Multi Modality Arena
1.0.0
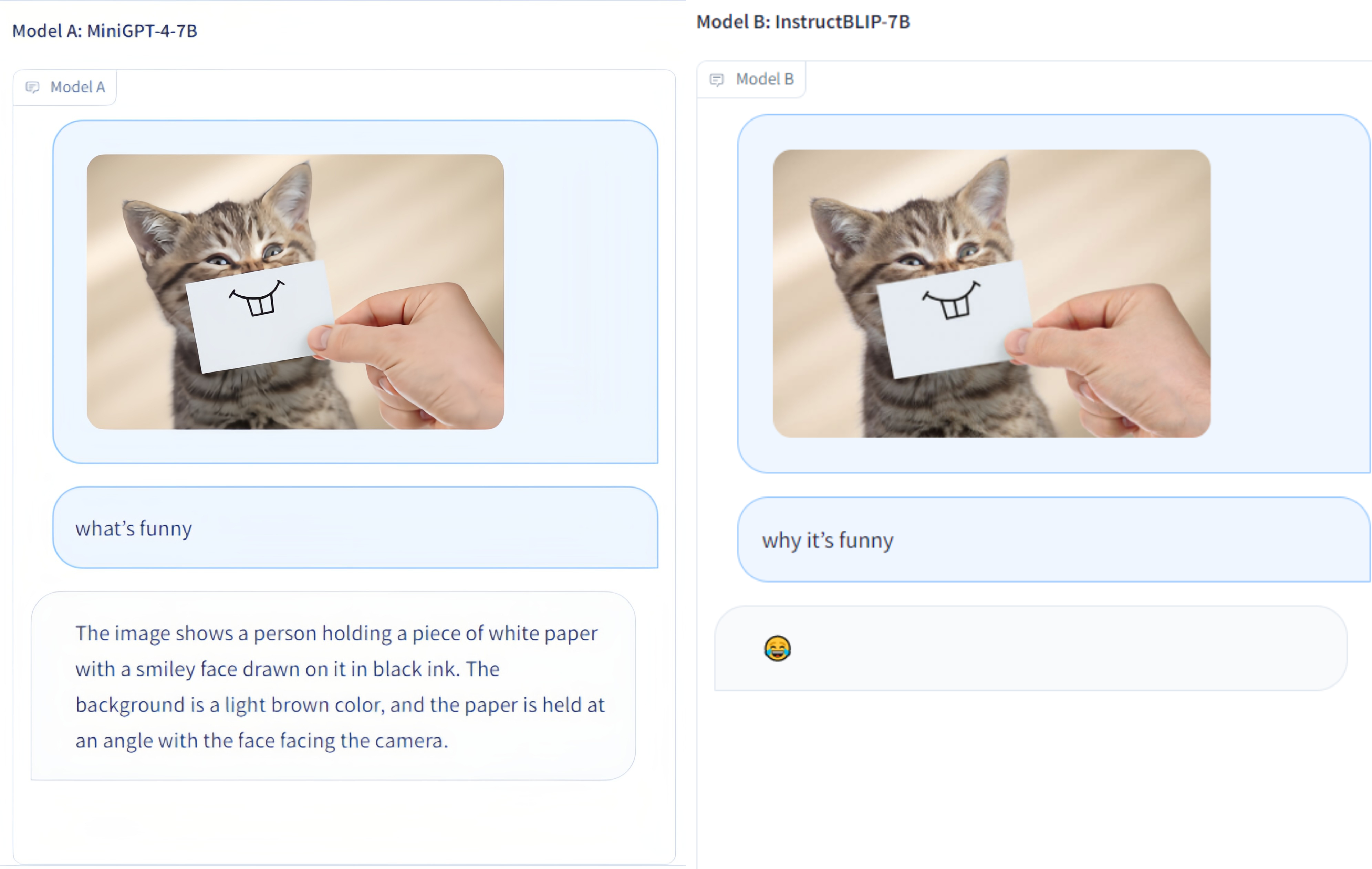
Multi-Modality Arena es una plataforma de evaluación para grandes modelos multimodales. Después de Fastchat, dos modelos anónimos se comparan uno al lado del otro en una tarea visual de respuesta a preguntas. Lanzamos la Demo y damos la bienvenida a la participación de todos en esta iniciativa de evaluación.
Conjunto de datos OmniMedVQA: contiene 118.010 imágenes con 127.995 elementos de control de calidad, que cubren 12 modalidades diferentes y hacen referencia a más de 20 regiones anatómicas humanas. El conjunto de datos se puede descargar desde aquí.
12 modelos: 8 LVLM de dominio general y 4 LVLM médicos especializados.
Pequeños conjuntos de datos: solo 50 muestras seleccionadas al azar para cada conjunto de datos, es decir, 42 puntos de referencia visuales relacionados con el texto y 2,1 mil muestras en total para facilitar su uso.
Más modelos: otros 4 modelos, es decir, 12 modelos en total, incluido Google Bard .
Evaluación de conjunto ChatGPT : mejor concordancia con la evaluación humana que el enfoque anterior de coincidencia de palabras.
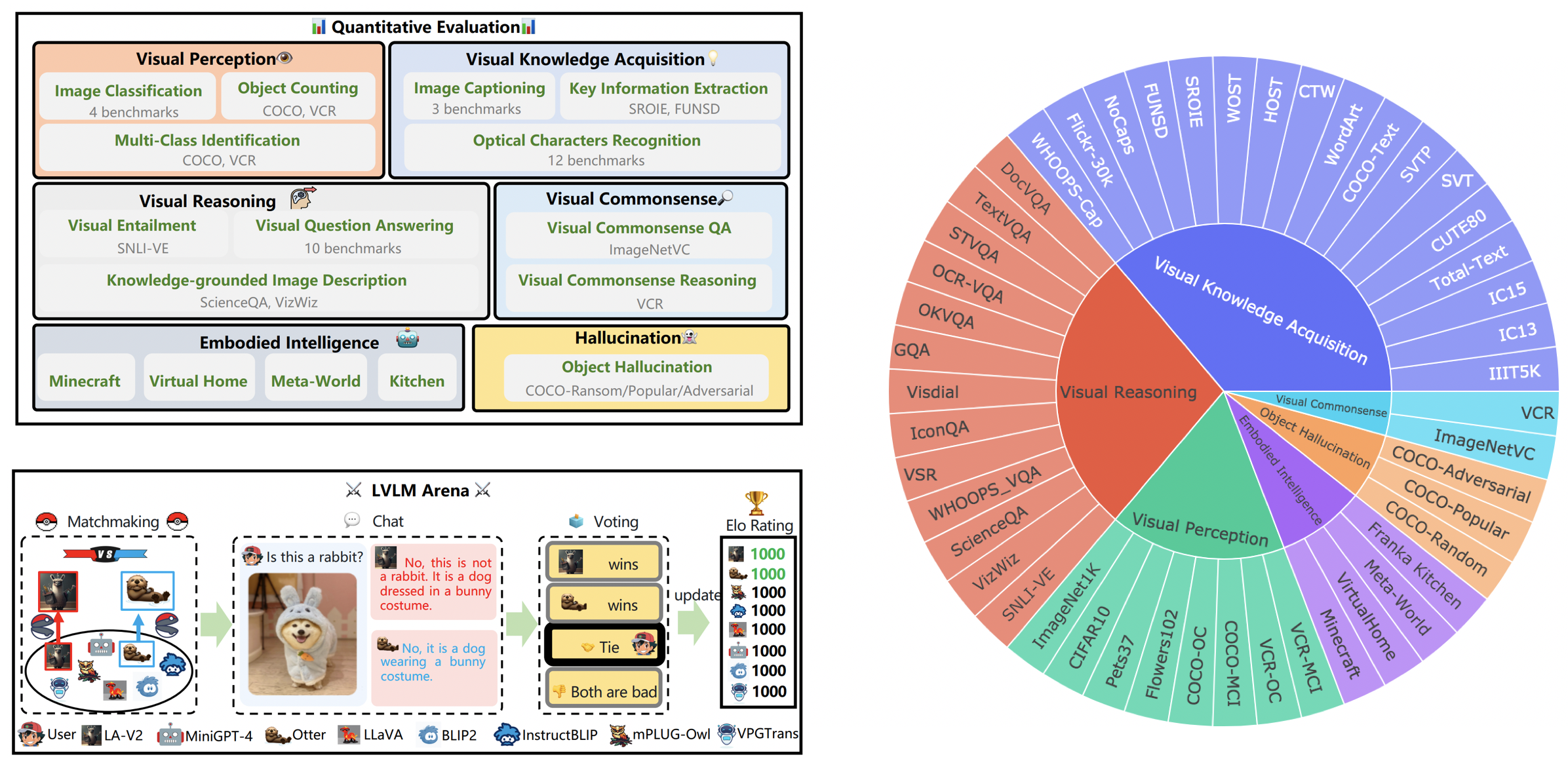
LVLM-eHub es un punto de referencia de evaluación integral para grandes modelos multimodales (LVLM) disponibles públicamente. Se evalúa ampliamente
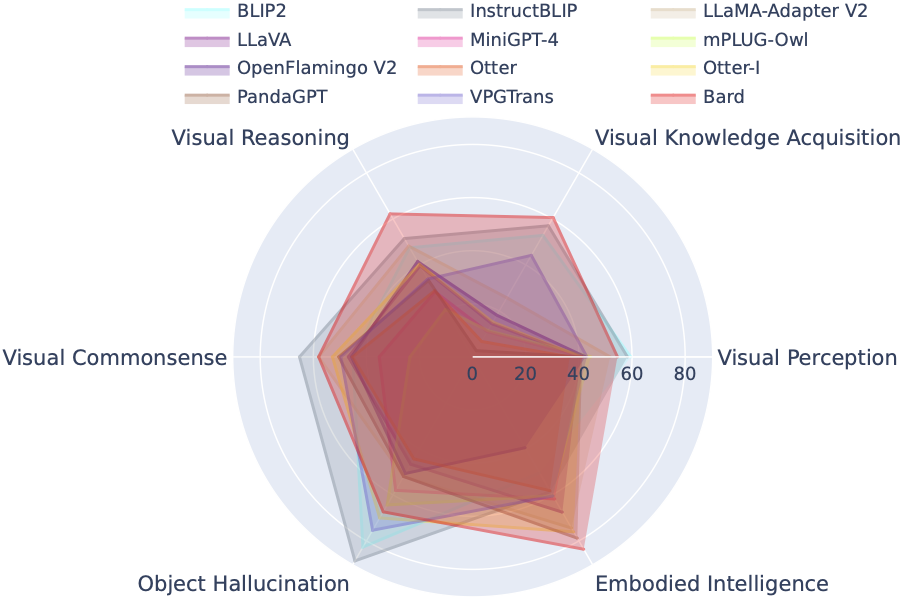
La tabla de clasificación LVLM clasifica sistemáticamente los conjuntos de datos presentados en la evaluación Tiny LVLM de acuerdo con sus habilidades específicas, incluidas la percepción visual, el razonamiento visual, el sentido común visual, la adquisición de conocimiento visual y la alucinación de objetos. Esta tabla de clasificación incluye modelos lanzados recientemente para reforzar su amplitud.
Puede descargar el punto de referencia desde aquí y puede encontrar más detalles aquí.
| Rango | Modelo | Versión | Puntaje |
|---|---|---|---|
| 1 | PasanteVL | InternVL-Chat | 327,61 |
| 2 | PasanteLM-XComposer-VL | PasanteLM-XComposer-VL-7B | 322.51 |
| 3 | Bardo | Bardo | 319.59 |
| 4 | Qwen-VL-Chat | Qwen-VL-Chat | 316,81 |
| 5 | LLaVA-1.5 | Vicuña-7B | 307.17 |
| 6 | InstruirBLIP | Vicuña-7B | 300.64 |
| 7 | PasanteLM-XCompositor | PasanteLM-XComposer-7B | 288,89 |
| 8 | BLIP2 | FlanT5xl | 284,72 |
| 9 | BLIVA | Vicuña-7B | 284.17 |
| 10 | Lince | Vicuña-7B | 279,24 |
| 11 | Guepardo | Vicuña-7B | 258,91 |
| 12 | LLaMA-Adaptador-v2 | llama-7b | 229.16 |
| 13 | VPGTrans | Vicuña-7B | 218.91 |
| 14 | Imagen de nutria | Nutria-9B-LA-InContext | 216,43 |
| 15 | VisualGLM-6B | VisualGLM-6B | 211,98 |
| 16 | mPLUG-búho | llama-7b | 209.40 |
| 17 | LLaVA | Vicuña-7B | 200.93 |
| 18 | MiniGPT-4 | Vicuña-7B | 192,62 |
| 19 | Nutria | Nutria-9B | 180,87 |
| 20 | OFv2_4BI | RedPajama-INCITE-Instruct-3B-v1 | 176,37 |
| 21 | PandaGPT | Vicuña-7B | 174,25 |
| 22 | LaVIN | llama-7b | 97,51 |
| 23 | micrófono | FlanT5xl | 94.09 |
31 de marzo de 2024. Lanzamos OmniMedVQA, un punto de referencia de evaluación integral a gran escala para LVLM médicos. Mientras tanto, tenemos 8 LVLM de dominio general y 4 LVLM de especialidad médica. Para obtener más detalles, visite MedicalEval.
16 de octubre de 2023. Presentamos una división del conjunto de datos a nivel de capacidad derivada del LVLM-eHub, complementada con la inclusión de ocho modelos lanzados recientemente. Para acceder a las divisiones del conjunto de datos, el código de evaluación, los resultados de inferencia del modelo y las tablas de rendimiento completas, visite tiny_lvlm_evaluación ✅.
8 de agosto de 2023. Lanzamos [Tiny LVLM-eHub] . Los códigos fuente de evaluación y los resultados de inferencia de modelos son de código abierto en tiny_lvlm_evaluación.
15 de junio de 2023. Lanzamos [LVLM-eHub] , un punto de referencia de evaluación para modelos de visión y lenguaje de gran tamaño. El código llegará pronto.
8 de junio de 2023. Gracias, Dr. Zhang, autor de VPGTrans, por sus correcciones. Los autores de VPGTrans provienen principalmente de NUS y la Universidad de Tsinghua. Anteriormente tuvimos algunos problemas menores al volver a implementar VPGTrans, pero descubrimos que su rendimiento en realidad es mejor. Para obtener más autores de modelos, comuníquese conmigo para discutirlo en el correo electrónico. Además, siga nuestra lista de clasificación de modelos, donde estarán disponibles resultados más precisos.
Puede. 22 de diciembre de 2023. Gracias, Dr. Ye, autor de mPLUG-Owl, por sus correcciones. Solucionamos algunos problemas menores en nuestra implementación de mPLIG-Owl.
Los siguientes modelos participan actualmente en batallas aleatorias,
KAUST/MiniGPT-4
Salesforce/BLIP2
Salesforce/InstructBLIP
Academia DAMO/mPLUG-Owl
NTU/nutria
Universidad de Wisconsin-Madison/LLaVA
Laboratorio de IA de Shanghai/llama_adapter_v2
NUS/VPGTrans
Puede encontrar más detalles sobre estos modelos en ./model_detail/.model.jpg . Intentaremos programar recursos informáticos para albergar más modelos multimodales en el campo.
Si está interesado en alguna parte de nuestra plataforma VLarena, no dude en unirse al grupo de Wechat.

Crear entorno conda
conda crear -n arena python = 3.10 conda activar arena
Instalar los paquetes necesarios para ejecutar el controlador y el servidor
pip instalar numpy gradio uvicorn fastapi
Luego, para cada modelo, es posible que requieran versiones conflictivas de paquetes de Python; recomendamos crear un entorno específico para cada modelo basado en su repositorio de GitHub.
Para servir utilizando la interfaz de usuario web, necesita tres componentes principales: servidores web que interactúan con los usuarios, trabajadores modelo que alojan dos o más modelos y un controlador para coordinar el servidor web y los trabajadores modelo.
Estos son los comandos a seguir en tu terminal:
controlador python.py
Este controlador gestiona los trabajadores distribuidos.
python model_worker.py --model-name SELECTED_MODEL --device TARGET_DEVICE
Espere hasta que el proceso termine de cargar el modelo y vea "Uvicorn ejecutándose en ...". El trabajador modelo se registrará ante el controlador. Para cada trabajador modelo, debe especificar el modelo y el dispositivo que desea utilizar.
python server_demo.py
Esta es la interfaz de usuario con la que los usuarios interactuarán.
Si sigue estos pasos, podrá ofrecer sus modelos mediante la interfaz de usuario web. Puedes abrir tu navegador y chatear con un modelo ahora. Si los modelos no aparecen, intente reiniciar el servidor web de gradio.
Valoramos profundamente todas las contribuciones destinadas a mejorar la calidad de nuestras evaluaciones. Esta sección comprende dos segmentos clave: Contributions to LVLM Evaluation y Contributions to LVLM Arena .
Puede acceder a la versión más reciente de nuestro código de evaluación en la carpeta LVLM_evaluación. Este directorio abarca un conjunto completo de códigos de evaluación, acompañado de los conjuntos de datos necesarios. Si está entusiasmado por participar en el proceso de evaluación, no dude en compartir los resultados de su evaluación o la API de inferencia del modelo con nosotros por correo electrónico a [email protected].
¡Le extendemos nuestro agradecimiento por su interés en integrar su modelo en nuestro LVLM Arena! Si desea incorporar su modelo a nuestra Arena, por favor prepare un probador de modelos estructurado de la siguiente manera:
clase ModelTester:def __init__(self, dispositivo=None) -> Ninguno:# TODO: inicialización del modelo y preprocesadores requeridosdef move_to_device(self, dispositivo) -> Ninguno:# TODO: esta función se usa para transferir el modelo entre CPU y GPU (opcional)def generar(self, imagen, pregunta) -> str: # TODO: código de inferencia del modelo
Además, estamos abiertos a enlaces de inferencia de modelos en línea, como los proporcionados por plataformas como Gradio. Se agradecen de todo corazón sus contribuciones.
Expresamos nuestra gratitud al estimado equipo de ChatBot Arena y su artículo Judging LLM-as-a-juez por su influyente trabajo, que sirvió de inspiración para nuestros esfuerzos de evaluación de LVLM. También nos gustaría extender nuestro más sincero agradecimiento a los proveedores de LVLM, cuyas valiosas contribuciones han contribuido significativamente al progreso y avance de los grandes modelos de visión y lenguaje. Finalmente, agradecemos a los proveedores de conjuntos de datos utilizados en nuestro LVLM-eHub.
El proyecto es una herramienta de investigación experimental únicamente con fines no comerciales. Tiene salvaguardias limitadas y puede generar contenido inapropiado. No puede usarse para nada ilegal, dañino, violento, racista o sexual.


