MiniGPT 3D
1.0.0
Yuan Tang Xu Han Xianzhi Li* Qiao Yu Yixue Hao Long Hu Min Chen
Universidad de Ciencia y Tecnología de Huazhong Universidad de Tecnología del Sur de China
ACM MM 2024
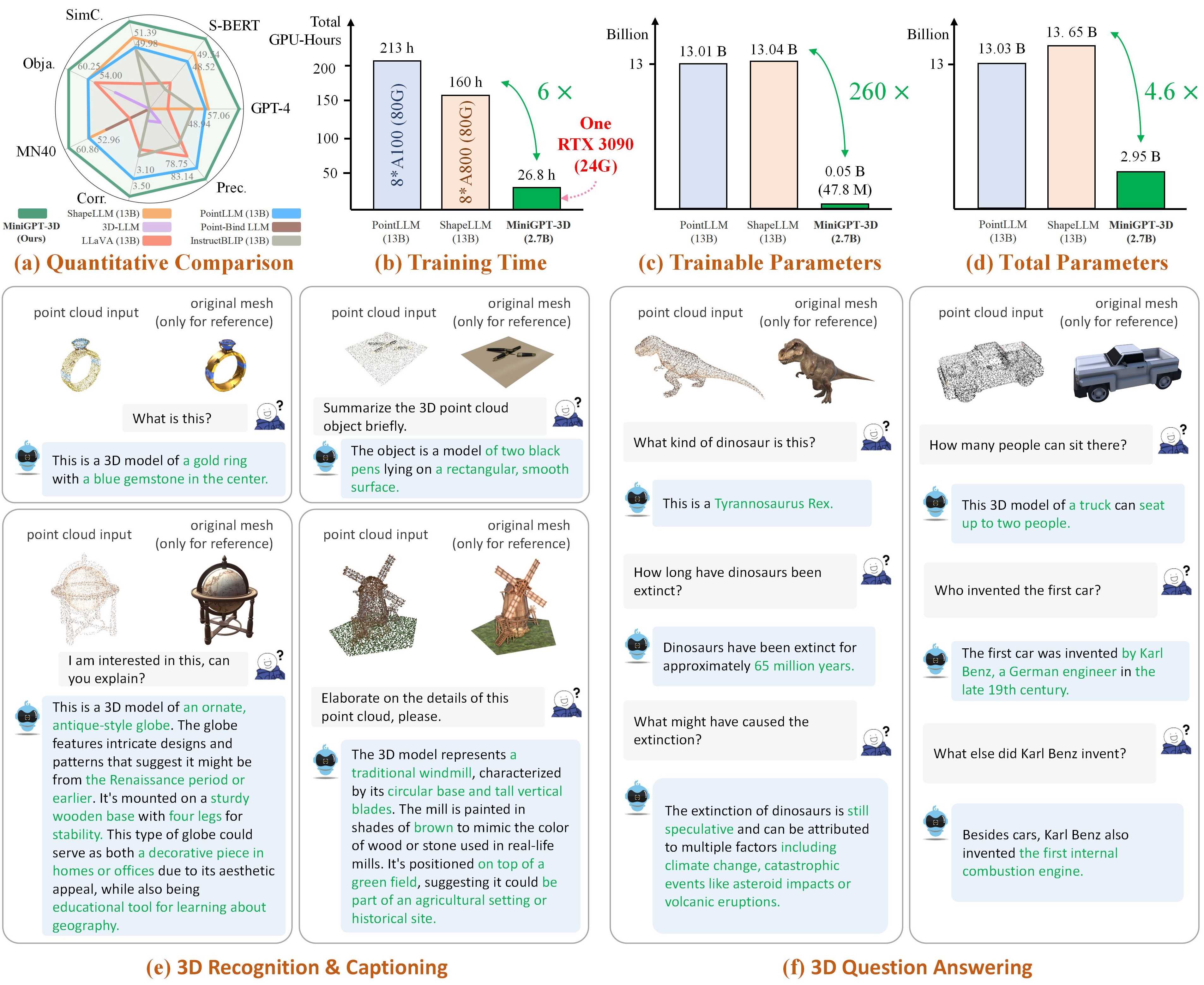

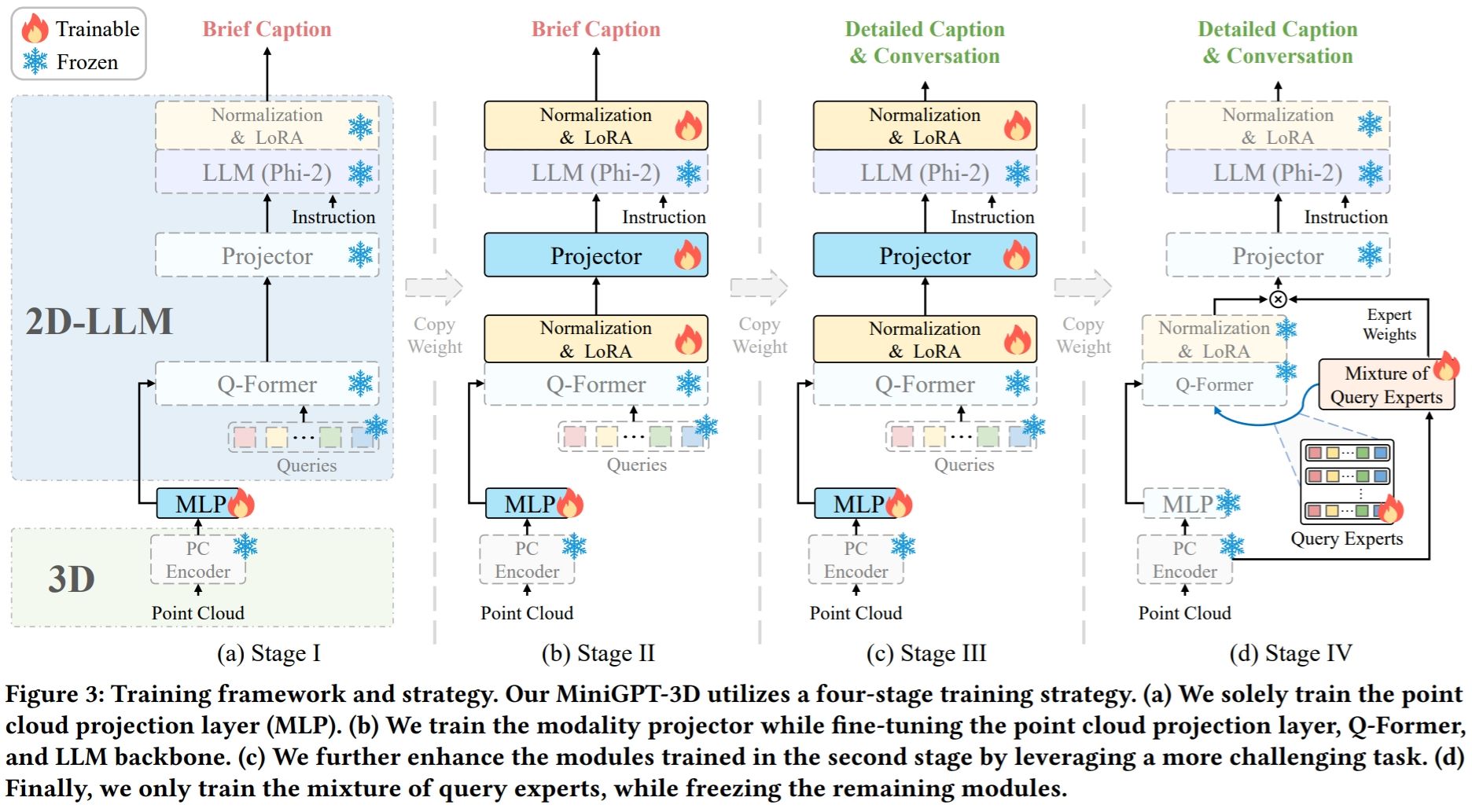
Nota: MiniGPT-3D da el primer paso hacia un 3D-LLM eficiente ; esperamos que MiniGPT-3D pueda aportar nuevos conocimientos a esta comunidad.
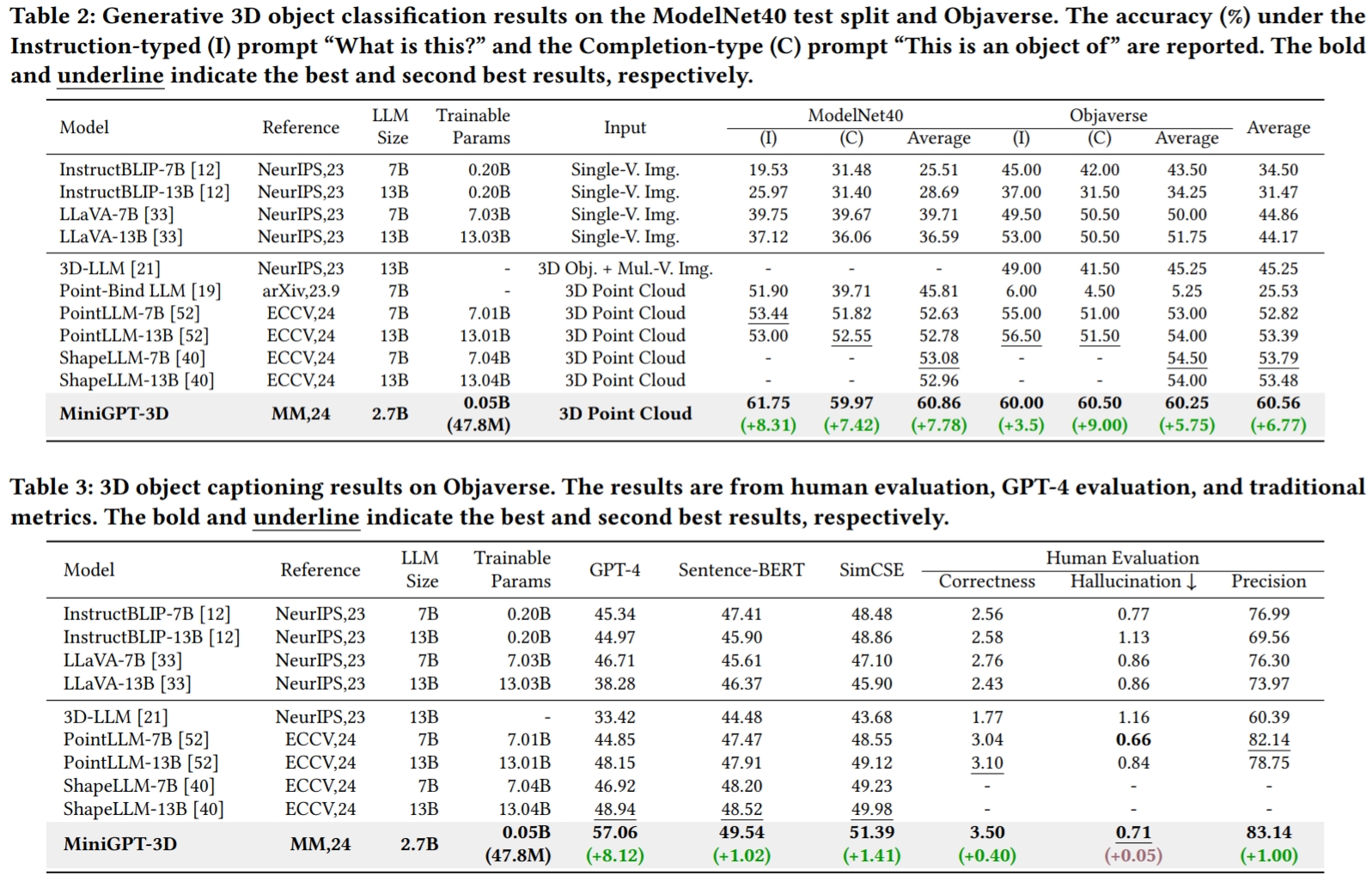
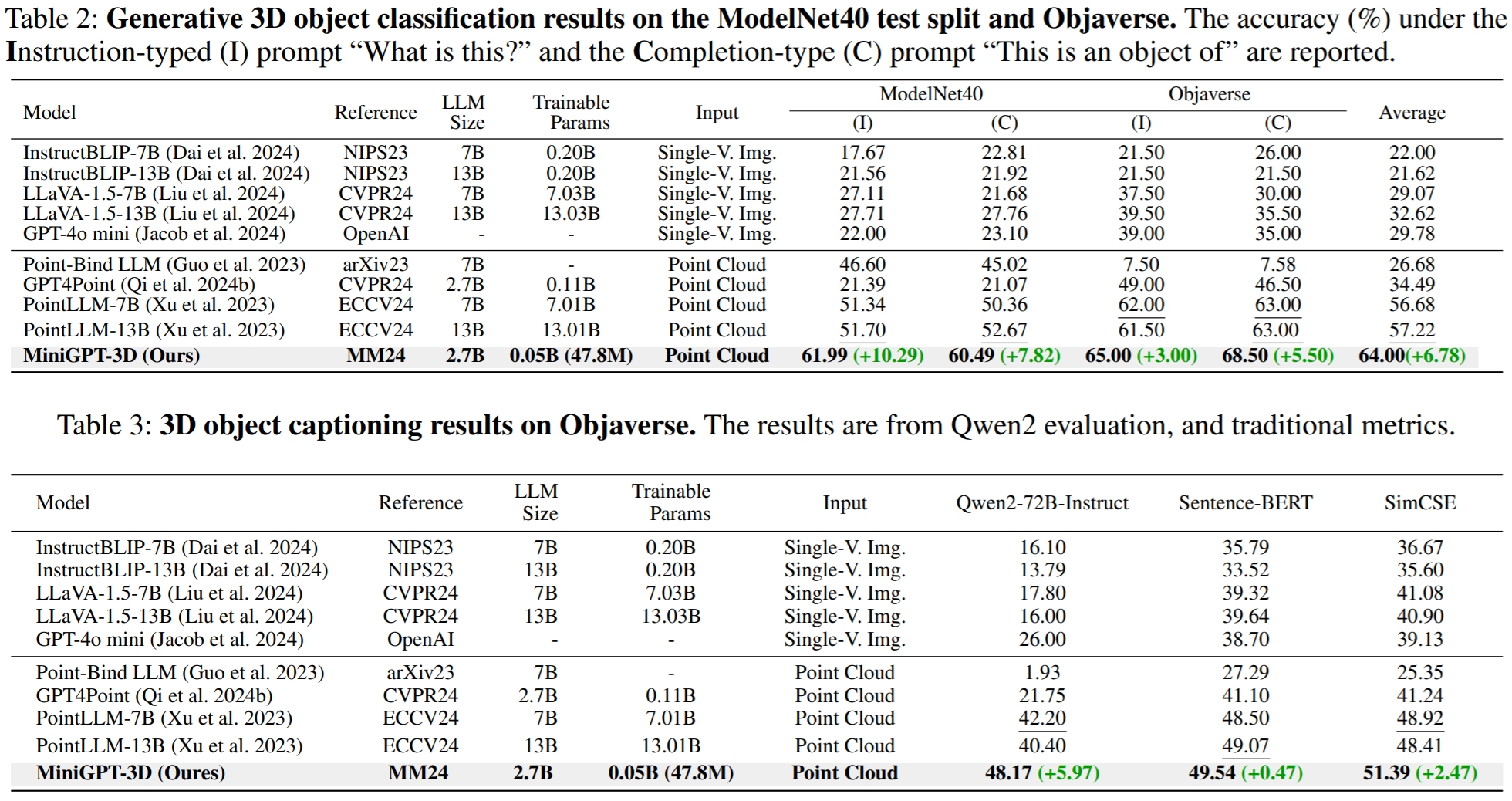
Los resultados se refieren a GreenPLM.

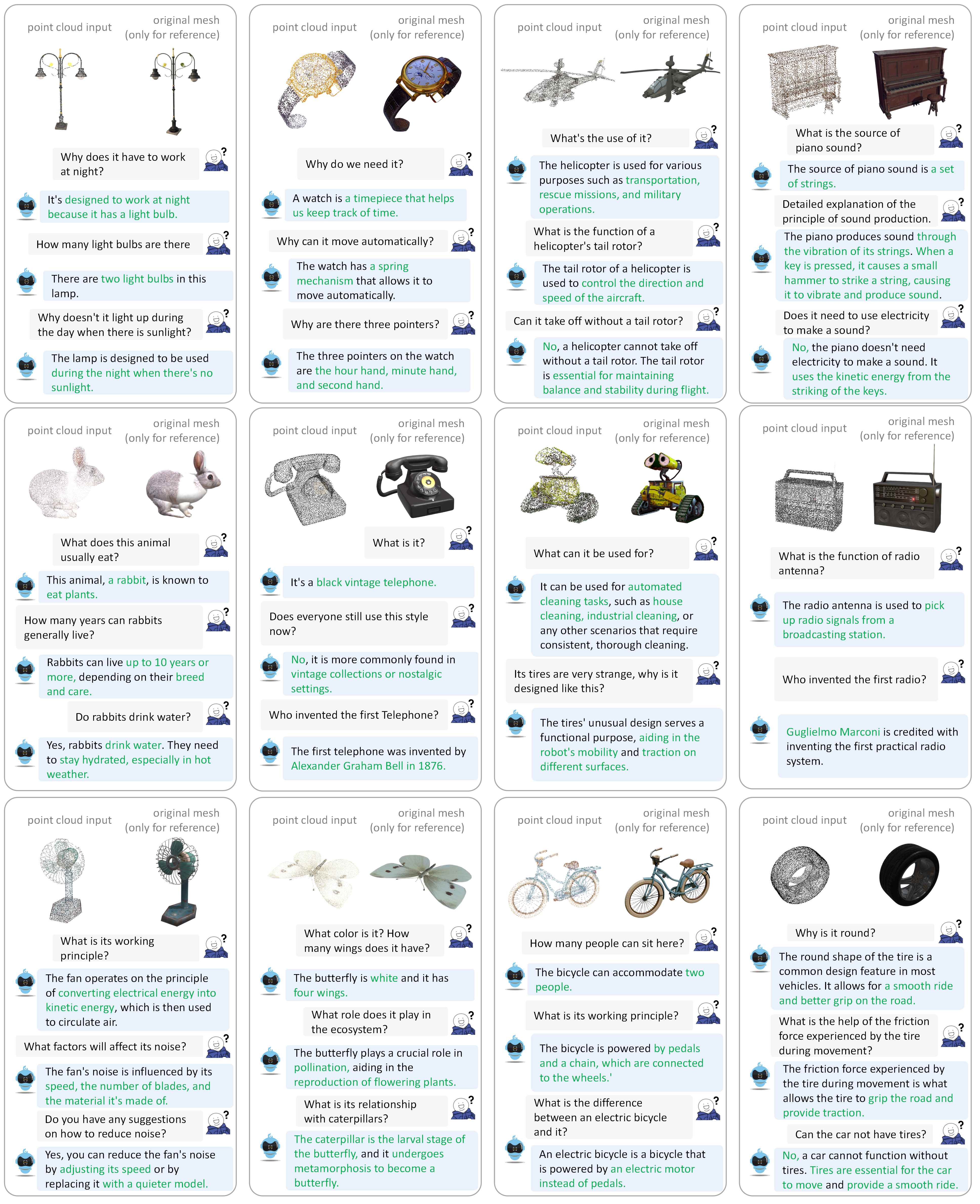
Consulte nuestro documento para obtener más ejemplos de diálogo.
Probamos nuestros códigos en el siguiente entorno:
Para empezar:
Clona este repositorio.
git clone https://github.com/TangYuan96/MiniGPT-3D.git
cd MiniGPT-3DInstalar paquetes
De forma predeterminada, ha instalado conda.
conda env create -f environment.yml
conda activate minigpt_3d
bash env_install.sh8192_npy que contiene archivos de nube de puntos de 660K llamados {Objaverse_ID}_8192.npy . Cada archivo es una matriz numerosa con dimensiones (8192, 6), donde las primeras tres dimensiones son xyz y las últimas tres dimensiones son rgb en el rango [0, 1]. cat Objaverse_660K_8192_npy_split_a * > Objaverse_660K_8192_npy.tar.gz
tar -xvf Objaverse_660K_8192_npy.tar.gz8192_npy a la carpeta ./data/objaverse_data ../data/anno_data .modelnet40_test_8192pts_fps.dat a la carpeta ./data/modelnet40_data .Finalmente, la estructura general del directorio de datos debería ser:
MiniGPT-3D/data
|-- anno_data
| |-- PointLLM_brief_description_660K.json
| |-- PointLLM_brief_description_660K_filtered.json
| |-- PointLLM_brief_description_val_200_GT.json
| |-- PointLLM_complex_instruction_70K.json
| |-- object_ids_660K.txt
| `-- val_object_ids_3000.txt
|-- modelnet40_data
| |-- modelnet40_test_8192pts_fps.dat
|-- objaverse_data
| |-- 00000054c36d44a2a483bdbff31d8edf_8192.npy
| |-- 00001ec0d78549e1b8c2083a06105c29_8192.npy
| .......
Clasificamos los pesos del modelo requeridos por MiniGPT-3D durante el entrenamiento y la inferencia.
params_weight a la carpeta del proyecto MiniGPT-3D .Finalmente, la estructura general del directorio de datos debería ser:
MiniGPT-3D
|-- params_weight
| |-- MiniGPT_3D_stage_3 # Our MiniGPT-3D stage III weight, needed to verify the results of paper
| |-- MiniGPT_3D_stage_4 # Our MiniGPT-3D stage IV weight, Needed to verify the results of paper
| |-- Phi_2 # LLM weight
| |-- TinyGPT_V_stage_3 # 2D-LLM weights including loRA & Norm of LLM and projector
| |-- all-mpnet-base-v2 # Used in the caption traditional evaluation
| |-- bert-base-uncased # Used in initialize Q-former
| |-- pc_encoder # point cloud encoder
| `-- sup-simcse-roberta-large # Used in the caption traditional evaluation
|-- train_configs
| `-- MiniGPT_3D
| .......
Puede ejecutar el siguiente comando para iniciar una demostración de conversación de gradio local:
python UI_demo.py --cfg-path ./eval_configs/MiniGPT_3D_conv_UI_demo.yaml --gpu-id 0 Luego, copie el enlace http://127.0.0.1:7860/ en su navegador, puede ingresar la identificación del objeto Objaverse compatible (660 000 objetos) o cargar un archivo de objeto (.ply o .npy) para hablar con nuestro MiniGPT-3D. .
Ejemplo: Introduzca el ID del objeto: 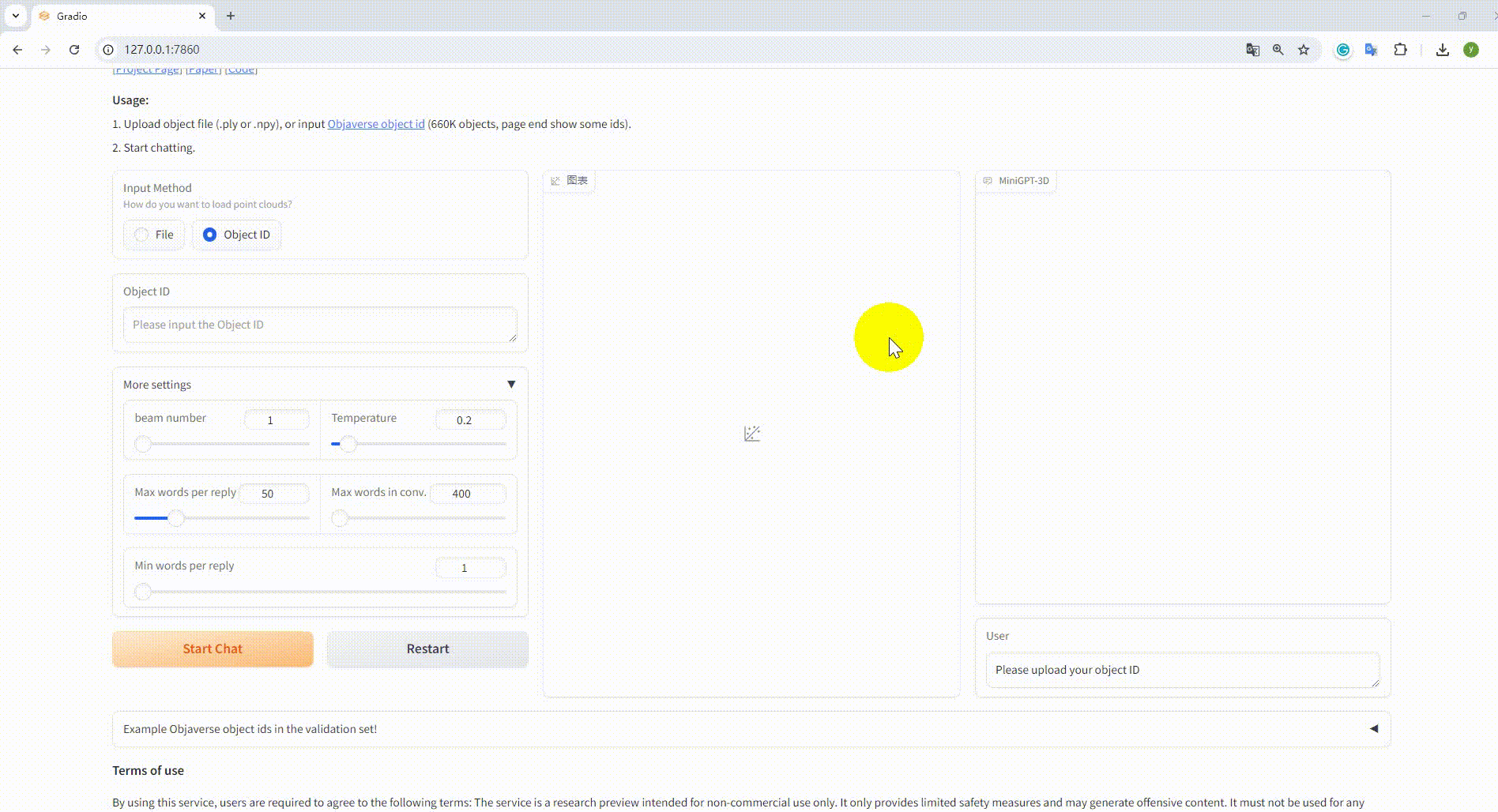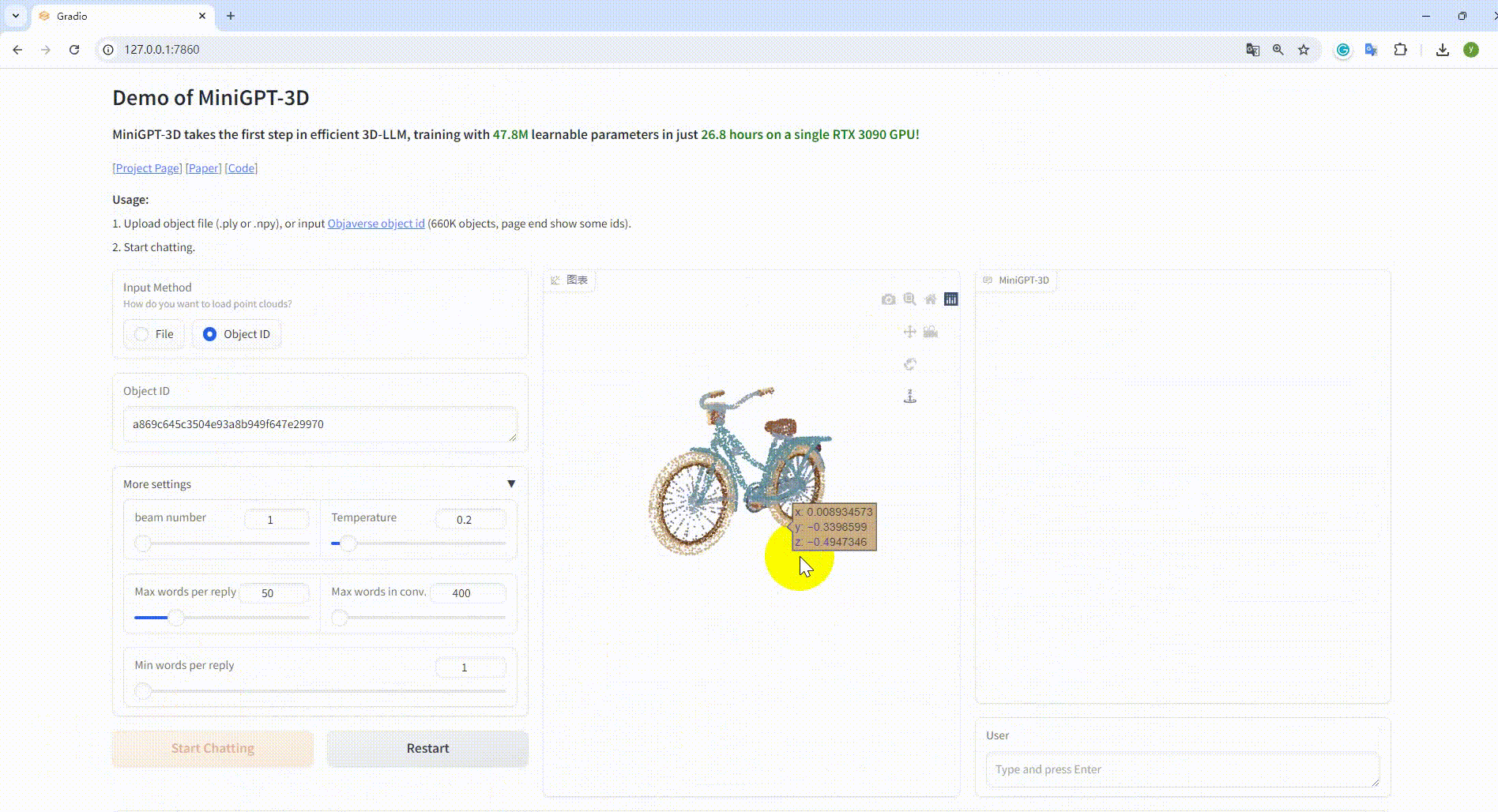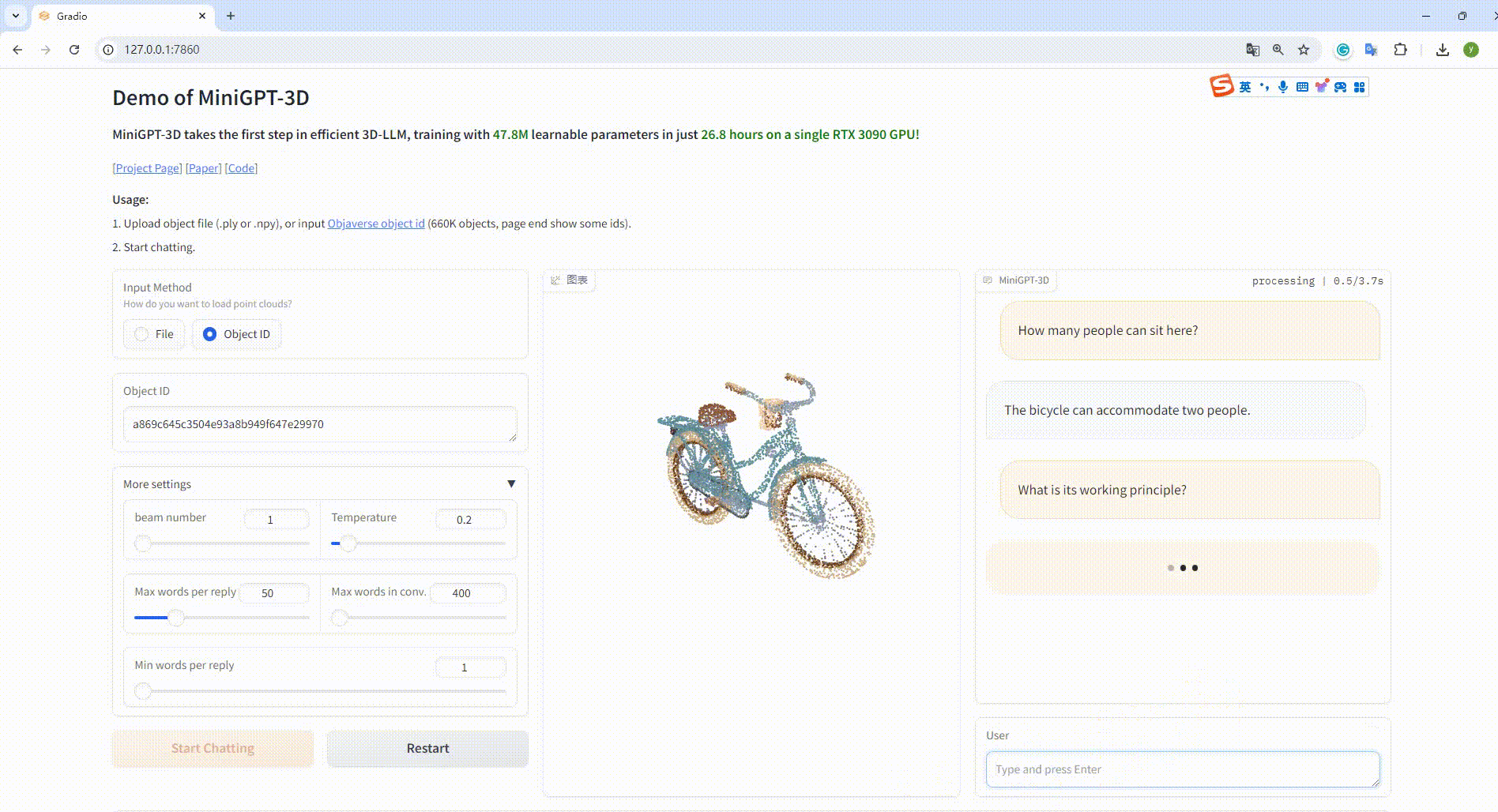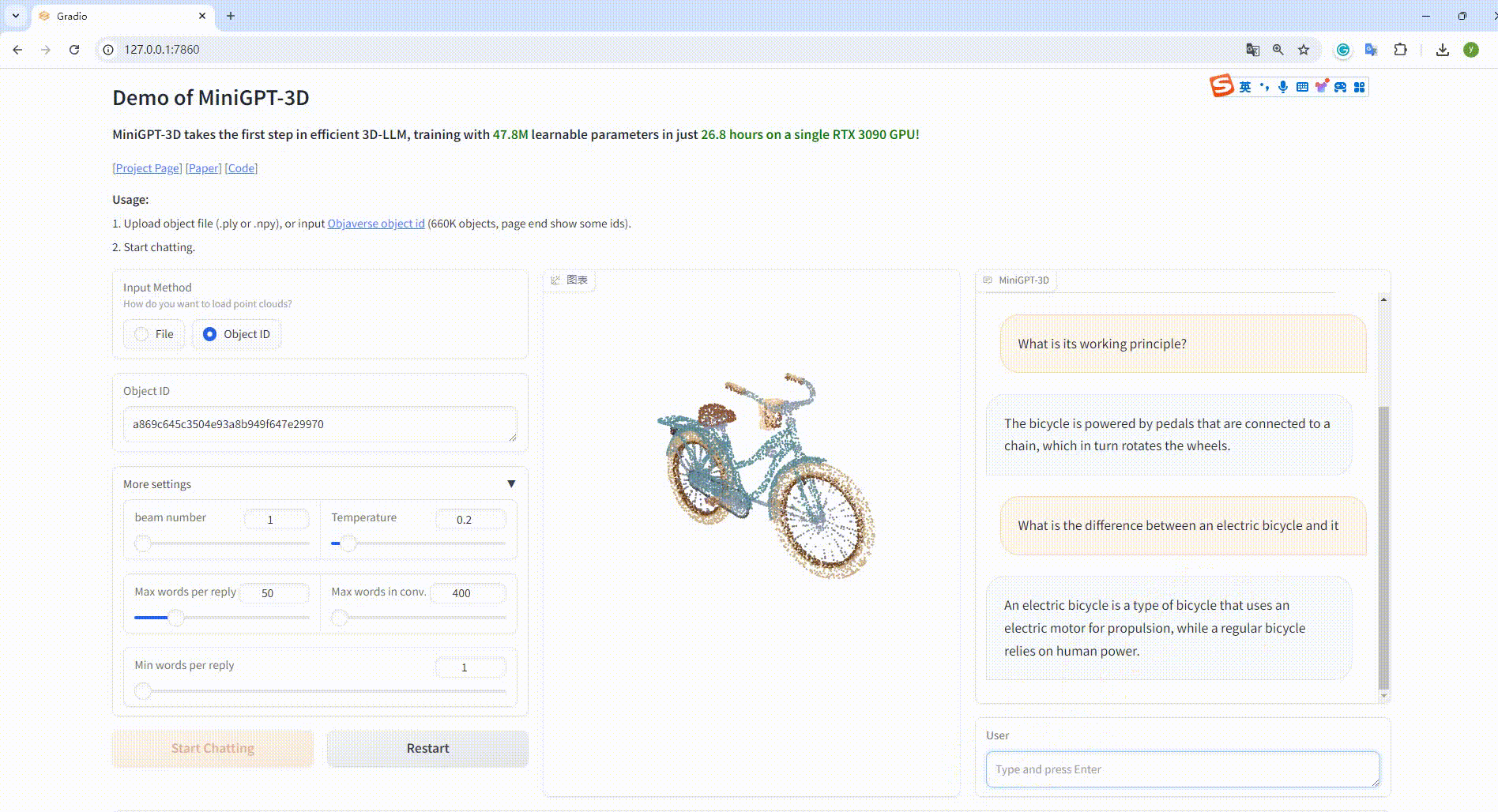
Ejemplo: cargar el archivo objeto: 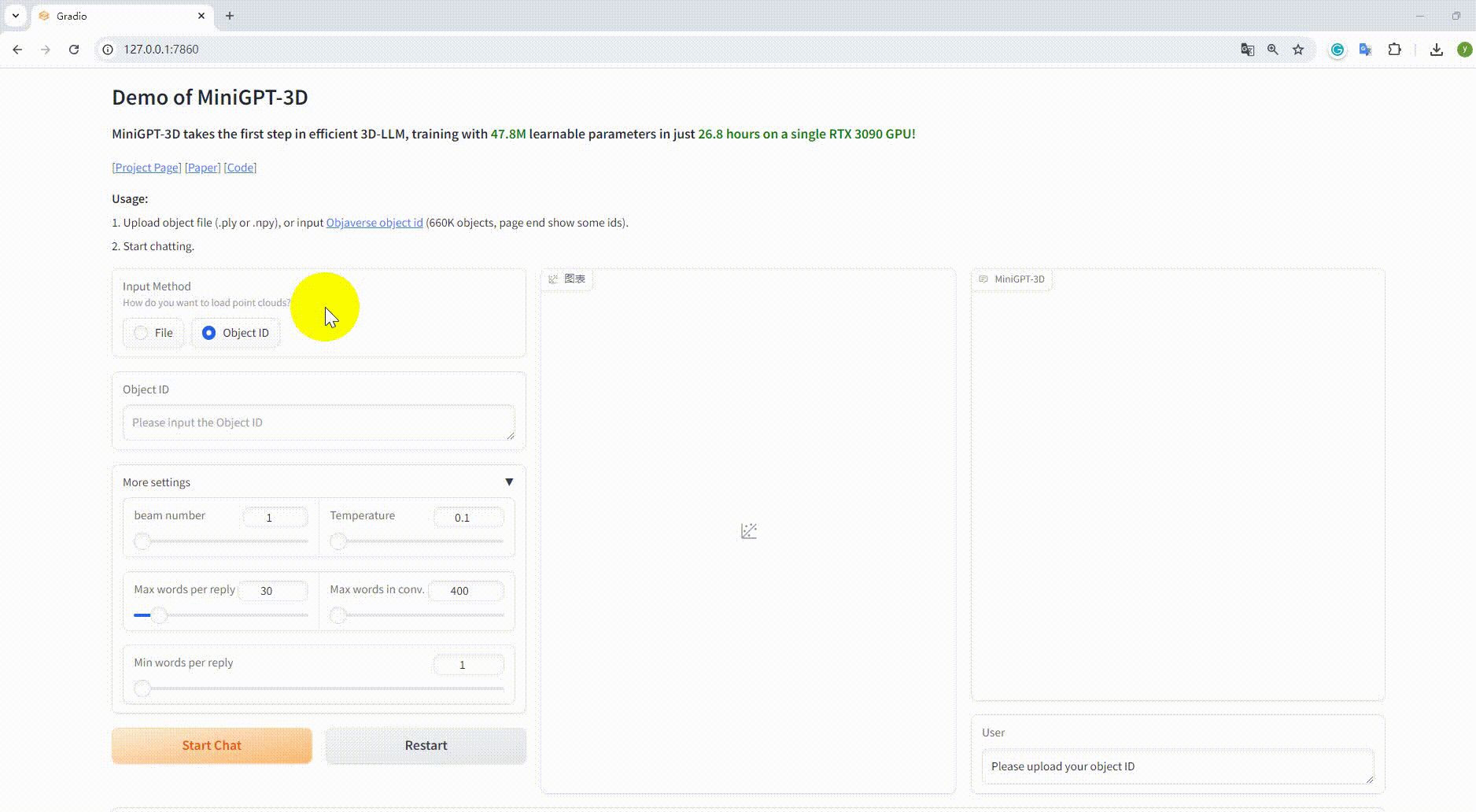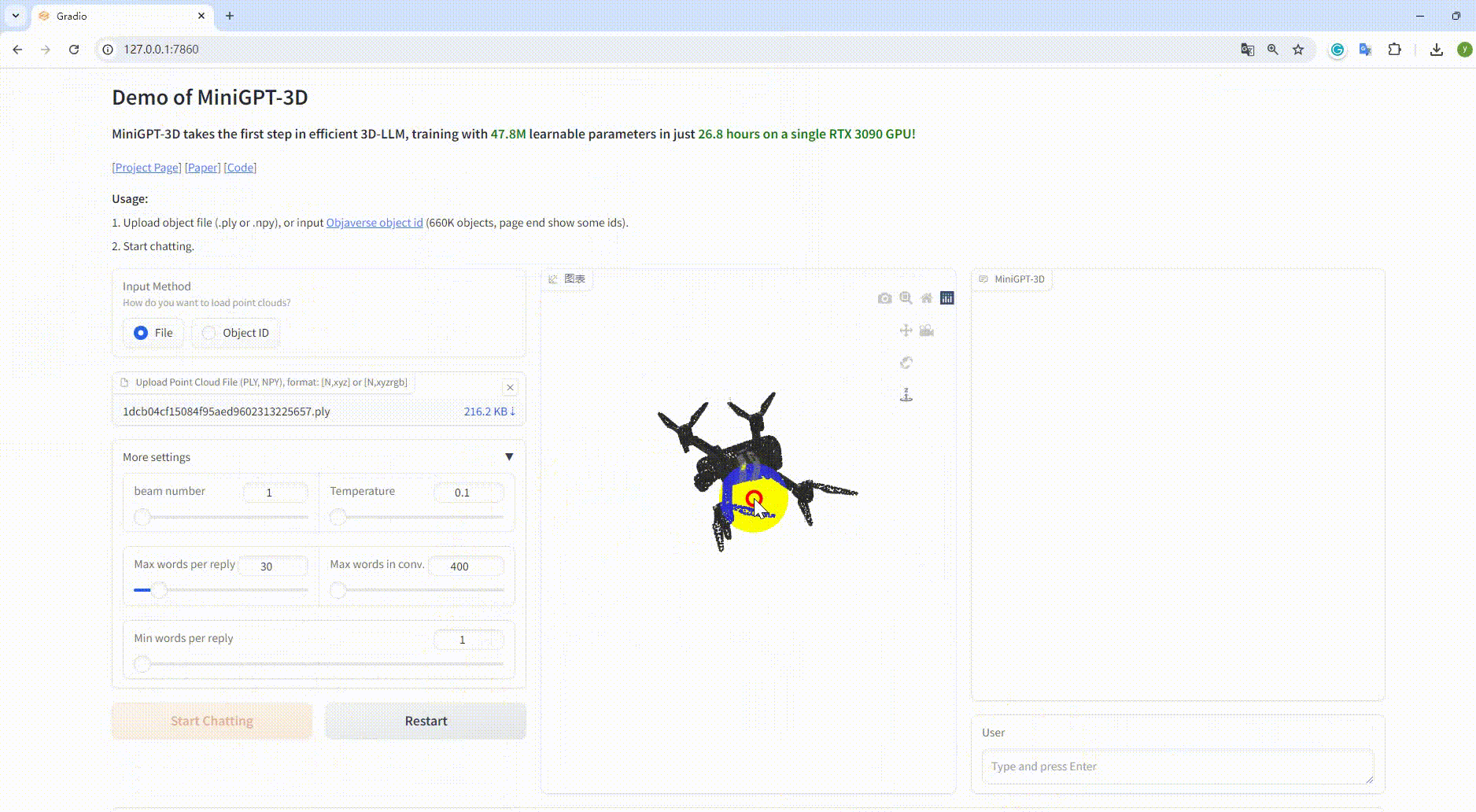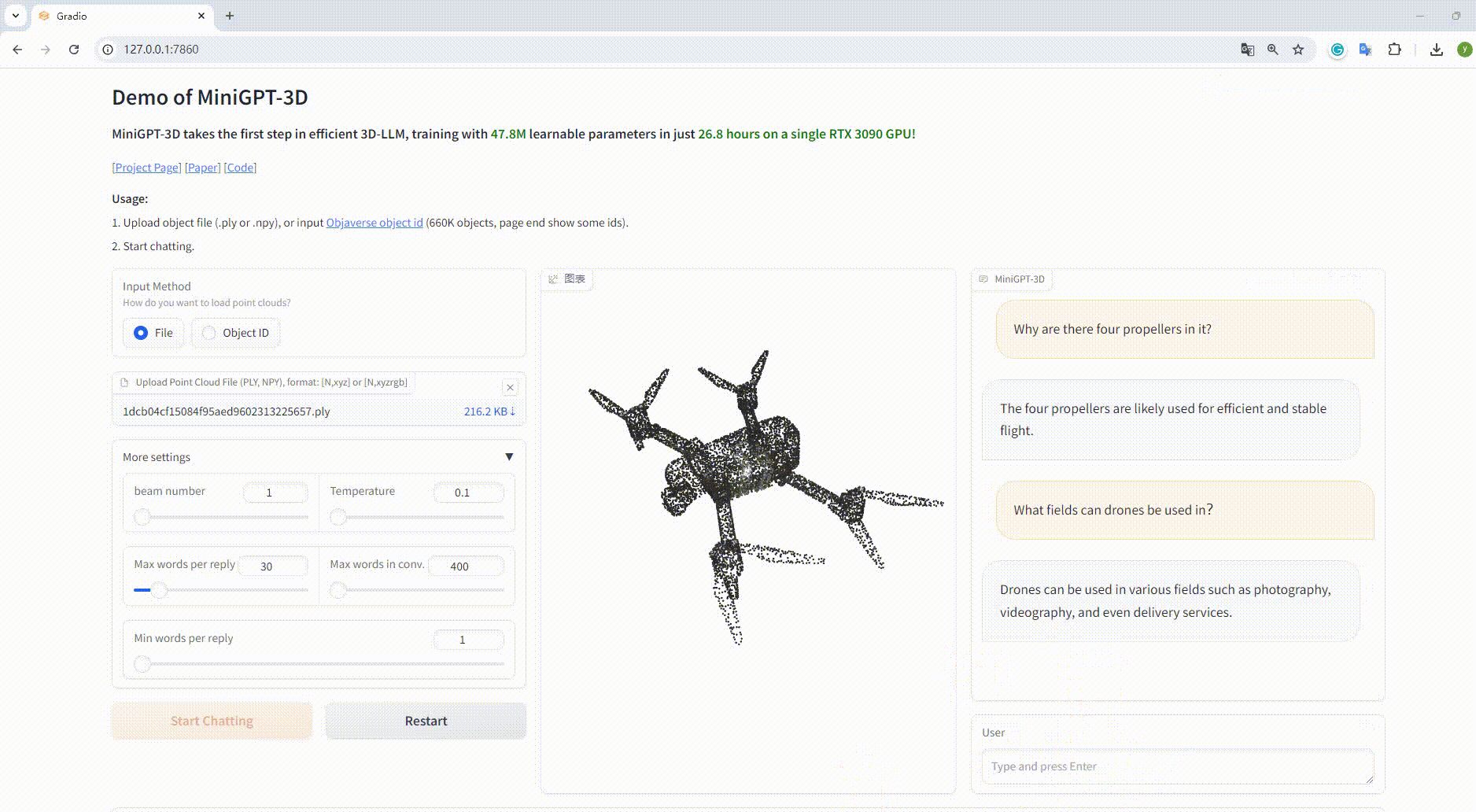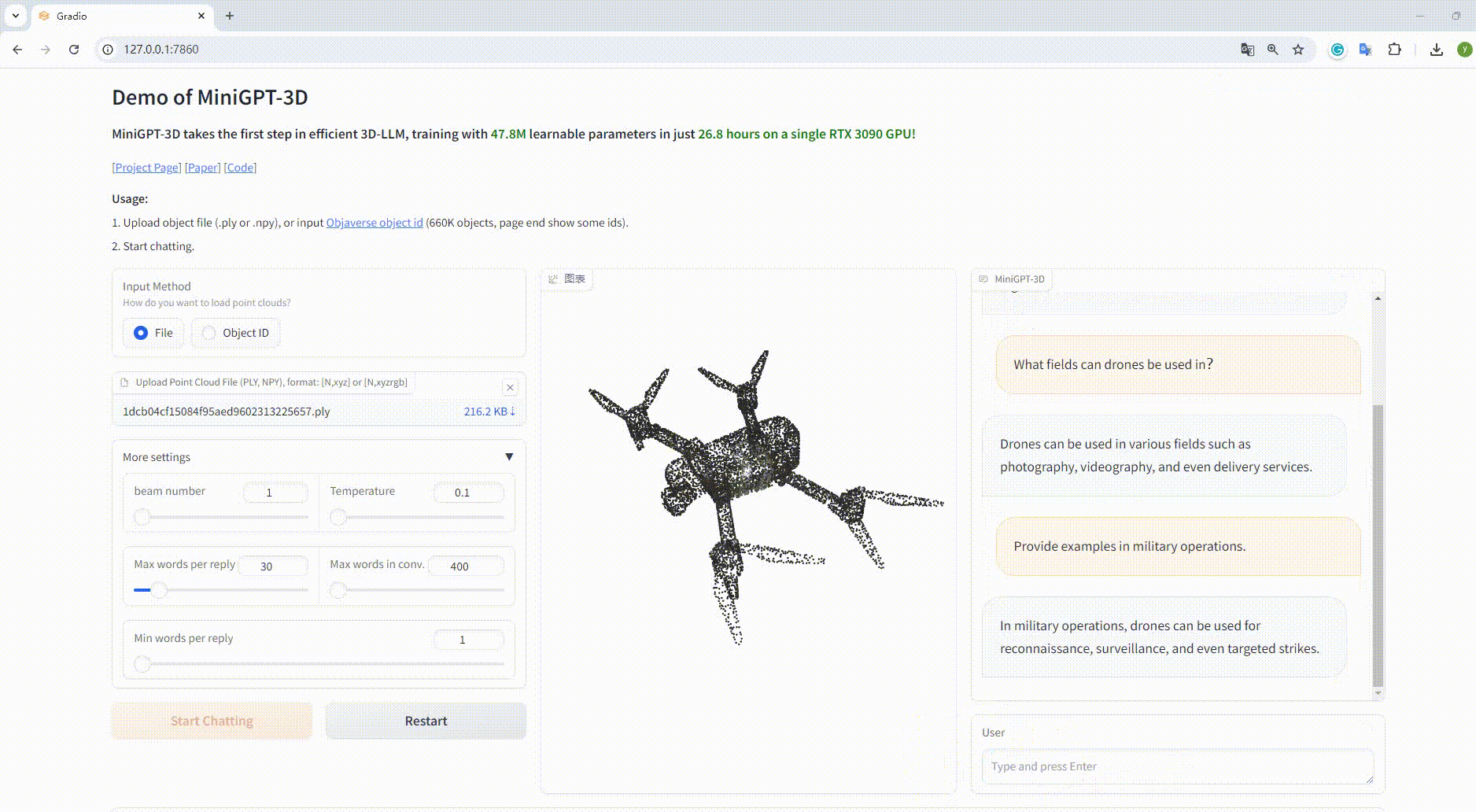
Si desea utilizar la ruta de salida predeterminada de cada etapa, puede ignorar los siguientes pasos.
CUDA_VISIBLE_DEVICES=0 python train.py --cfg-path ./train_configs/MiniGPT_3D/stage_1.yaml
CUDA_VISIBLE_DEVICES=0 python train.py --cfg-path ./train_configs/MiniGPT_3D/stage_2.yaml
CUDA_VISIBLE_DEVICES=0 python train.py --cfg-path ./train_configs/MiniGPT_3D/stage_3.yaml
CUDA_VISIBLE_DEVICES=0 python train.py --cfg-path ./train_configs/MiniGPT_3D/stage_4.yaml
Si solo desea verificar los resultados de nuestro artículo, puede ignorar los siguientes pasos:
Establezca su ruta de salida de la Etapa III aquí en la Línea 8.
Establezca la ruta de salida de la Etapa IV aquí en la Línea 9.
Generar el resultado de la clasificación de vocabulario abierto en objaverse
# Prompt 0:
export PYTHONPATH= $PWD
CUDA_VISIBLE_DEVICES=0 python pointllm/eval/eval_objaverse.py --out_path ./output/test --task_type classification --cfg-path ./eval_configs/benchmark_evaluation_paper.yaml --prompt_index 0 # Prompt 1:
export PYTHONPATH= $PWD
CUDA_VISIBLE_DEVICES=0 python pointllm/eval/eval_objaverse.py --out_path ./output/test --task_type classification --cfg-path ./eval_configs/benchmark_evaluation_paper.yaml --prompt_index 1Generar el resultado de la clasificación de disparo cero cercano en ModelNet40
# Prompt 0:
export PYTHONPATH= $PWD
CUDA_VISIBLE_DEVICES=0 python pointllm/eval/eval_modelnet_cls.py --out_path ./output/test --cfg-path ./eval_configs/benchmark_evaluation_paper.yaml --prompt_index 0 # Prompt 1:
export PYTHONPATH= $PWD
CUDA_VISIBLE_DEVICES=0 python pointllm/eval/eval_modelnet_cls.py --out_path ./output/test --cfg-path ./eval_configs/benchmark_evaluation_paper.yaml --prompt_index 1Generar el resultado de los subtítulos de objetos en objaverse
export PYTHONPATH= $PWD
CUDA_VISIBLE_DEVICES=0 python pointllm/eval/eval_objaverse.py --out_path ./output/test --task_type captioning --cfg-path ./eval_configs/benchmark_evaluation_paper.yaml --prompt_index 2En GreenPLM, hemos notado que los LLM de código cercano GPT-3.5 y GPT-4 tienen dos inconvenientes principales: versiones de API inconsistentes y altos costos de evaluación (~35 CNY o 5 USD por una evaluación) . Por ejemplo, el modelo GPT-3.5-turbo-0613 utilizado en PointLLM y nuestro MiniGPT-3D ya no se mantiene, lo que dificulta replicar los resultados .
export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
python pointllm/eval/evaluator.py --results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_classification_prompt0.json --model_type gpt-4-0613 --eval_type open-free-form-classification --parallel --num_workers 15 export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
python pointllm/eval/evaluator.py --results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_classification_prompt1.json --model_type gpt-4-0613 --eval_type open-free-form-classification --parallel --num_workers 15 export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
python pointllm/eval/evaluator.py --results_path /path/to/evaluation/ModelNet_classification_prompt0.json --model_type gpt-3.5-turbo-0613 --eval_type modelnet-close-set-classification --parallel --num_workers 15 export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
python pointllm/eval/evaluator.py --results_path /path/to/evaluation/ModelNet_classification_prompt1.json --model_type gpt-3.5-turbo-0613 --eval_type modelnet-close-set-classification --parallel --num_workers 15 export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
python pointllm/eval/evaluator.py --results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_captioning_prompt2.json --model_type gpt-4-0613 --eval_type object-captioning --parallel --num_workers 15En GreenPLM, proponemos nuevos puntos de referencia de subtítulos y clasificación de objetos 3D utilizando Qwen2-72B-Instruct de código abierto de nivel GPT-4 para hacer que las evaluaciones sean rentables y los resultados sean consistentemente reproducibles .
export PYTHONPATH= $PWD
export DASHSCOPE_API_KEY=sk-xxx
python ./pointllm/eval/evaluator_opensource_llm_QwenAPI.py
--results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_classification_prompt0.json
--eval_type open-free-form-classification
--model_type qwen2-72b-instruct
--parallel --num_workers 4 export PYTHONPATH= $PWD
export DASHSCOPE_API_KEY=sk-xxx
python ./pointllm/eval/evaluator_opensource_llm_QwenAPI.py
--results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_classification_prompt1.json
--eval_type open-free-form-classification
--model_type qwen2-72b-instruct
--parallel --num_workers 4 export PYTHONPATH= $PWD
export DASHSCOPE_API_KEY=sk-xxx
python ./pointllm/eval/evaluator_opensource_llm_QwenAPI.py
--results_path /path/to/evaluation/ModelNet_classification_prompt0.json
--eval_type modelnet-close-set-classification
--model_type qwen2-72b-instruct
--parallel --num_workers 4 export PYTHONPATH= $PWD
export DASHSCOPE_API_KEY=sk-xxx
python ./pointllm/eval/evaluator_opensource_llm_QwenAPI.py
--results_path /path/to/evaluation/ModelNet_classification_prompt1.json
--eval_type modelnet-close-set-classification
--model_type qwen2-72b-instruct
--parallel --num_workers 4 export PYTHONPATH= $PWD
export DASHSCOPE_API_KEY=sk-xxx
python ./pointllm/eval/evaluator_opensource_llm_QwenAPI.py
--results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_captioning_prompt2.json
--eval_type object-captioning
--model_type qwen2-72b-instruct
--parallel --num_workers 4Para la tarea de subtitulado de objetos, ejecute el siguiente comando para evaluar los resultados del modelo con las métricas tradicionales Sentence-BERT y SimCSE.
CUDA_VISIBLE_DEVICES=0 python pointllm/eval/traditional_evaluator.py --results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_captioning_prompt2.jsonEstablezca su ruta de salida de la Etapa III aquí en la Línea 8.
Establezca su ruta de salida de la Etapa IV aquí en la Línea 9.
Puede ejecutar el siguiente comando para iniciar una demostración de conversación de gradio local:
python UI_demo.py --cfg-path ./eval_configs/MiniGPT_3D_conv_UI_demo.yaml --gpu-id 0Si encuentra útil nuestro trabajo, considere citar:
@article { tang2024minigpt ,
title = { MiniGPT-3D: Efficiently Aligning 3D Point Clouds with Large Language Models using 2D Priors } ,
author = { Tang, Yuan and Han, Xu and Li, Xianzhi and Yu, Qiao and Hao, Yixue and Hu, Long and Chen, Min } ,
journal = { arXiv preprint arXiv:2405.01413 } ,
year = { 2024 }
}
Este trabajo se encuentra bajo la Licencia Internacional Creative Commons Atribución-No Comercial-CompartirIgual 4.0.
¡Juntos, hagamos que el LLM para 3D sea grandioso!
Nos gustaría agradecer a los autores de PointLLM, TinyGPT-V, MiniGPT-4 y Octavius por sus excelentes trabajos y repositorios.


