Sound Content Music Recommendation System
1.0.0

Si eres como yo, te encanta la música. Me encanta la música y me encanta encontrar nueva música. Spotify es uno de los principales servicios de transmisión de música en Internet y ya incluye herramientas increíbles que te ayudan a descubrir nueva música según lo que escuchas. Lo hace a través de una combinación de diferentes algoritmos, incluido el filtrado colaborativo donde se rastrea el uso similar entre usuarios y se utiliza para generar recomendaciones o recomendaciones basadas en contenido que recomiendan nuevas canciones basadas en información similar entre la información vinculada a una canción. ¿Como una canción? En Spotify, puedes escuchar la 'radio' de esa canción, que recopilará un grupo de canciones similares a esa canción de alguna manera o una combinación de formas. ¿Qué pasa si te gusta una canción, pero no te importa ninguna información más que el sonido que contiene? A veces, eso es todo lo que quiero escuchar.
Creé este proyecto para crear un sistema de recomendación de música basado únicamente en la información del sonido de la música. Ayudará al usuario a encontrar música nueva a través de canciones que suenan similares. Para ello, también explorará las similitudes entre toda la música e intentará capturar matemáticamente el timbre, el ritmo y el estilo de una canción.
El sonido siempre está a nuestro alrededor. A lo largo de nuestra vida, llegamos a discernir diferentes sonidos de los demás. La música no es diferente: hay muchos tipos de música y la música suele ser una combinación de muchos tipos diferentes de sonidos y ritmos que también podemos distinguir de los demás. ¿Pero podemos cuantificar esa información por nosotros mismos? A veces, la música se clasifica en géneros, lo que significa que un género es un grupo de músicos con cualidades similares de estilo, forma, ritmo, timbre, instrumentos o cultura. Pero no todos los artistas musicales crean sonido en el mismo género y no todos los géneros contienen el mismo tipo de música. Entonces, ¿qué es el sonido y cómo discernimos los diferentes tipos de sonido?
El sonido es una vibración de ondas acústicas que percibimos a través de nuestros oídos cuando esas ondas hacen vibrar nuestros tímpanos. Una onda de sonido es una señal y la velocidad a la que esa señal vibra se conoce como frecuencia. Si la frecuencia de un sonido es más alta, percibimos que ese sonido tiene un tono más alto. En la música, instrumentos como el bajo o el bombo crearán sonidos que vibran a una frecuencia más baja, mientras que los tonos altos tienen una frecuencia más alta. Suena como si el choque de un platillo o un sombrero alto fuera una combinación de muchas ondas en diferentes frecuencias y están representadas por una onda "ruidosa", de apariencia casi aleatoria.
¿Cómo se ve el sonido? Una forma de visualizar el sonido es trazar una señal a lo largo del tiempo:
A medida que acortamos la ventana de tiempo en cada subtrama, podemos ver la señal del audio mucho más cerca. Observe que en la imagen más ampliada de la señal la onda es una colección de diferentes frecuencias. Puede haber una señal de baja frecuencia que se combina con señales de alta frecuencia más pequeñas.
Entonces podemos visualizar una señal a lo largo del tiempo, pero ya podemos decir que es difícil entender mucho sobre esa onda de sonido con solo mirar esta visualización. ¿Qué tipos de frecuencias están presentes en esa ventana de 0,01 segundos? Para responder a eso, usaremos una transformada de Fourier para calcular un espectrograma.
La transformada de Fourier es un método para calcular la amplitud de las frecuencias presentes en una sección de una señal de audio. Como puedes ver en el gráfico anterior, las ondas pueden ser complejas y cada variación en la señal representa una frecuencia diferente (la velocidad de vibración). Básicamente, una transformada de Fourier extraerá las frecuencias para cada sección de tiempo y producirá una matriz bidimensional de amplitudes de frecuencia en función del tiempo. El producto de una transformada de Fourier es un espectrograma. A partir del espectrograma, convertimos las frecuencias producidas a la escala mel para crear un espectrograma mel. El espectrograma mel representa mejor la distancia percibida entre frecuencias tal como las escuchamos.
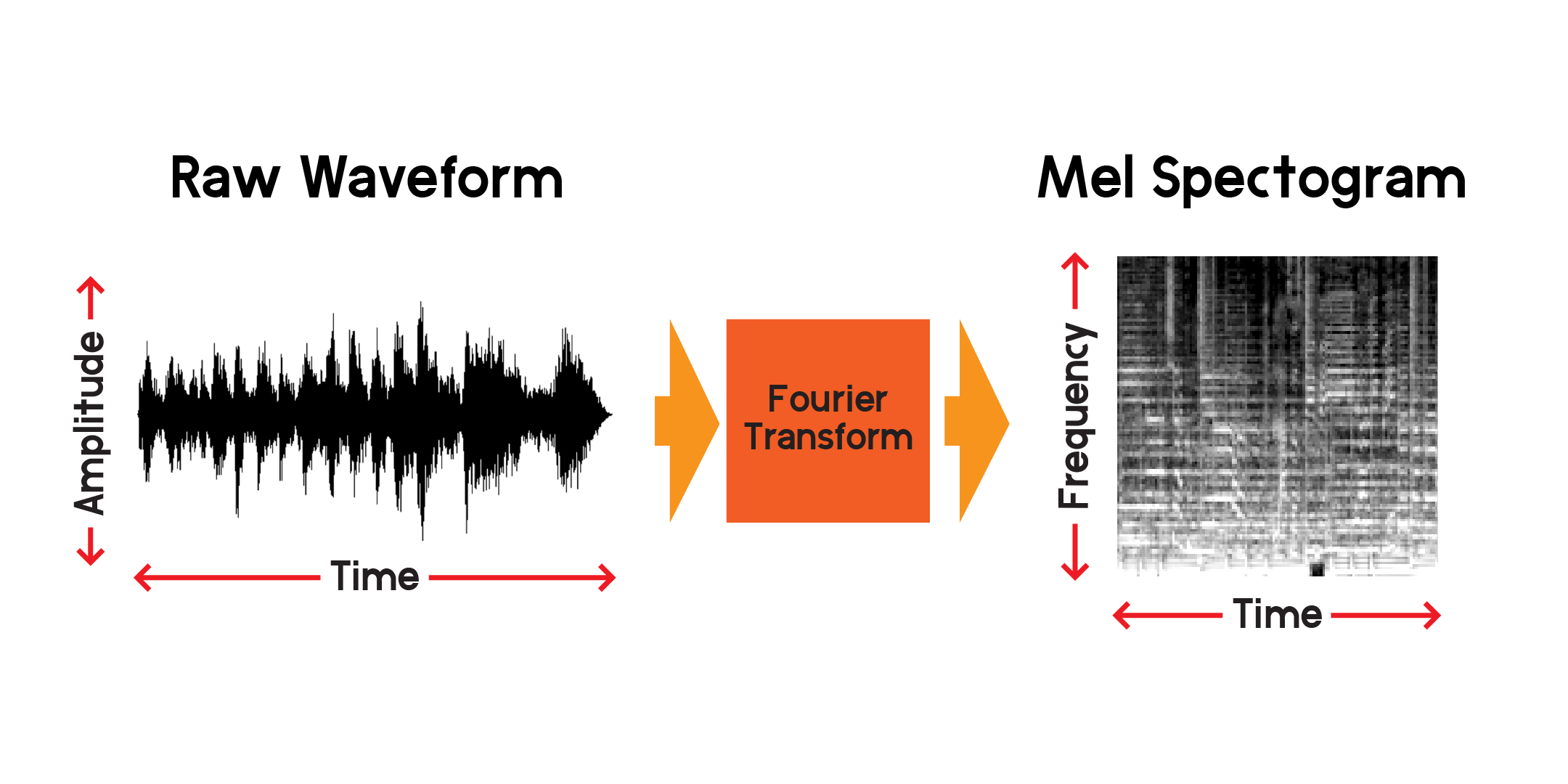
Trazamos un ejemplo de un espectrograma mel a partir de la misma muestra de audio que trazamos arriba:
Usando la API pública de Spotify, extraje información de la canción en un cuaderno anterior. Desde allí puedo descargar una vista previa en mp3 de 30 segundos de cada canción y convertirla en un espectrograma mel para usarlo en una red neuronal que entrena con imágenes. Primero, echemos un vistazo al marco de datos que usaremos para recopilar las vistas previas de mp3.
En otro cuaderno, tomé enlaces de vista previa de la API de Spotify, descargué los mp3 y convertí los archivos de sonido en una imagen compuesta que contiene el espectrograma mel, el coeficiente cepstral de frecuencia Mel y el cromagrama. Creé esta imagen compuesta con la intención de poder usar estas otras transformaciones, pero para este proyecto, solo entrenaré la red neuronal en los espectrogramas mel.
Para hacer recomendaciones de canciones similares basadas únicamente en el contenido de sonido, necesitaré crear funciones que de alguna manera expliquen el contenido de las canciones. Además, para hacer esto rápidamente, necesitaré comprimir la información de cada canción en un conjunto de números más pequeño que la entrada de los espectrogramas mel.
Para cada archivo de vista previa de canción, hay más de 600.000 muestras. En cada espectrograma mel, hay 512 x 128 píxeles con un total de 65.536 píxeles. Incluso una imagen de 128x128 contiene 16.384 píxeles. Este modelo de codificador automático comprimirá el contenido de una canción en sólo 256 números. Una vez que el codificador automático esté lo suficientemente entrenado, la red podrá reconstruir una canción a partir de ese vector de longitud 256 con una pérdida mínima.
Un autocodificador es un tipo de red neuronal que se compone de un codificador y un decodificador . Primero, el codificador comprimirá la información de la entrada en una cantidad mucho menor de datos y el decodificador reconstruirá los datos para que estén lo más cerca posible de la salida original.
Un codificador automático también es un tipo especial de red neuronal en el sentido de que no está supervisado, aunque no del todo sin supervisión. Es autosupervisado porque utiliza sus entradas para entrenar las salidas del modelo.
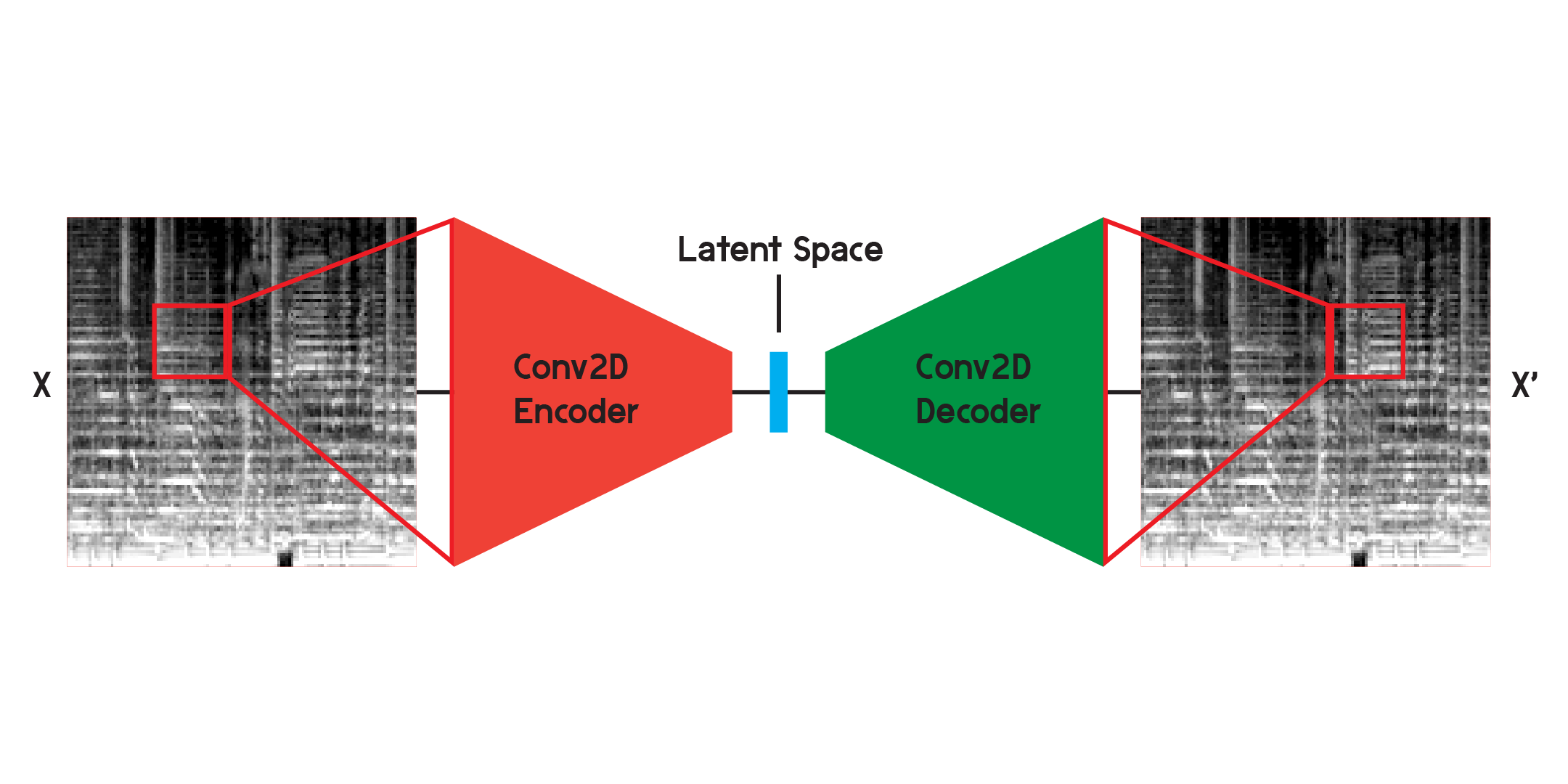
Cuando se trabaja con imágenes, el codificador es una secuencia de capas convolucionales bidimensionales, que crean filtros ponderados para extraer patrones en la imagen, al mismo tiempo que comprimen la imagen en una forma cada vez más pequeña. El decodificador es un reflejo especular del proceso en el codificador, remodelando y expandiendo una pequeña cantidad de datos en una más grande. El modelo minimiza el error cuadrático medio entre el original y la reconstrucción. Una vez entrenado lo suficiente, el error cuadrático medio entre el original y la salida del modelo será muy pequeño. Aunque el error cuadrático medio será mínimo, todavía existe una diferencia visual entre la reconstrucción y la imagen original, especialmente en los detalles más pequeños. El codificador automático es un reductor de ruido. Queremos extraer tantos detalles como sea posible, pero en última instancia, el codificador automático también combinará algunos detalles.
Inicialmente entrené la red usando la estructura ilustrada arriba, pero descubrí que faltaban muchos detalles en las reconstrucciones. Las capas convolucionales buscan patrones que son solo una pequeña porción de la imagen completa. Pero tras entrenar y observar los filtros, resulta complicado intuir los patrones que se extraen.
Los codificadores automáticos como estos se pueden utilizar en varios problemas diferentes y, con capas convolucionales, existen muchas aplicaciones para el reconocimiento y la generación de imágenes. Pero dado que el espectrograma mel no es solo una imagen sino un gráfico de frecuencias en el contenido del sonido a lo largo del tiempo, creo que se puede implementar una estructura ligeramente diferente para minimizar la pérdida en la reconstrucción, y al mismo tiempo minimizar la incertidumbre creada por la convolución bidimensional. capas.
En el modelo utilizado para los resultados finales del modelo, dividí el codificador en dos codificadores separados. Cada codificador utiliza capas convolucionales unidimensionales para comprimir el espacio de la imagen. Un codificador se entrena en X, mientras que el otro se entrena en transposición X o una versión girada 90 grados de la entrada. De esta manera, un codificador aprende información del eje de tiempo de la imagen y el otro aprende del eje de frecuencia.
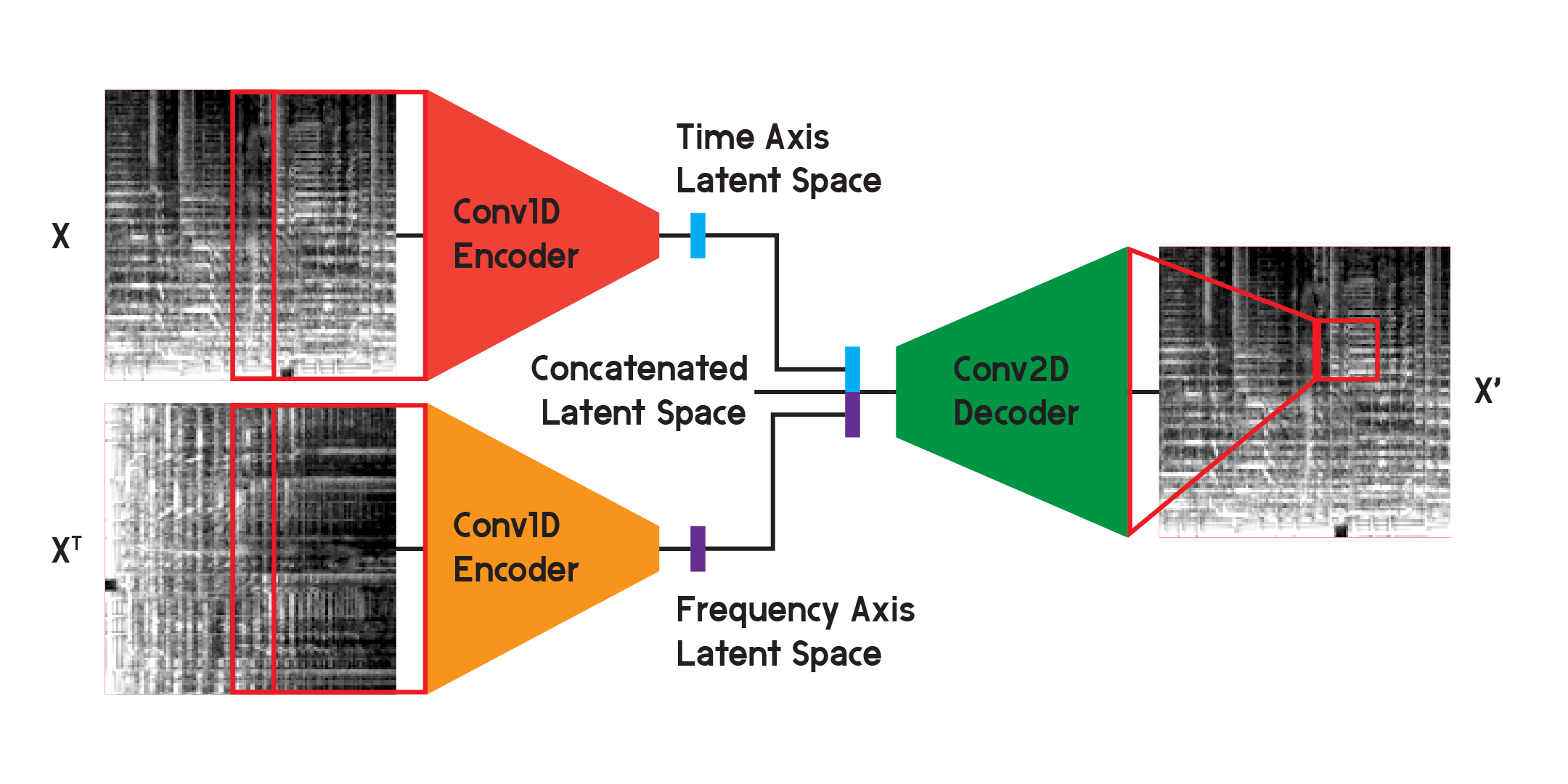
Después de que la entrada pasa por cada codificador, los vectores codificados resultantes se concatenan en un vector y se ingresan en el decodificador convolucional bidimensional como se ilustra antes. Las salidas están entrenadas para minimizar la pérdida entre las entradas como antes.
Al final, la pérdida en el modelo final fue mucho menor que en la estructura básica, alcanzando un error cuadrático medio de 0,0037 (entrenamiento) y 0,0037 (validación) después de 20 épocas, con 125.440 imágenes en el conjunto de entrenamiento y 2560 en el. conjunto de validación.
Construiremos el modelo aquí solo con fines demostrativos, ya que entrené el modelo en otro cuaderno y cargaremos los pesos del modelo entrenado una vez que esté construido.
Usando una clase personalizada para ejecutar inferencias a través de la red y guardar resultados, podemos construir el espacio latente para cada espectrograma mel que tengamos. Podemos hacer esto ejecutando los datos solo a través del codificador y recibiendo un vector del tamaño con el que inicializamos el modelo con, en este caso, 256 dimensiones.
Para explorar el paisaje abstracto creado por el espacio latente de los datos a través del modelo, podemos utilizar la reducción de dimensionalidad. UMAP, como T-SNE, puede reducir un espacio multidimensional a 2 dimensiones para visualizarlo en un gráfico.
La clase LatentSpace personalizada buscará recomendaciones utilizando similitud de coseno para cada vector.
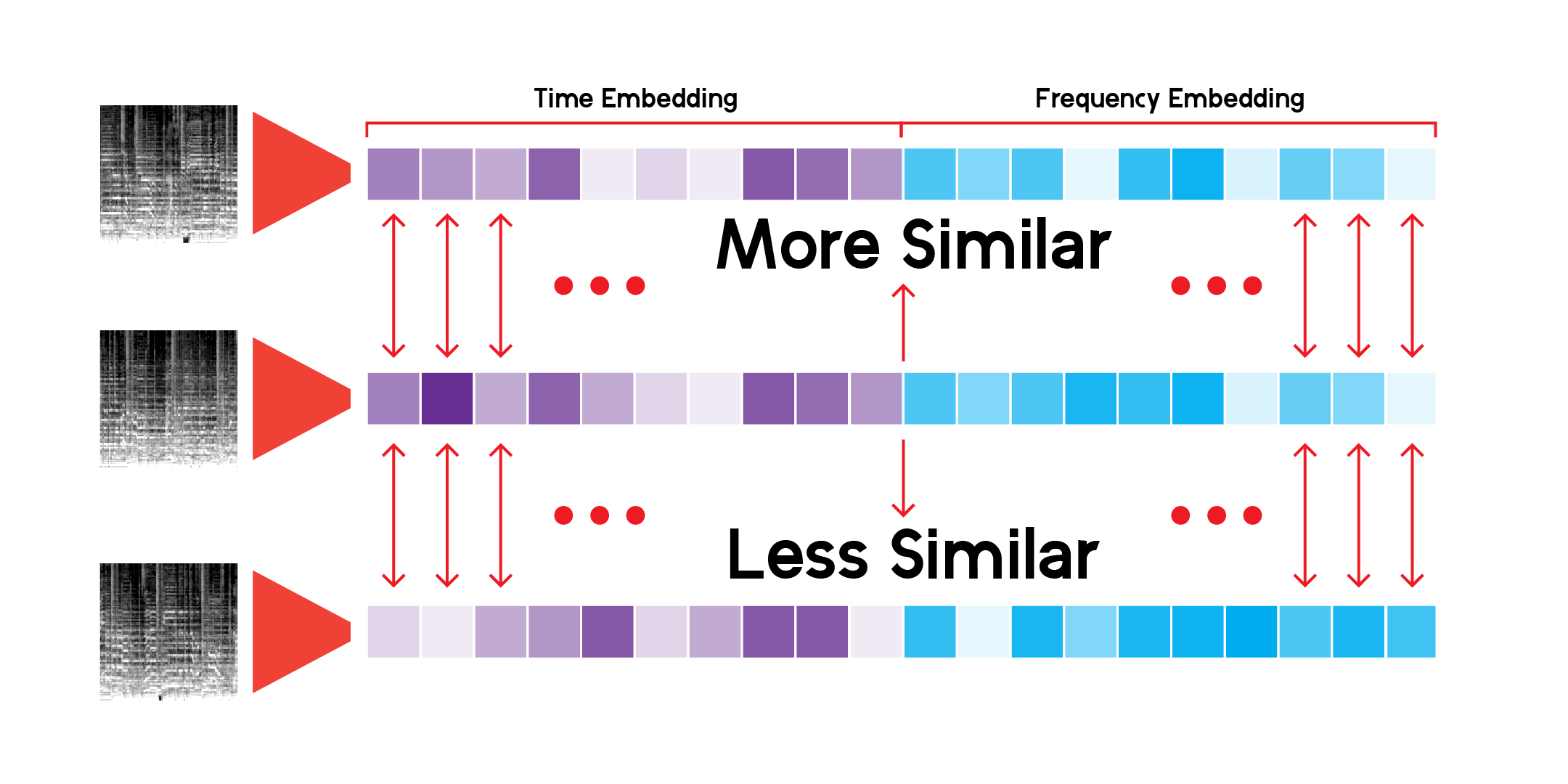
He buscado incesantemente en este sistema de recomendaciones y estoy satisfecho de que el modelo pueda detectar conexiones muy interesantes entre sonidos musicales diferentes pero también similares. Estas son algunas de mis conclusiones:
Lo que quiero decir con esto es que el modelo hace recomendaciones basadas en el contenido de sonido de cada canción, pero no escucha la canción. Crea un espectrograma mel y hace una comparación matemática.
A veces, el sistema hará una recomendación para una canción según su antigüedad. Si una canción se grabó hace mucho tiempo, el modelo recogerá esas frecuencias particulares del material o equipo de grabación y mostrará los resultados.
Además, el modelo es muy bueno para captar voces o instrumentos particulares. Debido a esto, si una canción incluye mucha conversación o canto, es posible que solo recomiende pistas de palabras habladas. Además, si hay mucha distorsión en una canción, podría recomendar sonidos de lluvia o cantos de pájaros.
Algunas vistas previas de pistas no están disponibles en la API de Spotify, como se señaló en mi EDA inicial. Por lo tanto, su contribución al modelo también falta y no será una recomendación cuando podrían encajar perfectamente en uno. Por ejemplo, no hay canciones de James Brown, los Beatles o Prince. Necesita más datos.
El sistema utiliza más de 278.000 vistas previas para hacer recomendaciones, y eso todavía no es suficiente. Al observar la proyección de UMAP para todas las pistas, hay mucha continuidad en los datos, pero hay algunos vacíos. Idealmente, el sistema podría utilizar muchos más datos a los que recurrir.
Lo que hace que un sistema/servicio de recomendación como Spotify sea tan bueno para hacer recomendaciones es que combina muchos tipos diferentes de sistemas de recomendación y características como esta para brindar recomendaciones. Desde rastrear lo que escuchas regularmente hasta usar filtrado colaborativo para encontrar recomendaciones basadas en usos similares de usuarios, Spotify puede hacer predicciones mucho más equilibradas sobre lo que le gustará y escuchará a alguien. Este modelo me parece interesante para hacer predicciones, pero se puede mejorar agregando más características como géneros similares, años de lanzamiento y datos de usuario similares para hacer mejores predicciones.
Con todo, además de hacer predicciones y recomendaciones, creo que la verdadera importancia de este modelo existe para explicar la continuidad y el espectro del lenguaje y el sonido musical. Los géneros son etiquetas que la gente pone a un artista o sonido, pero los géneros se mezclan y cada sonido existe en este espacio continuo, al menos matemáticamente.
Además, la música no tiene barreras. La mayoría de las veces, al consultar una canción en el sistema de recomendación, los resultados provendrán de todas las épocas y lugares diferentes. Dado que ninguno de los metadatos de una canción es una entrada para el codificador automático, los resultados se basan en su similitud sonora y nada más.


