividir TFRecords oficiales del documento StyleGAN para el conjunto de datos del dormitorio LSUN. |
| │ └ split_tfrecords_ffhq.py | Para dividir TFRecords oficiales del documento StyleGAN para el conjunto de datos FFHQ. |
| ├ conjunto de datos_muestras | Carpeta con entradas de muestra para diferentes conjuntos de datos. Se utiliza para cifras y para entradas de prueba durante el entrenamiento. |
| ├ hacer_figuras | Guiones para realizar varias figuras. |
| ├ métricas | Scripts para calcular métricas. |
| ├ direcciones_principales | Scripts para calcular vectores de dirección principales para varios atributos. Para demostración interactiva . |
| ├ mezcla de estilos | Ejemplos de aportaciones y guión para producir figuras que combinen estilos. |
| ├ artefactos_entrenamiento | Lugar predeterminado para guardar puntos de control/salidas de muestra/gráficos. |
| │ └ descargar_all.py | Script para descargar todos los modelos previamente entrenados. |
| ├ interactivo_demo.py | Script ejecutable para demostración interactiva. |
| ├ tren_alae.py | Script ejecutable para entrenamiento. |
| ├ train_alae_separate.py | Script ejecutable para entrenamiento para estudio de ablación (codificador y discriminador separados). |
| ├ checkpointer.py | Módulo para guardar/restaurar pesos de modelos, estado del optimizador e historial de pérdidas. |
| ├ personalizado_adam.py | Optimizador Adam personalizado para ecualización de la tasa de aprendizaje y beta de cero segundos. |
| ├cargador de datos.py | Módulo con clases de conjuntos de datos, cargadores, iteradores, etc. |
| ├ valores predeterminados.py | Definición de variables de configuración con valores predeterminados. |
| ├ lanzador.py | Ayudante para ejecutar entrenamiento multiproceso y multi-GPU. Configura la configuración y el registro. |
| ├ lod_driver.py | Clase de ayuda para gestionar redes en crecimiento/estabilización. |
| ├ lreq.py | Módulos personalizados Linear , Conv2d y ConvTranspose2d para ecualización de la tasa de aprendizaje. |
| ├ modelo.py | Módulo con definición de modelo de alto nivel. |
| ├ model_separate.py | Igual que el anterior, pero para estudio de ablación. |
| ├ net.py | Definición de todos los bloques de red para múltiples arquitecturas. |
| ├ registro.py | Registro de bloques de red para seleccionar desde el archivo de configuración. |
| ├ programador.py | Programadores personalizados con inicio en caliente y agregación de varios optimizadores. |
| ├ rastreador.py | Módulo de trazado de pérdidas. |
| └ utils.py | Decorador para llamadas asíncronas, decorador para almacenamiento en caché, registro para bloques de red. |
En este código base, yacs se utiliza para manejar configuraciones.
La mayoría de los scripts ejecutables aceptan el parámetro -c que puede especificar los archivos de configuración que se utilizarán. Por ejemplo, para hacer figuras de reconstrucción, puedes ejecutar:
python make_figures/make_recon_figure_paged.py
python make_figures/make_recon_figure_paged.py -c celeba
python make_figures/make_recon_figure_paged.py -c celeba-hq256
python make_figures/make_recon_figure_paged.py -c bedroom
La configuración predeterminada es ffhq .
La formación se realiza mediante TFRecords. Los TFRecords se leen usando DareBlopy, que permite usarlos con Pytorch.
En los archivos de configuración, así como en todos los scripts de preparación, se supone que todos los conjuntos de datos están en /data/datasets/ . Puede cambiar la ruta en los archivos de configuración o crear un enlace simbólico donde almacena los conjuntos de datos.
La forma oficial de generar CelebA-HQ puede resultar un desafío. Consulte esta página: https://github.com/suvojit-0x55aa/celebA-HQ-dataset-download. Puede obtener el conjunto de datos pregenerado desde: https://drive.google.com/drive/folders/11Vz0fqHS2rXDb5pprgTjpD7S2BAJhi1P
Para descargar modelos previamente entrenados, ejecute:
python training_artifacts/download_all.py
Nota : Solía haber problemas con la descarga de modelos desde Google Drive debido al límite de descarga. Ahora, el script está configurado de tal manera que si no puede descargar datos de Google Drive, intentará descargarlos desde S3.
Si tiene problemas, intente eliminar todos los archivos *.pth, actualice el paquete dlutils ( pip install dlutils --upgrade ) y luego ejecute download_all.py nuevamente. Si eso no resuelve el problema, abra un problema. Además, puede intentar descargar modelos manualmente desde aquí: https://drive.google.com/drive/folders/1tsI1q1u8QRX5t7_lWCSjpniLGlNY-3VY?usp=sharing
En los archivos de configuración, OUTPUT_DIR apunta al lugar donde se guardan y leen los pesos. Por ejemplo: OUTPUT_DIR: training_artifacts/celeba-hq256
En OUTPUT_DIR guarda un archivo last_checkpoint que contiene la ruta al pepinillo .pth real con el peso del modelo. Si desea probar el modelo con un archivo de peso específico, simplemente puede modificar el archivo last_checkpoint .
Para generar figuras de mezcla de estilos ejecute:
python style_mixing/stylemix.py -c <config>
Donde en lugar de <config> ponga uno de: ffhq , celeba , celeba-hq256 , bedroom
Para generar una reconstrucción con imágenes a múltiples escalas:
python make_figures/make_recon_figure_multires.py -c <config>
Para generar una reconstrucción a partir de todas las entradas de muestra en varias páginas:
python make_figures/make_recon_figure_paged.py -c <config>
También hay:
python make_figures/old/make_recon_figure_celeba.py
python make_figures/old/make_recon_figure_bed.py
Para generar la reconstrucción a partir del conjunto de prueba de FFHQ:
python make_figures/make_recon_figure_ffhq_real.py
Para generar una figura de interpolación:
python make_figures/make_recon_figure_interpolation.py -c <config>
Para generar la figura de recorridos:
(Para conjuntos de datos que no sean FFHQ, primero deberá encontrar las direcciones principales)
python make_figures/make_traversarls.py -c <config>
Para ejecutar la cifra de generación:
make_generation_figure.py -c <config>
Además de instalar los paquetes requeridos:
pip install -r requirements.txt
Necesitarás instalar DareBlopy:
pip install dareblopy
Para ejecutar el entrenamiento:
python train_alae.py -c <config>
Ejecutará entrenamiento de múltiples GPU en todas las GPU disponibles. Utiliza DistributedDataParallel para el paralelismo. Si solo hay una GPU disponible, se ejecutará en una sola GPU, no se necesita ningún cuidado especial.
La cantidad recomendada de GPU es 8. La reproducibilidad en una cantidad menor de GPU puede tener problemas. Es posible que deba ajustar el tamaño del lote en el archivo de configuración según el tamaño de la memoria de las GPU.
Además de instalar los paquetes necesarios y DareBlopy, debe instalar TensorFlow y dnnlib de StyleGAN.
Tensorflow debe ser de la versión 1.10 :
pip install tensorflow-gpu==1.10
Requiere CUDA versión 9.0.
Quizás la mejor manera sea usar Anaconda para manejar esto, pero prefiero instalar CUDA 9.0 desde repositorios pop-os (funciona en Ubuntu):
sudo echo "deb http://apt.pop-os.org/proprietary bionic main" | sudo tee -a /etc/apt/sources.list.d/pop-proprietary.list
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-key 204DD8AEC33A7AFF
sudo apt update
sudo apt install system76-cuda-9.0
sudo apt install system76-cudnn-9.0
Luego simplemente configure la variable LD_LIBRARY_PATH :
export LD_LIBRARY_PATH=/usr/lib/cuda-9.0/lib64
Dnnlib es un paquete utilizado en StyleGAN. Puedes instalarlo con:
pip install https://github.com/podgorskiy/dnnlib/releases/download/0.0.1/dnnlib-0.0.1-py3-none-any.whl
Todo el código para ejecutar métricas se basa en gran medida en los del repositorio StyleGAN. También utiliza los mismos modelos previamente entrenados:
https://github.com/NVlabs/stylegan#licenses
inception_v3_features.pkl e inception_v3_softmax.pkl se derivan de la red Inception-v3 previamente entrenada por Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens y Zbigniew Wojna. La red se compartió originalmente bajo la licencia Apache 2.0 en el repositorio de TensorFlow Models.
vgg16.pkl y vgg16_zhang_perceptual.pkl se derivan de la red VGG-16 previamente entrenada por Karen Simonyan y Andrew Zisserman. La red se compartió originalmente bajo la licencia Creative Commons BY 4.0 en la página del proyecto Redes convolucionales muy profundas para el reconocimiento visual a gran escala.
vgg16_zhang_perceptual.pkl se deriva además de los pesos LPIPS previamente entrenados por Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman y Oliver Wang. Los pesos se compartieron originalmente bajo la licencia "simplificada" de cláusula 2 BSD en el repositorio PerceptualSimilarity.
Finalmente, para ejecutar métricas:
python metrics/fid.py -c <config> # FID score on generations
python metrics/fid_rec.py -c <config> # FID score on reconstructions
python metrics/ppl.py -c <config> # PPL score on generations
python metrics/lpips.py -c <config> # LPIPS score of reconstructions