gutenberg dialog
1.0.0
Código para descargar y crear su propia versión del conjunto de datos de diálogo de Gutenberg. Fácilmente ampliable con nuevos idiomas. Pruebe chatbots capacitados en varios idiomas aquí: https://ricsinaruto.github.io/chatbot.html.
| Enlace de descarga | Número de declaraciones | Longitud promedio del enunciado | Número de diálogos | Duración media del diálogo |
|---|---|---|---|---|
| Inglés | 14 773 741 | 22.17 | 2 526 877 | 5.85 |
| Alemán | 226 015 | 24.44 | 43 440 | 5.20 |
| Holandés | 129 471 | 24.26 | 23 541 | 5.50 |
| Español | 58 174 | 18.62 | 6 912 | 8.42 |
| italiano | 41 388 | 19.47 | 6 664 | 6.21 |
| húngaro | 18 816 | 14,68 | 2 826 | 6.66 |
| portugués | 16 228 | 21.40 | 2 233 | 7.27 |
? Genere su propio conjunto de datos ajustando los parámetros que afectan el equilibrio entre tamaño y calidad del conjunto de datos.
La interfaz modular facilita la ampliación del conjunto de datos a otros idiomas.
? Puede excluir libros fácilmente de forma manual al crear el conjunto de datos.
Ejecute setup.py que instala los paquetes necesarios.
python setup.py
El archivo principal debe llamarse desde la raíz del repositorio. El siguiente comando ejecuta la canalización de creación del conjunto de datos para los idiomas separados por comas proporcionados como argumento. Actualmente se admiten inglés, alemán, holandés, español, portugués, italiano y húngaro.
python code/main.py -l=en,de,nl,es,pt,it,hu -a
Todos los argumentos configurables se pueden ver a continuación: 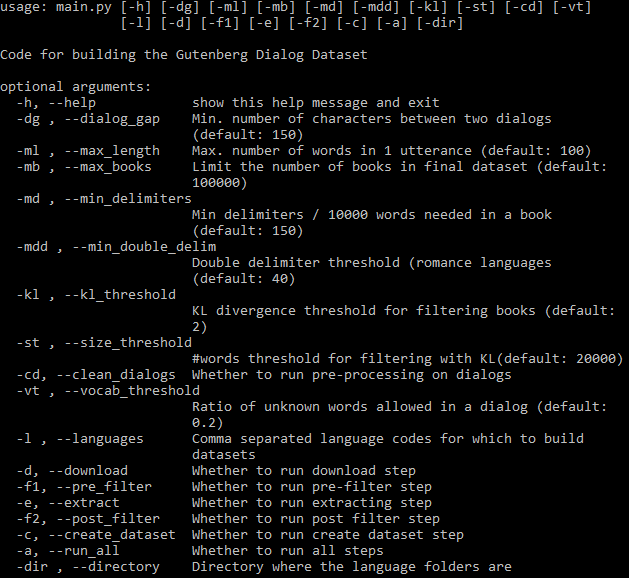
El indicador -a controla si se debe ejecutar todo el proceso automáticamente. Si se omite -a , se debe especificar un subconjunto de pasos mediante indicadores (consulte la ayuda más arriba). Una vez que se completa un paso, su salida se puede usar en pasos posteriores y solo se ejecuta nuevamente si se cambian los parámetros o el código relacionado con ese paso. Todos los pasos se ejecutan por separado para cada idioma.
Descargue libros para idiomas determinados.
Nota: si todos los libros no se pueden descargar con el error "No se pudo descargar el libro", una causa probable es que el espejo predeterminado utilizado por el paquete gutenberg se haya vuelto inaccesible. En caso de que esto ocurra, es posible utilizar cualquiera de los espejos alternativos enumerados en https://www.gutenberg.org/MIRRORS.ALL a través de la variable de entorno GUTENBERG_MIRROR . Por ejemplo:
export GUTENBERG_MIRROR="https://gutenberg.pglaf.org"
python code/main.py ...
El filtrado previo elimina algunos libros viejos y ruido.
Los diálogos se extraen de libros. Al ampliar el conjunto de datos a nuevos idiomas (consulte la sección a continuación), este es el paso que se puede modificar, por lo que los pasos anteriores se pueden omitir una vez finalizados.
Un segundo paso de filtrado que elimina algunos diálogos basados en vocabulario.
Reunir el conjunto de datos final y dividirlo en datos de entrenamiento/desarrollo/prueba. El último paso crea el archivo Author_and_title.txt en el directorio de salida que contiene todos los libros (más títulos y autores) utilizados para extraer el conjunto de datos final. Los usuarios pueden copiar manualmente líneas de este archivo a banned_books.txt correspondientes a libros que no deberían permitirse en el conjunto de datos. En ejecuciones posteriores de cualquier paso, los libros de este archivo no se tendrán en cuenta.
El código se puede ampliar fácilmente para procesar otros idiomas. Se debe crear un archivo llamado <código de idioma>.py en la carpeta de idiomas. Aquí se debe definir una clase con el nombre del código de idioma en mayúsculas (por ejemplo, En para inglés), con LANG o cualquiera de las otras subclases como padre. Con self.cfg se puede acceder a los parámetros de configuración. Dentro de esta clase se deben definir las 3 funciones siguientes. Consulte it.py para ver un ejemplo.
Estadísticas de idiomas
Esta función debería devolver un diccionario donde las claves sean delimitadores potenciales. Para cada delimitador se debe definir una función (valores en el diccionario), que toma como entrada una línea y devuelve un número. Este número puede ser, por ejemplo, el recuento de delimitadores, un indicador de si hay un delimitador en la línea, etc. Normalmente se recomienda un recuento ponderado, dependiendo de la importancia de los diferentes delimitadores. Los valores se utilizarán para determinar el delimitador que se debe utilizar en el libro respectivo (pasado a la función siguiente) y para filtrar libros que contienen una cantidad baja de delimitadores. en.py contiene ejemplos de delimitadores múltiples.
Esta función debería extraer los diálogos de un libro y agregarlos a self.dialogs , que es una lista de diálogos, y cada diálogo es una lista de expresiones consecutivas. lista_párrafos contiene el libro como una lista de párrafos consecutivos. delimitador es el delimitador más común en este archivo que debe usarse para extraer cuadros de diálogo.
Esta función se utiliza para el posprocesamiento de cuadros de diálogo (por ejemplo, eliminar ciertos caracteres). Toma como entrada un enunciado. Tenga en cuenta que la tokenización de palabras nltk se ejecuta automáticamente.
Este proyecto tiene la licencia MIT; consulte el archivo de LICENCIA para obtener más detalles.
Incluya un enlace a este repositorio si utiliza alguno de los conjuntos de datos o códigos en su trabajo y considere citar el siguiente documento:
@inproceedings{Csaky:2021,
title = "The Gutenberg Dialogue Dataset",
author = "Cs{'a}ky, Rich{'a}rd and Recski, G{'a}bor",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics",
month = apr,
year = "2021",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2004.12752",
}


