Seq2seq Chatbot for Keras
1.0.0
Este repositorio contiene un nuevo modelo generativo de chatbot basado en el modelado seq2seq. Se pueden encontrar más detalles sobre este modelo en la Sección 3 del artículo Aprendizaje adversario de extremo a extremo para agentes conversacionales generativos. En el caso de una publicación que utilice ideas o fragmentos de código de este repositorio, por favor cite este artículo.
El modelo entrenado disponible aquí utilizó un pequeño conjunto de datos compuesto por ~8.000 pares de contexto (las dos últimas expresiones del diálogo hasta el punto actual) y la respuesta respectiva. Los datos fueron recolectados de diálogos de cursos de inglés en línea. Este modelo entrenado se puede ajustar utilizando un conjunto de datos de dominio cerrado para aplicaciones del mundo real.
El modelo canónico seq2seq se hizo popular en la traducción automática neuronal, una tarea que tiene diferentes distribuciones de probabilidad previa para las palabras que pertenecen a las secuencias de entrada y salida, ya que las expresiones de entrada y salida están escritas en diferentes idiomas. La arquitectura presentada aquí asume las mismas distribuciones anteriores para palabras de entrada y salida. Por lo tanto, comparte una capa de incrustación (incrustación de palabras previamente entrenadas con Glove) entre los procesos de codificación y decodificación mediante la adopción de un nuevo modelo. Para mejorar la sensibilidad al contexto, el vector de pensamiento (es decir, la salida del codificador) codifica las dos últimas expresiones de la conversación hasta el punto actual. Para evitar olvidar el contexto durante la generación de la respuesta, el vector de pensamiento se concatena a un vector denso que codifica la respuesta incompleta generada hasta el punto actual. El vector resultante se proporciona a capas densas que predicen el token actual de la respuesta. Consulte la Sección 3.1 de nuestro artículo para obtener una mejor comprensión de las ventajas de nuestro modelo.
El algoritmo itera incluyendo el token predicho en la respuesta incompleta y devolviéndolo a la capa de entrada del lado derecho del modelo que se muestra a continuación.
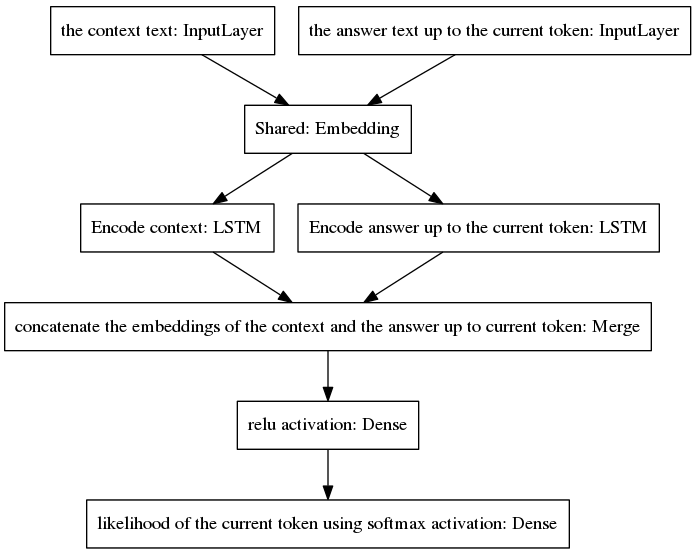
Como se puede ver en la figura anterior, los dos LSTM están dispuestos en paralelo, mientras que el seq2seq canónico tiene las capas recurrentes de codificador y decodificador dispuestas en serie. Las capas recurrentes se despliegan durante la retropropagación a través del tiempo, lo que resulta en una gran cantidad de funciones anidadas y, por lo tanto, un mayor riesgo de desaparición del gradiente, lo que se ve agravado por la cascada de capas recurrentes del modelo canónico seq2seq, incluso en el caso de arquitecturas cerradas. como los LSTM. Creo que esta es una de las razones por las que mi modelo se comporta mejor durante el entrenamiento que el canónico seq2seq.
El siguiente pseudocódigo explica el algoritmo.

El entrenamiento de este nuevo modelo converge en pocas épocas. Utilizando nuestro conjunto de datos de ejemplos de entrenamiento de 8K, solo se necesitaron 100 épocas para alcanzar una pérdida categórica de entropía cruzada de 0,0318, a un costo de 139 s/época ejecutándose en una GPU GTX980. El rendimiento de este modelo entrenado (proporcionado en este repositorio) parece tan convincente como el rendimiento de un modelo vanilla seq2seq entrenado en los ~300.000 ejemplos de entrenamiento del Cornell Movie Dialogs Corpus, pero requiere mucho menos esfuerzo computacional para entrenar.
Para chatear con el modelo previamente entrenado:
Descargue el archivo de Python "conversation.py", el archivo de vocabulario "vocabulary_movie" y los pesos netos "my_model_weights20", que se pueden encontrar aquí;
Ejecute conversación.py.
Para chatear con el nuevo modelo entrenado por nuestro nuevo algoritmo de entrenamiento basado en GAN:
Descargue el archivo de Python "conversation_discriminator.py", el archivo de vocabulario "vocabulary_movie" y los pesos netos "my_model_weights20.h5", "my_model_weights.h5" y "my_model_weights_discriminator.h5", que se pueden encontrar aquí;
Ejecute conversation_discriminator.py.
Este modelo tiene un mejor rendimiento utilizando los mismos datos de entrenamiento. El discriminador del modelo basado en GAN se utiliza para seleccionar la mejor respuesta entre dos modelos, uno entrenado por la fuerza del profesor y otro entrenado por nuestro nuevo método de entrenamiento similar a GAN, cuyos detalles se pueden encontrar en este documento.
Para entrenar un nuevo modelo o realizar ajustes en sus propios datos:
Si quieres entrenar desde cero, elimina el archivo my_model_weights20.h5. Para ajustar sus datos, conserve este archivo;
Descargue la carpeta Glove 'glove.6B' e incluya esta carpeta en el directorio del chatbot (puede encontrar esta carpeta aquí). Este algoritmo aplica el aprendizaje por transferencia mediante el uso de una incrustación de palabras previamente entrenada, que se ajusta durante el entrenamiento;
Ejecute split_qa.py para dividir el contenido de sus datos de entrenamiento en dos archivos: 'context' y 'answers' y get_train_data.py para almacenar las oraciones rellenadas en los archivos 'Padded_context' y 'Padded_answers';
Ejecute train_bot.py para entrenar el chatbot (se recomienda el uso de GPU, para hacerlo escriba: THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32,exception_verbosity=high python train_bot.py);
Nombra tus datos de entrenamiento como "data.txt". Este archivo debe contener una expresión de diálogo por línea. Si su conjunto de datos es grande, establezca la variable num_subsets (en la línea 29 de train_bot.py) en un número mayor.
Weights_file = 'mi_modelo_pesos20.h5' pesos_file_GAN = 'mi_modelo_pesos.h5' pesos_archivo_discrim = 'mi_modelo_pesos_discriminator.h5'
Aquí se puede encontrar una buena descripción general de las implementaciones actuales de modelos conversacionales neuronales para diferentes marcos (junto con algunos resultados).
Nuestro modelo se puede aplicar a otras tareas de PNL, como el resumen de texto; consulte, por ejemplo, Alternativa 2: Modelo recursivo A. Fomentamos la aplicación de nuestro modelo en otras tareas; en este caso, le rogamos que cite nuestro trabajo como pueda. puede verse en este documento, registrado en julio de 2017.
Estos códigos se pueden ejecutar en Ubuntu 14.04.3 LTS, Python 2.7.6, Theano 0.9.0 y Keras 2.0.4. El uso de otra configuración puede requerir algunas adaptaciones menores.


