dialog eval
1.0.0
Un repositorio liviano para la evaluación automática de modelos de diálogo utilizando 17 métricas .
? Elija qué métricas desea que se calculen
La evaluación puede ejecutarse automáticamente en un archivo de respuestas o en un directorio que contenga varios archivos.
? Las métricas se guardan en un formato predefinido fácil de procesar.
Ejecute este comando para instalar los paquetes necesarios:
pip install -r requirements.txt
El archivo principal se puede llamar desde cualquier lugar, pero al especificar rutas a los directorios debe proporcionarlas desde la raíz del repositorio.
python code/main.py -h
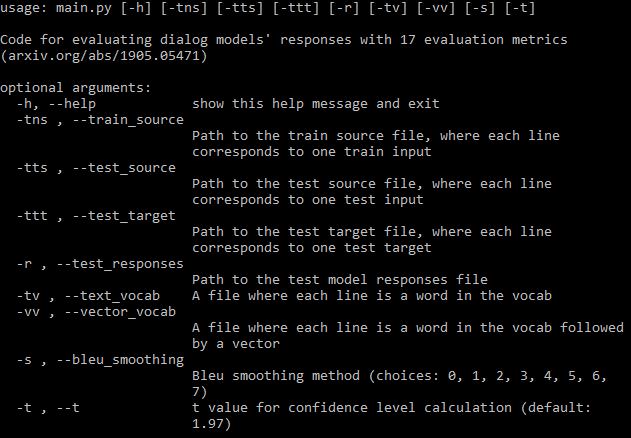
Para obtener la documentación completa, visite la wiki.
Debe proporcionar tantas rutas de argumentos requeridas (imagen de arriba) como sea posible. Si omite algunos, el programa aún se ejecutará, pero no calculará algunas métricas que requieran esos archivos (imprimirá estas métricas). Si tiene un archivo de datos de entrenamiento, el programa puede generar automáticamente un vocabulario y descargar incrustaciones de fastText.
Si no desea calcular todas las métricas, puede establecer muy fácilmente qué métricas deben calcularse en el archivo de configuración.
Se guardará un archivo en el directorio donde se encuentran los archivos de respuesta. La primera fila contiene los nombres de las métricas y luego cada fila contiene las métricas de un archivo. El nombre del archivo va seguido de los valores de métricas individuales separados por espacios. Cada métrica consta de tres números separados por comas: la media, la desviación estándar y el intervalo de confianza. Puede establecer el valor t del intervalo de confianza en los argumentos; el valor predeterminado es un 95% de confianza.
Curiosamente, las 17 métricas mejoran hasta cierto punto y luego se estancan sin que se produzca sobreajuste durante el entrenamiento de un modelo Transformer en DailyDialog. Consulte el apéndice del artículo para ver las figuras. 
TRF es el modelo Transformer evaluado en el mínimo de pérdida de validación y TRF-O es el modelo Transformer evaluado después de 150 épocas de entrenamiento, donde las métricas comienzan a estancarse. RT significa respuestas seleccionadas aleatoriamente del conjunto de entrenamiento y GT significa respuestas reales sobre el terreno.

TRF es el modelo Transformer, mientras que RT significa respuestas seleccionadas aleatoriamente del conjunto de entrenamiento y GT significa respuestas reales. Estos resultados se miden en el equipo de prueba en un punto de control donde la pérdida de validación fue mínima.

TRF es el modelo Transformer, mientras que RT significa respuestas seleccionadas aleatoriamente del conjunto de entrenamiento y GT significa respuestas reales. Estos resultados se miden en el equipo de prueba en un punto de control donde la pérdida de validación fue mínima.
Se pueden agregar nuevas métricas creando una clase para la métrica, que maneja el cálculo de los datos dados de la métrica. Consulte las métricas de BLEU para ver un ejemplo. Normalmente, la función init maneja cualquier configuración de datos que se necesite más adelante, y update_metrics actualiza el dictado de métricas utilizando el ejemplo actual de los argumentos. Dentro de la clase debes definir el dictado self.metrics, que almacena listas de valores de métricas para un archivo de prueba determinado. Los nombres de estas métricas (claves del diccionario) también deben agregarse en el archivo de configuración de self.metrics. Finalmente necesitas agregar una instancia de tu clase métrica a self.objects. Aquí, durante la inicialización, puede utilizar rutas a archivos de datos si su métrica requiere alguna configuración. Después de esto, su métrica debería calcularse y guardarse automáticamente.
Sin embargo, también debe agregar algunas restricciones a su métrica, por ejemplo, si falta un archivo requerido para el cálculo de la métrica, se debe notificar al usuario, como aquí.
Este proyecto tiene la licencia MIT; consulte el archivo de LICENCIA para obtener más detalles.
Incluya un enlace a este repositorio si lo utiliza en su trabajo y considere citar el siguiente documento:
@inproceedings{Csaky:2019,
title = "Improving Neural Conversational Models with Entropy-Based Data Filtering",
author = "Cs{'a}ky, Rich{'a}rd and Purgai, Patrik and Recski, G{'a}bor",
booktitle = "Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2019",
address = "Florence, Italy",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/P19-1567",
pages = "5650--5669",
}


