system design primer
1.0.0
Inglés ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελληνικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Español ∙ ภาษาไทย ∙ Türkçe ∙ tiếng Việt ∙ Français | Agregar traducción
¡Ayuda a traducir esta guía!
Aprenda a diseñar sistemas a gran escala.
Prepárese para la entrevista de diseño del sistema.
Aprender a diseñar sistemas escalables le ayudará a convertirse en un mejor ingeniero.
El diseño de sistemas es un tema amplio. Existe una gran cantidad de recursos repartidos por toda la web sobre principios de diseño de sistemas.
Este repositorio es una colección organizada de recursos que le ayudarán a aprender cómo crear sistemas a escala.
Este es un proyecto de código abierto que se actualiza continuamente.
¡Las contribuciones son bienvenidas!
Además de codificar las entrevistas, el diseño del sistema es un componente obligatorio del proceso de entrevistas técnicas en muchas empresas de tecnología.
Practique preguntas comunes de entrevistas sobre diseño de sistemas y compare sus resultados con soluciones de muestra : discusiones, códigos y diagramas.
Temas adicionales para la preparación de la entrevista:
Las barajas de tarjetas didácticas de Anki proporcionadas utilizan repeticiones espaciadas para ayudarle a retener conceptos clave de diseño del sistema.
Ideal para usar mientras estás en movimiento.
¿Busca recursos que le ayuden a prepararse para la entrevista de codificación ?
Consulte el repositorio hermano Interactive Coding Challenges , que contiene un mazo Anki adicional:
Aprende de la comunidad.
No dudes en enviar solicitudes de extracción para ayudar:
El contenido que necesita algo de pulido se encuentra en desarrollo.
Revise las pautas de contribución.
Resúmenes de varios temas de diseño de sistemas, incluidos los pros y los contras. Todo es una compensación .
Cada sección contiene enlaces a recursos más detallados.
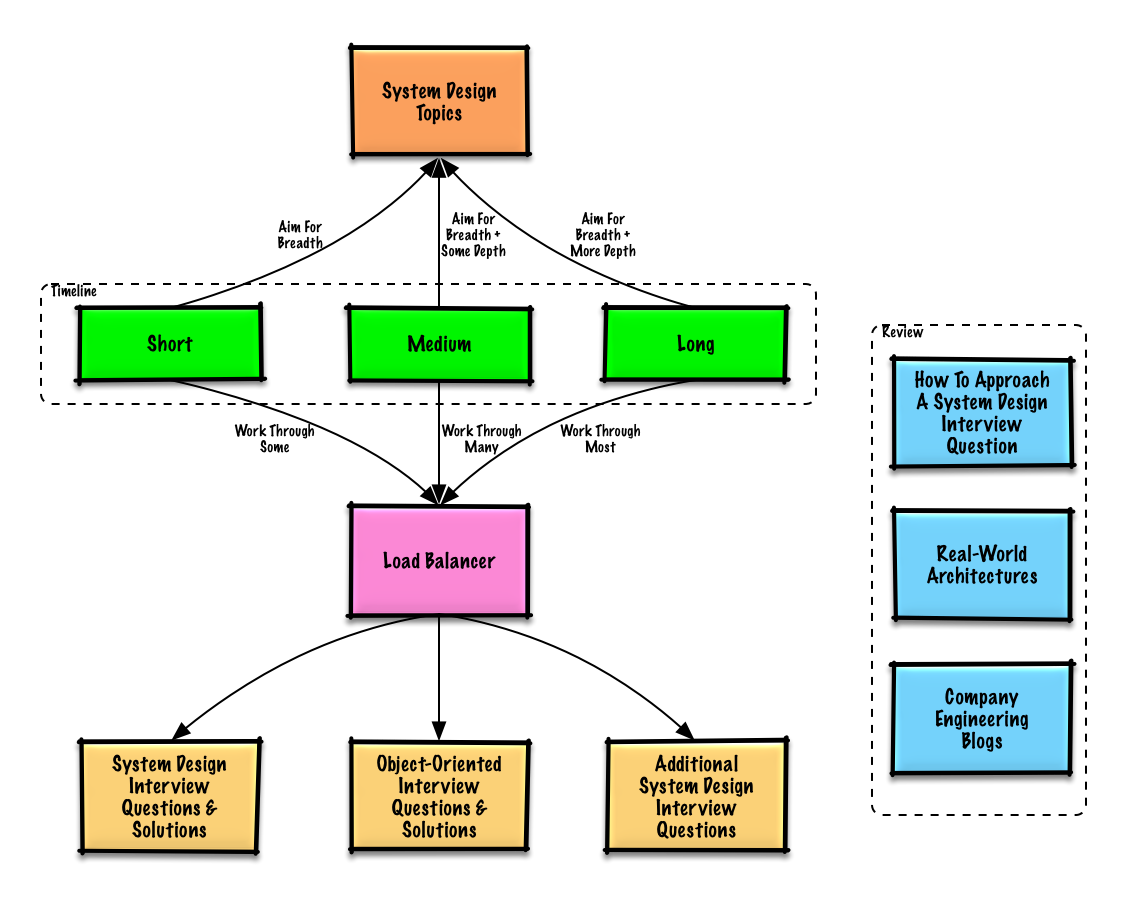
Temas sugeridos para revisar según el cronograma de su entrevista (corto, mediano, largo).
P: Para entrevistas, ¿necesito saber todo aquí?
R: No, no es necesario que sepas todo lo que hay aquí para prepararte para la entrevista .
Lo que te preguntan en una entrevista depende de variables como:
Generalmente se espera que los candidatos más experimentados sepan más sobre el diseño de sistemas. Se podría esperar que los arquitectos o los líderes de equipo sepan más que los contribuyentes individuales. Es probable que las principales empresas de tecnología realicen una o más rondas de entrevistas de diseño.
Empiece de forma amplia y profundice en algunas áreas. Es útil saber un poco sobre varios temas clave de diseño de sistemas. Ajuste la siguiente guía según su cronograma, experiencia, para qué puestos está entrevistando y con qué empresas está entrevistando.
| Corto | Medio | Largo | |
|---|---|---|---|
| Lea los temas de diseño de sistemas para obtener una comprensión amplia de cómo funcionan los sistemas. | ? | ? | ? |
| Lea algunos artículos en los blogs de ingeniería de la empresa para las empresas con las que se entrevistará. | ? | ? | ? |
| Lea algunas arquitecturas del mundo real. | ? | ? | ? |
| Revise Cómo abordar una pregunta de entrevista sobre diseño de sistemas | ? | ? | ? |
| Trabaje a través de preguntas de la entrevista de diseño de sistemas con soluciones. | Alguno | Muchos | Mayoría |
| Resuelva las preguntas de la entrevista de diseño orientado a objetos con soluciones | Alguno | Muchos | Mayoría |
| Revise las preguntas adicionales de la entrevista sobre diseño de sistemas | Alguno | Muchos | Mayoría |
Cómo abordar una pregunta de entrevista sobre diseño de sistemas.
La entrevista de diseño del sistema es una conversación abierta . Se espera que usted lo lidere.
Puede utilizar los siguientes pasos para guiar la discusión. Para ayudar a solidificar este proceso, trabaje en la sección Preguntas de la entrevista de diseño del sistema con soluciones siguiendo los siguientes pasos.
Reúna los requisitos y analice el problema. Haga preguntas para aclarar casos de uso y limitaciones. Discuta las suposiciones.
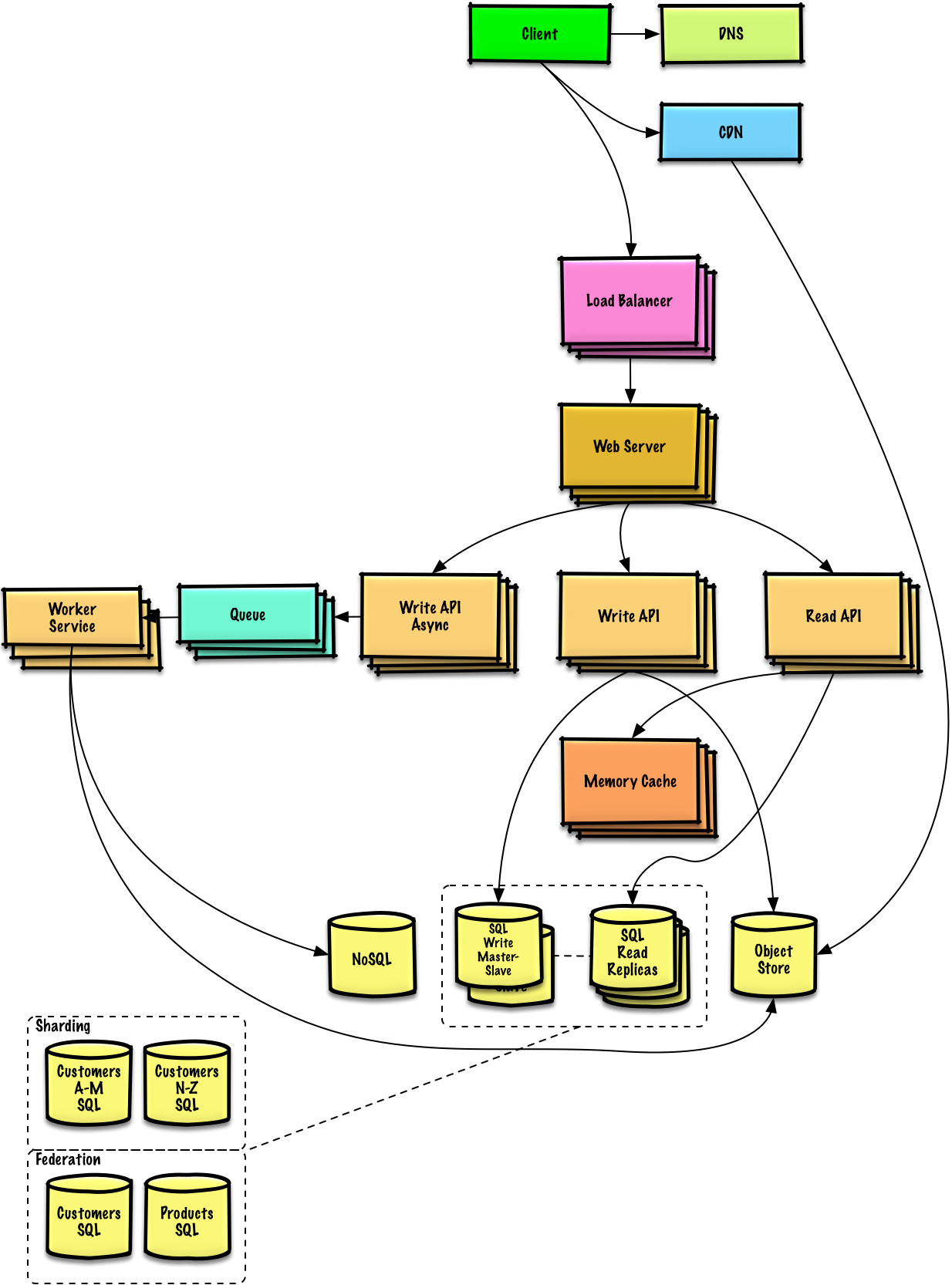
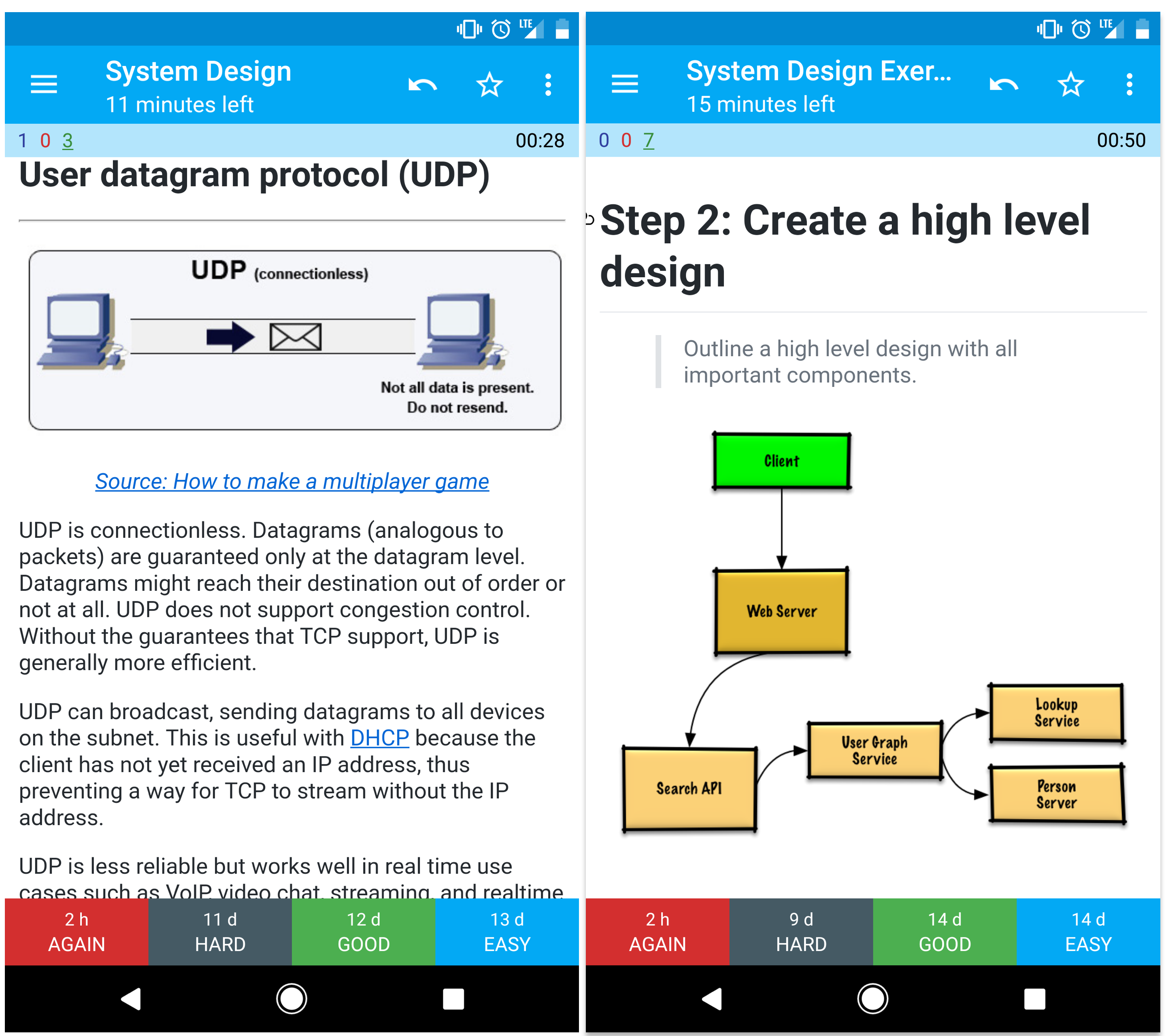
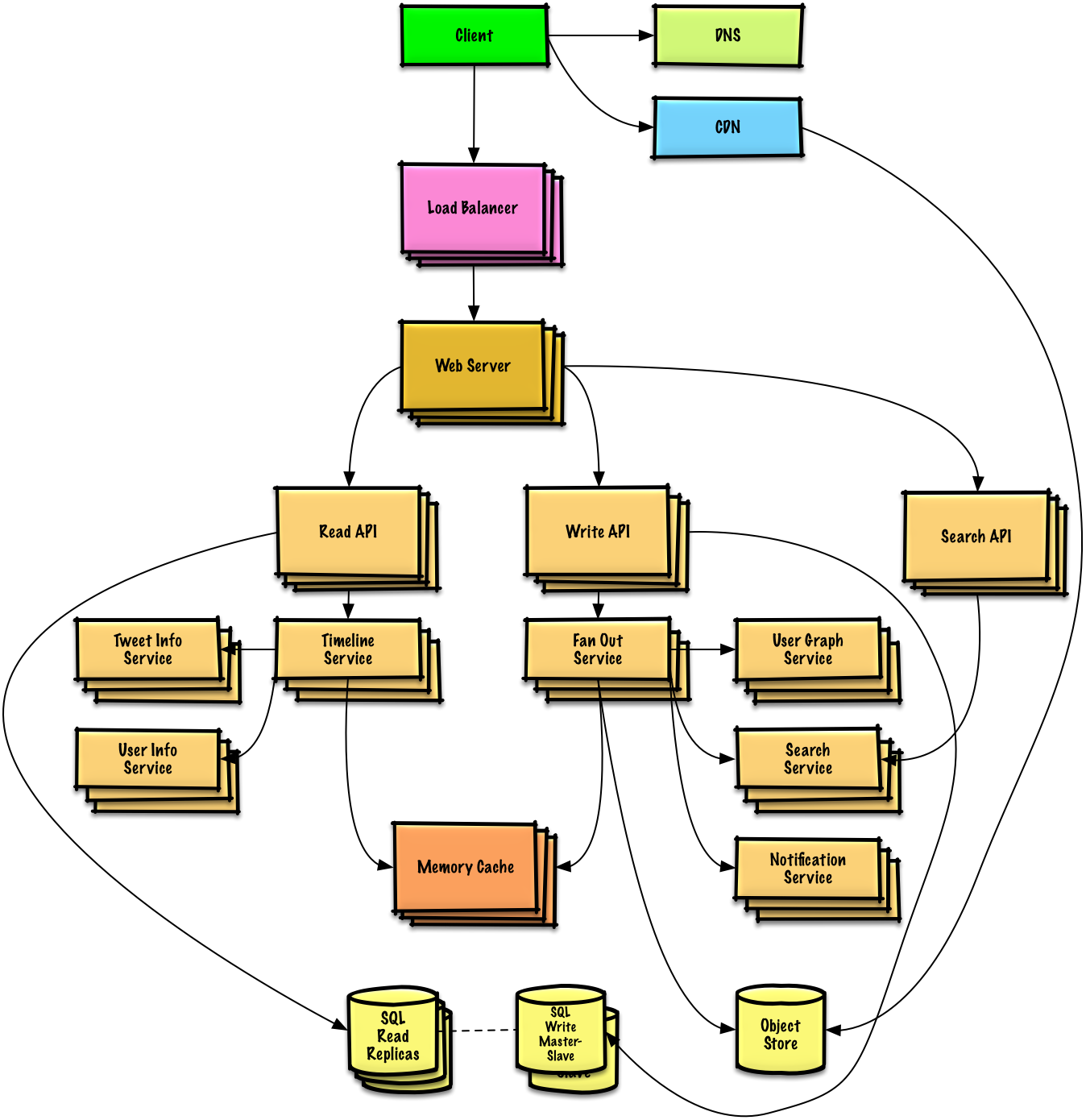
Describe un diseño de alto nivel con todos los componentes importantes.
Profundice en los detalles de cada componente principal. Por ejemplo, si le pidieran que diseñara un servicio de acortamiento de URL, analice:
Identificar y abordar los obstáculos, dadas las limitaciones. Por ejemplo, ¿necesita lo siguiente para abordar los problemas de escalabilidad?
Discuta posibles soluciones y compensaciones. Todo es una compensación. Abordar los cuellos de botella utilizando principios de diseño de sistemas escalables.
Es posible que le pidan que haga algunas estimaciones a mano. Consulte el Apéndice para obtener los siguientes recursos:
Consulte los siguientes enlaces para tener una mejor idea de qué esperar:
Preguntas de entrevista sobre diseño de sistemas comunes con ejemplos de debates, códigos y diagramas.
Soluciones vinculadas al contenido de la carpeta
solutions/.
| Pregunta | |
|---|---|
| Diseño Pastebin.com (o Bit.ly) | Solución |
| Diseñar la línea de tiempo y la búsqueda de Twitter (o el feed y la búsqueda de Facebook) | Solución |
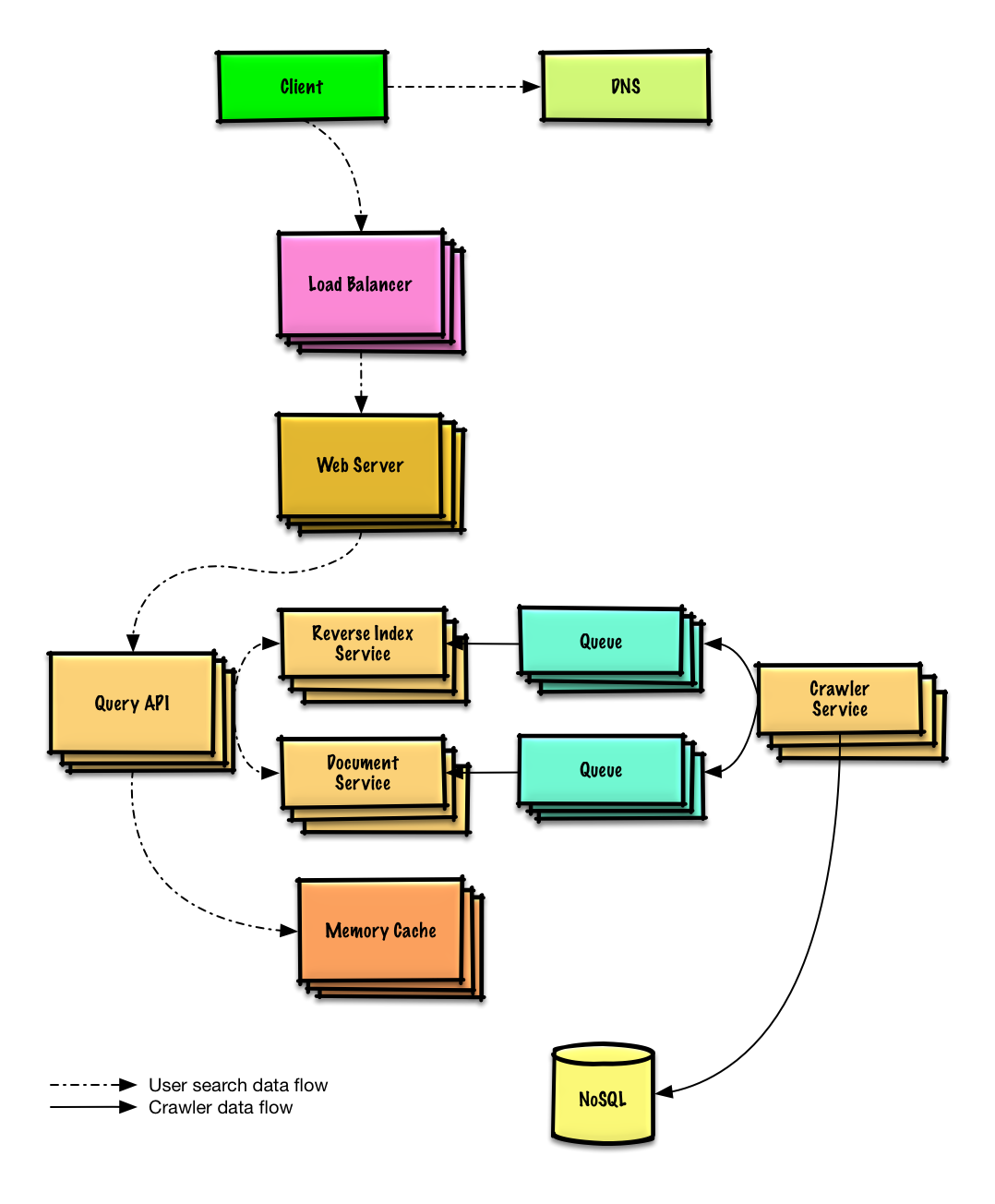
| Diseñar un rastreador web | Solución |
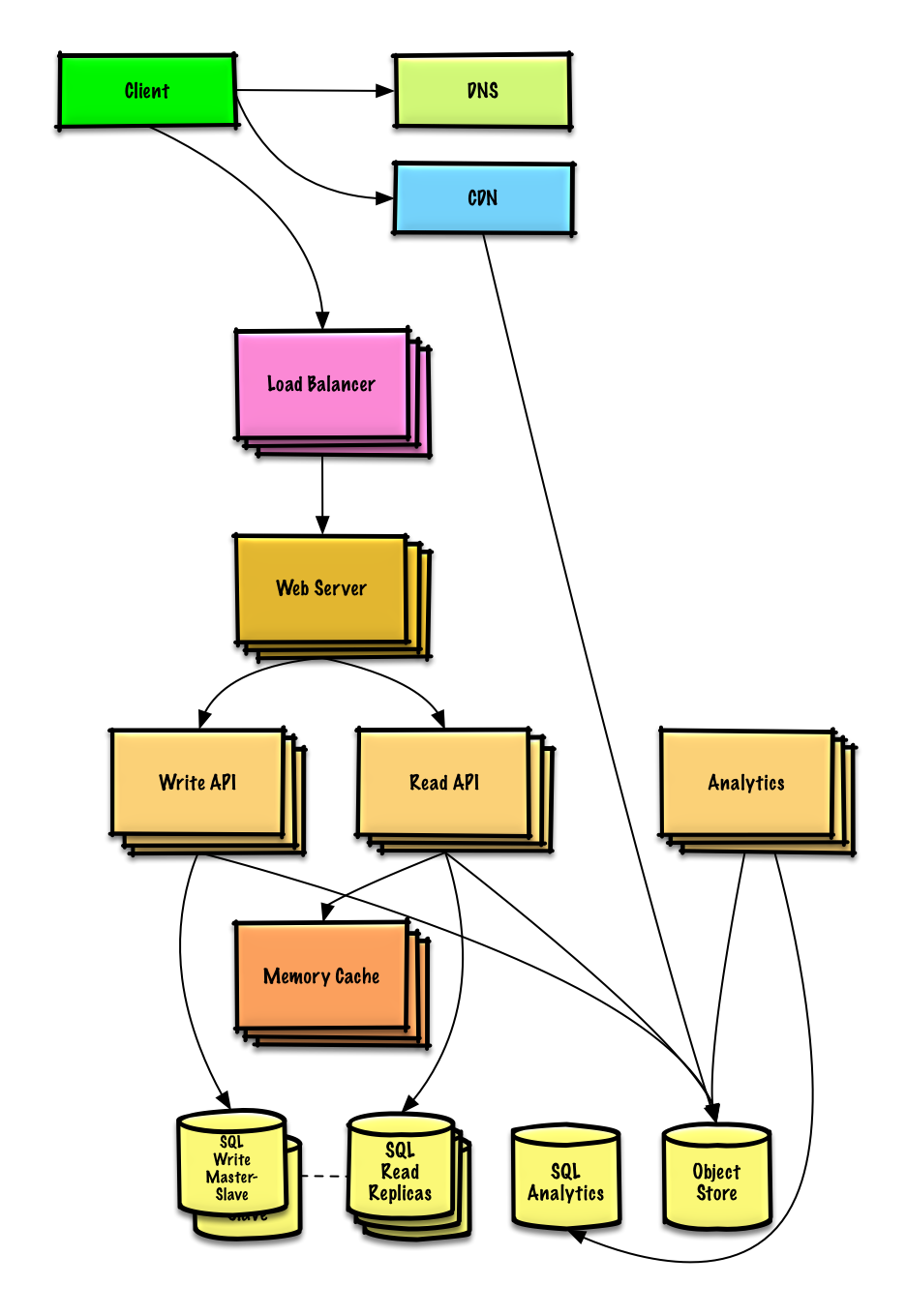
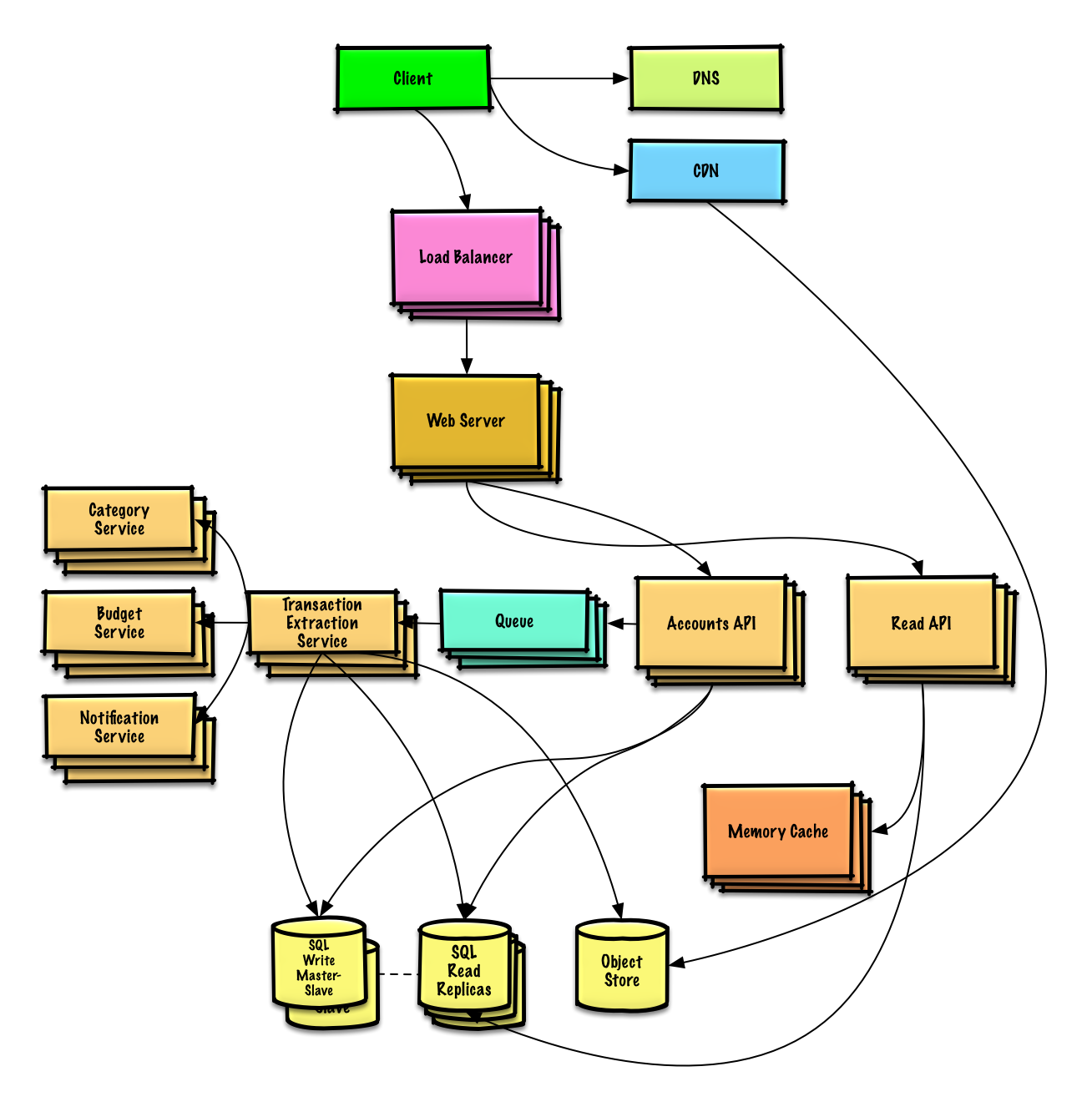
| Diseño Mint.com | Solución |
| Diseñar las estructuras de datos para una red social. | Solución |
| Diseñar una tienda de valores clave para un motor de búsqueda. | Solución |
| Diseñar el ranking de ventas de Amazon por función de categoría | Solución |
| Diseñe un sistema que pueda escalar a millones de usuarios en AWS | Solución |
| Agregar una pregunta de diseño del sistema | Contribuir |
Ver ejercicio y solución
Ver ejercicio y solución
Ver ejercicio y solución
Ver ejercicio y solución
Ver ejercicio y solución
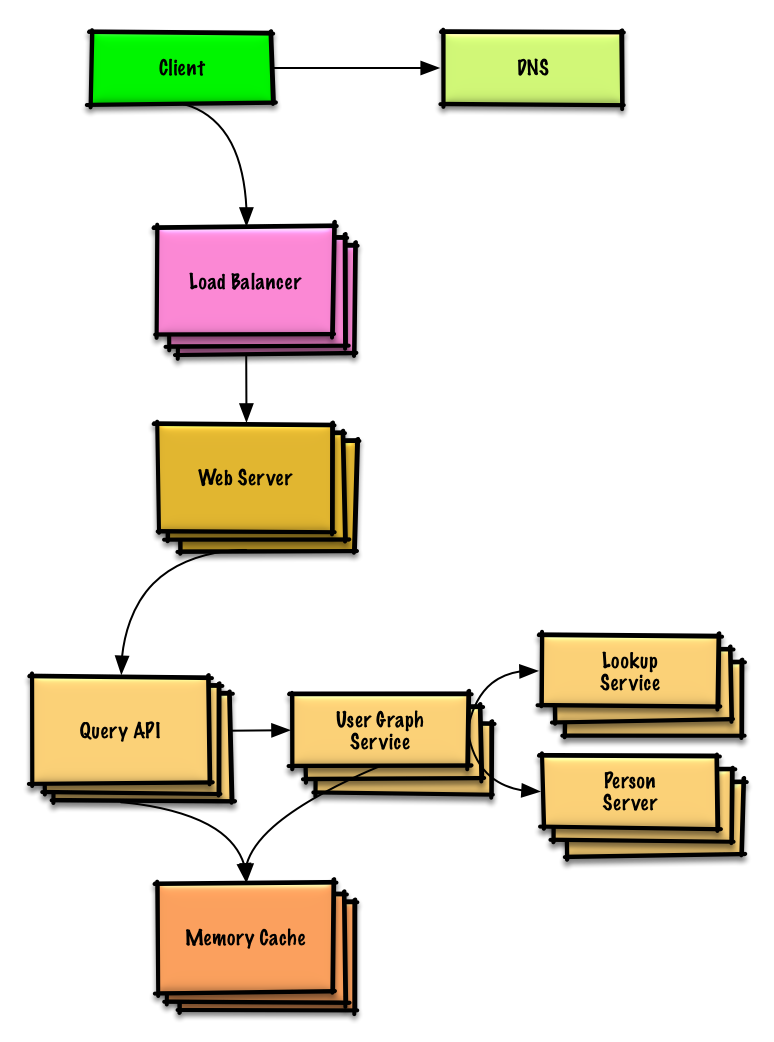
Ver ejercicio y solución
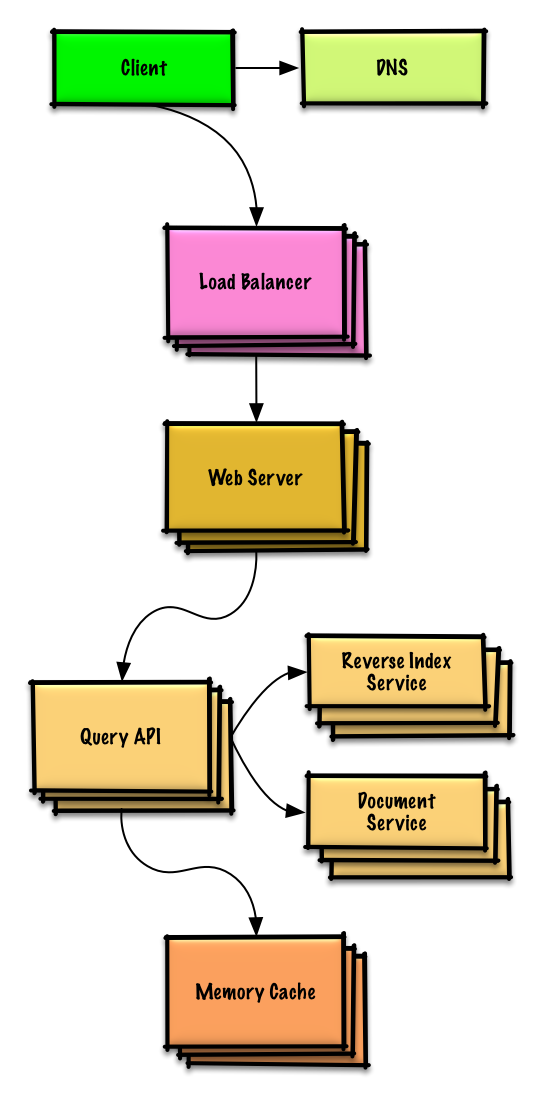
Ver ejercicio y solución
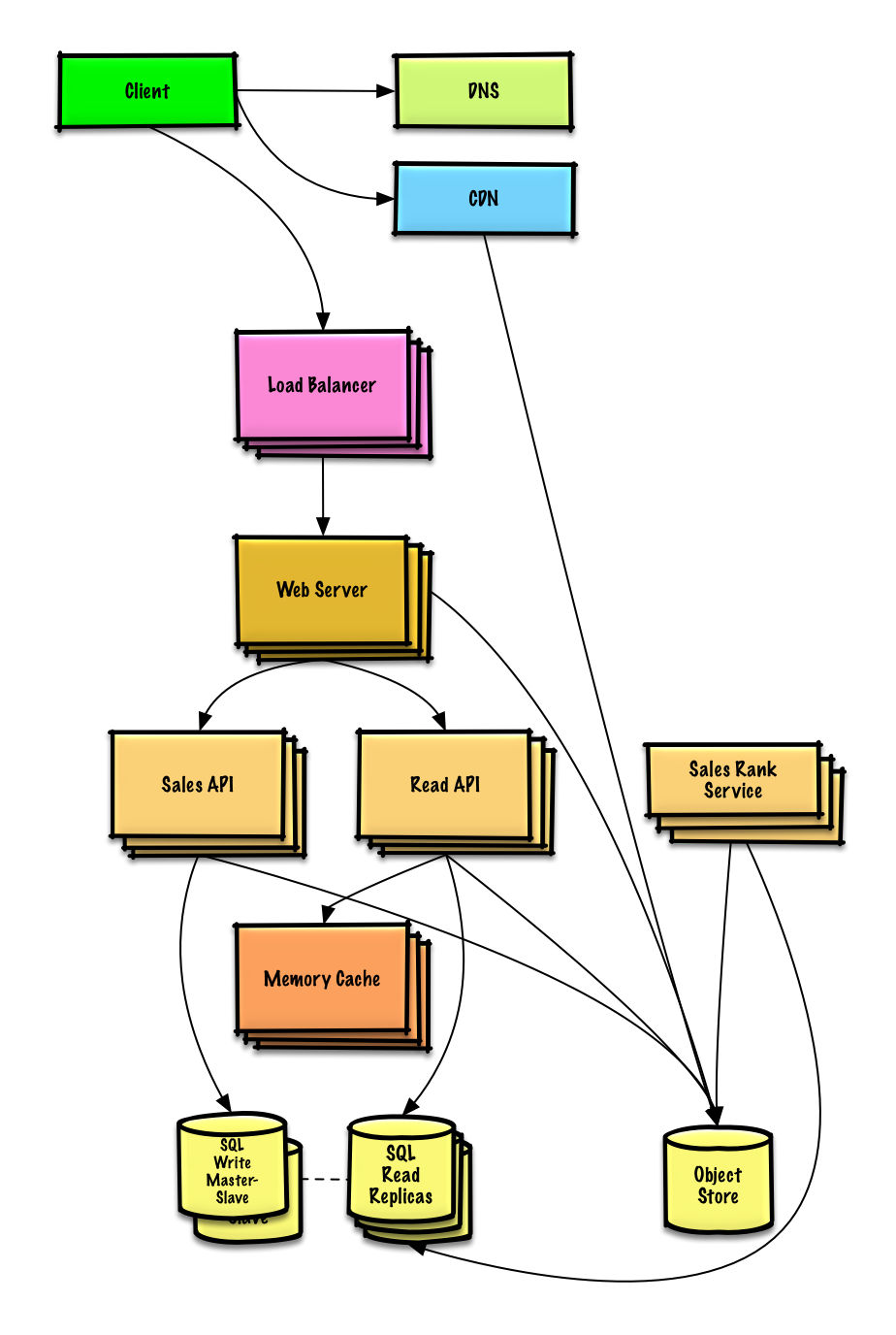
Ver ejercicio y solución
Preguntas comunes de entrevistas sobre diseño orientado a objetos con ejemplos de discusiones, códigos y diagramas.
Soluciones vinculadas al contenido de la carpeta
solutions/.
Nota: Esta sección está en desarrollo.
| Pregunta | |
|---|---|
| Diseñar un mapa hash | Solución |
| Diseñar un caché usado menos recientemente | Solución |
| Diseñar un centro de llamadas. | Solución |
| Diseñar una baraja de cartas. | Solución |
| Diseñar un estacionamiento | Solución |
| Diseñar un servidor de chat | Solución |
| Diseñar una matriz circular | Contribuir |
| Agregar una pregunta de diseño orientada a objetos | Contribuir |
¿Nuevo en el diseño de sistemas?
En primer lugar, necesitará una comprensión básica de los principios comunes, aprender qué son, cómo se utilizan y sus ventajas y desventajas.
Conferencia sobre escalabilidad en Harvard
Escalabilidad
A continuación, veremos las compensaciones de alto nivel:
Tenga en cuenta que todo es una compensación .
Luego profundizaremos en temas más específicos como DNS, CDN y balanceadores de carga.
Un servicio es escalable si da como resultado un mayor rendimiento de manera proporcional a los recursos agregados. Generalmente, aumentar el rendimiento significa atender a más unidades de trabajo, pero también puede significar manejar unidades de trabajo más grandes, como cuando crecen los conjuntos de datos. 1
Otra forma de ver el rendimiento frente a la escalabilidad:
La latencia es el tiempo para realizar alguna acción o producir algún resultado.
El rendimiento es el número de dichas acciones o resultados por unidad de tiempo.
En general, debe aspirar a lograr el máximo rendimiento con una latencia aceptable .
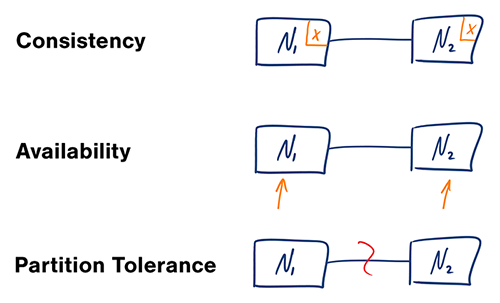
Fuente: Teorema CAP revisado
En un sistema informático distribuido, sólo se pueden soportar dos de las siguientes garantías:
Las redes no son confiables, por lo que deberá admitir la tolerancia de partición. Deberá hacer un equilibrio entre la coherencia y la disponibilidad del software.
Esperar una respuesta del nodo particionado puede provocar un error de tiempo de espera. CP es una buena opción si las necesidades de su negocio requieren lecturas y escrituras atómicas.
Las respuestas devuelven la versión más disponible de los datos disponibles en cualquier nodo, que puede no ser la más reciente. Las escrituras pueden tardar algún tiempo en propagarse cuando se resuelve la partición.
AP es una buena opción si la empresa necesita permitir una eventual coherencia o cuando el sistema necesita seguir funcionando a pesar de los errores externos.
Con múltiples copias de los mismos datos, nos enfrentamos a opciones sobre cómo sincronizarlas para que los clientes tengan una vista consistente de los datos. Recuerde la definición de coherencia del teorema CAP: cada lectura recibe la escritura más reciente o un error.
Después de una escritura, las lecturas pueden verla o no. Se adopta un enfoque de mejor esfuerzo.
Este enfoque se ve en sistemas como memcached. La coherencia débil funciona bien en casos de uso en tiempo real, como VoIP, video chat y juegos multijugador en tiempo real. Por ejemplo, si estás en una llamada telefónica y pierdes la recepción durante unos segundos, cuando recuperas la conexión no escuchas lo que se habló durante la pérdida de conexión.
Después de una escritura, las lecturas eventualmente la verán (normalmente en milisegundos). Los datos se replican de forma asincrónica.
Este enfoque se ve en sistemas como DNS y correo electrónico. La coherencia final funciona bien en sistemas de alta disponibilidad.
Después de escribir, las lecturas lo verán. Los datos se replican de forma sincrónica.
Este enfoque se ve en sistemas de archivos y RDBMS. Una coherencia sólida funciona bien en sistemas que necesitan transacciones.
Hay dos patrones complementarios para admitir la alta disponibilidad: conmutación por error y replicación .
Con la conmutación por error activo-pasivo, se envían latidos entre el servidor activo y el pasivo en espera. Si se interrumpe el latido, el servidor pasivo toma el control de la dirección IP del activo y reanuda el servicio.
La duración del tiempo de inactividad está determinada por si el servidor pasivo ya se está ejecutando en modo de espera "activo" o si necesita iniciarse desde el modo de espera "frío". Sólo el servidor activo maneja el tráfico.
La conmutación por error activo-pasivo también se puede denominar conmutación por error maestro-esclavo.
En activo-activo, ambos servidores gestionan el tráfico, repartiendo la carga entre ellos.
Si los servidores son públicos, el DNS necesitaría conocer las IP públicas de ambos servidores. Si los servidores son internos, la lógica de la aplicación necesitaría conocer ambos servidores.
La conmutación por error activo-activo también se puede denominar conmutación por error maestro-maestro.
Este tema se analiza con más detalle en la sección Base de datos:
La disponibilidad a menudo se cuantifica por el tiempo de actividad (o inactividad) como porcentaje del tiempo que el servicio está disponible. La disponibilidad generalmente se mide en número de 9: un servicio con una disponibilidad del 99,99 % se describe como si tuviera cuatro 9.
| Duración | Tiempo de inactividad aceptable |
|---|---|
| Tiempo de inactividad por año | 8h 45min 57s |
| Tiempo de inactividad por mes | 43m 49,7s |
| Tiempo de inactividad por semana | 10m 4,8s |
| Tiempo de inactividad por día | 1m 26,4s |
| Duración | Tiempo de inactividad aceptable |
|---|---|
| Tiempo de inactividad por año | 52min 35,7s |
| Tiempo de inactividad por mes | 4m 23s |
| Tiempo de inactividad por semana | 1m 5s |
| Tiempo de inactividad por día | 8,6s |
Si un servicio consta de varios componentes propensos a fallar, la disponibilidad general del servicio depende de si los componentes están en secuencia o en paralelo.
La disponibilidad general disminuye cuando dos componentes con disponibilidad < 100 % están en secuencia:
Availability (Total) = Availability (Foo) * Availability (Bar)
Si tanto Foo como Bar tuvieran cada uno un 99,9% de disponibilidad, su disponibilidad total en secuencia sería del 99,8%.
La disponibilidad general aumenta cuando dos componentes con disponibilidad < 100 % están en paralelo:
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))
Si tanto Foo como Bar tuvieran cada uno un 99,9% de disponibilidad, su disponibilidad total en paralelo sería del 99,9999%.
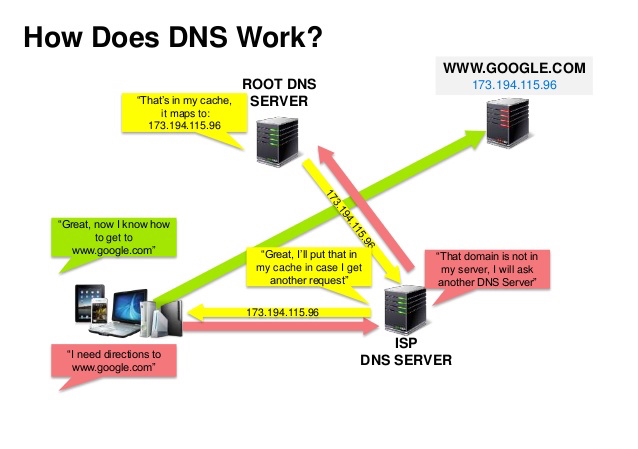
Fuente: presentación de seguridad DNS
Un sistema de nombres de dominio (DNS) traduce un nombre de dominio como www.example.com a una dirección IP.
El DNS es jerárquico, con algunos servidores autorizados en el nivel superior. Su enrutador o ISP proporciona información sobre qué servidores DNS contactar al realizar una búsqueda. Asignaciones de caché de servidores DNS de nivel inferior, que podrían volverse obsoletas debido a retrasos en la propagación de DNS. Los resultados de DNS también pueden ser almacenados en caché por su navegador o sistema operativo durante un cierto período de tiempo, determinado por el tiempo de vida (TTL).
CNAME (ejemplo.com a www.ejemplo.com) o a un registro AServicios como CloudFlare y Route 53 brindan servicios de DNS administrados. Algunos servicios DNS pueden enrutar el tráfico a través de varios métodos:
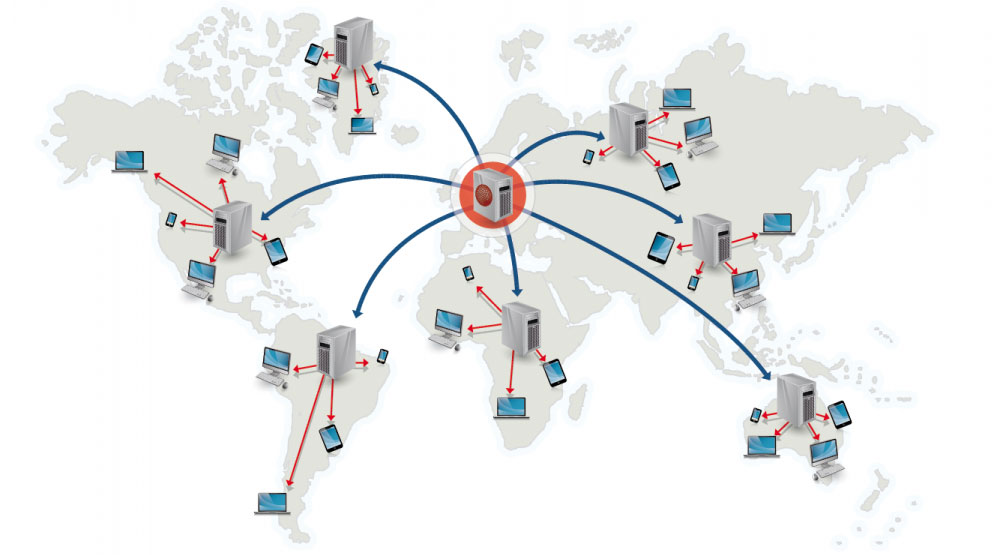
Fuente: ¿Por qué utilizar una CDN?
Una red de entrega de contenido (CDN) es una red de servidores proxy distribuida globalmente que sirve contenido desde ubicaciones más cercanas al usuario. Generalmente, los archivos estáticos como HTML/CSS/JS, fotos y vídeos se sirven desde CDN, aunque algunas CDN como CloudFront de Amazon admiten contenido dinámico. La resolución DNS del sitio indicará a los clientes con qué servidor contactar.
Servir contenido desde CDN puede mejorar significativamente el rendimiento de dos maneras:
Las CDN push reciben contenido nuevo cada vez que se producen cambios en su servidor. Usted asume toda la responsabilidad de proporcionar contenido, cargarlo directamente en la CDN y reescribir las URL para que apunten a la CDN. Puede configurar cuándo caduca el contenido y cuándo se actualiza. El contenido se carga solo cuando es nuevo o modificado, lo que minimiza el tráfico pero maximiza el almacenamiento.
Los sitios con una pequeña cantidad de tráfico o sitios con contenido que no se actualiza con frecuencia funcionan bien con las CDN push. El contenido se coloca en las CDN una vez, en lugar de volver a extraerse a intervalos regulares.
Las CDN extraíbles obtienen contenido nuevo de su servidor cuando el primer usuario solicita el contenido. Deja el contenido en su servidor y reescribe las URL para que apunten a la CDN. Esto da como resultado una solicitud más lenta hasta que el contenido se almacena en caché en la CDN.
Un tiempo de vida (TTL) determina cuánto tiempo se almacena en caché el contenido. Las CDN de extracción minimizan el espacio de almacenamiento en la CDN, pero pueden crear tráfico redundante si los archivos caducan y se extraen antes de que realmente hayan cambiado.
Los sitios con mucho tráfico funcionan bien con las CDN pull, ya que el tráfico se distribuye de manera más uniforme y solo queda en la CDN el contenido solicitado recientemente.
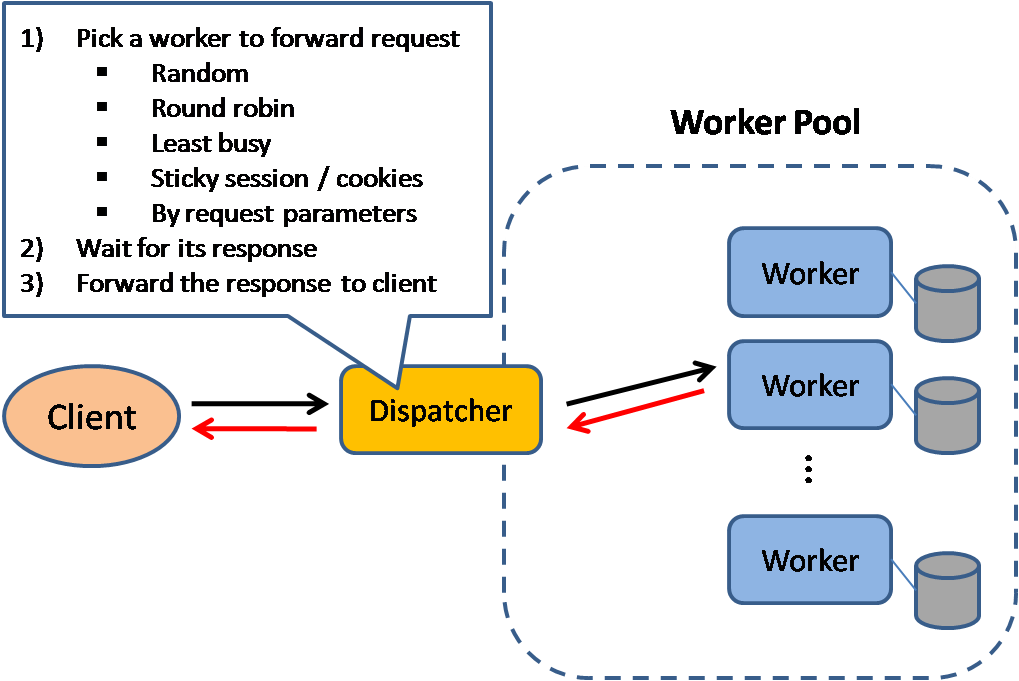
Fuente: Patrones de diseño de sistemas escalables.
Los balanceadores de carga distribuyen las solicitudes entrantes de los clientes a recursos informáticos como servidores de aplicaciones y bases de datos. En cada caso, el equilibrador de carga devuelve la respuesta del recurso informático al cliente apropiado. Los balanceadores de carga son efectivos en:
Los balanceadores de carga se pueden implementar con hardware (caro) o con software como HAProxy.
Los beneficios adicionales incluyen:
Para protegerse contra fallas, es común configurar múltiples balanceadores de carga, ya sea en modo activo-pasivo o activo-activo.
Los balanceadores de carga pueden enrutar el tráfico en función de varias métricas, que incluyen:
Los balanceadores de carga de capa 4 analizan la información de la capa de transporte para decidir cómo distribuir las solicitudes. Generalmente, esto involucra las direcciones IP de origen, destino y puertos en el encabezado, pero no el contenido del paquete. Los balanceadores de carga de capa 4 reenvían paquetes de red hacia y desde el servidor ascendente, realizando la traducción de direcciones de red (NAT).
Los balanceadores de carga de capa 7 analizan la capa de aplicación para decidir cómo distribuir las solicitudes. Esto puede involucrar el contenido del encabezado, el mensaje y las cookies. Los equilibradores de carga de capa 7 finalizan el tráfico de red, leen el mensaje, toman una decisión de equilibrio de carga y luego abren una conexión con el servidor seleccionado. Por ejemplo, un equilibrador de carga de capa 7 puede dirigir el tráfico de vídeo a servidores que alojan vídeos y, al mismo tiempo, dirigir el tráfico de facturación de usuarios más sensible a servidores con seguridad reforzada.
A costa de la flexibilidad, el equilibrio de carga de la capa 4 requiere menos tiempo y recursos informáticos que la capa 7, aunque el impacto en el rendimiento puede ser mínimo en el hardware básico moderno.
Los balanceadores de carga también pueden ayudar con el escalamiento horizontal, mejorando el rendimiento y la disponibilidad. La ampliación mediante el uso de máquinas básicas es más rentable y da como resultado una mayor disponibilidad que la ampliación de un único servidor en hardware más caro, lo que se denomina escalamiento vertical . También es más fácil contratar talentos que trabajen en hardware básico que en sistemas empresariales especializados.
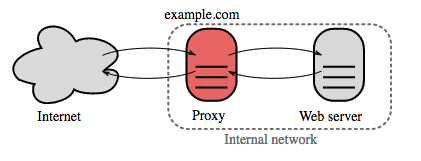
Fuente: Wikipedia
Un proxy inverso es un servidor web que centraliza los servicios internos y proporciona interfaces unificadas al público. Las solicitudes de los clientes se reenvían a un servidor que puede cumplirlas antes de que el proxy inverso devuelva la respuesta del servidor al cliente.
Los beneficios adicionales incluyen:
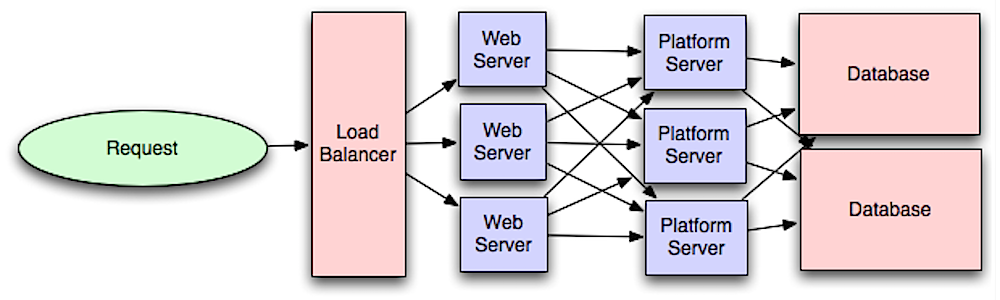
Fuente: Introducción a la arquitectura de sistemas a escala.
Separar la capa web de la capa de aplicación (también conocida como capa de plataforma) le permite escalar y configurar ambas capas de forma independiente. Agregar una nueva API da como resultado agregar servidores de aplicaciones sin necesariamente agregar servidores web adicionales. El principio de responsabilidad única aboga por servicios pequeños y autónomos que trabajen juntos. Los equipos pequeños con servicios pequeños pueden planificar de manera más agresiva para lograr un crecimiento rápido.
Los trabajadores en la capa de aplicación también ayudan a habilitar el asincronismo.
Relacionados con esta discusión están los microservicios, que pueden describirse como un conjunto de servicios modulares, pequeños y desplegables de forma independiente. Cada servicio ejecuta un proceso único y se comunica a través de un mecanismo liviano y bien definido para cumplir un objetivo comercial. 1
Pinterest, por ejemplo, podría tener los siguientes microservicios: perfil de usuario, seguidor, feed, búsqueda, subida de fotos, etc.
Sistemas como Consul, Etcd y Zookeeper pueden ayudar a que los servicios se encuentren entre sí realizando un seguimiento de los nombres, direcciones y puertos registrados. Las comprobaciones de estado ayudan a verificar la integridad del servicio y, a menudo, se realizan mediante un punto final HTTP. Tanto Consul como Etcd tienen un almacén de valores-clave integrado que puede resultar útil para almacenar valores de configuración y otros datos compartidos.
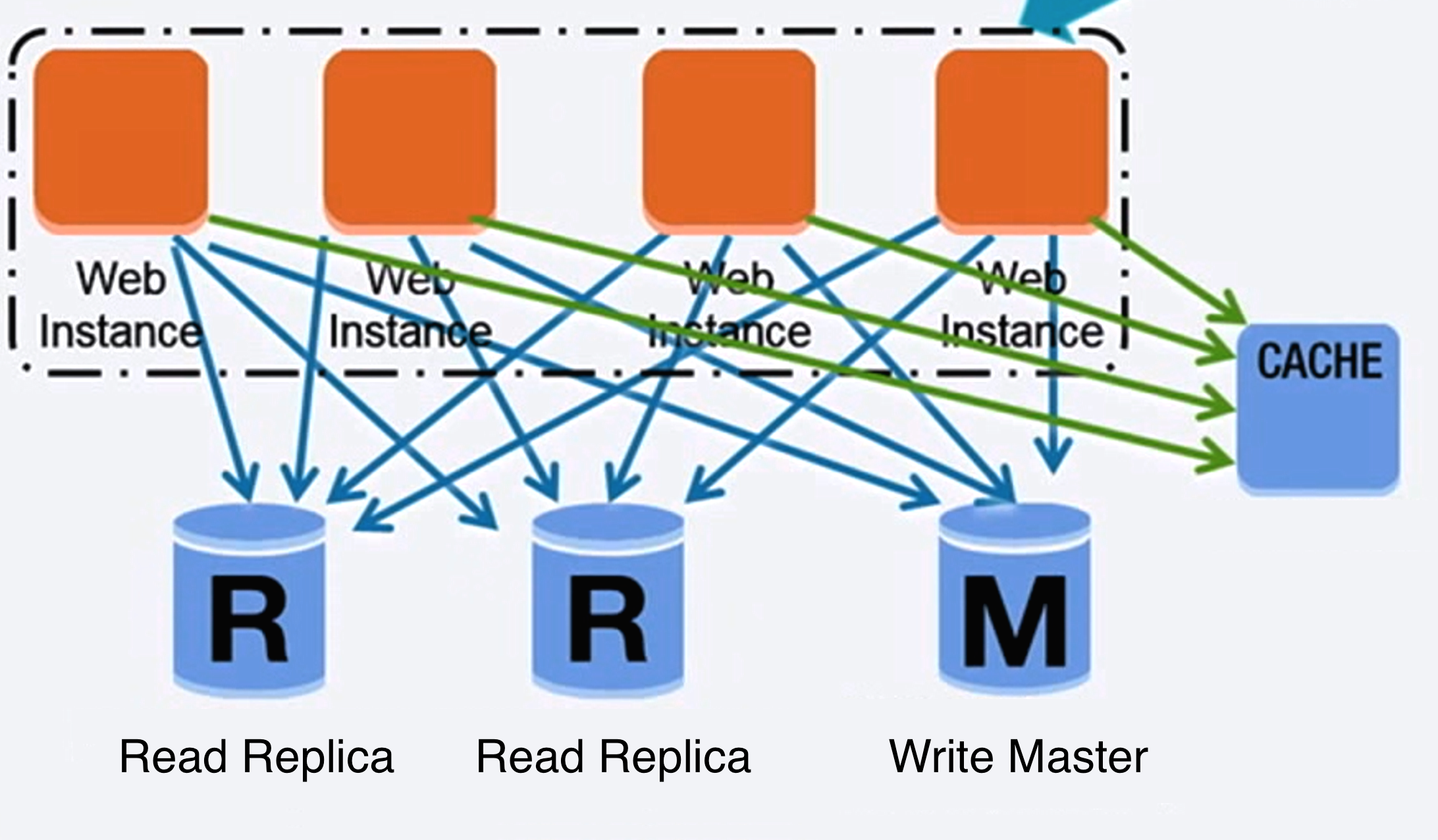
Fuente: Ampliación hasta los primeros 10 millones de usuarios
Una base de datos relacional como SQL es una colección de elementos de datos organizados en tablas.
ACID es un conjunto de propiedades de transacciones de bases de datos relacionales.
Existen muchas técnicas para escalar una base de datos relacional: replicación maestro-esclavo , replicación maestro-maestro , federación , fragmentación , desnormalización y ajuste de SQL .
El maestro realiza lecturas y escrituras, replicando escrituras en uno o más esclavos, que solo realizan lecturas. Los esclavos también pueden replicarse en esclavos adicionales en forma de árbol. Si el maestro se desconecta, el sistema puede continuar funcionando en modo de solo lectura hasta que un esclavo sea promovido a maestro o se aprovisione un nuevo maestro.
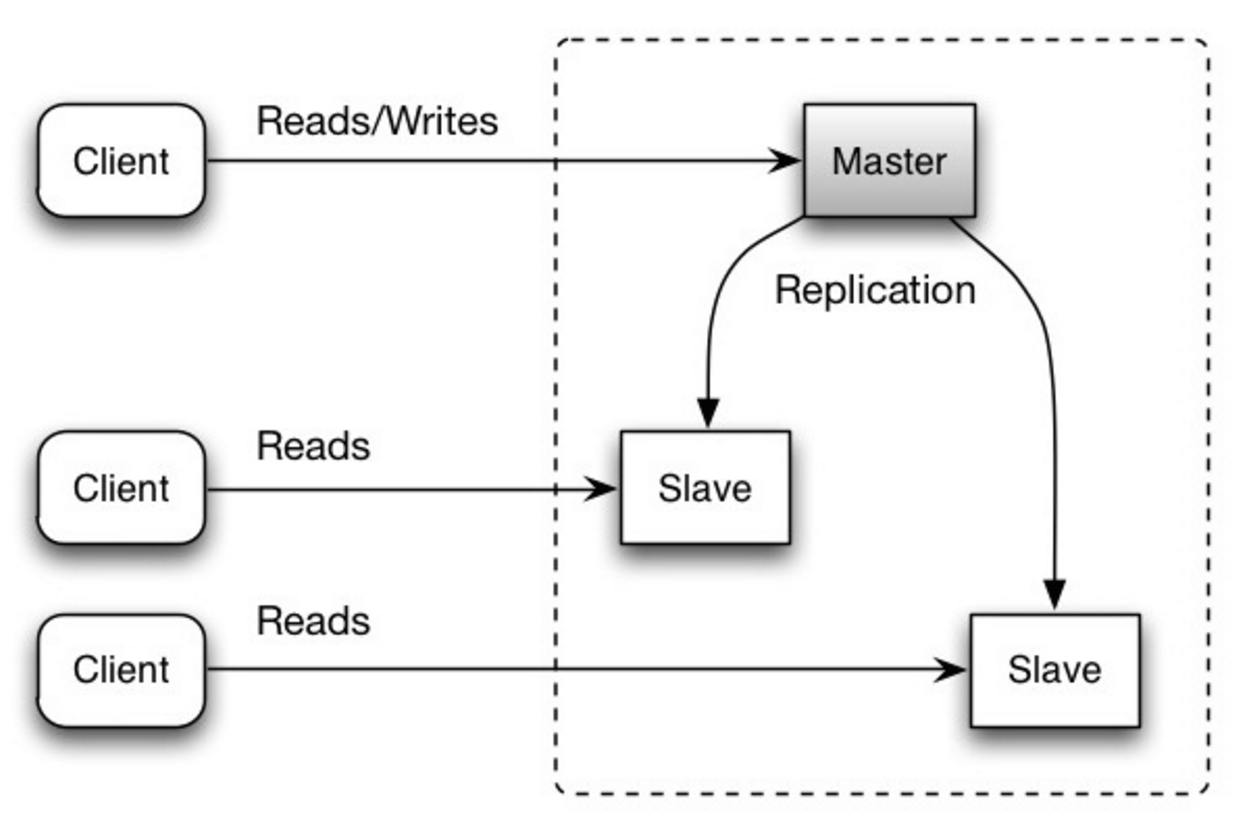
Fuente: Escalabilidad, disponibilidad, estabilidad, patrones.
Ambos maestros realizan lecturas y escrituras y se coordinan entre sí en escrituras. Si cualquiera de los maestros falla, el sistema puede continuar funcionando con lecturas y escrituras.
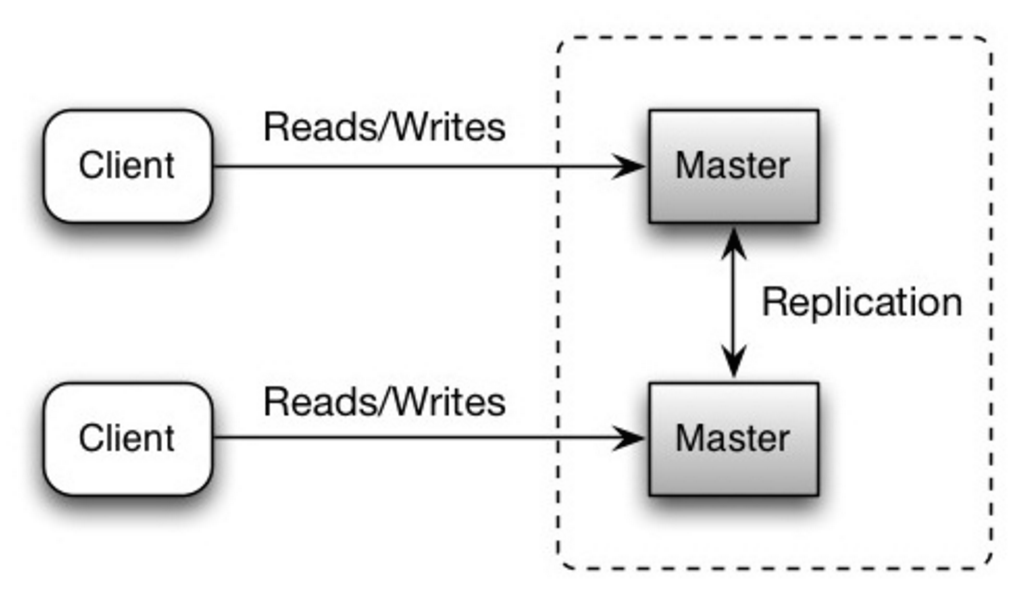
Fuente: Escalabilidad, disponibilidad, estabilidad, patrones.
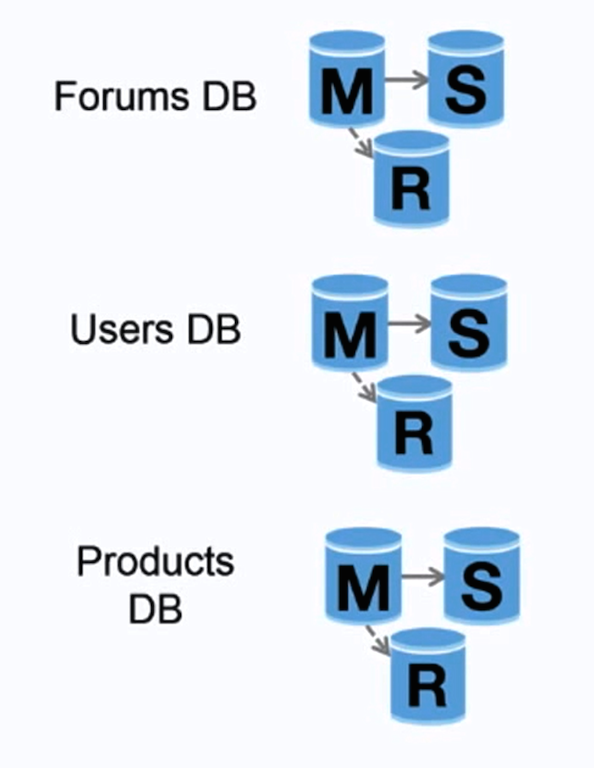
Fuente: Ampliación hasta los primeros 10 millones de usuarios
La federación (o partición funcional) divide las bases de datos por función. Por ejemplo, en lugar de una base de datos única y monolítica, podría tener tres bases de datos: foros , usuarios y productos , lo que generaría menos tráfico de lectura y escritura en cada base de datos y, por lo tanto, menos retraso en la replicación. Las bases de datos más pequeñas generan más datos que caben en la memoria, lo que a su vez resulta en más aciertos de caché debido a la mejora de la localidad de caché. Sin una única escritura de serialización maestra central, puede escribir en paralelo, lo que aumenta el rendimiento.
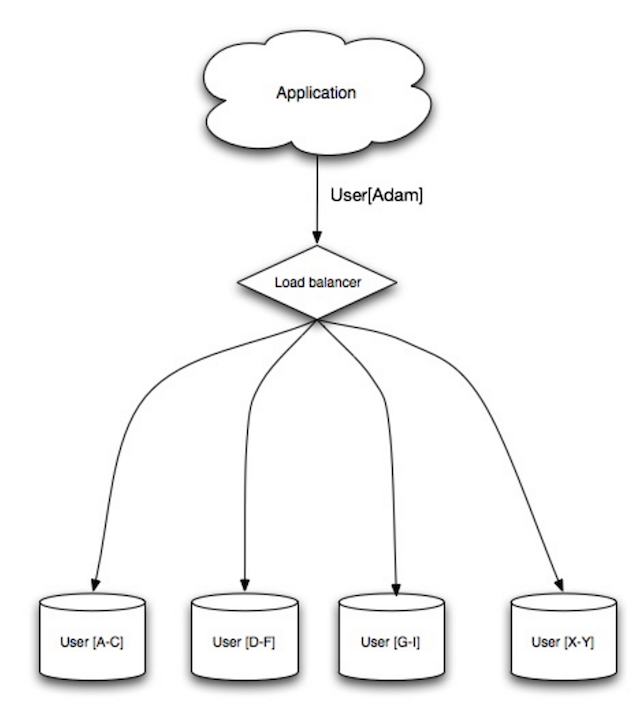
Fuente: Escalabilidad, disponibilidad, estabilidad, patrones.
La fragmentación distribuye datos entre diferentes bases de datos, de modo que cada base de datos solo puede administrar un subconjunto de datos. Tomando como ejemplo una base de datos de usuarios, a medida que aumenta el número de usuarios, se agregan más fragmentos al clúster.
De manera similar a las ventajas de la federación, la fragmentación genera menos tráfico de lectura y escritura, menos replicación y más aciertos de caché. El tamaño del índice también se reduce, lo que generalmente mejora el rendimiento con consultas más rápidas. Si un fragmento falla, los otros fragmentos siguen operativos, aunque querrás agregar alguna forma de replicación para evitar la pérdida de datos. Al igual que la federación, no existe un único maestro central que serialice las escrituras, lo que le permite escribir en paralelo con un mayor rendimiento.
Las formas más comunes de fragmentar una tabla de usuarios son mediante la inicial del apellido del usuario o la ubicación geográfica del usuario.
La denormalización intenta mejorar el rendimiento de lectura a expensas de algún rendimiento de escritura. Las copias redundantes de los datos se escriben en múltiples tablas para evitar juntas costosas. Algunos RDBM como PostgreSQL y Oracle admiten vistas materializadas que manejan el trabajo de almacenar información redundante y mantener consistentes copias redundantes.
Una vez que los datos se distribuyen con técnicas como la federación y el fragmento, la gestión se une a los centros de datos aumenta aún más la complejidad. La denormalización podría eludir la necesidad de tales uniones complejas.
En la mayoría de los sistemas, las lecturas pueden superar en gran medida las escrituras de 100: 1 o incluso 1000: 1. Una lectura que resulta en una unión de base de datos compleja puede ser muy costosa, pasando una cantidad significativa de tiempo en operaciones de disco.
SQL Tuning es un tema amplio y muchos libros se han escrito como referencia.
Es importante comparar y perfil para simular y descubrir cuellos de botella.
La evaluación comparativa y el perfil pueden apuntar a las siguientes optimizaciones.
CHAR en lugar de VARCHAR para campos de longitud fija.CHAR efectivamente permite un acceso rápido y aleatorio, mientras que con VARCHAR , debe encontrar el final de una cadena antes de pasar al siguiente.TEXT para grandes bloques de texto, como publicaciones de blog. TEXT también permite búsquedas booleanas. El uso de un campo TEXT da como resultado almacenar un puntero en el disco que se utiliza para ubicar el bloque de texto.INT para números mayores de hasta 2^32 o 4 mil millones.DECIMAL para la moneda para evitar errores de representación de puntos flotantes.BLOBS grandes, almacene la ubicación de dónde obtener el objeto en su lugar.VARCHAR(255) es el mayor número de caracteres que se pueden contar en un número de 8 bits, a menudo maximizando el uso de un byte en algunos RDBMS.NOT NULL cuando corresponda para mejorar el rendimiento de la búsqueda. SELECT , GROUP BY , ORDER BY , JOIN ) podrían ser más rápidos con los índices.NoSQL es una colección de elementos de datos representados en una tienda de valor clave , almacén de documentos , almacén de columnas ancho o una base de datos de gráficos . Los datos se desnormalizan y generalmente se realizan en el código de aplicación. La mayoría de las tiendas NoSQL carecen de verdaderas transacciones ácidas y favorecen la consistencia eventual.
La base a menudo se usa para describir las propiedades de las bases de datos NoSQL. En comparación con el teorema de CAP, la base elige la disponibilidad sobre la consistencia.
Además de elegir entre SQL o NoSQL, es útil comprender qué tipo de base de datos NoSQL se ajusta mejor a sus casos de uso. Revisaremos las tiendas de valor clave , las tiendas de documentos , las tiendas de columnas anchas y las bases de datos de gráficos en la siguiente sección.
Abstracción: tabla hash
Una tienda de valor clave generalmente permite que O (1) lea y escriba y a menudo se respalde por memoria o SSD. Las tiendas de datos pueden mantener las claves en orden lexicográfico, lo que permite una recuperación eficiente de rangos clave. Las tiendas de valor clave pueden permitir el almacenamiento de metadatos con un valor.
Las tiendas de valor clave proporcionan un alto rendimiento y a menudo se usan para modelos de datos simples o para datos que cambian rápidamente, como una capa de caché en memoria. Dado que ofrecen solo un conjunto limitado de operaciones, la complejidad se desplaza a la capa de aplicación si se necesitan operaciones adicionales.
Una tienda de valor clave es la base para sistemas más complejos, como un almacén de documentos, y en algunos casos, una base de datos de gráficos.
Abstracción: almacén de valor clave con documentos almacenados como valores
Una tienda de documentos se centra en los documentos (XML, JSON, Binary, etc.), donde un documento almacena toda la información para un objeto dado. Las tiendas de documentos proporcionan API o un lenguaje de consulta para consultar en función de la estructura interna del documento en sí. Tenga en cuenta que muchas tiendas de valor clave incluyen características para trabajar con los metadatos de un valor, difuminando las líneas entre estos dos tipos de almacenamiento.
Según la implementación subyacente, los documentos están organizados por colecciones, etiquetas, metadatos o directorios. Aunque los documentos pueden organizarse o agruparse, los documentos pueden tener campos que son completamente diferentes entre sí.
Algunas tiendas de documentos como MongoDB y CouchDB también proporcionan un lenguaje similar a SQL para realizar consultas complejas. DynamoDB admite tanto valores como documentos.
Las tiendas de documentos proporcionan una alta flexibilidad y a menudo se usan para trabajar con datos que cambian ocasionalmente.
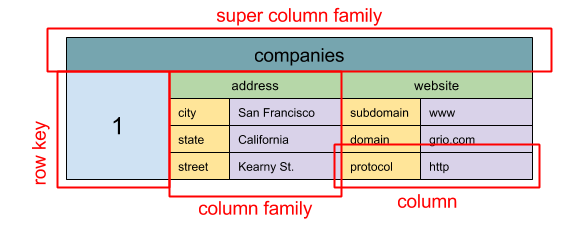
Fuente: SQL y NoSQL, una breve historia
Abstracción:
ColumnFamily<RowKey, Columns<ColKey, Value, Timestamp>>
La unidad de datos básica de una tienda de columna amplia es una columna (par de nombre/valor). Se puede agrupar una columna en familias de columnas (análoga a una tabla SQL). Familias de Super Column Familias de columna de grupos adicionales. Puede acceder a cada columna de forma independiente con una tecla de fila, y las columnas con la misma tecla de fila forman una fila. Cada valor contiene una marca de tiempo para versiones y resolución de conflictos.
Google introdujo Bigtable como la primera tienda de columnas amplias, que influyó en la HBase de código abierto a menudo utilizada en el ecosistema Hadoop y Cassandra de Facebook. Las tiendas como BigTable, HBase y Cassandra mantienen las claves en orden lexicográfico, lo que permite una recuperación eficiente de rangos clave selectivos.
Las tiendas de columna amplias ofrecen alta disponibilidad y alta escalabilidad. A menudo se usan para conjuntos de datos muy grandes.
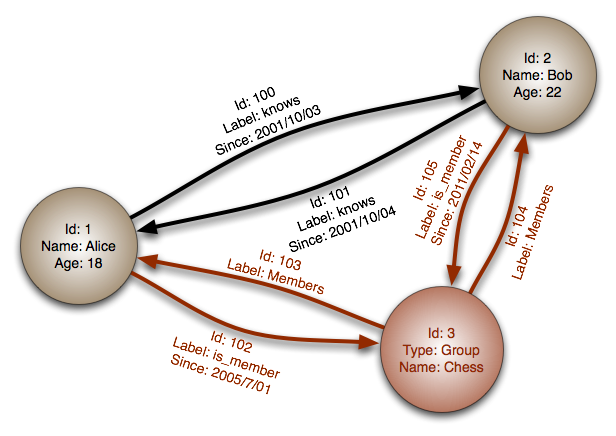
Fuente: Base de datos de gráficos
Abstracción: gráfico
En una base de datos de gráficos, cada nodo es un registro y cada arco es una relación entre dos nodos. Las bases de datos gráficas están optimizadas para representar relaciones complejas con muchas claves extranjeras o relaciones de muchas a muchos.
Las bases de datos de gráficos ofrecen un alto rendimiento para modelos de datos con relaciones complejas, como una red social. Son relativamente nuevos y aún no se usan ampliamente; Puede ser más difícil encontrar herramientas y recursos de desarrollo. Solo se puede acceder a muchos gráficos con API REST.
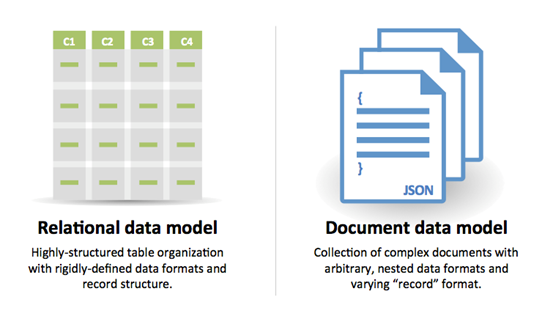
Fuente: Transición de RDBMS a NoSQL
Razones para SQL :
Razones para NoSQL :
Datos de muestra bien adecuado para NoSQL:
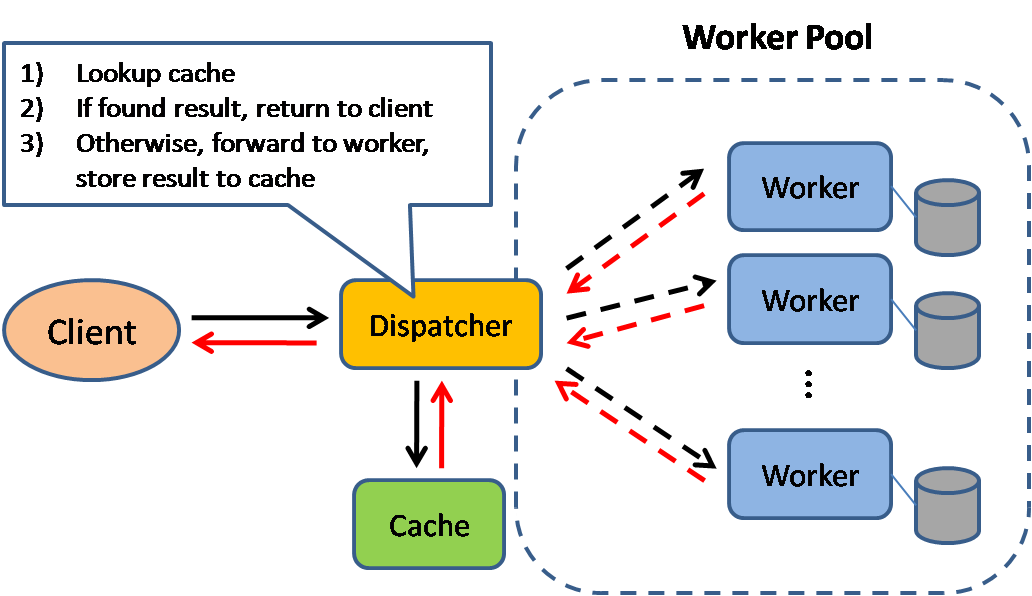
Fuente: patrones de diseño de sistema escalable
El almacenamiento en caché mejora los tiempos de carga de la página y puede reducir la carga en sus servidores y bases de datos. En este modelo, el despachador primero buscará si la solicitud se ha realizado antes e intentará encontrar el resultado anterior para devolver, para guardar la ejecución real.
Las bases de datos a menudo se benefician de una distribución uniforme de lecturas y escrituras en sus particiones. Los artículos populares pueden sesgar la distribución, causando cuellos de botella. Poner un caché frente a una base de datos puede ayudar a absorber cargas y picos desiguales en el tráfico.
Los cachés se pueden ubicar en el lado del cliente (sistema operativo o navegador), lado del servidor o en una capa de caché distinta.
Los CDN se consideran un tipo de caché.
Los proxies inversos y los cachés como el barniz pueden servir al contenido estático y dinámico directamente. Los servidores web también pueden almacenar en caché de las solicitudes, devolviendo respuestas sin tener que contactar a los servidores de aplicaciones.
Su base de datos generalmente incluye algún nivel de almacenamiento en caché en una configuración predeterminada, optimizado para un caso de uso genérico. Ajustar estas configuraciones para patrones de uso específicos puede aumentar aún más el rendimiento.
Los cachés en memoria, como Memcached y Redis, son tiendas de valores clave entre su aplicación y su almacenamiento de datos. Dado que los datos se mantienen en RAM, es mucho más rápido que las bases de datos típicas donde los datos se almacenan en el disco. La RAM es más limitada que el disco, por lo que los algoritmos de invalidación de caché, como menos recientemente usado (LRU), pueden ayudar a invalidar las entradas 'frías' y mantener los datos 'calientes' en la RAM.
Redis tiene las siguientes características adicionales:
Hay múltiples niveles en los que puede almacenar en caché que caen en dos categorías generales: consultas y objetos de bases de datos:
En general, debe intentar evitar el almacenamiento en caché basado en archivos, ya que dificulta la clonación y la escala automática.
Cada vez que consulta la base de datos, hash la consulta como una clave y almacene el resultado en el caché. Este enfoque sufre de problemas de vencimiento:
Consulte sus datos como un objeto, similar a lo que hace con su código de aplicación. Haga que su aplicación ensamble el conjunto de datos desde la base de datos en una instancia de clase o una estructura (s) de datos:
Sugerencias de qué almacenamiento en caché:
Dado que solo puede almacenar una cantidad limitada de datos en caché, deberá determinar qué estrategia de actualización de caché funciona mejor para su caso de uso.
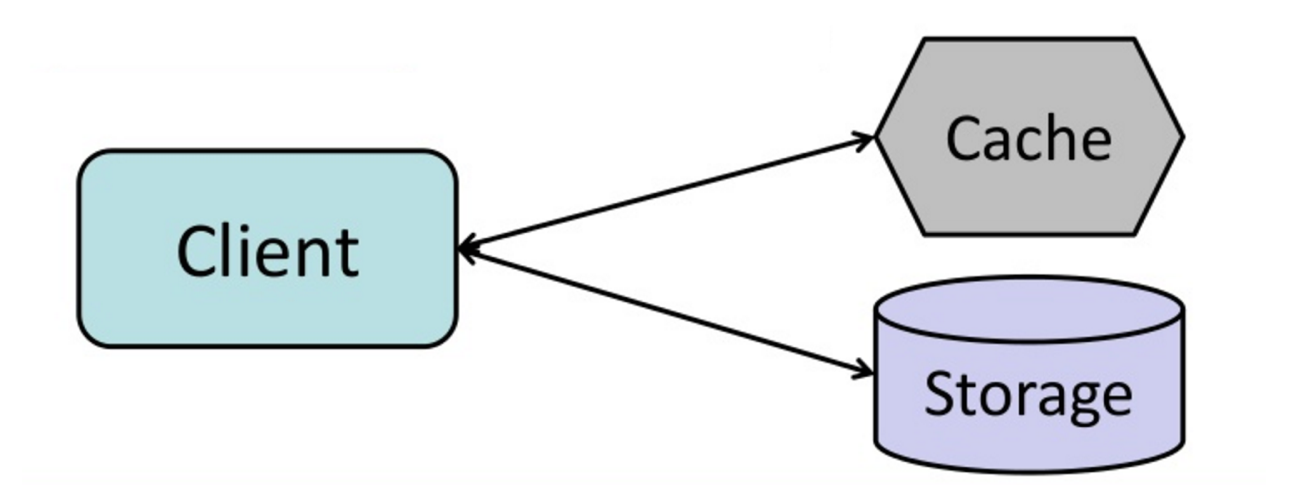
Fuente: Desde el caché hasta la cuadrícula de datos en la memoria
La aplicación es responsable de leer y escribir desde el almacenamiento. El caché no interactúa con el almacenamiento directamente. La aplicación hace lo siguiente:
def get_user ( self , user_id ):
user = cache . get ( "user.{0}" , user_id )
if user is None :
user = db . query ( "SELECT * FROM users WHERE user_id = {0}" , user_id )
if user is not None :
key = "user.{0}" . format ( user_id )
cache . set ( key , json . dumps ( user ))
return userMemcached se usa generalmente de esta manera.
Las lecturas posteriores de los datos agregados a la memoria caché son rápidas. El cache-asidio también se conoce como carga perezosa. Solo los datos solicitados se almacenan en caché, lo que evita completar el caché con datos que no se solicitan.
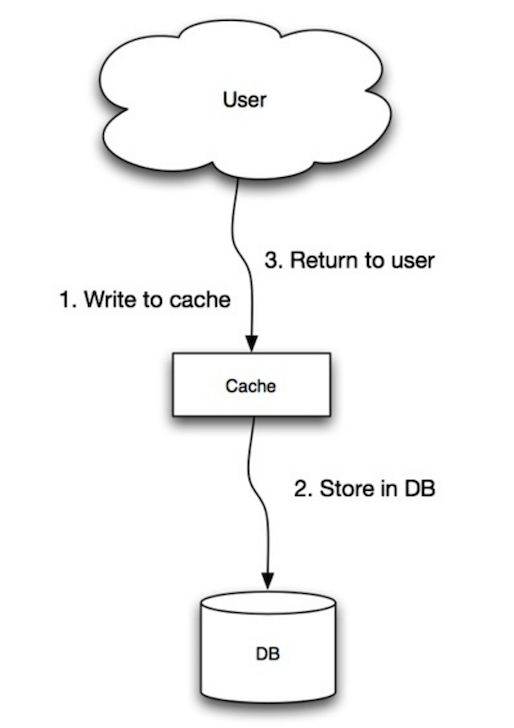
Fuente: escalabilidad, disponibilidad, estabilidad, patrones
La aplicación utiliza el caché como el almacén de datos principal, lee y escribe datos, mientras que el caché es responsable de leer y escribir en la base de datos:
Código de aplicación:
set_user ( 12345 , { "foo" : "bar" })Código de caché:
def set_user ( user_id , values ):
user = db . query ( "UPDATE Users WHERE id = {0}" , user_id , values )
cache . set ( user_id , user )El trabajo de escritura es una operación general lenta debido a la operación de escritura, pero las lecturas posteriores de datos recién escritos son rápidas. Los usuarios generalmente son más tolerantes a la latencia al actualizar los datos que leer datos. Los datos en el caché no son obsoletos.
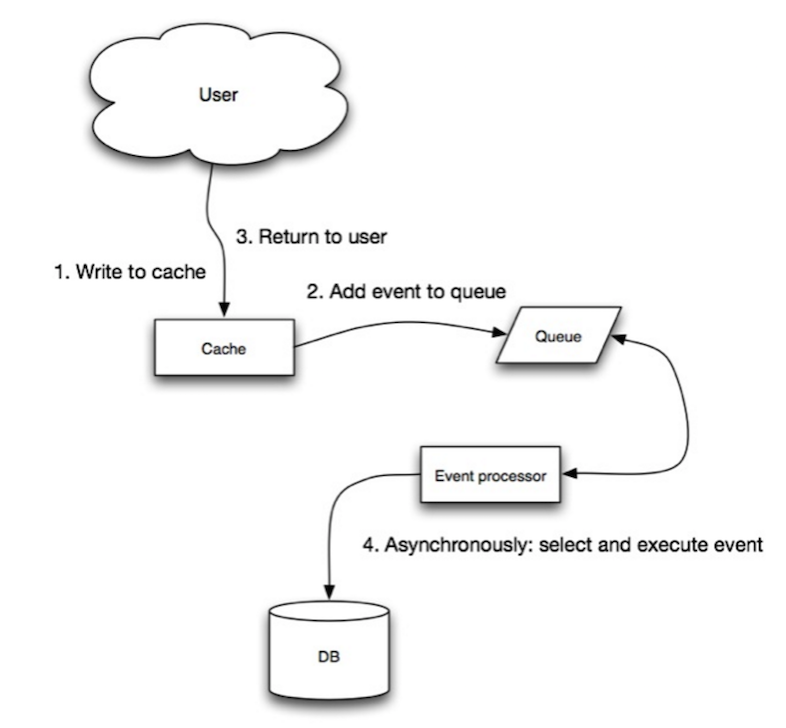
Fuente: escalabilidad, disponibilidad, estabilidad, patrones
En escritura, la aplicación hace lo siguiente:
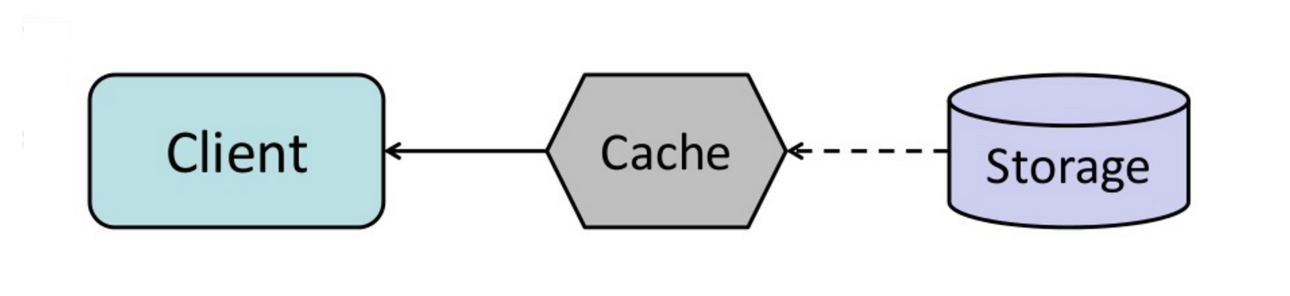
Fuente: Desde el caché hasta la cuadrícula de datos en la memoria
Puede configurar el caché para actualizar automáticamente cualquier entrada de caché recientemente accedida antes de su vencimiento.
Actualizar el avance puede dar como resultado una latencia reducida frente a lectura si el caché puede predecir con precisión qué elementos probablemente se necesitarán en el futuro.
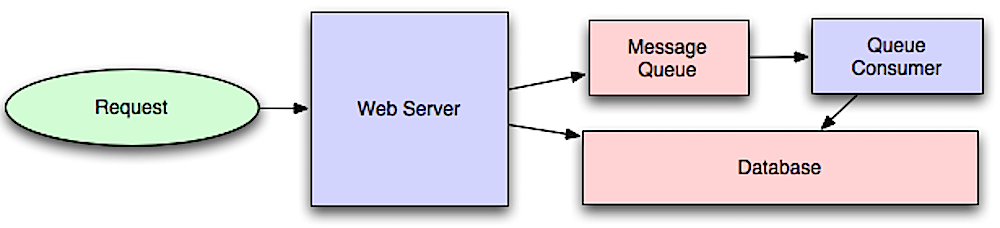
Fuente: Introducción a sistemas de arquitectura para escala
Los flujos de trabajo asincrónicos ayudan a reducir los tiempos de solicitud de operaciones costosas que de otro modo se realizarían en línea. También pueden ayudar realizando un trabajo con mucho tiempo por adelantado, como la agregación periódica de datos.
Las colas de mensajes reciben, retienen y entregan mensajes. Si una operación es demasiado lenta para realizar en línea, puede usar una cola de mensajes con el siguiente flujo de trabajo:
El usuario no está bloqueado y el trabajo se procesa en segundo plano. Durante este tiempo, el cliente podría opcionalmente hacer una pequeña cantidad de procesamiento para que parezca que la tarea se ha completado. Por ejemplo, si publica un tweet, el tweet podría publicarse instantáneamente en su línea de tiempo, pero podría pasar un tiempo antes de que su tweet se entregue a todos sus seguidores.
Redis es útil como corredor de mensajes simple, pero los mensajes se pueden perder.
RabbitMQ es popular, pero requiere que se adapte al protocolo 'AMQP' y administre sus propios nodos.
Amazon SQS está alojado, pero puede tener alta latencia y tiene la posibilidad de que los mensajes se entreguen dos veces.
Las colas de tareas reciben tareas y sus datos relacionados, los ejecutan y luego ofrecen sus resultados. Pueden admitir la programación y pueden usarse para ejecutar trabajos computacionalmente intensivos en segundo plano.
Cereyer tiene apoyo para la programación y principalmente tiene soporte de Python.
Si las colas comienzan a crecer significativamente, el tamaño de la cola puede ser mayor que la memoria, lo que resulta en fallas de caché, lecturas de disco e incluso un rendimiento más lento. La presión posterior puede ayudar limitando el tamaño de la cola, manteniendo así una alta tasa de rendimiento y buenos tiempos de respuesta para los trabajos que ya están en la cola. Una vez que la cola se llena, los clientes obtienen un servidor ocupado o el código de estado HTTP 503 para que vuelva a intentarlo más tarde. Los clientes pueden volver a intentar la solicitud en un momento posterior, tal vez con retroceso exponencial.
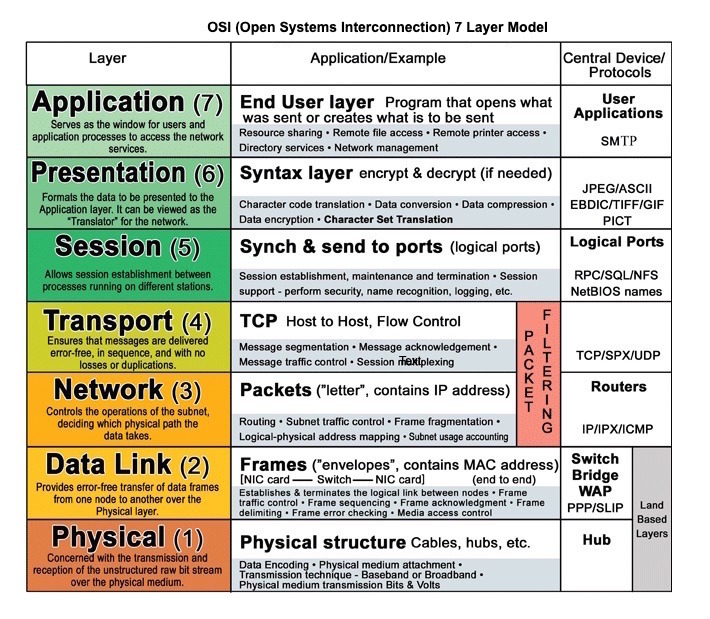
Fuente: Modelo de capa OSI 7
HTTP es un método para codificar y transportar datos entre un cliente y un servidor. Es un protocolo de solicitud/respuesta: los clientes emiten solicitudes y los servidores emiten respuestas con contenido relevante y información de estado de finalización sobre la solicitud. HTTP es autónomo, lo que permite que las solicitudes y las respuestas fluyan a través de muchos enrutadores y servidores intermedios que realizan equilibrio de carga, almacenamiento en caché, cifrado y compresión.
Una solicitud HTTP básica consiste en un verbo (método) y un recurso (punto final). A continuación se muestran verbos HTTP comunes:
| Verbo | Descripción | IdeMpotent* | Seguro | Almacenable en caché |
|---|---|---|---|---|
| CONSEGUIR | Lee un recurso | Sí | Sí | Sí |
| CORREO | Crea un recurso o activa un proceso que maneja los datos | No | No | Sí, si la respuesta contiene información de frescura |
| PONER | Crea o reemplaza un recurso | Sí | No | No |
| PARCHE | Actualiza parcialmente un recurso | No | No | Sí, si la respuesta contiene información de frescura |
| BORRAR | Elimina un recurso | Sí | No | No |
*Se puede llamar muchas veces sin resultados diferentes.
HTTP es un protocolo de capa de aplicación que depende de protocolos de nivel inferior como TCP y UDP .
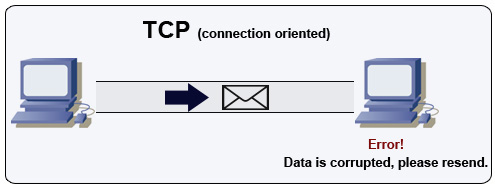
Fuente: Cómo hacer un juego multijugador
TCP es un protocolo orientado a la conexión a través de una red IP. La conexión se establece y termina utilizando un apretón de manos. Todos los paquetes enviados están garantizados para llegar al destino en el orden original y sin corrupción a través de:
Si el remitente no recibe una respuesta correcta, reenviará los paquetes. Si hay múltiples tiempos de espera, la conexión se elimina. TCP también implementa el control de flujo y el control de congestión. Estas garantías causan retrasos y generalmente dan como resultado una transmisión menos eficiente que UDP.
Para garantizar un alto rendimiento, los servidores web pueden mantener abiertas una gran cantidad de conexiones TCP, lo que resulta en un alto uso de memoria. Puede ser costoso tener una gran cantidad de conexiones abiertas entre los hilos del servidor web y decir, un servidor Memcached. La agrupación de conexión puede ayudar, además de cambiar a UDP, cuando corresponda.
TCP es útil para aplicaciones que requieren alta confiabilidad pero que son menos críticas. Algunos ejemplos incluyen servidores web, información de base de datos, SMTP, FTP y SSH.
Use TCP sobre UDP cuando:
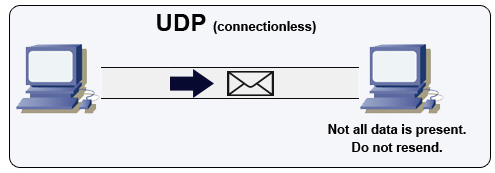
Fuente: Cómo hacer un juego multijugador
UDP es sin conexión. Los datagramas (análogos a los paquetes) están garantizados solo a nivel de datagrama. Los datagramas pueden llegar a su destino fuera de servicio o no en absoluto. UDP no admite el control de congestión. Sin las garantías de que el soporte de TCP, UDP es generalmente más eficiente.
UDP puede transmitir, enviando datagramas a todos los dispositivos en la subred. Esto es útil con DHCP porque el cliente aún no ha recibido una dirección IP, evitando así una forma de que TCP transmita sin la dirección IP.
UDP es menos confiable, pero funciona bien en casos de uso en tiempo real como VoIP, chat de video, transmisión y juegos multijugador en tiempo real.
Use UDP sobre TCP cuando:
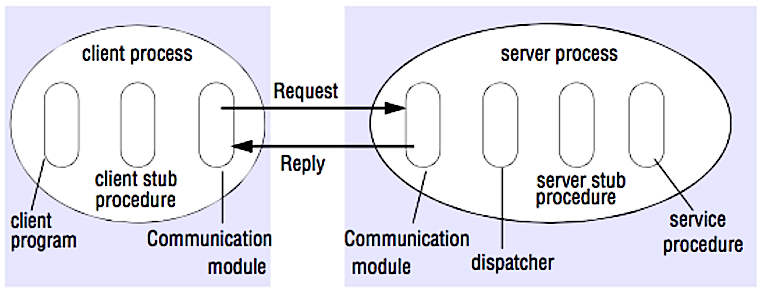
Fuente: Cruce la entrevista de diseño del sistema
En un RPC, un cliente hace que un procedimiento se ejecute en un espacio de direcciones diferente, generalmente un servidor remoto. El procedimiento se codifica como si fuera una llamada de procedimiento local, abstraiendo los detalles de cómo comunicarse con el servidor del programa del cliente. Las llamadas remotas suelen ser más lentas y menos confiables que las llamadas locales, por lo que es útil distinguir las llamadas RPC de las llamadas locales. Los marcos RPC populares incluyen ProtoBuf, Thrift y Avro.
RPC es un protocolo de respuesta de solicitud:
Muestra de llamadas de RPC:
GET /someoperation?data=anId
POST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
RPC se centra en exponer comportamientos. Los RPC a menudo se usan por razones de rendimiento con comunicaciones internas, ya que puede hacer manualidades a mano las llamadas nativas para adaptarse mejor a sus casos de uso.
Elija una biblioteca nativa (también conocida como SDK) cuando:
Las API HTTP después del reposo tienden a usarse con más frecuencia para las API públicas.
REST es un estilo arquitectónico que hace cumplir un modelo de cliente/servidor donde el cliente actúa en un conjunto de recursos administrados por el servidor. El servidor proporciona una representación de recursos y acciones que pueden manipular o obtener una nueva representación de recursos. Toda la comunicación debe ser apátrida y almacenable.
Hay cuatro cualidades de una interfaz RESTful:
Muestra de reposo llamadas:
GET /someresources/anId
PUT /someresources/anId
{"anotherdata": "another value"}
REST se centra en exponer datos. Minimiza el acoplamiento entre el cliente/servidor y a menudo se usa para las API públicas HTTP. REST utiliza un método más genérico y uniforme para exponer los recursos a través de URI, representación a través de encabezados y acciones a través de verbos como Get, Post, Put, Eliminar y el parche. Al ser apátrate, el descanso es excelente para la escala horizontal y la partición.
| Operación | RPC | DESCANSAR |
|---|---|---|
| Inscribirse | Post /Registro | Post /Personas |
| Renunciar | Post /renunciar { "Personido": "1234" } | Eliminar /Personas /1234 |
| Leer una persona | Get /Readperson? Personid = 1234 | Obtener /Personas /1234 |
| Leer la lista de artículos de una persona | Get /ReaduseSitemslist? Personid = 1234 | Obtener /personas/1234/elementos |
| Agregue un artículo a los artículos de una persona | Post /additemToUsitemslist { "Personido": "1234"; "itemid": "456" } | Post /personas/1234/elementos { "itemid": "456" } |
| Actualizar un elemento | Post /ModifyItem { "itemId": "456"; "clave": "valor" } | Poner /elementos /456 { "clave": "valor" } |
| Eliminar un artículo | Post /removerItem { "itemid": "456" } | Eliminar /elementos /456 |
Fuente: ¿Realmente sabes por qué prefieres descansar sobre RPC?
Esta sección podría usar algunas actualizaciones. ¡Considere contribuir!
La seguridad es un tema amplio. A menos que tenga una experiencia considerable, un fondo de seguridad o que esté solicitando un puesto que requiera conocimiento de seguridad, probablemente no necesite saber más que lo básico:
A veces se le pedirá que haga estimaciones de 'retroceso de la otra'. Por ejemplo, es posible que deba determinar cuánto tiempo llevará generar 100 miniaturas de imágenes desde el disco o cuánta memoria tomará una estructura de datos. Los poderes de dos números de tabla y latencia que todo programador debe conocer son referencias útiles.
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 ms
Notes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
Métricas prácticas basadas en los números anteriores:
Preguntas comunes de la entrevista de diseño del sistema, con enlaces a recursos sobre cómo resolver cada una.
| Pregunta | (S) referencia (s) |
|---|---|
| Diseñe un servicio de sincronización de archivos como Dropbox | youtube.com |
| Diseñe un motor de búsqueda como Google | cola.acm.org stackexchange.com ardendertat.com stanford.edu |
| Diseñe un rastreador web escalable como Google | quora.com |
| Diseñar Google Docs | code.google.com neil.fraser.name |
| Diseñe una tienda de valor clave como Redis | slideshare.net |
| Diseñe un sistema de caché como Memcached | slideshare.net |
| Diseñe un sistema de recomendación como Amazon's | hulu.com ijcai13.org |
| Diseñe un sistema Tinyurl como Bitly | n00tc0d3r.blogspot.com |
| Diseñe una aplicación de chat como WhatsApp | Highscalability.com |
| Diseñe un sistema de intercambio de imágenes como Instagram | Highscalability.com Highscalability.com |
| Diseñe la función de alimentación de noticias de Facebook | quora.com quora.com slideshare.net |
| Diseñe la función de línea de tiempo de Facebook | facebook.com Highscalability.com |
| Diseñe la función de chat de Facebook | erlang-factory.com facebook.com |
| Diseñe una función de búsqueda de gráficos como la de Facebook | facebook.com facebook.com facebook.com |
| Diseñe una red de entrega de contenido como Cloudflare | figshare.com |
| Diseñar un sistema de temas de tendencia como el de Twitter | Michael-noll.com snikolov .wordpress.com |
| Diseñe un sistema de generación de identificación aleatorio | blog.twitter.com github.com |
| Devuelva las solicitudes K superiores durante un intervalo de tiempo | cs.ucsb.edu wpi.edu |
| Diseñe un sistema que sirva datos de múltiples centros de datos | Highscalability.com |
| Diseñe un juego de cartas multijugador en línea | indieflashblog.com buildnewgames.com |
| Diseñar un sistema de recolección de basura | StuffWithstuff.com Washington.edu |
| Diseñar un limitador de velocidad API | https://stripe.com/blog/ |
| Diseñe una bolsa de valores (como Nasdaq o Binance) | Jane Street Implementación de Golang Implementación de GO |
| Agregar una pregunta de diseño del sistema | Contribuir |
Los artículos sobre cómo se diseñan los sistemas del mundo real.
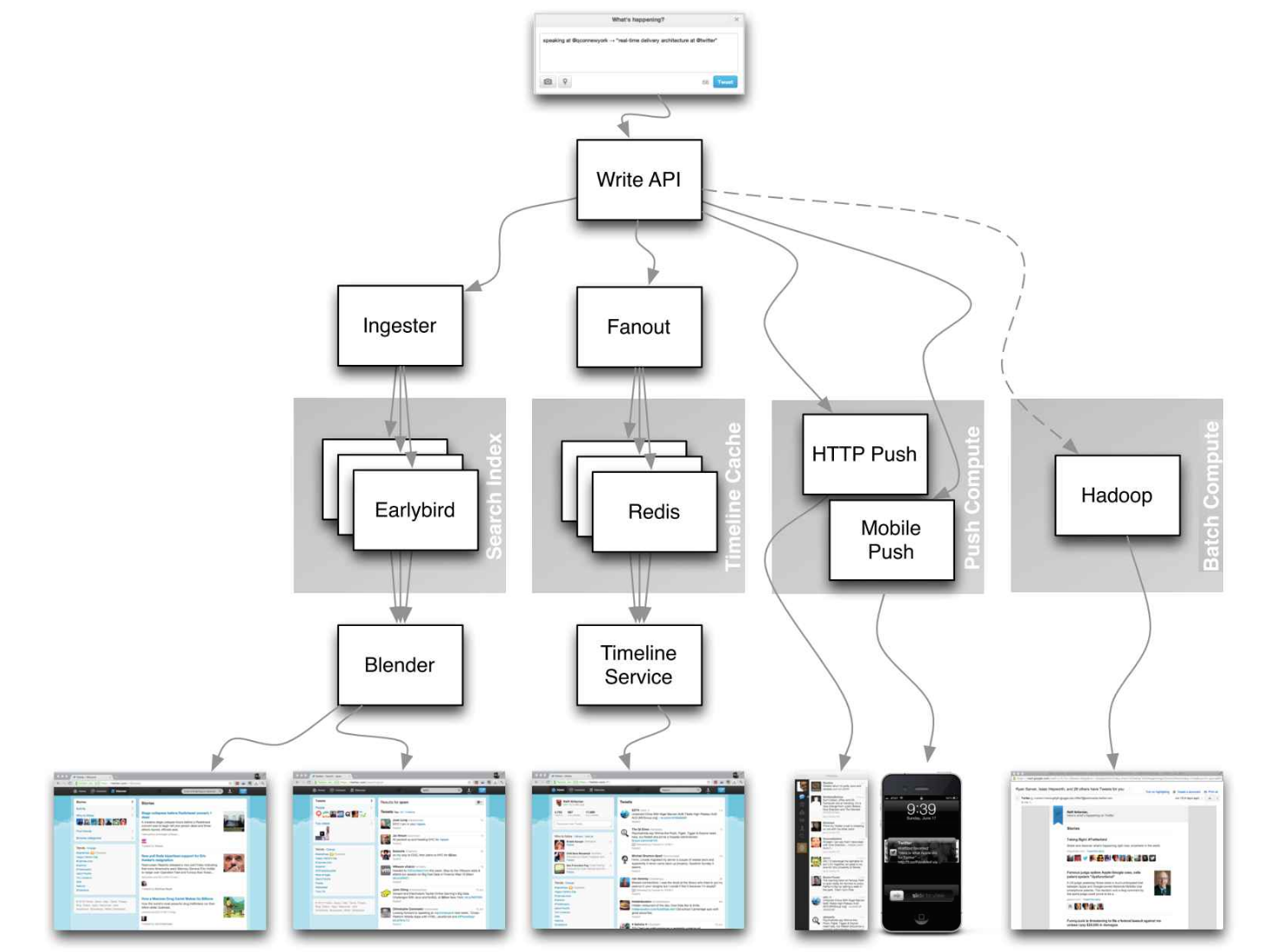
Fuente: plazos de Twitter a escala
En su lugar, no se concentre en los detalles arenosos de los siguientes artículos:
| Tipo | Sistema | (S) referencia (s) |
|---|---|---|
| Proceso de datos | MapReduce - Procesamiento de datos distribuidos de Google | investigar.google.com |
| Proceso de datos | Spark - Procesamiento de datos distribuidos de Databricks | slideshare.net |
| Proceso de datos | Tormenta : procesamiento de datos distribuidos desde Twitter | slideshare.net |
| Almacén de datos | BigTable - Base de datos orientada a columnas distribuida de Google | Harvard.edu |
| Almacén de datos | HBASE - Implementación de código abierto de BigTable | slideshare.net |
| Almacén de datos | Cassandra - Base de datos distribuida orientada a columnas de Facebook | slideshare.net |
| Almacén de datos | DYNAMODB - Base de datos orientada a documentos de Amazon | Harvard.edu |
| Almacén de datos | MongoDB - Base de datos orientada a documentos | slideshare.net |
| Almacén de datos | Spanner : base de datos distribuida a nivel mundial desde Google | investigar.google.com |
| Almacén de datos | MEMCACHED - Sistema de almacenamiento en caché de memoria distribuido | slideshare.net |
| Almacén de datos | Redis - Distributed memory caching system with persistence and value types | slideshare.net |
| File system | Google File System (GFS) - Distributed file system | research.google.com |
| File system | Hadoop File System (HDFS) - Open source implementation of GFS | apache.org |
| Varios | Chubby - Lock service for loosely-coupled distributed systems from Google | research.google.com |
| Varios | Dapper - Distributed systems tracing infrastructure | research.google.com |
| Varios | Kafka - Pub/sub message queue from LinkedIn | slideshare.net |
| Varios | Zookeeper - Centralized infrastructure and services enabling synchronization | slideshare.net |
| Add an architecture | Contribuir |
| Compañía | Reference(s) |
|---|---|
| Amazonas | Amazon architecture |
| Cinchcast | Producing 1,500 hours of audio every day |
| DataSift | Realtime datamining At 120,000 tweets per second |
| buzón | How we've scaled Dropbox |
| ESPN | Operating At 100,000 duh nuh nuhs per second |
| Google architecture | |
| 14 million users, terabytes of photos What powers Instagram | |
| Justin.tv | Justin.Tv's live video broadcasting architecture |
| Scaling memcached at Facebook TAO: Facebook's distributed data store for the social graph Facebook's photo storage How Facebook Live Streams To 800,000 Simultaneous Viewers | |
| Flickr | Flickr architecture |
| Buzón | From 0 to one million users in 6 weeks |
| netflix | A 360 Degree View Of The Entire Netflix Stack Netflix: What Happens When You Press Play? |
| From 0 To 10s of billions of page views a month 18 million visitors, 10x growth, 12 employees | |
| Playfish | 50 million monthly users and growing |
| PlentyOfFish | PlentyOfFish architecture |
| fuerza de ventas | How they handle 1.3 billion transactions a day |
| Desbordamiento de pila | Stack Overflow architecture |
| tripadvisor | 40M visitors, 200M dynamic page views, 30TB data |
| tumblr | 15 billion page views a month |
| Gorjeo | Making Twitter 10000 percent faster Storing 250 million tweets a day using MySQL 150M active users, 300K QPS, a 22 MB/S firehose Timelines at scale Big and small data at Twitter Operations at Twitter: scaling beyond 100 million users How Twitter Handles 3,000 Images Per Second |
| Úber | How Uber scales their real-time market platform Lessons Learned From Scaling Uber To 2000 Engineers, 1000 Services, And 8000 Git Repositories |
| The WhatsApp architecture Facebook bought for $19 billion | |
| YouTube | YouTube scalability YouTube architecture |
Architectures for companies you are interviewing with.
Questions you encounter might be from the same domain.
Looking to add a blog? To avoid duplicating work, consider adding your company blog to the following repo:
Interested in adding a section or helping complete one in-progress? ¡Contribuir!
Credits and sources are provided throughout this repo.
Special thanks to:
Feel free to contact me to discuss any issues, questions, or comments.
My contact info can be found on my GitHub page.
I am providing code and resources in this repository to you under an open source license. Because this is my personal repository, the license you receive to my code and resources is from me and not my employer (Facebook).
Copyright 2017 Donne Martin
Creative Commons Attribution 4.0 International License (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/


