Transformer in generating dialogue
1.0.0
El código es una implementación de Paper Attention, es todo lo que necesita para trabajar en tareas de generación de diálogos como: Chatbot , generación de texto , etc.
Gracias a todos los amigos que plantearon problemas y ayudaron a resolverlos. Tu contribución es muy importante para la mejora de este proyecto. Debido al soporte limitado del 'modo de gráfico estático' en la codificación, decidimos trasladar las funciones a la versión 2.0.0-beta1. Sin embargo, si le preocupan los problemas de la construcción de Docker y la creación de servicios con problemas de versión, todavía conservamos una versión anterior del código escrito en modo ansioso usando la versión tensorflow 1.12.x como referencia.
|-- root/
|-- data/
|-- src-train.csv
|-- src-val.csv
|-- tgt-train.csv
`-- tgt-val.csv
|-- old_version/
|-- data_loader.py
|-- eval.py
|-- make_dic.py
|-- modules.py
|-- params.py
|-- requirements.txt
`-- train.py
|-- tf1.12.0-eager/
|-- bleu.py
|-- main.ipynb
|-- modules.py
|-- params.py
|-- requirements.txt
`-- utils.py
|-- images/
|-- bleu.py
|-- main-v2.ipynb
|-- modules-v2.py
|-- params.py
|-- requirements.txt
`-- utils-v2.py
Como todos sabemos, el sistema de traducción se puede utilizar para implementar el modelo conversacional simplemente reemplazando dos oraciones diferentes por preguntas y respuestas. Después de todo, el modelo de conversación básico denominado "Secuencia a secuencia" se desarrolla a partir del sistema de traducción. Entonces, ¿por qué no mejorar la eficiencia del modelo de conversación a la hora de generar diálogos?
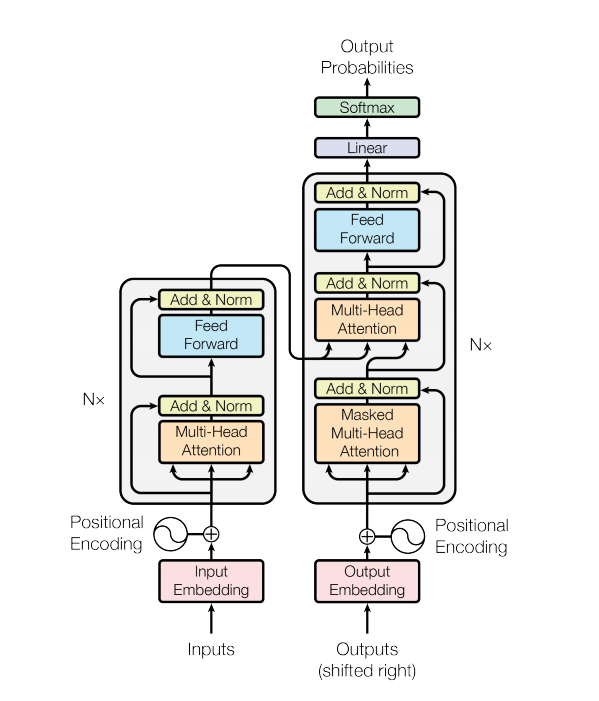
Con el desarrollo de modelos basados en BERT, cada vez más tareas de PNL se actualizan constantemente. Sin embargo, el modelo de lenguaje no está incluido en las tareas de código abierto de BERT. No hay duda de que en este camino aún nos queda un largo camino por recorrer.
Un modelo de transformador maneja entradas de tamaño variable utilizando pilas de capas de autoatención en lugar de RNN o CNN. Esta arquitectura general tiene una serie de ventajas y características especiales. Ahora vamos a sacarlos:
En la versión más reciente de nuestro código , completamos los detalles descritos en papel.
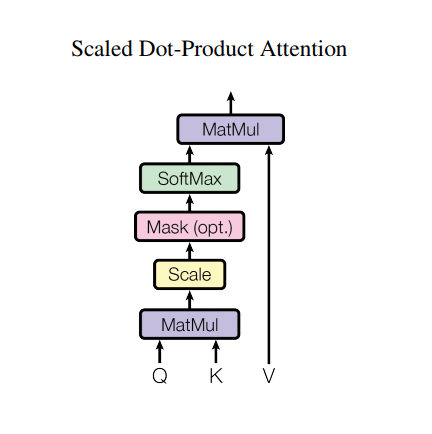
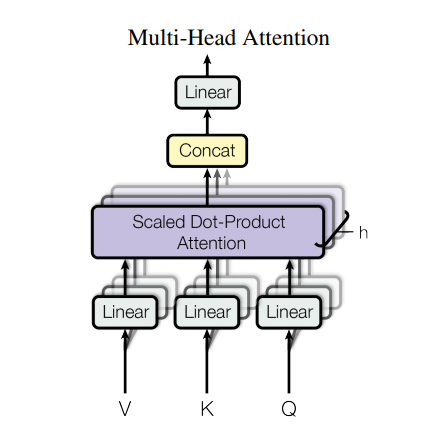
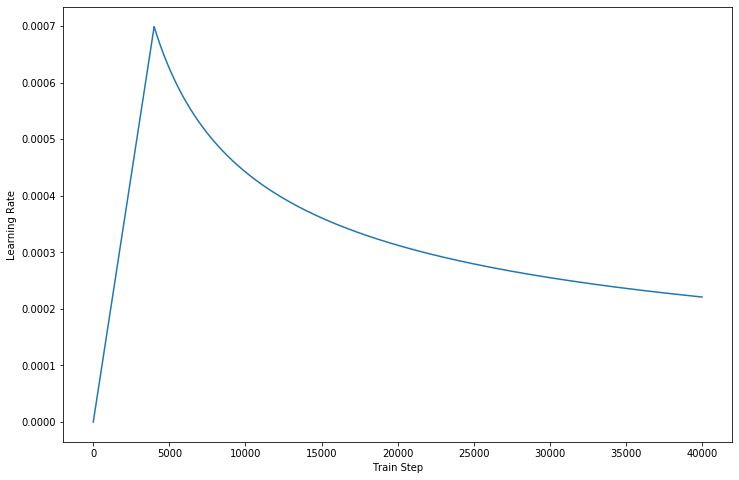
Sin embargo, una arquitectura tan sólida todavía tiene algunas desventajas:
data/ .params.py si lo desea.make_dic.py para generar archivos de vocabulario en una nueva carpeta llamada dictionary .train.py para construir el modelo. El punto de control se almacenará en la carpeta checkpoint mientras que los archivos de eventos de tensorflow se pueden encontrar en logdir .eval.py para evaluar el resultado con datos de prueba. El resultado se almacenará en la carpeta Results .GPU para acelerar el procesamiento de capacitación, configure su dispositivo en el código (admite capacitación de varios trabajadores). - Source: 肥 宅 初 夜 可 以 賣 多 少 `
- Ground Truth: 肥 宅 還 是 去 打 手 槍 吧
- Predict: 肥 宅 還 是 去 打 手 槍 吧
- Source: 兇 的 女 生 484 都 很 胸
- Ground Truth: 我 看 都 是 醜 的 比 較 凶
- Predict: 我 看 都 是 醜 的 比 較 <UNK>
- Source: 留 髮 不 留 頭
- Ground Truth: 還 好 我 早 就 禿 頭 了
- Predict: 還 好 我 早 就 禿 頭 了
- Source: 當 人 好 痛 苦 R 的 八 卦
- Ground Truth: 去 中 國 就 不 用 當 人 了
- Predict: 去 中 國 就 不 會 有 了 -
- Source: 有 沒 有 今 天 捷 運 的 八 卦
- Ground Truth: 有 - 真 的 有 多
- Predict: 有 - 真 的 有 多
- Source: 2016 帶 走 了 什 麼 `
- Ground Truth: HellKitty 麥 當 勞 歡 樂 送 開 門 -
- Predict: <UNK> 麥 當 勞 歡 樂 送 開 門 -
- Source: 有 沒 有 多 益 很 賺 的 八 卦
- Ground Truth: 比 大 型 包 裹 貴
- Predict: 比 大 型 包 <UNK> 貴
- Source: 邊 緣 人 收 到 地 震 警 報 了
- Ground Truth: 都 跑 到 窗 邊 了 才 來
- Predict: 都 跑 到 <UNK> 邊 了 才 來
- Source: 車 震
- Ground Truth: 沒 被 刪 版 主 是 有 眼 睛 der
- Predict: 沒 被 刪 版 主 是 有 眼 睛 der
- Source: 在 家 跌 倒 的 八 卦 `
- Ground Truth: 傷 到 腦 袋 - 可 憐
- Predict: 傷 到 腦 袋 - 可 憐
- Source: 大 家 很 討 厭 核 核 嗎 `
- Ground Truth: 核 核 欠 幹 阿
- Predict: 核 核 欠 幹 阿
- Source: 館 長 跟 黎 明 打 誰 贏 -
- Ground Truth: 我 愛 黎 明 - 我 愛 黎 明 -
- Predict: 我 愛 <UNK> 明 - 我 愛 <UNK> 明 -
- Source: 嘻 嘻 打 打
- Ground Truth: 媽 的 智 障 姆 咪 滾 喇 幹
- Predict: 媽 的 智 障 姆 咪 滾 喇 幹
- Source: 經 典 電 影 台 詞
- Ground Truth: 超 時 空 要 愛 裡 滿 滿 的 梗
- Predict: 超 時 空 要 愛 裡 滿 滿 滿 的
- Source: 2B 守 得 住 街 亭 嗎 `
- Ground Truth: 被 病 毒 滅 亡 真 的 會 -
- Predict: <UNK> 守 得 住
Si intenta utilizar AutoGraph para acelerar su proceso de entrenamiento, asegúrese de que los conjuntos de datos tengan una longitud fija. Debido a que la operación de reconstrucción del gráfico se activará durante el entrenamiento, lo que puede afectar el rendimiento. Nuestro código solo garantiza el rendimiento de la versión 2.0, y las inferiores pueden intentar referirla.
Gracias por Transformer y Tensorflow


